Start Exploring Keyword Ideas
Use Serpstat to find the best keywords for your website
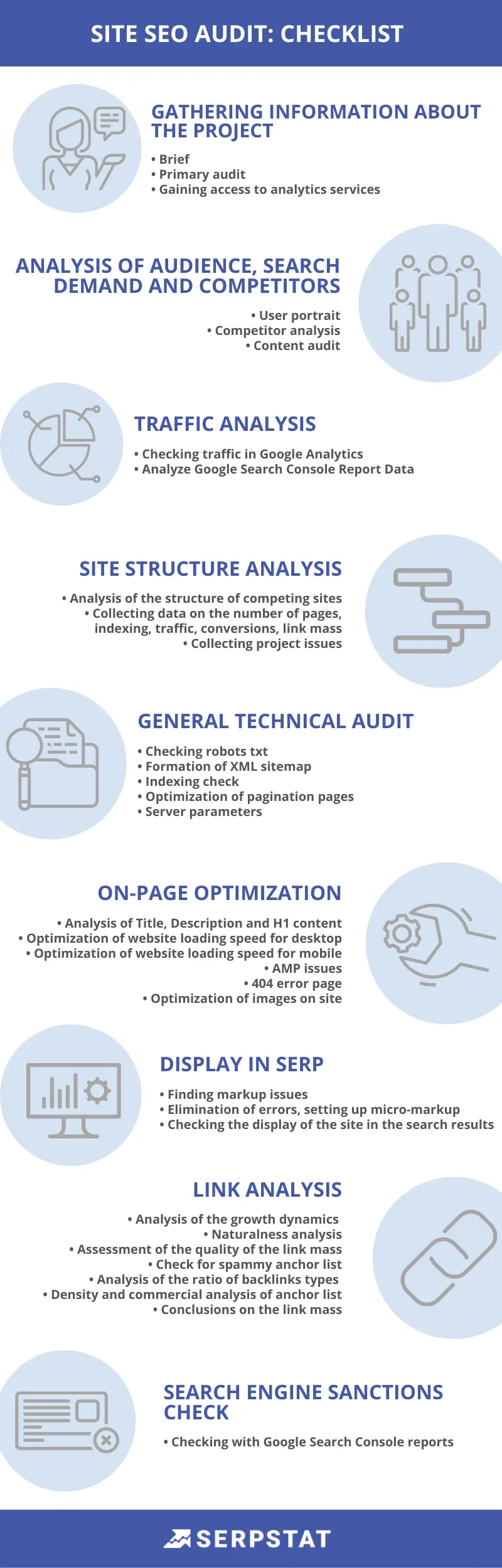
Advanced SEO Audit Checklist for All Stages of The Analysis
[Infographic]


SEO Audit is a website check for internal issues and compliance with search engines' requirements. An audit is necessary in case of search engine sanctions and when everything is fine. It can help accelerate website growth by identifying and fixing technical vulnerabilities.
You should always carry out a detailed audit before starting on-site optimization. It will help you find minor bugs and serious problems.
Let's get to our technical SEO audit checklist.
General information
What is an SEO audit
An SEO audit assesses a website's effectiveness by measuring its performance in search results. It allows you to establish the current quality of website optimization and find weaknesses or growth points for further improvement and increased search traffic.
Why is SEO audit important
In-depth technical audit on a website helps you find weaknesses in site optimization, making it possible to correct existing errors and increase traffic from organic search results.
Additionally, the audit allows you to:
- Find the target audience portrait.
- Collect the primary information about the project.
- Asses current SEO metrics.
- Customize meta tags.
- Improve backlinkscrawling.



Stages of an SEO audit
Gathering information about the project
First of all, you should decide on the goals, which can vary (brief, primary audit, etc.). It will be helpful to obtain the maximum information about the specifics of the client's work, business data, and approximate performance indicators.
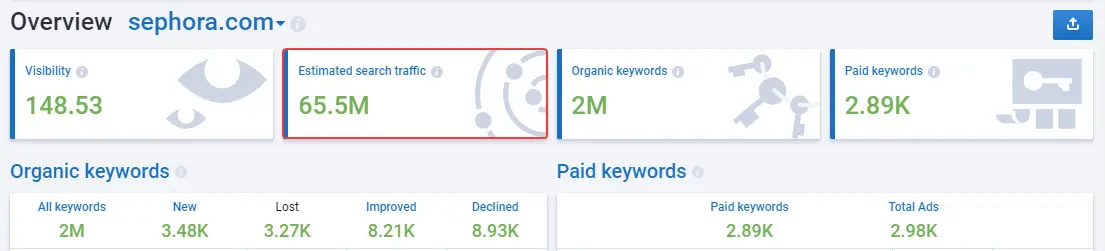
For a primary audit, you can use Serpstat or an alternative service, which lets you get data on keywords the site already ranks for, analyze links and visibility for the last year, and much more.
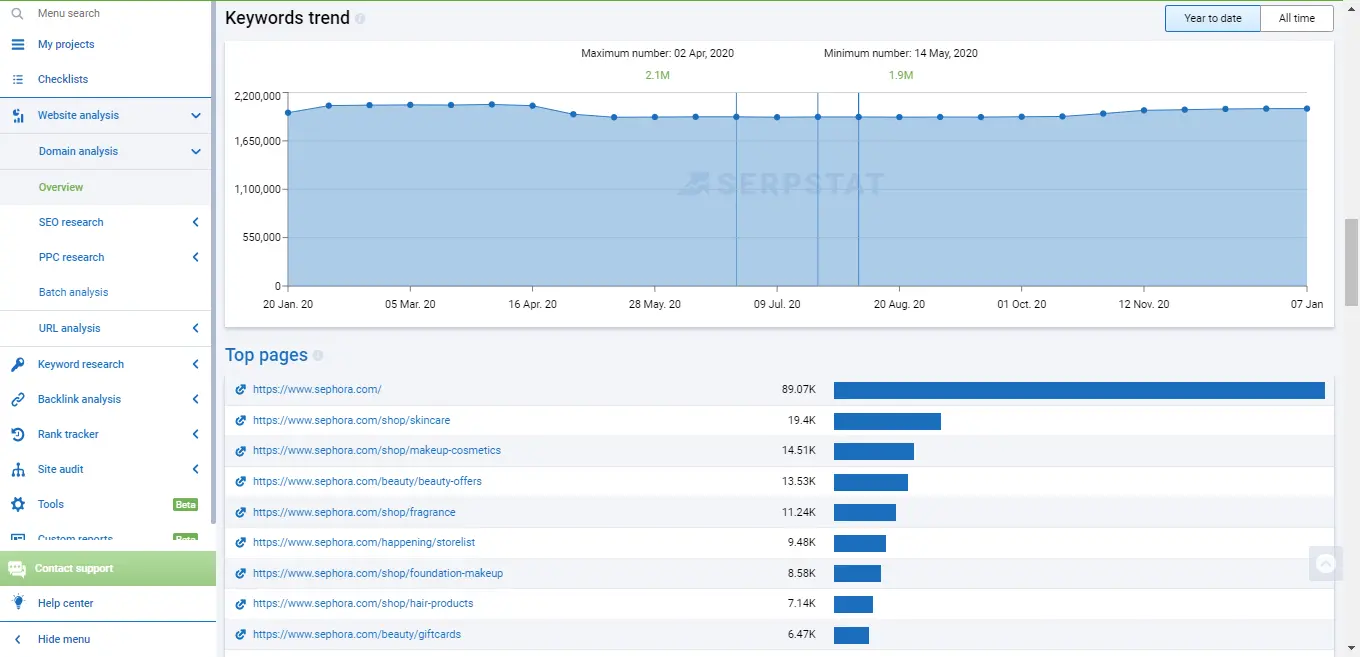
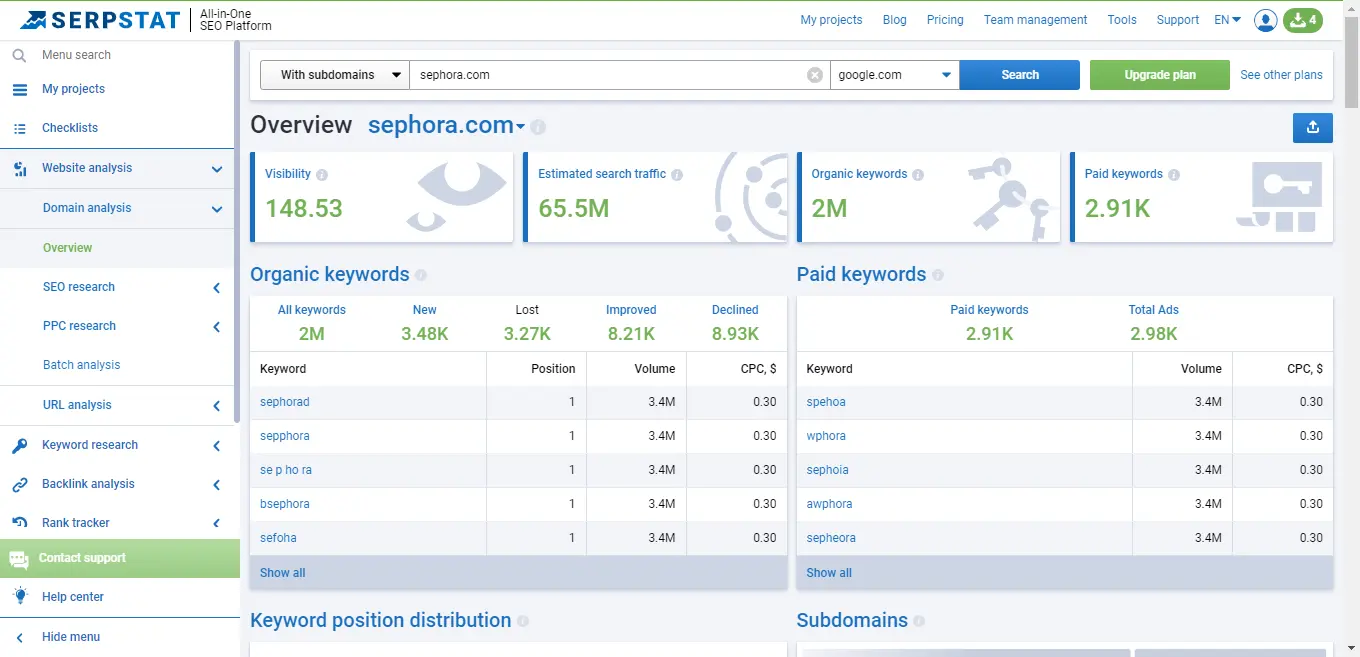
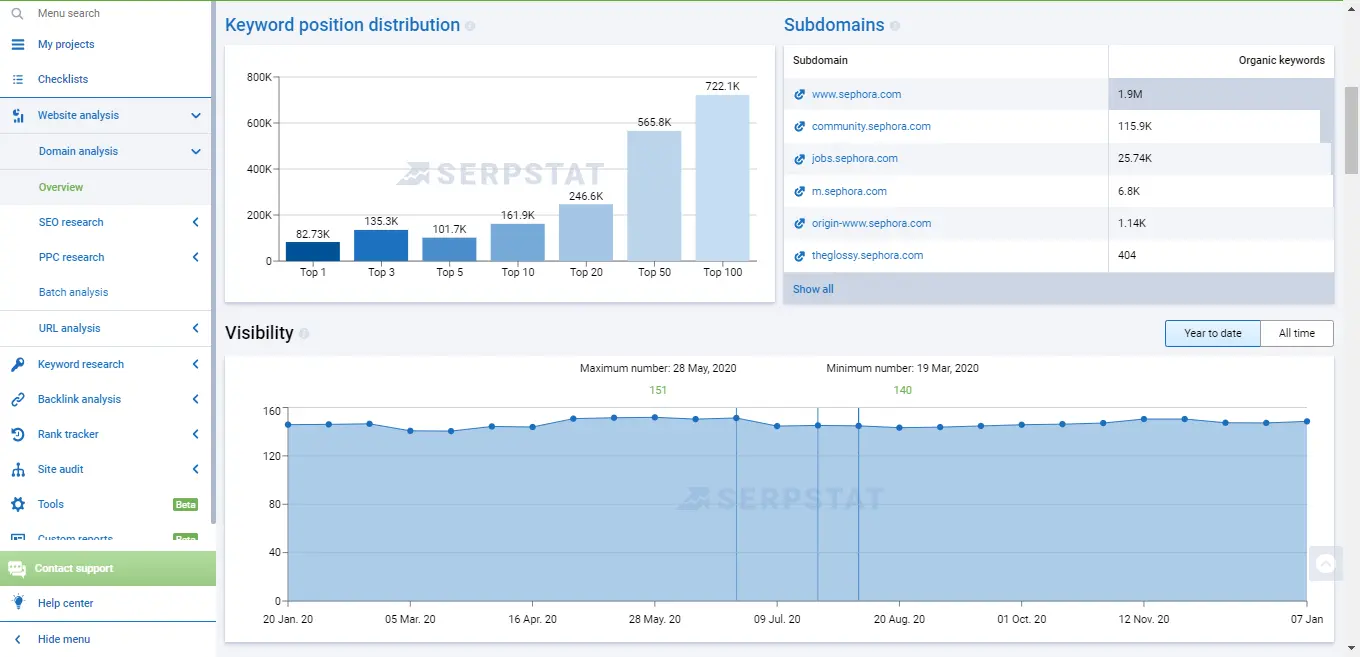
Required accesses:
- Google Analytics
- Google Search Console
Also, in case the company has already worked with SEO contractors, it is better to analyze an SEO report. It will allow you to understand the work that has already been done and pay attention to the tasks that have not yet been completed.
Unlock the Power of SEO Analysis with Serpstat's 7-Day Trial!
Whether you're an experienced SEO pro or business owner, our platform helps you assess the work done and identify pending tasks.
Analysis of audience, search demand, and competitors
User persona
Let's proceed with our SEO audit checklist. The first point is the portrait of the target audience, which should contain the following data:
- age;
- gender;
- residence;
- marital status;
- area of employment;
- income level;
- position;
- needs, desires, and hobbies.
Additionally, you should understand that some topics may have several user personas, which may be interested in the promoted product.
Competitor analysis
There is a lot of work here since you should collect the maximum amount of data about your competitors:
You could even go as far as doing a complete competitor website audit. Find a full list of all possible data on competitor analysis here.
Content audit:
It's impossible to delegate this process to robots completely. A human SEO auditor still needs to work with texts and content. Although, you can automate a major part of content audit processes with specialized tools.
Traffic analysis
Traffic analysis can be performed using the standard analytics system - Google Analytics.
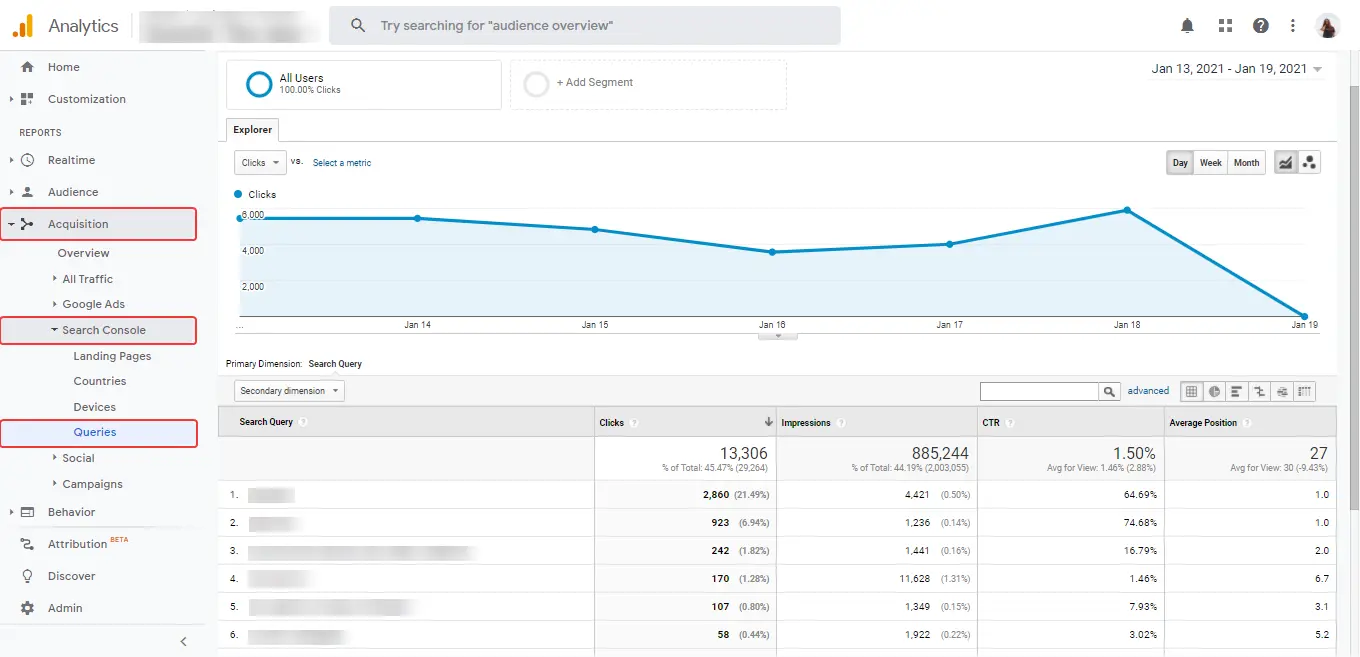
It's also worth checking out reports from Google Search Console, for example, Devices.
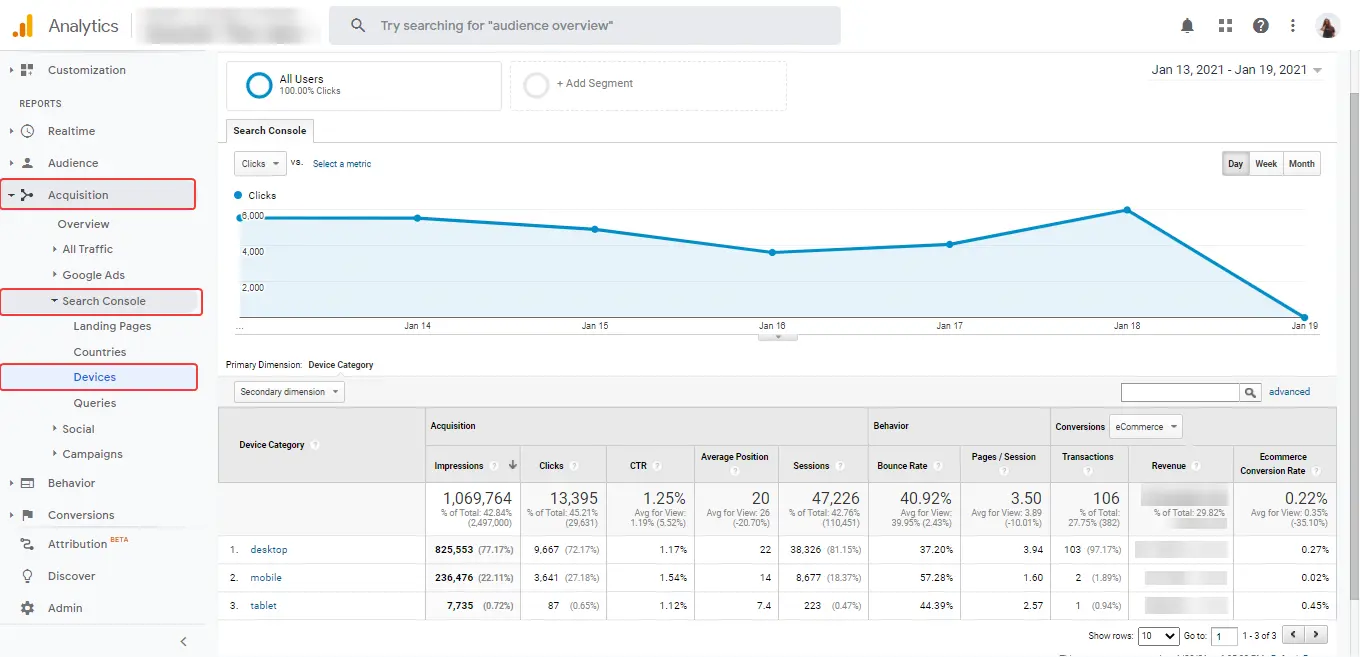
Analysis of the site structure
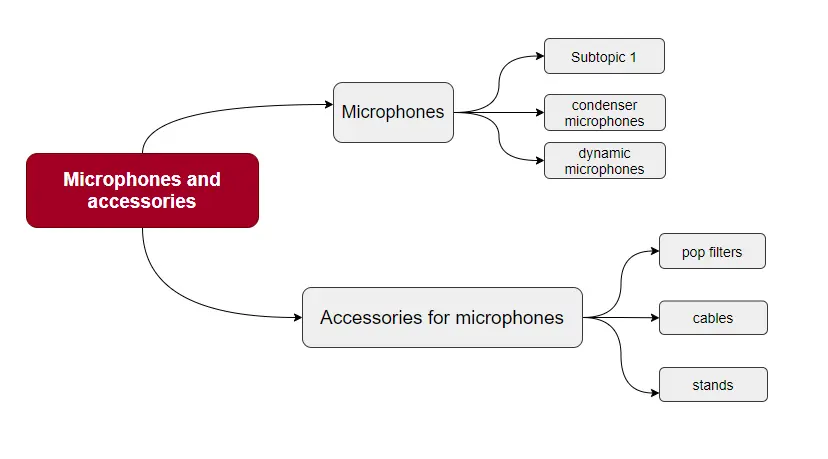
There are many types of site structures: linear, branched, tree, mixed, etc. First, you should see if it looks harmonious after expanding the keyword list or if it needs redone.
For example, in an online store, you can determine the category of goods to which, e.g., microphones, can be related. Accordingly, think over the entire path of the user to the section. For example, you can start with the category "Microphones and accessories," after which they can be divided into "Microphones" and "Accessories", and so on.
A large site is not homogeneous; it consists of several sections, each of which (with proper content structuring) corresponds to a sub-niche with its own search demand, competition, and user behavior patterns.
Therefore, an audit must contain a comparative analysis of the sections. Moreover, without careful study of the parts of the site, one cannot be sure there are no technical problems. Different dynamics across sections can easily distort the indicators we tested.
The analysis itself is simple enough. You need to collect data on the number of pages, indexing, traffic, conversions, backlink profile, and so on in a pivot table. Then, problems and inconsistencies appear at a glance.
General technical audit
Robots txt check
In the case of Google, you can use the Google Search Console; it is enough to select a property and start working. Here, we also see the entire file with the rules.
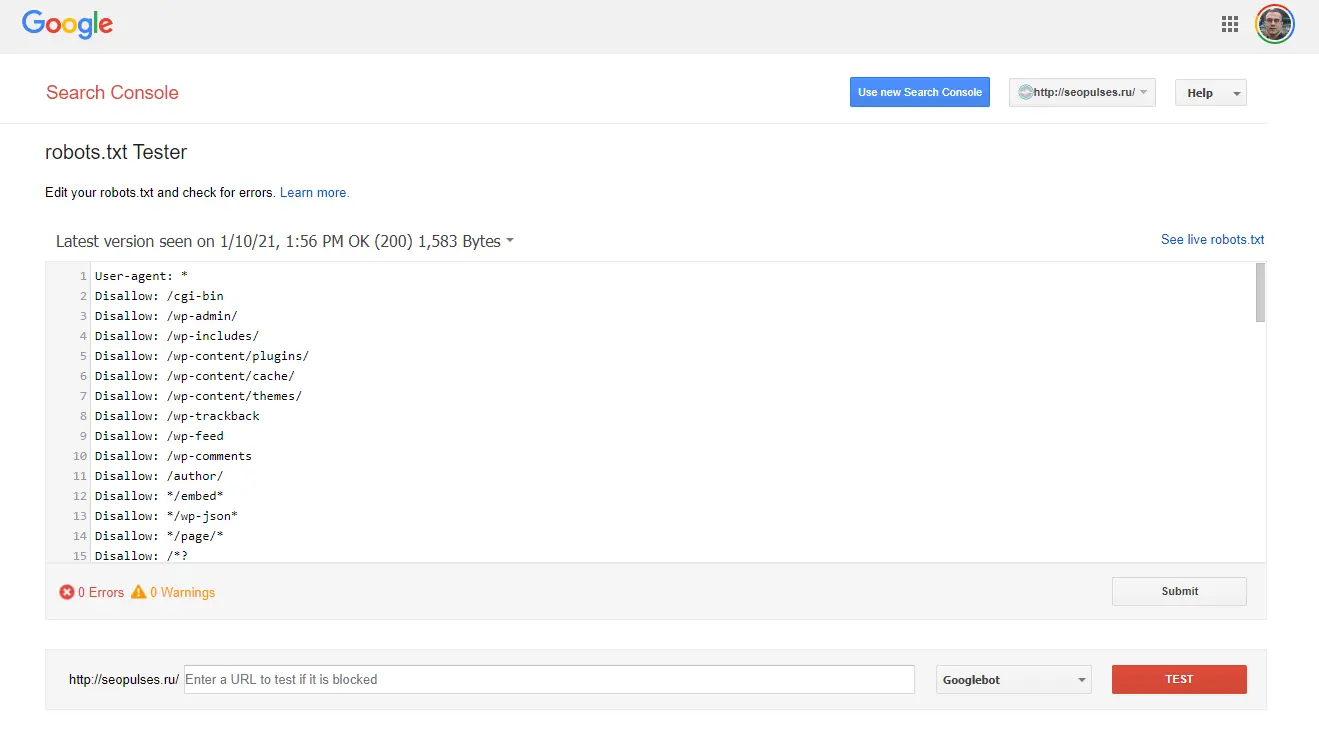
If you need, you can check the ability to scan pages.
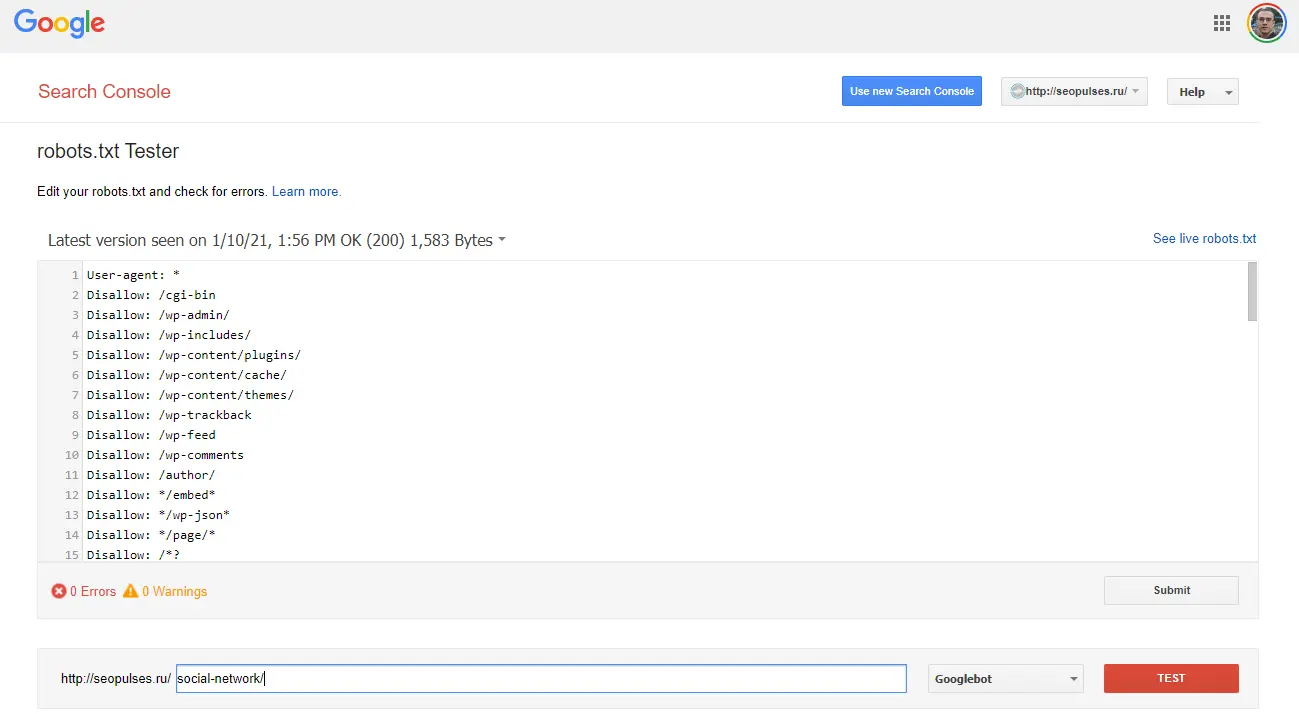
Then, we see the result and the prohibiting rule.
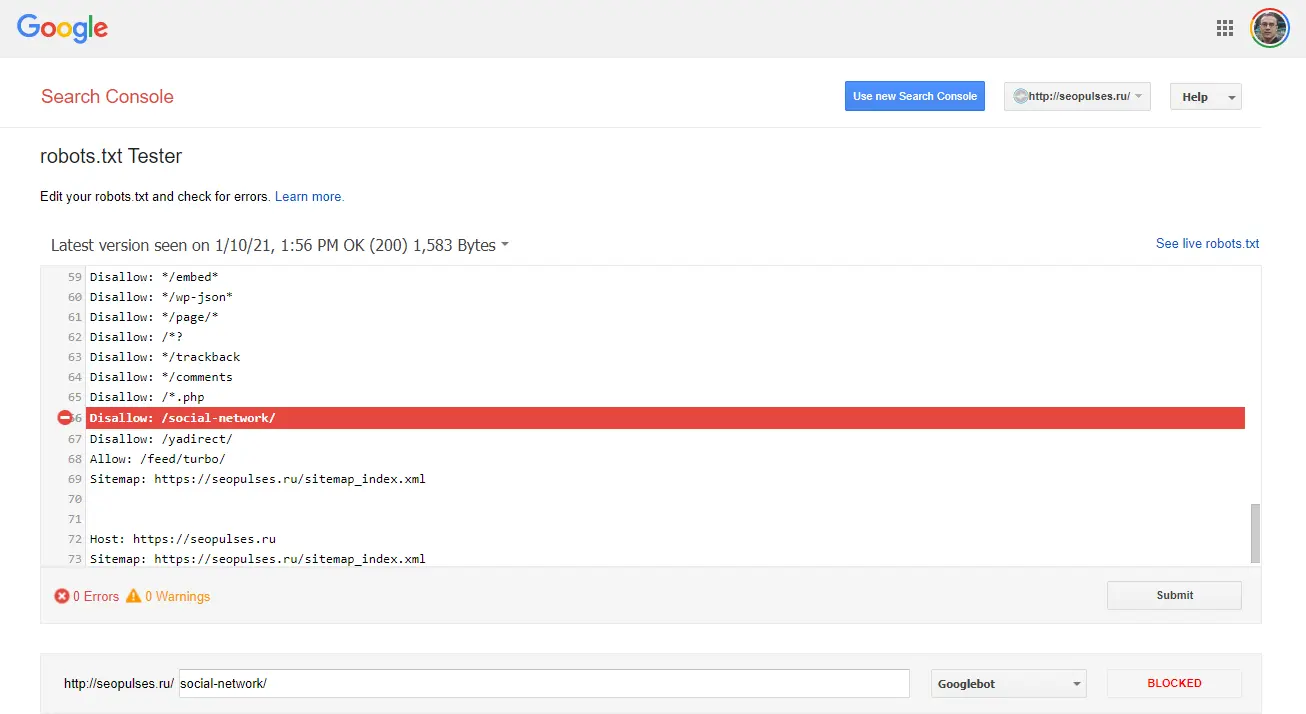
After reviewing the indexing and understanding which pages should not be crawled by the robot, just add them to the robots.txt file.
Check if the correct pages are closed in robots.txt. You will find this recommendation in the Serpstat Site Audit.

One move with your magic wand and "Allow: /" turns into "Disallow: /." In this case, do not be surprised why your site is not indexed or, even worse, dropped out of the index and lost all positions. How can these problems be avoided? Like Meta Robots — keep track of positions and regularly check the site with a crawler. Be careful when setting up robots.txt on test subdomains (for developers and QA) — these subdomains obviously should not be indexed; therefore, it is advisable to close them in robots.txt.

Would you like to try an SEO audit with Serpstat?
Start your 7-day trial today and supercharge your SEO efforts!
XML Sitemap
You can use modules or plugins to generate a sitemap on a traditional CMS. For example, in the case of WordPress, it is enough to install the Yoast SEO plugin, where you can enable the generation of an XML sitemap in the general settings.
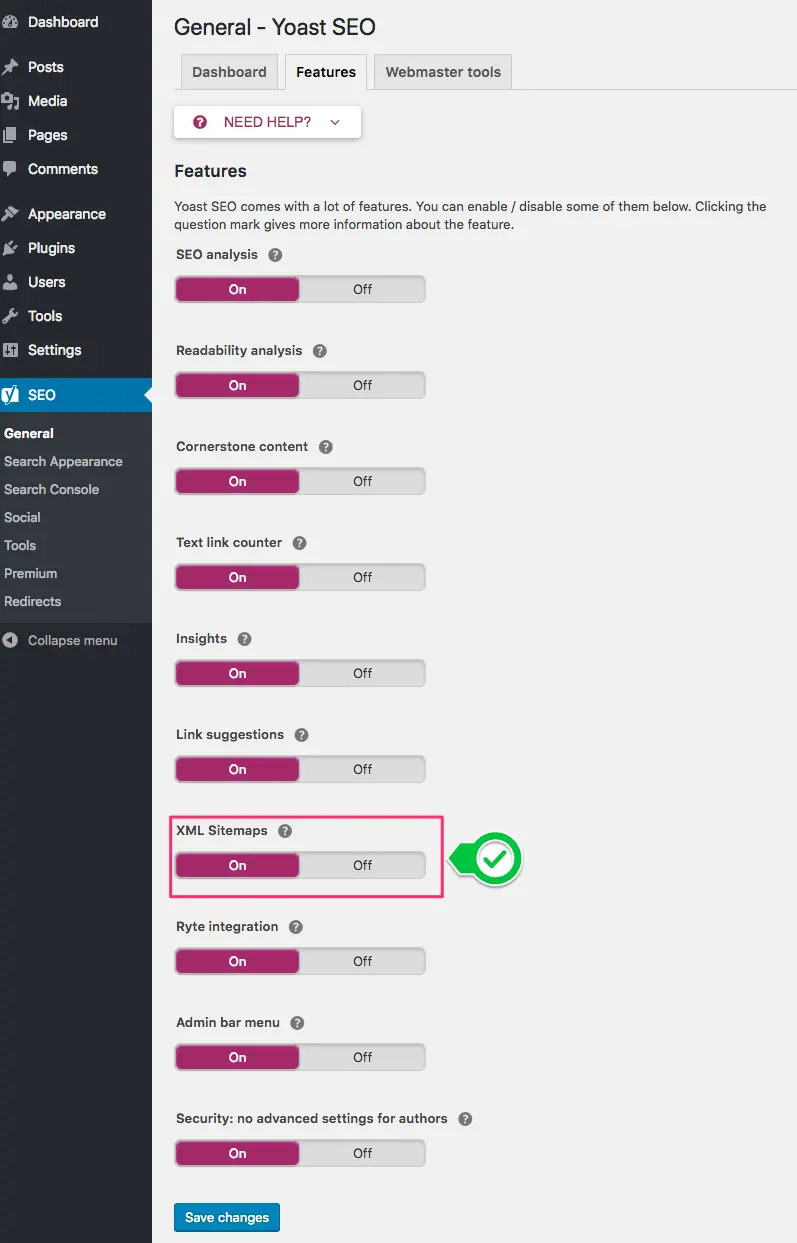
Employin ga non-standard CMS, you can use the free SiteAnalyzer tool to generate a sitemap in XML format. After that, you need to download the file to the file's root folder and use it to download to the systems you need.



Indexing check
You can check the indexing of site pages in Google through Search Console, where in the Indexing — Page section, you can see the following types of pages:
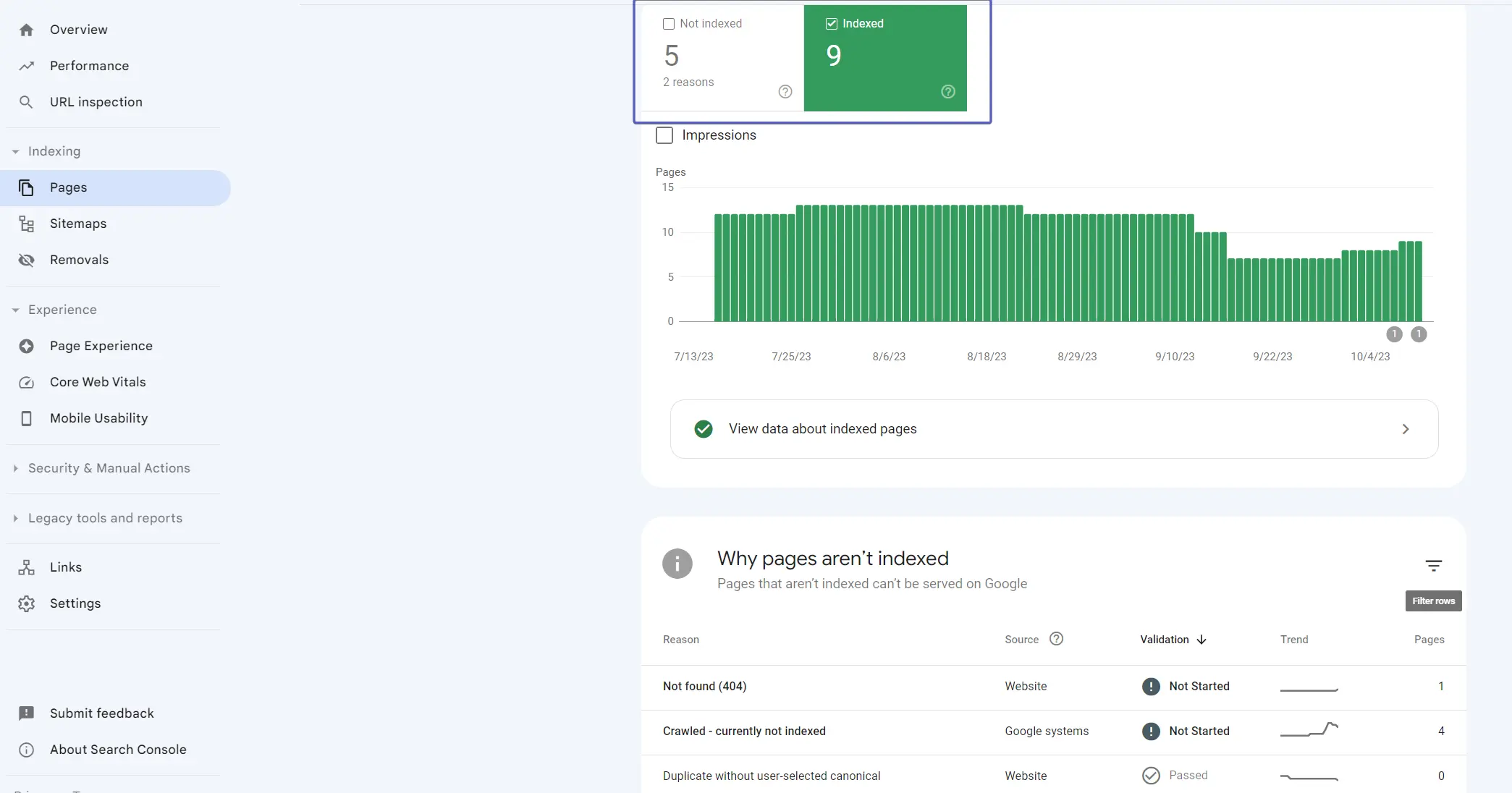
You can also use filters to speed up your search.
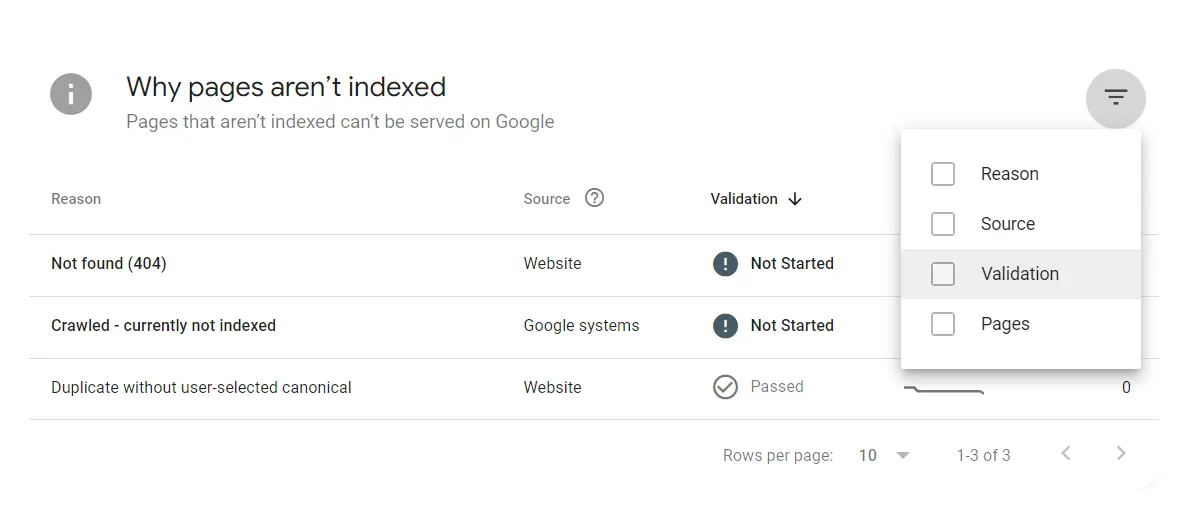
To check the indexing of a specific page, you can just enter a URL in the search bar. The indexing status will be shown by the Console immediately.
Optimization of pagination pages
Optimization is needed to eliminate the problem of indexing pagination pages, which are sequential URLs with numbers:
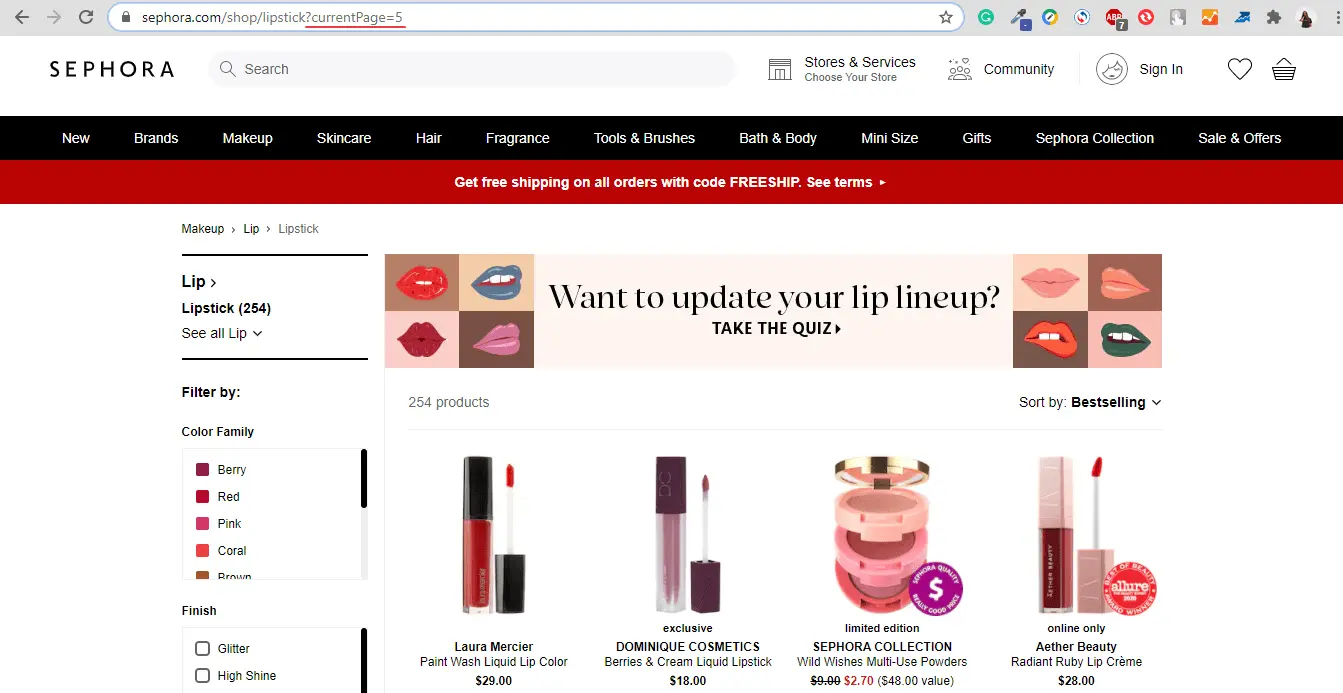
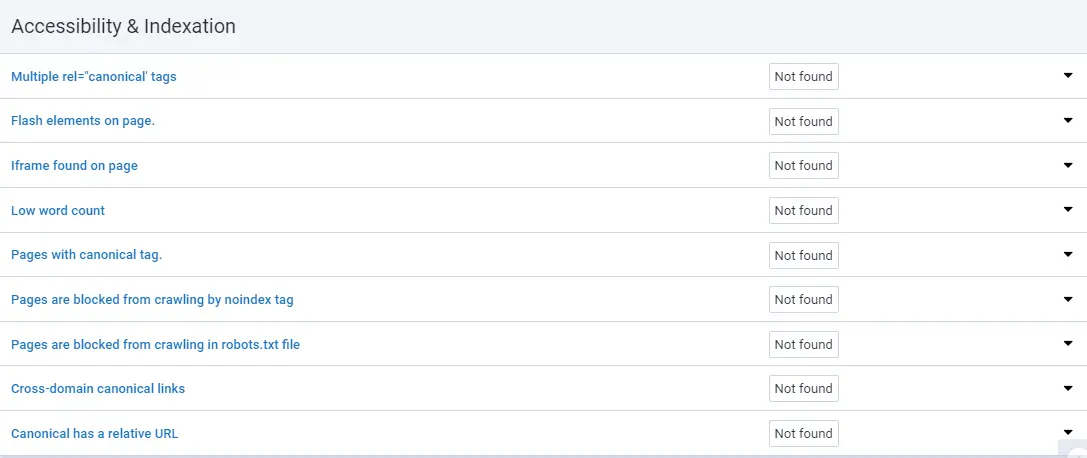
Search engines can sometimes crawl these pages and add them to search results. To solve this problem, adding the "rel ="canonical" tag to the site page code is enough.
You can find errors related to misuse of the canonical tag in the Site Audit ’All issues’ report.
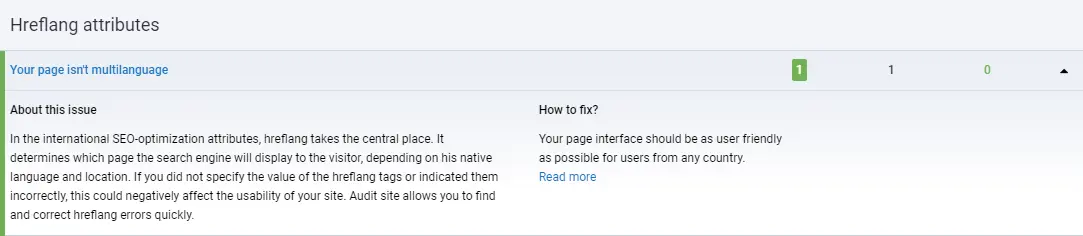
Multilingual websites
For search engines to consider all site versions (language), arranging them on separate URLs is necessary. Additionally, you should set the hreflang attribute for alternate pages. The hreflang is relevant primarily for Google.
The most frequently encountered error in using this attribute is the lack of links from one page to another. After all, if several page versions are in different languages, each must contain a link to another. Also, do not forget about the Sitemap, where you must add several page versions through the "loc" element.
You can easily find errors related to incorrect use of the hreflang tag in the Serpstat Site Audit tool.
In July 2024, Serpstat updated the functionality of the website audit tool. Among the key changes:
- improved tool stability and accuracy in detecting errors on pages
- better scanning logic, which has become more streamlined
- the ability to scan websites on JavaScript has been added
- detection of a new type of error called "Missing markup in JSON-LD format"
Server parameters
Server parameters play a significant role in the site loading speed, which affects the usability and the position in the search results.
To optimize your site at the server level, it is recommended to use:
- Caching
- Compression
- CDN
On-page SEO guide
Title, Description, and H1 heading
It's the first step in SEO page analysis and an essential one. Before anything else, you should check all site pages for accurate and optimized titles and descriptions.
To do this, right-click on the reviewed page in Google Chrome and then select "View page source" in the drop-down menu.
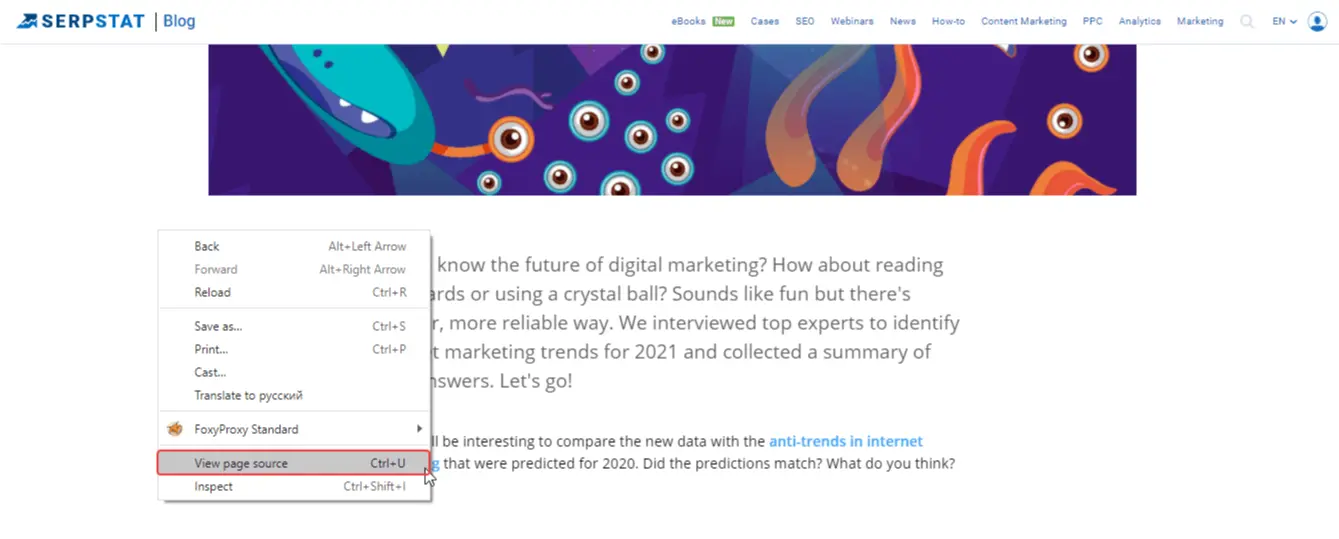
You can find the values you need in the page code.

As a more straightforward method, you can use a simple Google Chrome extension, SEO META. You can also check meta tags using the free Serpstat Website SEO Checker extension.
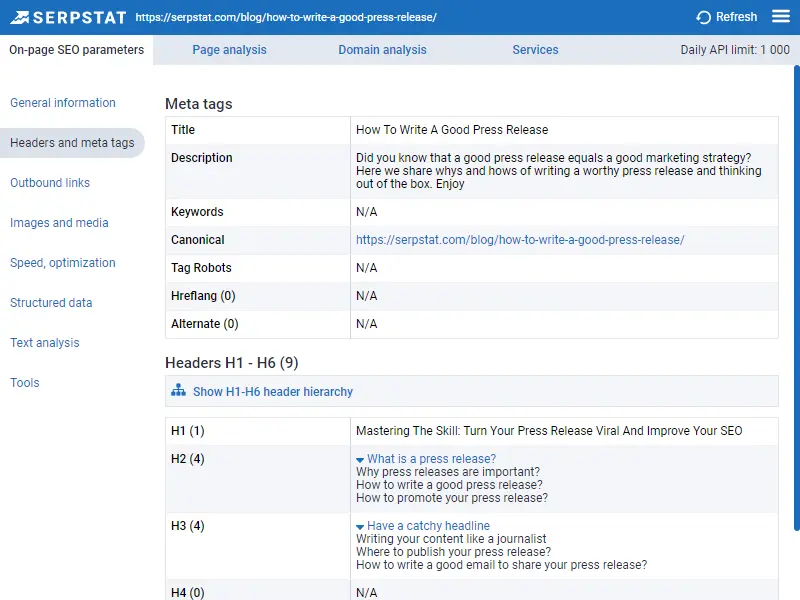
You can also use crawlers, for example, Netpeak Spider or Serpstat Audit, which allows you to get all errors in the meta tags and titles.
Title
There are many SEOs who deliberately write titles longer than 65 characters, giving robots one or two more keywords that humans cannot see. Still, robots perceive and skip into the ranking.
Recommendations for beginner SEOs on how to compose a title tag:
- The site pages' indexing depends on how the Title is created, so write about information/goods on the page as accurately and concisely as possible.
- In the Title, use the primary keyword (product name, service, type of activity); if this is an article, indicate what a person can discover by visiting your page.
- Avoid adjectives and quality keywords like "best phone" or "best hotel." Headlines like these often increase CTR, but robots often ignore them. So be careful!
- Do not write page titles like "The main page of the development company ...". Nobody cares that this is the site's home page.
- Do not copy the titles of your competitors. Your title should be unique and meaningful. Refrain from borrowing other optimizers' possible mistakes, and remember to constantly improve your site.
- Use regular and special characters sparingly. Search engines themselves will try to remove or replace them. For example, if you compose the title "Promotion!!! Mass sale and credit at 0%," the search engine will remove unnecessary signs or alter the Title at its discretion.
- Don't spam with keywords. One page — one keyword. There is no need to list everything possible. The robot and people will not understand what is on the page. Use keywords in content.
Description
Different search engines have different optimal lengths for this meta tag. Usually, there are about 320 characters in Google snippets. Also, search engines are replacing the tags with the relevant information found on the page. So, descriptions' importance in optimization could be less significant.
Recommendations for beginner SEOs on making Description attributes:
- Your page descriptions should be meaningful and engaging.
- Use icons and special symbols to be quickly noticed.
- It is advisable to use the main page keyword in the first sentence. Refrain from filling your descriptions with promotional offers alone; they rank poorly.
- Do not copy text fragments into the description; the robot can do it for you.
- Do not copy competitors’ descriptions.
Although robots consider the description attribute in ranking poorly, you should pay attention to it. It boosts CTR as well. Stick to the optimal length. If a page contains a lot of information, provide a clear description and direct visitors to the page for more details.
Optimizing website loading speed for desktop
To improve the speed of loading the site on computers, you can use the following methods:
- Image compressing
- Compressing pages in zip or gzip
- Using WebP images
- Lazy Load
- Caching
- Reducing CSS and JavaScript.
Slow download speed is still typical, as speed optimization on medium to large projects can be challenging. Creating new types of documents (for example, tag pages) often requires database queries not provided at the design stage.
To speed up, it is necessary to perform complex work, testing all kinds of pages using various tools. Sometimes, SEOs limit themselves to checking the home page in Page Speed Insights. Of course, more effort is needed.
Optimizing website loading speed for mobile
For mobile devices, in addition to the methods used in the PC, optimizers used Google Accelerated Pages (AMP). In 2023, AMP pages will no longer be served via the Google domain.
Due to improvements in mobile page speeds and user experience, AMPs have become unnecessary. As Google updates its algorithm and prioritizes different ranking factors, accelerated mobile pages may become obsolete.
You can use this tool to check if a page has an AMP version.
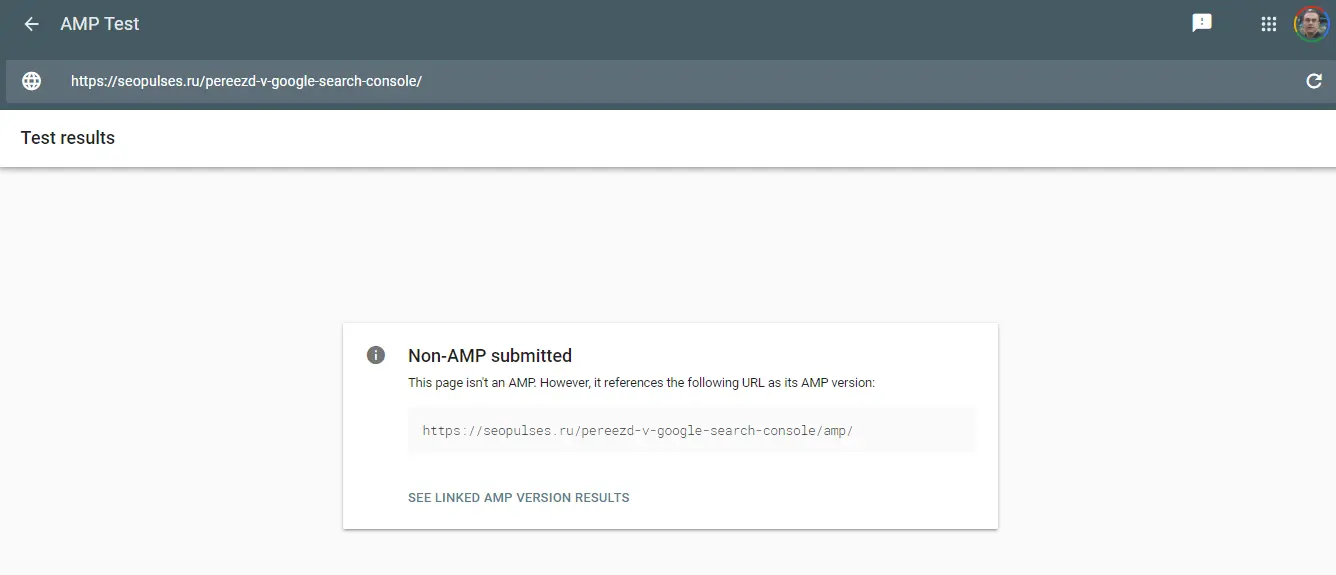
404 error page
The presence of broken links on the site must be regularly checked, and this can be done using various tools, for example,
- Serpstat
- Screaming Frog
- Netpeak Spider
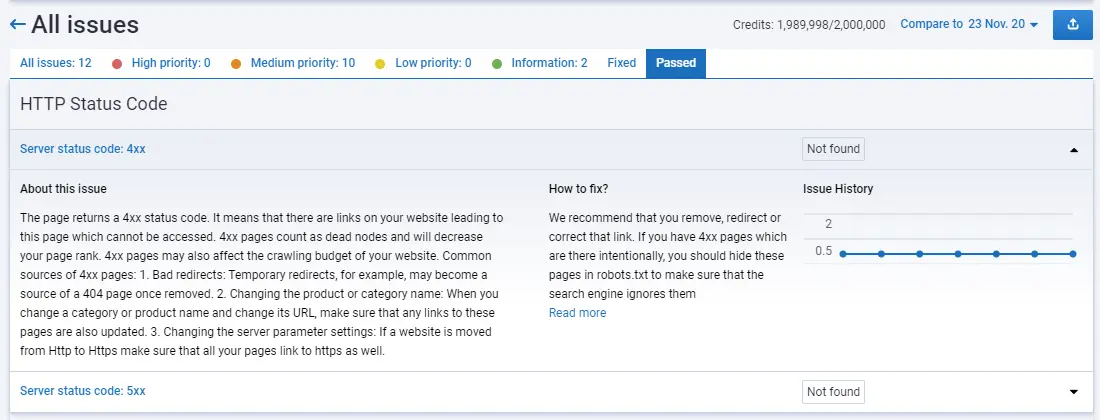
If only a few pages return such server response code, there is nothing wrong with that, but as soon as they start to expand, it is necessary to fix this technical problem urgently. Otherwise, it will lead to poor indexing or losing credibility and, accordingly, position in search.
The search engine will define 404 and 500 similarly — the page does not exist. If there is a 503, it will come back later to see the changes, but if it stays for more than two days, it will also be evaluated as 404. Avoid 4xx and 5xx errors on the site unless you create them specifically for others' goals.
Optimizing images on the site (multimedia)
The main reason for slow loading on the promoted page is the images, so fixing them first will improve loading speed. You can also use Serpstat Audit to find large images.
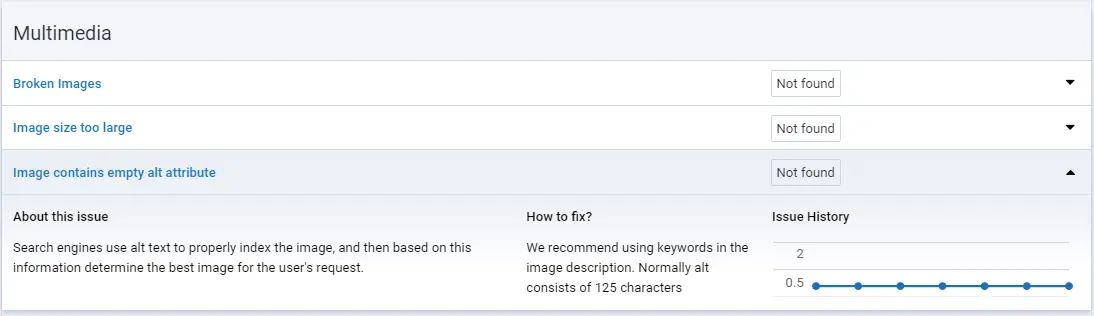
How to do a quick SEO audit of the site
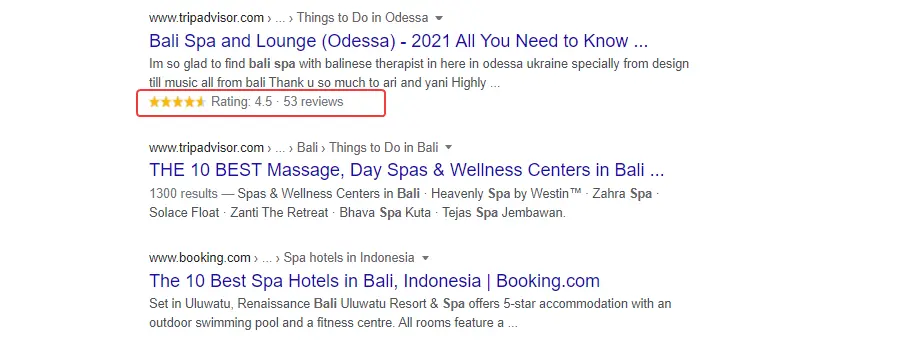
SERP features
Microdata allows you to highlight a site in the search results, for example, you can get a search line from the main page of the site. Or add a rating.
You can use a tool from Google to check the rich results on the pages.
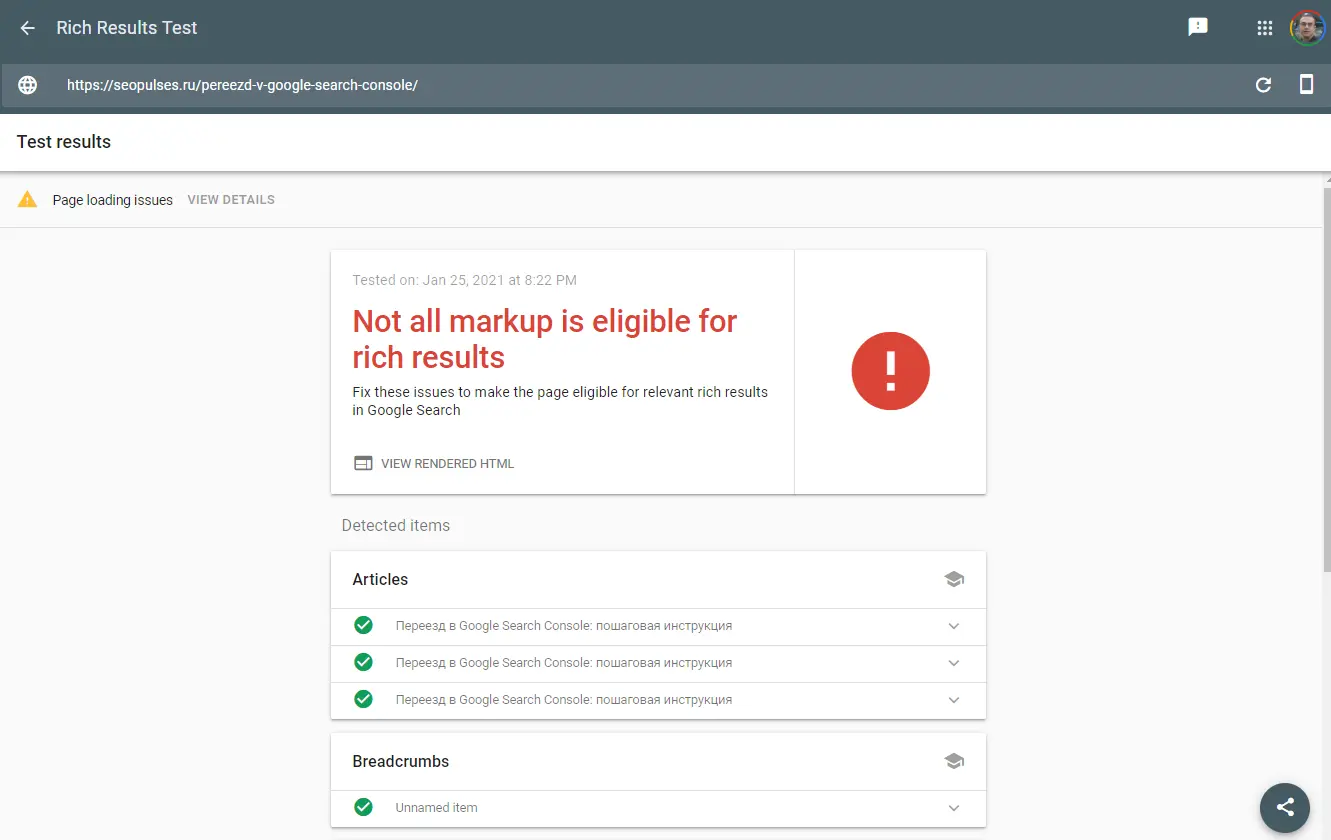
After checking and determining the error, you can troubleshoot and adjust to one of the schema.org formats. Use the Serpstat Checklist tool to make optimizing your site easier. There, you will find simple and understandable checklists for different work areas with the site, which you can adjust to suit your goals.
Backlink analysis
Growth dynamics
You can check the number of links and the dynamics of site growth via Serpstat Backlink Analysis tool, Overview:
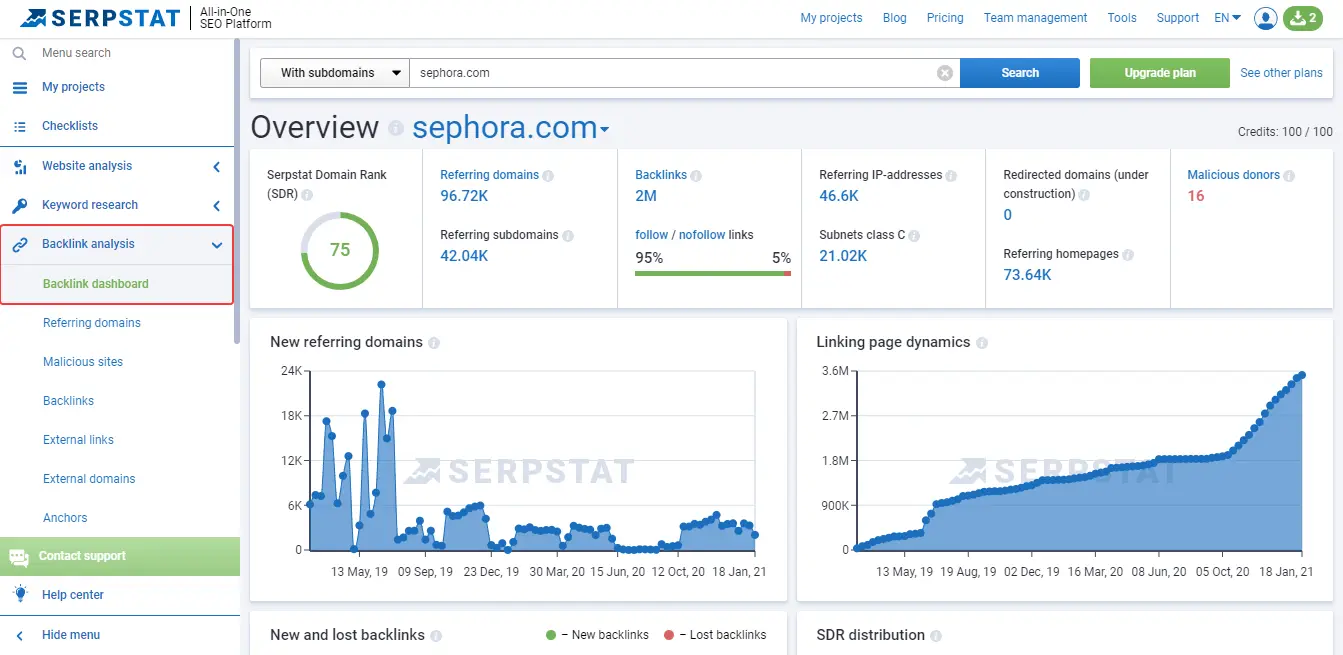
Natural links
Unfortunately, there is no exact way to automate determining naturalness. However, you can check link anchors through the Serpstat report "Backlink Anchors."
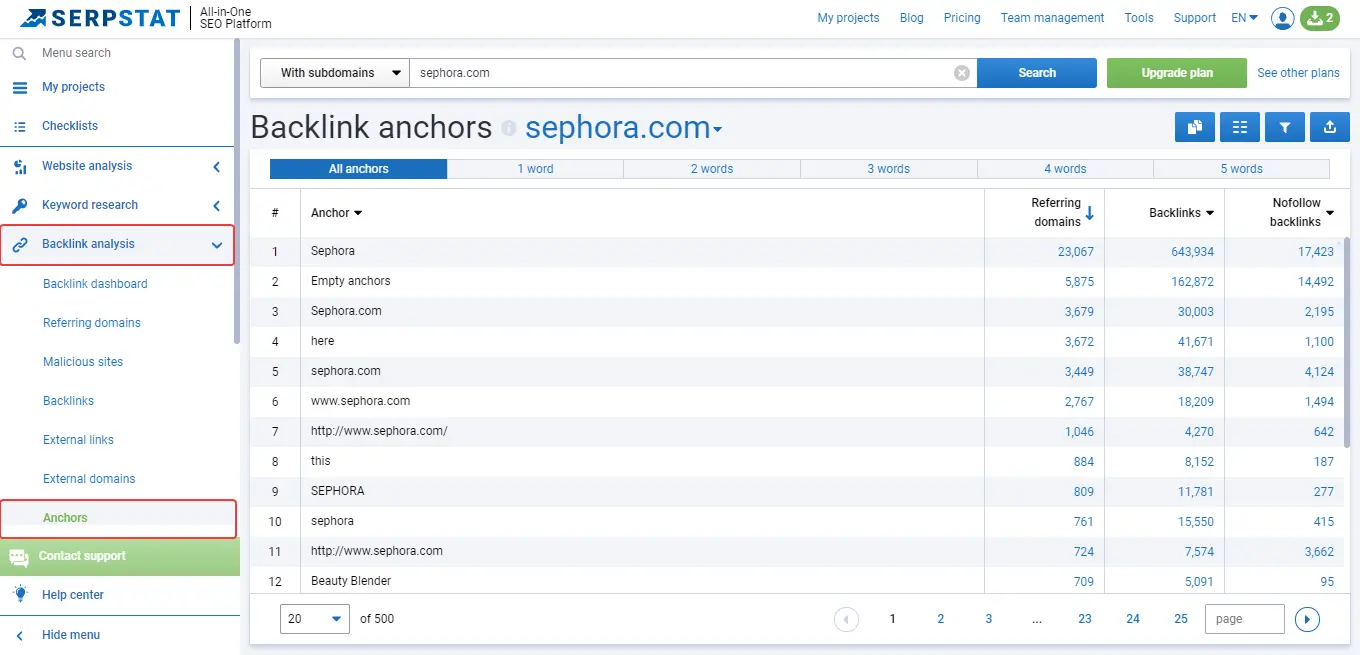
Then, evaluate the domains by Domain Rank (SDR). This indicator will help you understand how authoritative the site is.
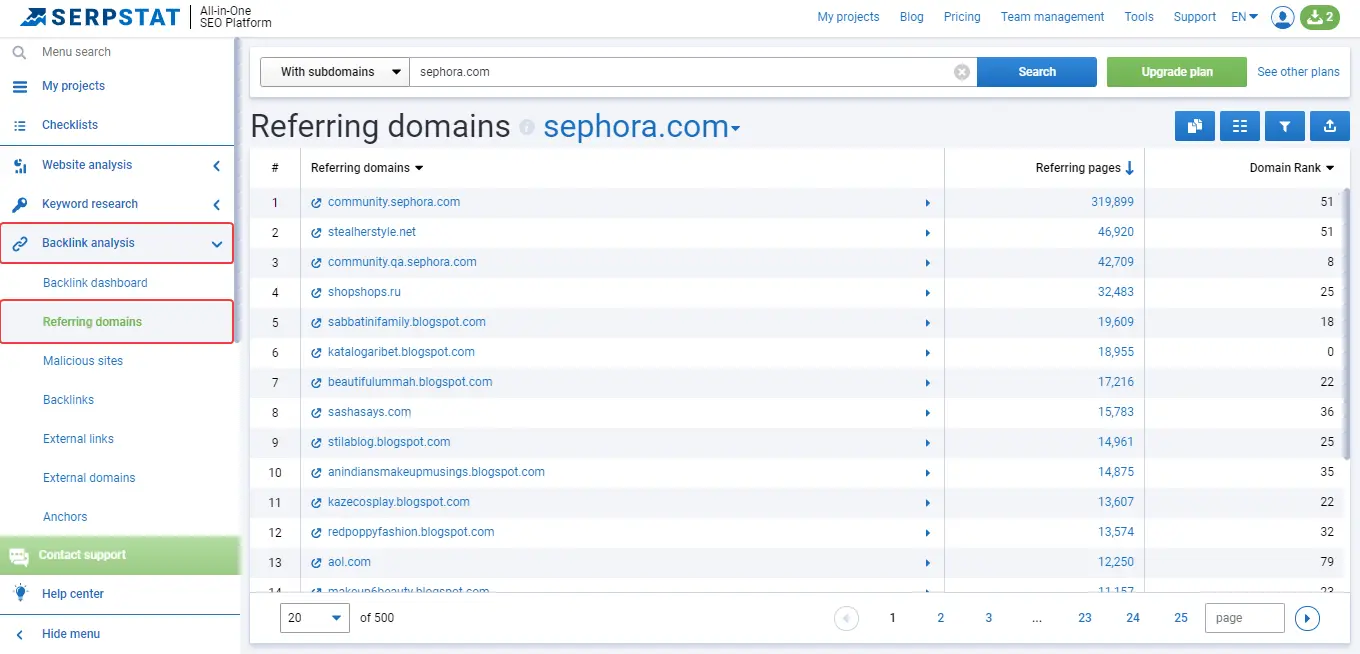
It is best to separately consider each link and its naturalness, for example, how concisely and unobtrusively the link is.
Link quality
To more accurately understand how the links correspond to the quality indicator, you should use a table to analyze all the links. You can also use the API to get the data. In the table itself, we should fill in:
- number;
- date of indexation/appearance;
- donor;
- acceptor;
- anchor;
- backlinks;
- donor page;
- acceptor page;
- traffic (can be obtained via Similarweb);
- trust;
- spam;
- external links.
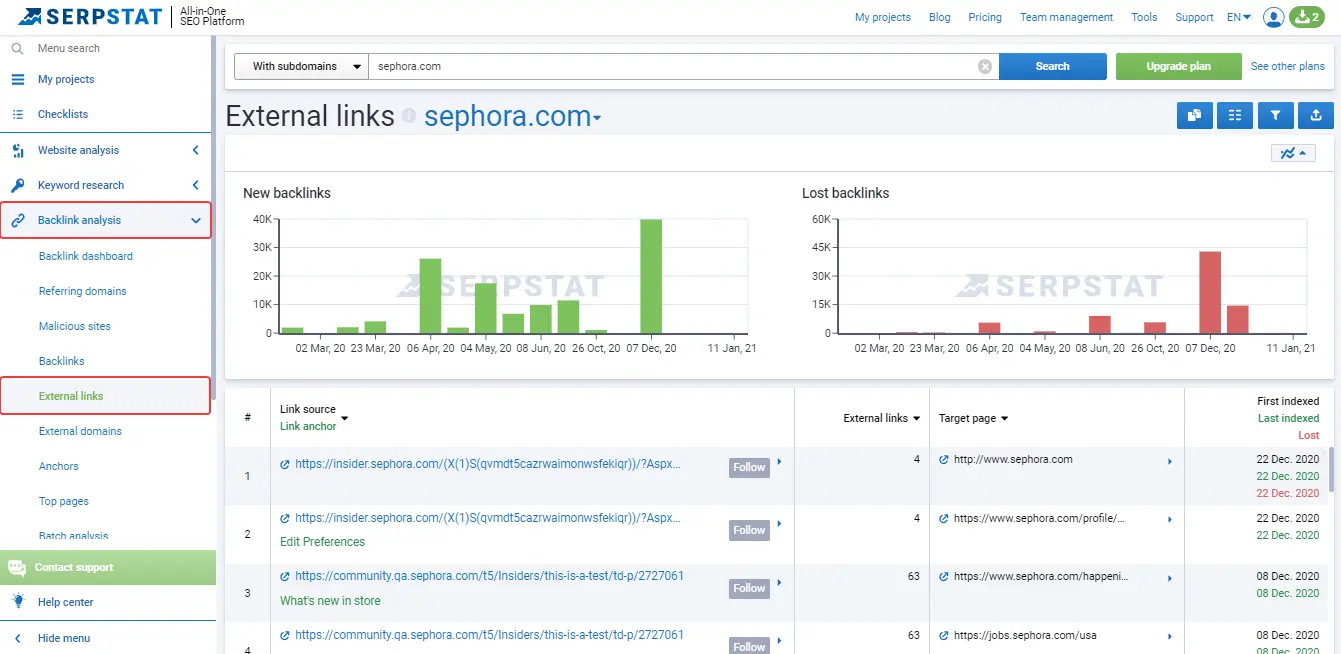
After that, you can already determine the quality indicators of each link or domain.
Spamming anchor list
You can also add an indicator for link type to the table (non-anchor, anchor, mixed). This link ratio is better to keep in mind:
- Anchor: 20%
- Non-anchor: 65%
- Mixed: 15%
Ty to get these proportions in the future when building the backlink profile.
Density and commercial analysis of anchor list
The task can be performed using the same Backlink Anchors report and table from above.
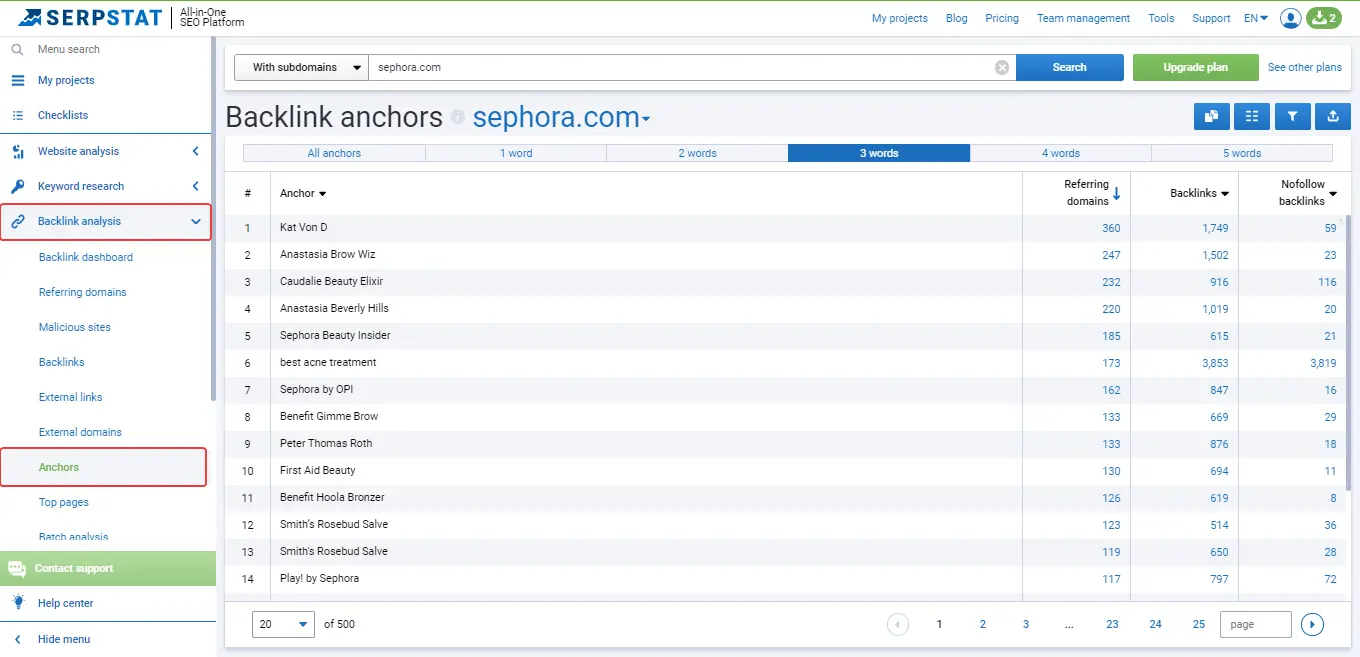
The link juice
Based on how many search queries a site can be promoted by and how many links already exist, it is possible to understand the approximate level of link growth, as well as to which URLs (landing pages) they should be directed.
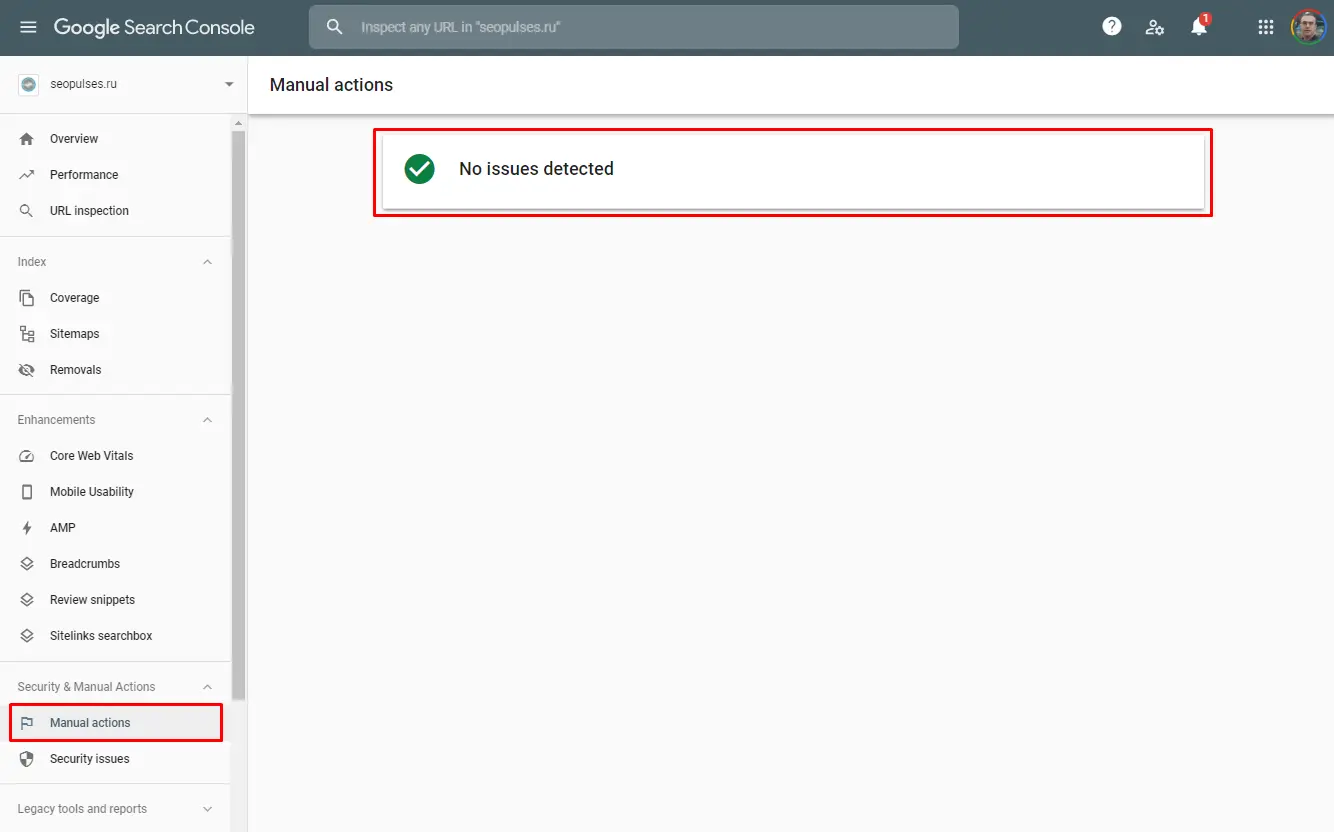
Checking for penalties by search engines, risk assessment
To check for penalties from search engines, just use the Google Search Console. You can see the issues in the Manual Action section.
Additional checks related to the specifics of the project
Before finalizing the report, it is recommended to revisit competitors' websites and consider the project's unique aspects relevant to the company's industry or its operations. In the second scenario, companies selling goods or services across multiple regions should consider promoting through subdomains or other methods.
It is possible to customize a website according to the specific needs of a business. For instance, websites related to design or construction may have a price calculator to provide clients with an estimated cost of services. This feature can also enhance the website's user engagement, encouraging visitors to stay on the site for a longer period of time.
Search for effective ways of project development
The first step is to make a plan. For example, it is best to approach these tasks initially:
Reporting and optimization plan
After completing all necessary analysis points, you can start drawing up a report on the audit results. You should understand that the final report should be as simple and understandable as possible so that even non-specialists can realize that there is an N series of problems and issues, and they will need X hours and a specific budget to fix them.
You also need to remember that the report may differ for different sites, not only in size but also in the content of some blocks, to eliminate existing errors.
It is necessary to indicate additional blocks in the report:
- SWOT analysis. Here, we show the strengths and weaknesses of the project.
- Analysis of competitors.
To ensure that everyone understands what needs to be done, it would be helpful to include a summary that lists the most significant mistakes, an assessment of the risks and conditions of the site, as well as the expected timeframe and required budget. This will help to provide a clear overview of the project's objectives and requirements.
To speed up the SEO reporting process, you can use custom reports in Serpstat.
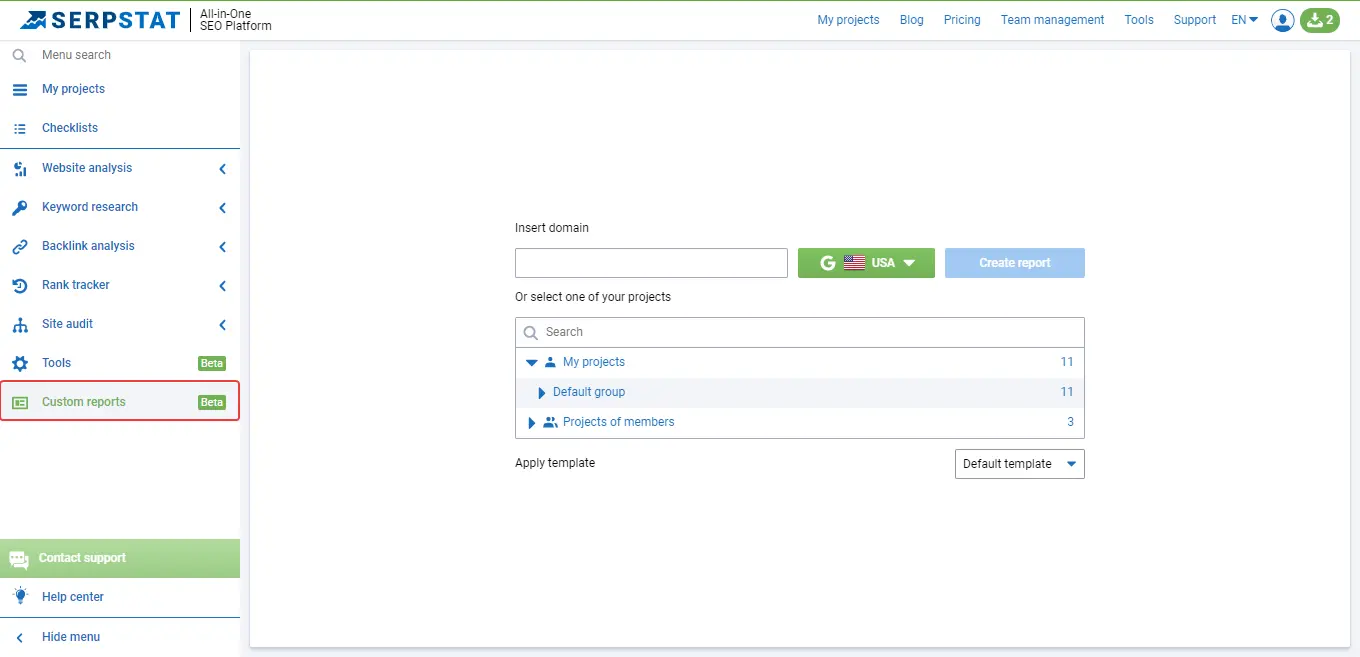
This will simplify the collection of statistics, make the data more accurate, and automate some of the processes.
Conclusion
In this article, we will outline key points for conducting a comprehensive website analysis that can be utilized for most websites.
It should be noted that no universal solution can be applied to all sites since each project's capacity, budget, and other features must be considered.
It is best to use a systematic approach and, after initially checking all the site factors, proceed to their solution to achieve the maximum result with minimum labor costs and then move on to more complex tasks.
FAQ
There’s no expected time frame. It can take 10 minutes up to a day, a week, or several months, depending on the size of your website, the depth of the analysis, the tool being used, the specialist(s) involved, etc.
An SEO Audit is essential for any website. It is important to conduct regular website maintenance, even when there are no apparent issues or performance problems. This should be done about once every six months. Here are the steps you should take:
It is a helpful tool that effectively analyzes your website and detects any technical issues that impact its search result performance.
Discover More SEO Tools
Backlink Cheсker
Backlinks checking for any site. Increase the power of your backlink profile
API for SEO
Search big data and get results using SEO API
Competitor Website Analytics
Complete analysis of competitors' websites for SEO and PPC
Keyword Rank Checker
Google Keyword Rankings Checker - gain valuable insights into your website's search engine rankings
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.