How to Group Keywords Automatically With the Keyword Clustering Tool

Eugenia Pisarenko
Customer Support & Education Specialist
at Serpstat
To compose the structure of a site correctly, distribute keywords for certain pages manually, draw up a content brief for writing articles to a copywriter, separate requests into commercial and informational — all these takes you a lot of time? Learn how the "Keyword clustering" tool can help you reduce spent time on these processes.
Before we jump into the topic, let us remind you about opportunities that Serpstat can propose to your business if you are looking to enhance site SEO:
- Keyword Research. Pick the right keywords for SEO and PPC campaigns that attract your audience.
- Keyword Clustering. Organize keywords by thematic similarity.
- Website SEO Audit. Find and fix on-site issues to boost your Google rankings.
- Keyword Rank Tracker. Track website positions.
- Backlink Checker. Increase the power of your backlink profile.
What Is Keyword Clustering?
Keyword clustering is the process of grouping keywords in such a way that keywords in the same group (or cluster) are relevant to a particular website page.
Let's say you have a list of keywords: iphone 6s, iphone 7, bmx, mountain bike, road bikes and macbook. Here is what you'll get after clusterization the following clusters: {iphone 6s, iphone 7}; {bmx, mountain bike, road bikes}; {macbook}.
Effective keywords clustering ensures better content targeting, streamlined website navigation, and improved SEO performance by organizing related keywords into actionable groups.
Why Do You Need Keyword Clustering
- grouping of the related keywords;
- automatic analysis of a keyword pool;
- collecting the right keywords for specific pages;
- keywords distribution across pages for a site's SEO structure;
- searching for website keywords that fall outside all obtained groups.



How Do Other Keyword Clustering Tools Work?
The most fundamental drawback of the majority of existing keyword clustering tools is that the clusters are formed based on the cluster's center — the keyword with the highest search volume. They find similar keywords which share SERPs results with it.
Keyword grouping software simplifies the process of segmenting keywords into clusters, providing advanced metrics and insights for more precise SEO planning.
Here are some problems of such method cases:
How Our Keyword Clustering Tool Works?
The aim of grouping keywords in Serpstat is to get clusters with the most semantically related keywords and not lose any of the keywords.
First 7 Days of Experience at No Cost
Start your exploration of the platform with Keyword clustering. Use the guide below to set up your project at ease.
Cancel any time.
Try for freeWhat Keyword Clustering Methods Does Serpstat Provide?
To group keywords for your needs you may select two major settings: strength and cluster type. The number of clusters and the keywords similarity depend on this choice.
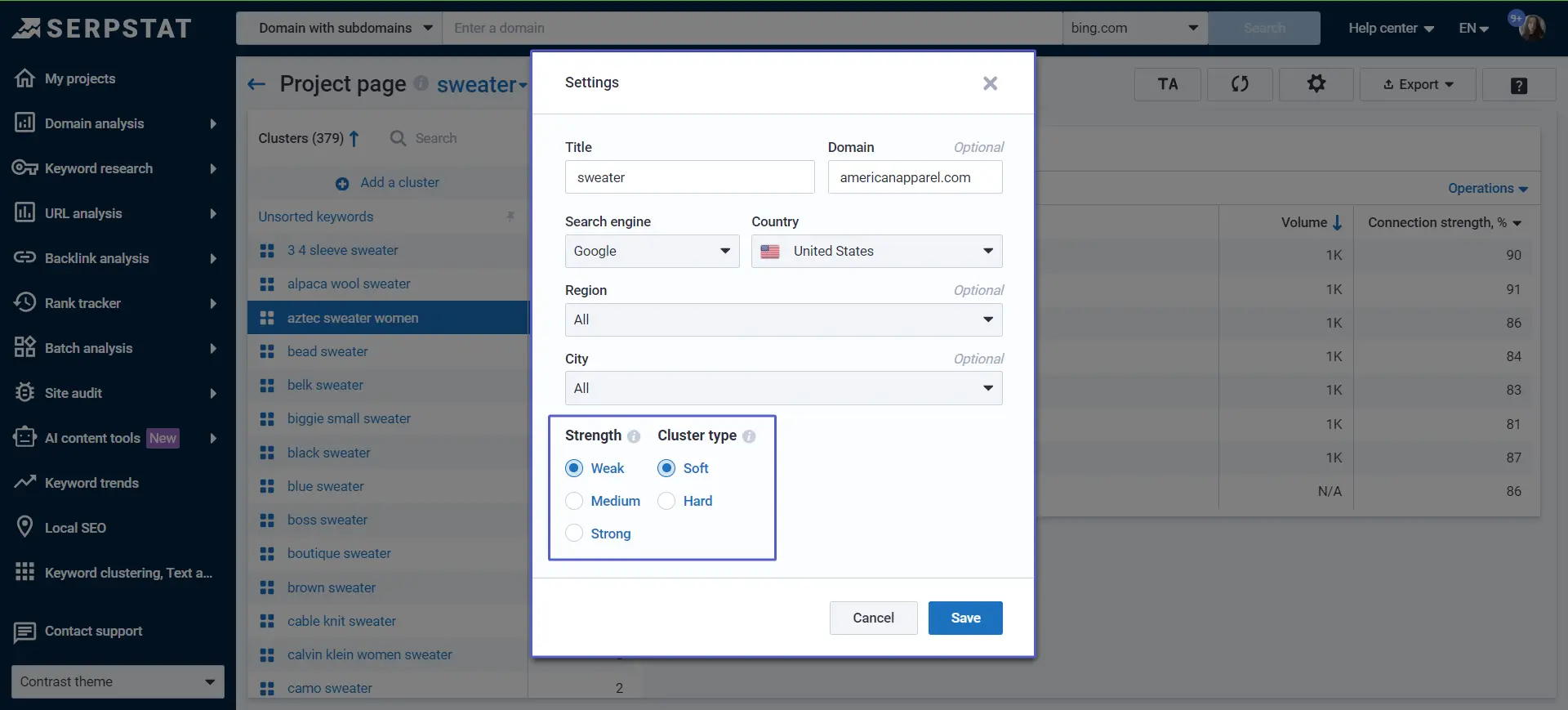
Strength
There are three types of strength — Weak/Medium/Strong.
Cluster Type
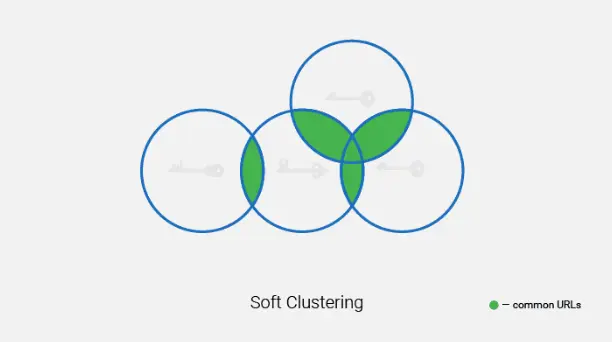
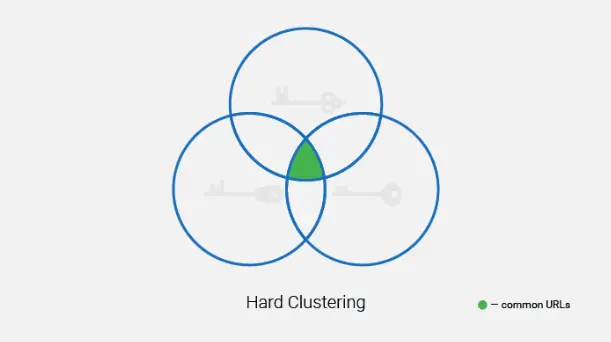
After clustering is finished, some keywords can fall into the " Unsorted keywords" directory. These are keywords that have no semantic similarity to the topic of the analyzed keyword set.
An alternative solution here is to create separate pages for these keywords or move them to one of the created clusters if you consider they belong there.
What Clustering Method to Choose?
You can choose any pairing of the settings according to your needs. The decision should be based on the semantic similarity of the objects from your dataset.
If keywords are initially closely related, for example, sneakers of different brands, you should choose "Strong"+"Strong" or "Strong"+"Weak" so that only the closest synonyms are combined into a cluster. As a result, you'll get lots of clusters to use for separate pages or specific categories.
In the case of various products and services, for example, you are collecting keywords for a multi-product store or medical center with a full range of health-care services, it's worth selecting "Weak"+"Weak".

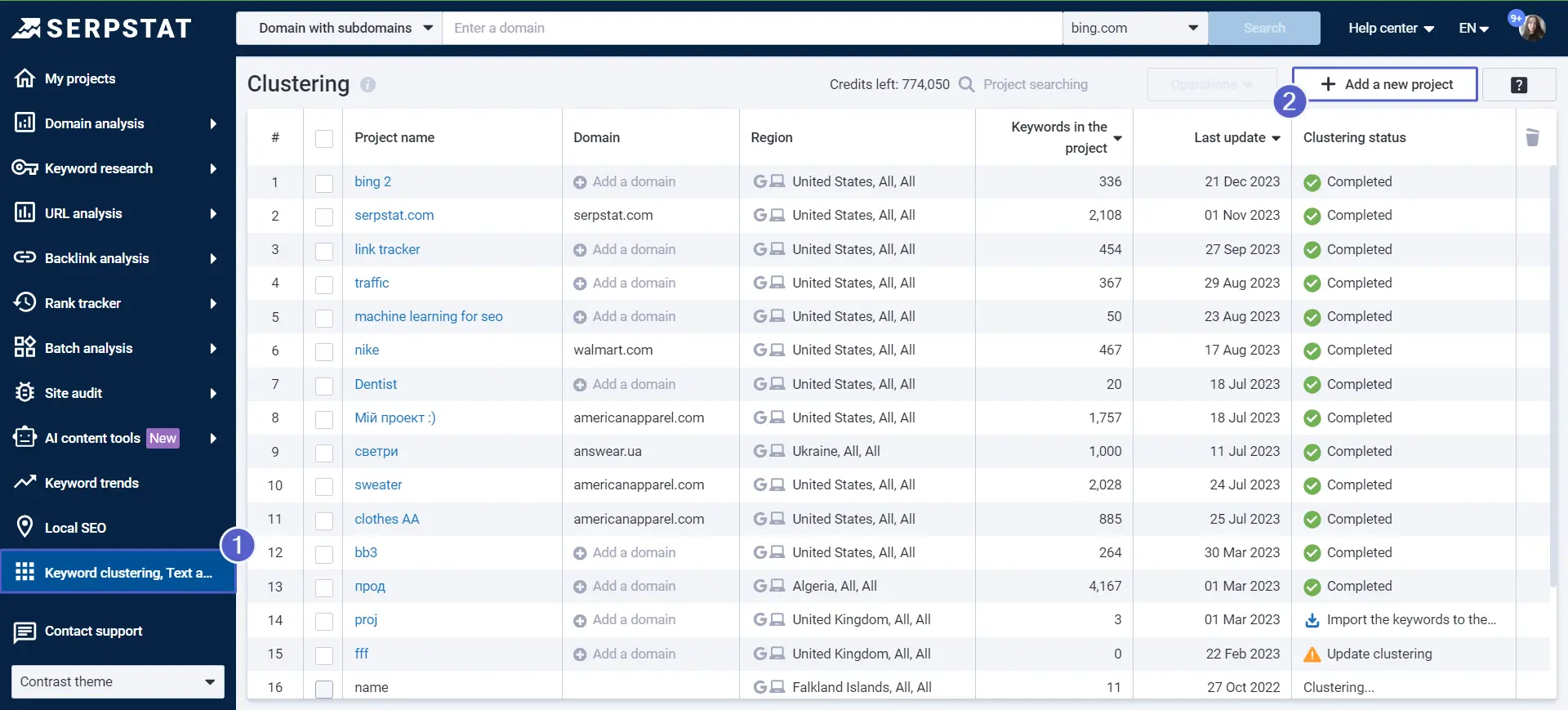
How to Use the "Keyword Clustering" Tool?
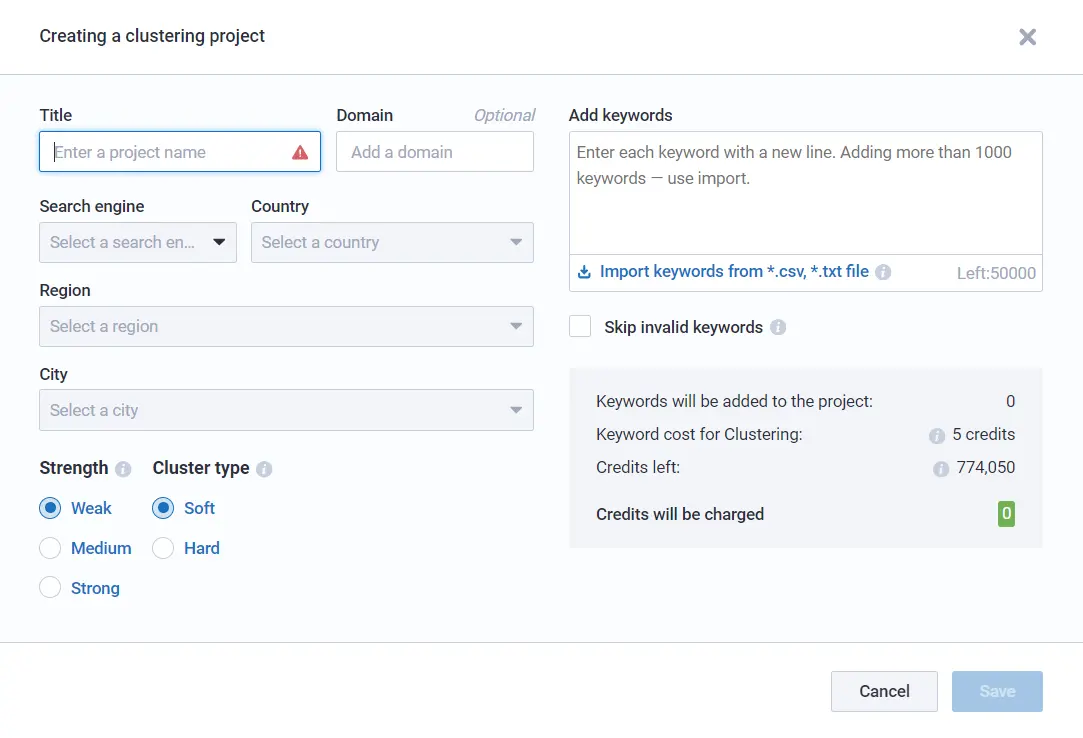
- Duplicates
- Special characters
- Search operators
- Spaces at the beginning or at the end
- Double spaces
- Digits as keywords
- Keywords longer than 80 characters
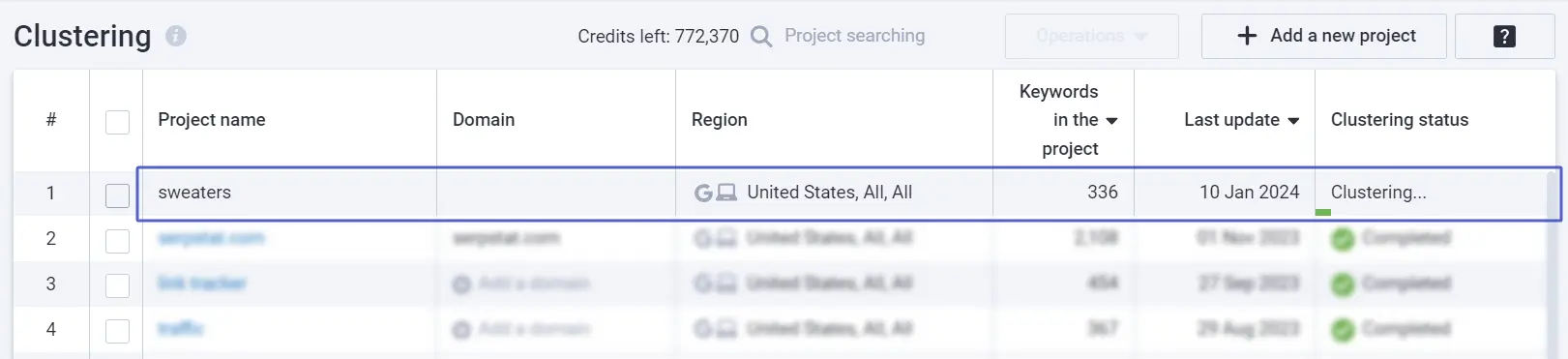
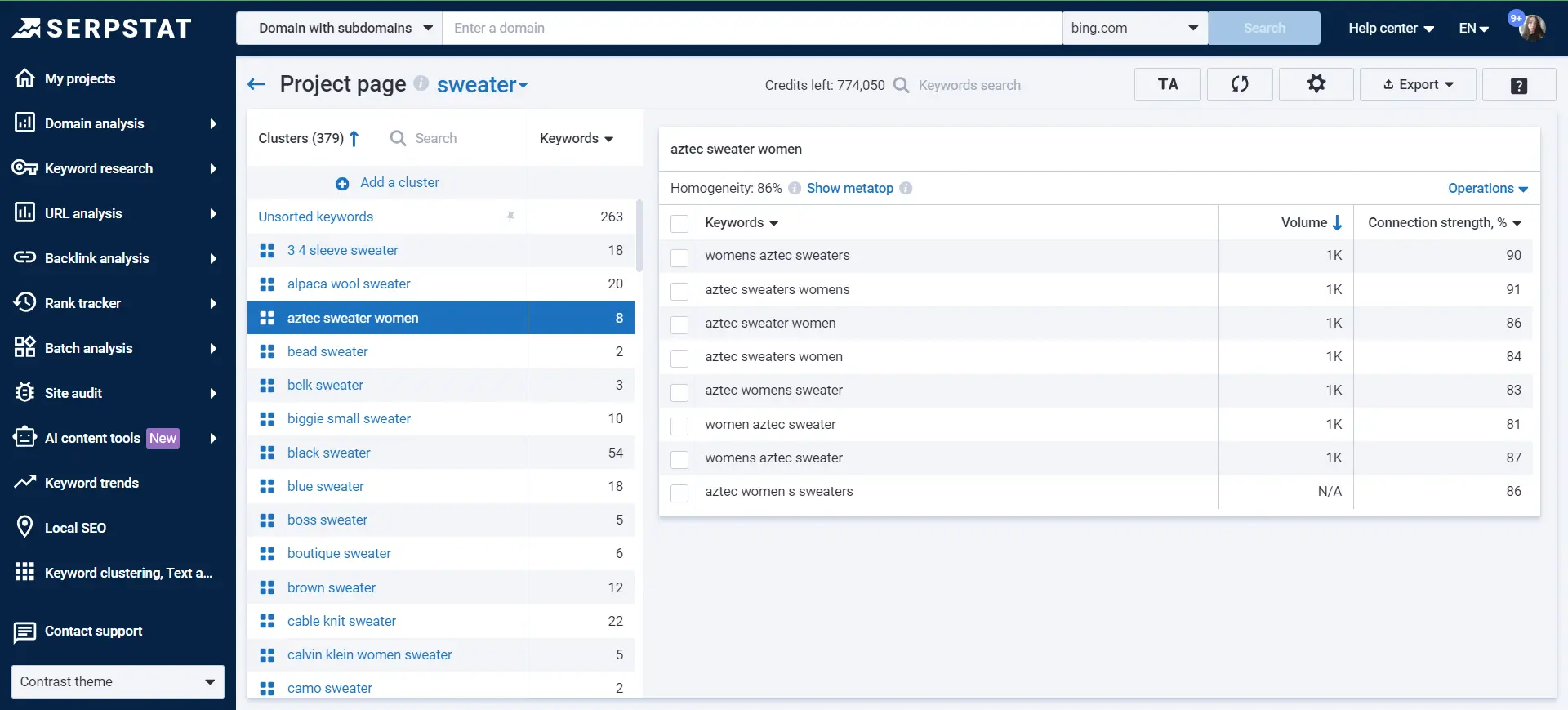
After the keyword clustering is done, the project will look like this:
Using a keyword grouping tool allows SEO specialists to efficiently organize large keyword datasets into meaningful clusters, saving time and ensuring optimized content strategies.
Now, let's look through all the indicators and figure out what it all means.
Project Navigation

In the left block, we see a list of clusters.
On the right block, you see all keywords within a selected cluster with additional information:
Tip : if you see that some keywords are irrelevant to the cluster or you would like to add more keywords to the specific cluster, move them around — use " Operations".
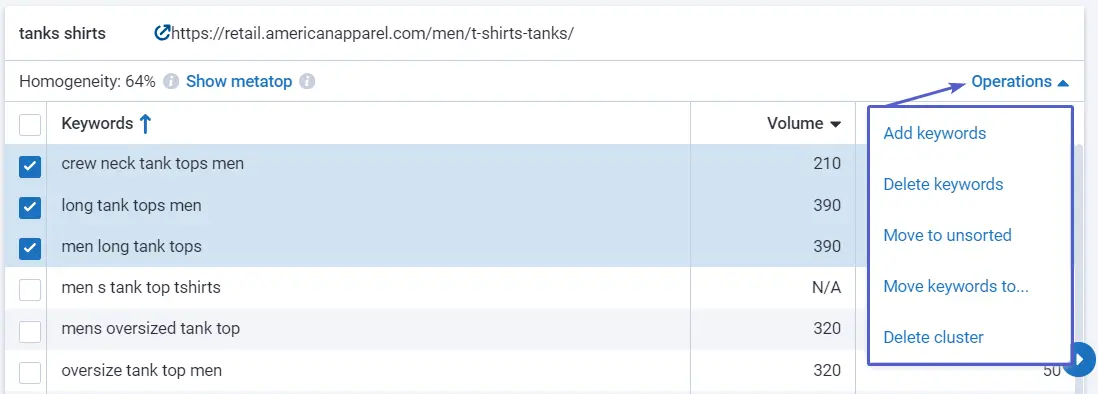
You'll also use buttons at the top:

Time to Try It Out Yourself!
Start a 7-day trial to test the Keyword clustering for free. Use this guide to help you along the way, and don't hesitate to contact our support team in case of any questions.
Cancel any time.
Get Your Free TrialVideo Tutorial
You may have a better perception of what keyword clustering is and how it works by watching the video.
How Are Credits Spent?
Number of keywords * 5 = the number of Tools credits spent when creating or updating a project.
Example: 300 keywords * 5 = 1,500 credits spent.
Credits are not spent when you change Strength and Cluster type only.
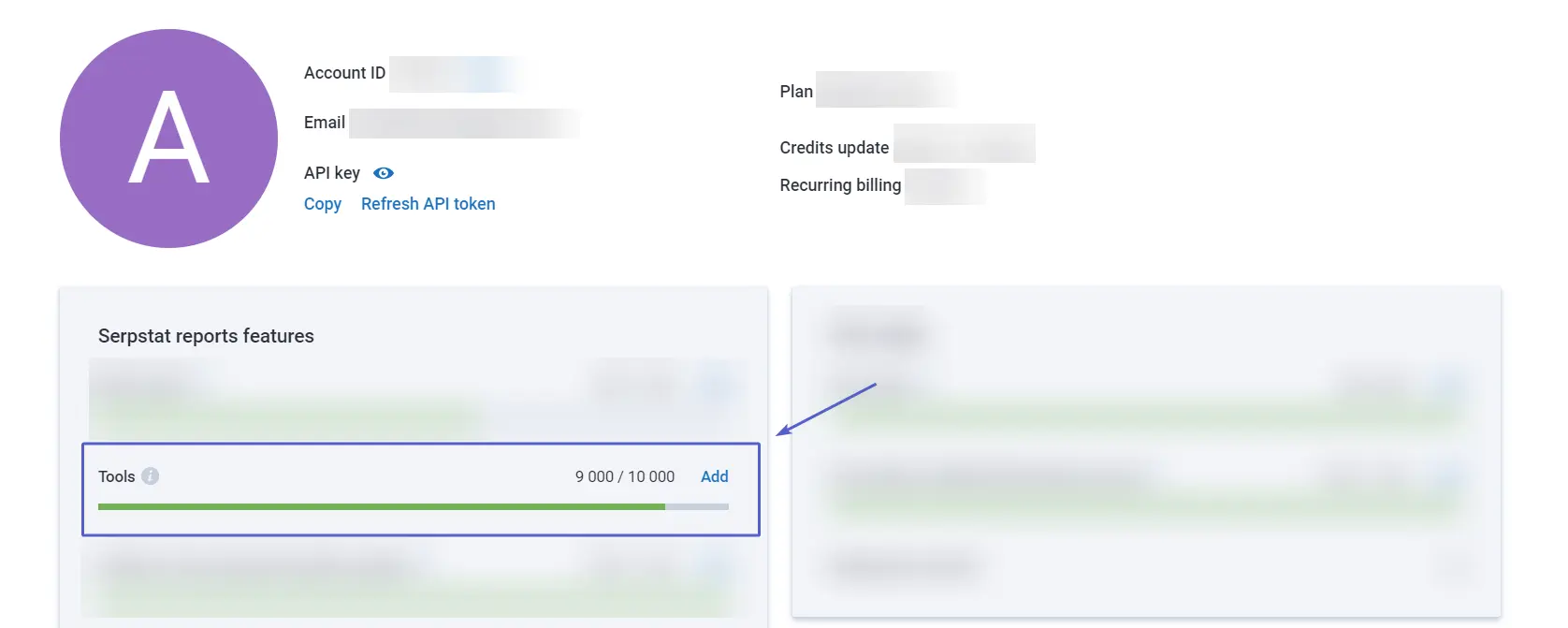
Check how many credits you have left in My account.
Use Cases
Keyword clustering may be used for different goals by different specialists: SEO specialists, blog editors, content writers, marketing analysts.
Based on formed clusters, you can:
- Create or improve a website structure.
- Create new landing pages.
- Create new website sections.
- Create new filters for e-commerce websites.
- Plan future blog content.
- Optimize product listings.
- Optimize titles and descriptions.
- Optimize contextual advertising.
- Analyze an industry, a niche, or a specific competitor.
FAQ
What is keyword grouping, and why is it important?
Keyword grouping is the process of organizing related keywords into specific categories or clusters. It improves SEO by helping structure content, ensuring relevance, and optimizing individual pages for specific topics.
How does semantic keyword grouping enhance SEO?
Semantic keyword grouping enhances SEO by organizing related keywords into meaningful clusters, allowing you to create more targeted and relevant content that aligns with user intent and improves search engine rankings.
Start Finding
Keyword Ideas
Sign up and try for free
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.