Start Exploring Keyword Ideas
Use Serpstat to find the best keywords for your website
The Importance Of Technical SEO: Insights Of Technical Issues Of Unibaby Project


2. Introducing the Unibaby SEO case
3. Analyzing sites for technical issues
4. Status code optimization and communication with search engine crawlers
4.1 Difference between 404 and 410 status code
4.2 From temporary to permanent redirect
4.3 URL typo correction and canonicalization
4.4 Index cleansing: removing duplicate and underperformed pages
4.5 Removing redirection chains (301 Inlinks) and 404 resources
5. Crawlability issues and wrong robots.txt rules
5.1 Uncertainty principle for search engines and ranking ecosystem
5.2 What we do for better crawling, rendering, and indexing
6. Conclusions and takeaways
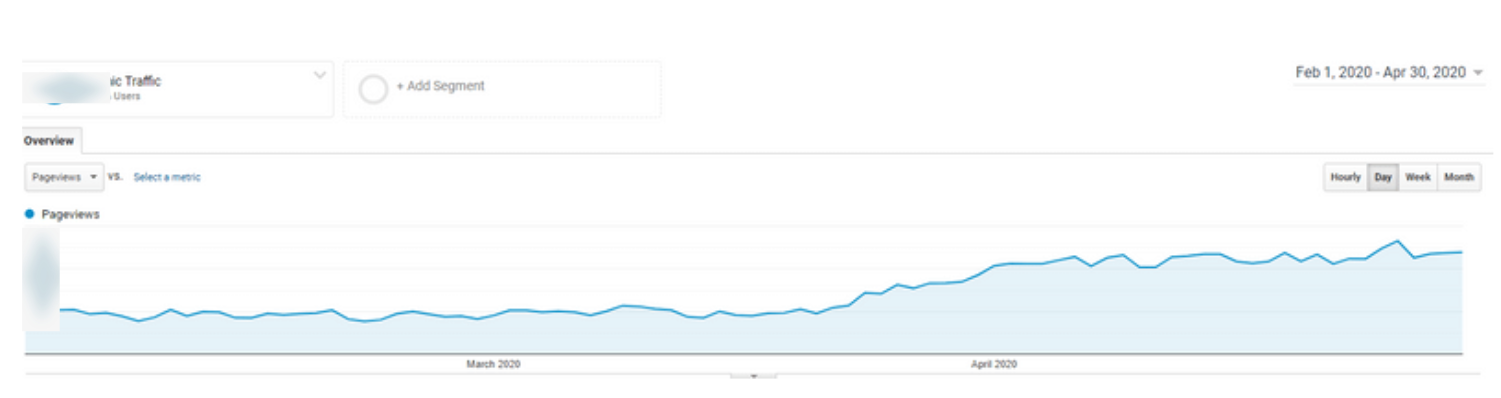
When I started working with the project, I saw that the brand's products were being searched all over the internet, but the brand was not recorded on Google's Knowledge Graph.
The second point to work on was the website page speed (which is still far from perfect because of the new deployments). The third thing appeared to be technical SEO and authoritative content marketing, focusing on the better page layout.
Specialists often carry out a site audit when the site is under the sanctions of search engines. In this case, an inspection allows you to find errors, fix them, and return your position.
It would be best if you also had an on-page SEO audit when everything is good with the project: traffic is growing, and positions are gradually increasing. You can further speed up the growth of the website by identifying and correcting technical issues.
You should perform a detailed site check before starting the work on site's SEO. It will help to find minor issues and severe problems so that the optimizer can safely work on other ranking factors and promote it.
Try Site Audit here:


Wrong status codes give false signals, and they create confusion for search engines and their algorithms. To create a search engine friendly web entity, you should ensure semantic, systematic, and consistent communication with search engine crawlers in every aspect of the digital environment.
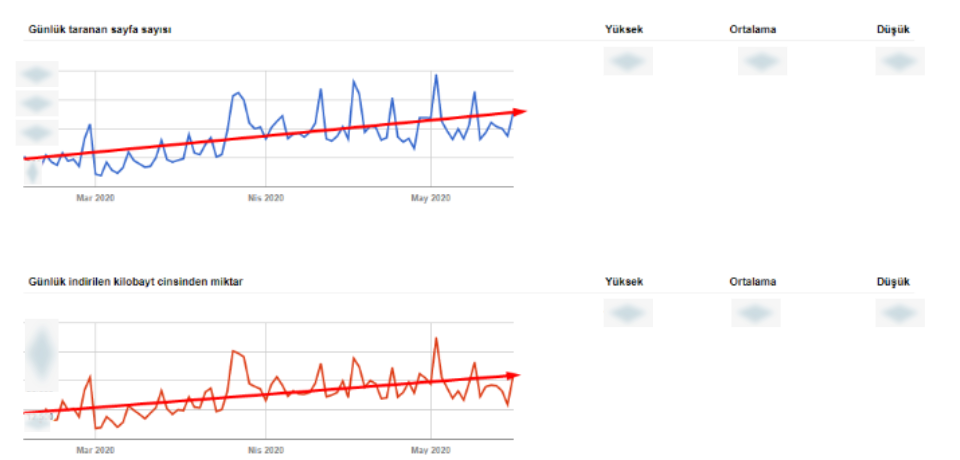
If you perform log analysis, you will probably see that search engine robots crawl lots of 404 URLs. You might delete a web page 5 years ago, but Googlebot has a long memory. It scrapes the web and creates more data for its search memory. It means that Google may not index your 404 web pages, but it will continue to crawl them with decreasing frequency to confirm that they are not available.
In Unibaby, I haven't performed log analysis, because the IT team didn't store the log files. But if you want to learn more about how 410 status code affects your log file profile, you may examine one of my previous SEO case studies. I have talked about keeping log files without letting server slowdown with IIS servers, and without a log file, we have changed the old web pages, resources, and other kinds of 404 errors to 410.
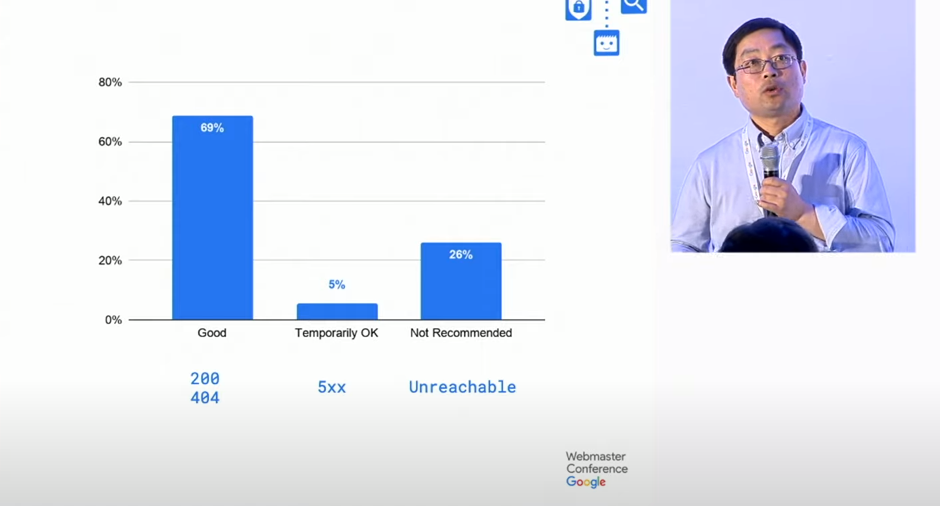
301 and 308 redirects are permanent. They have a definite meaning for the Googlebot. It means that an old resource is moved to another location, and you should stop crawling the old request. The difference between 301 and 308 is the HTTP method. In 301 permanent redirect, you may use every HTTP method for both of the redirection source and target. Still, with 308 redirects, you have to use the same HTTP method for both of the redirection sources and destinations.
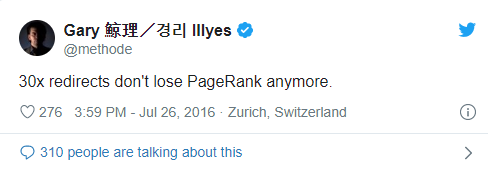
According to the Bing Webmaster Guideline, you shouldn't use a temporary redirection for more than 15 days. If your temporary redirects last longer than 15 days, it means that your methodology is wrong. For Google, we don't know the time limit, but improper redirection methods may still have different meanings and outputs in terms of crawl budget, PageRank calculation, and canonicalization.
Self-canonicalization is another crucial issue around URL typos. Every URL with a capitalized letter has a canonical URL for itself, which gives a wrong signal to Google. Canonical URL, sitemap URL, and hreflang URL should be consistent under the index and robots.txt rules.

Every blog web page had an exact duplicate example as well as self-canonicalization. We redirected the duplicate ones to the original resource.
We performed the same process for duplicate web pages.
- We removed more than 500 web pages from the index.
- We stopped the ranking signal division in duplicate pages.
- We improved our crawl efficiency.
- We also redirected some of the underperformed web pages by unifying them with the related ones.
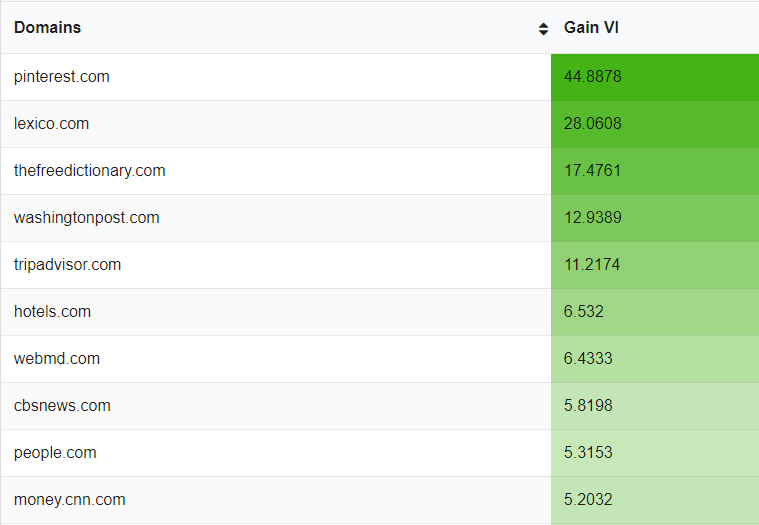
There were also other kinds of exact duplicate web pages because of the additional filters. For the different colors of the same product, we have different URLs while they don't even have any search demand. We reported on these kinds of duplications, but they couldn't be attended to before the May Core Algorithm Update.
We cleaned several redirect chains, old and missing resources, and deleted web pages' links from the source codes. I used Serpstat Site Audit to determine these errors.
On this project, I identified an issue with the robots.txt. When I fetched, downloaded, and rendered the homepage, I started to understand why there are paid services for only checking and automatically fixing robots.txt files. There was nothing on the robots.txt file.

The real problem here was with Unibaby's CDN address. Img-unibaby.mncdn.com address' robots.txt file was blocking Googlebot and other crawlers from checking Unibaby.com's CSS and JS assets.
They have also developed an algorithm hierarchy that works in harmony. The algorithm hierarchy decreased the cost and increased the effectiveness and speed of creating better SERP options.
In our example, Google didn't clean all domains from the index due to pure HTML content and design because the Uncertainty Principle gives Google Algorithms the ability to allow for gray areas.
In the old days, a bad design could have been a reason for deindexing, but now one of the baby algorithms of Google RankBrain Ecosystem can tell that this is not spam or bad design, it is a web developing error that shouldn't hurt the user.

That's the beauty of the hierarchy of algorithms and millions of baby algorithms of Google. The reasoning is always vital for SEO, especially when trying to interpret a secret ranking system.
About the CDN with problematic robots.txt file:
The development team had also copied all of the websites with the same content, images, links, and URL structure into the CDN. All of the duplicated sites were open to the index. So, Google encountered an exact match copy of Unibaby in its CDN address and indexed them for the same queries. Imagine if your CDN address is competing with you with the same content!
That's why I have told you about the Uncertainty Principle of search engines. What would you think if you saw this as a search engine? I always ask this question to myself, and that's why I always read about Google Patents and SEO case studies together.
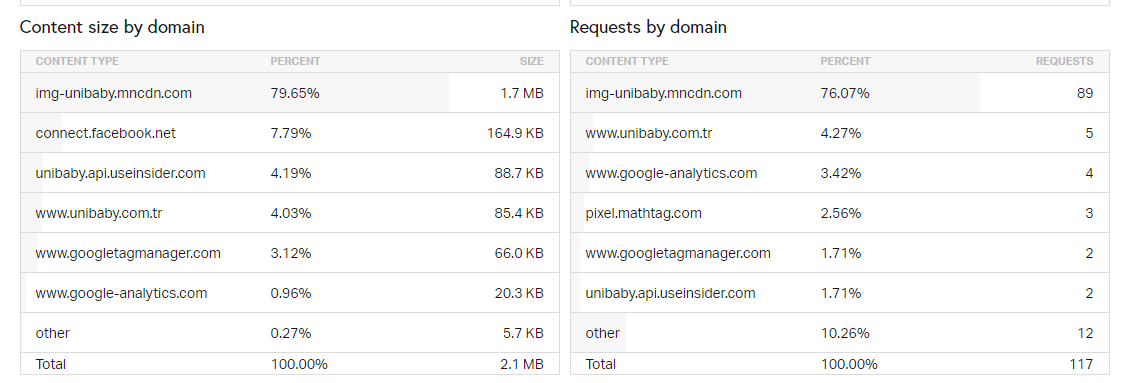
This is being called content clustering by Google. They collect similar or duplicate content to understand the source and determine the most influential brand for that content cluster. In this way, they also create a more efficient SERP with unique content and publishers.
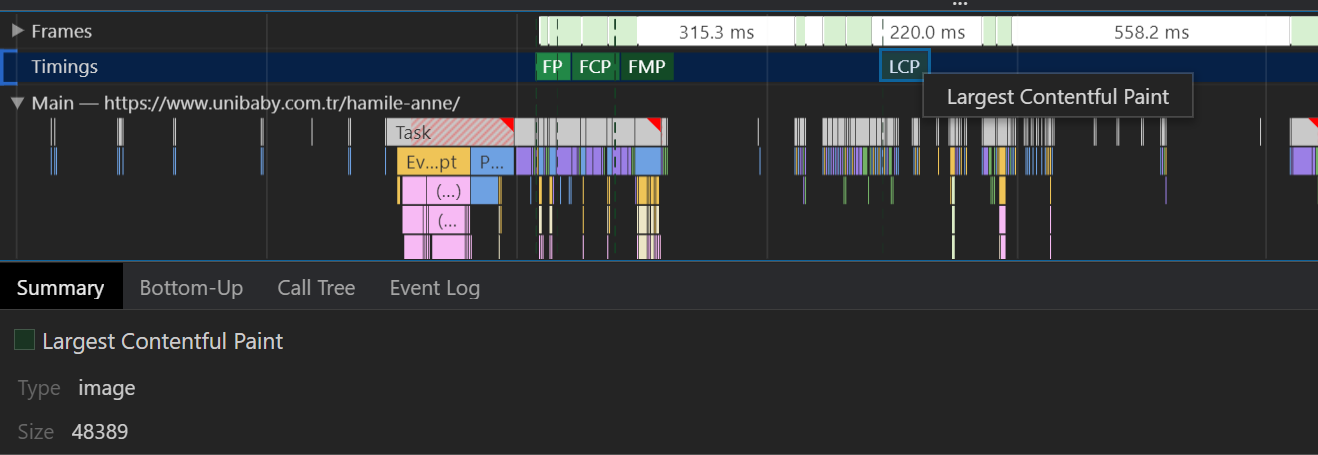
If your CDN address has links that point to you and duplicate content, Google might think you are doing this on purpose. Because of this situation, the CDN of Unibaby was taking impressions and clicks from the same queries with Unibaby.
Google chooses to show CDN addresses at search results, but it didn't give all the CDN ranking signals. Again, thinking in the gray area helped the Search Engine.
That's why the Uncertainty Principle is essential for the web. There are tons of different aspects of every page and situation.
After fixing the Robots.txt file, I tested with a mobile-friendly test and Google Search Console. The web pages have now returned to 2020 in terms of design and functionality.
We also deleted all of the exact match copy web pages from the Unibaby's CDN.
What would happen if Unibaby's CDN has all of the CSS and JS resources without blocking Googlebot, and Unibaby's main web page wouldn't have any of those? I wonder how Google's opinions would shape the same situation by its millions of baby algorithms in the hierarchy of algorithms.
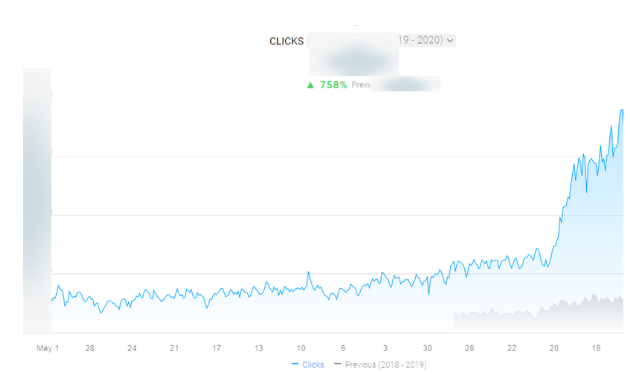
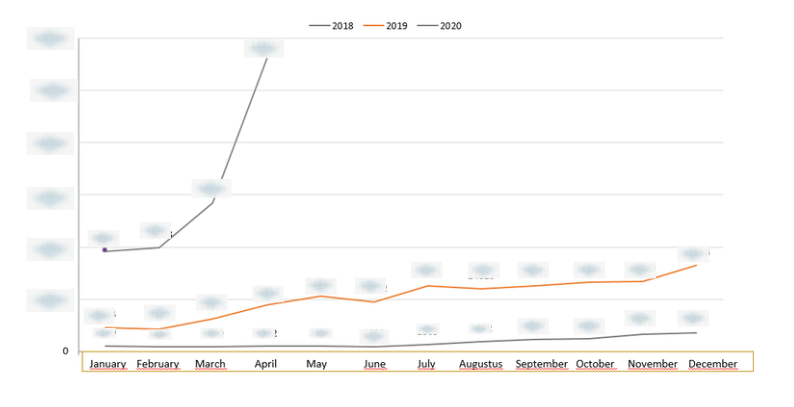
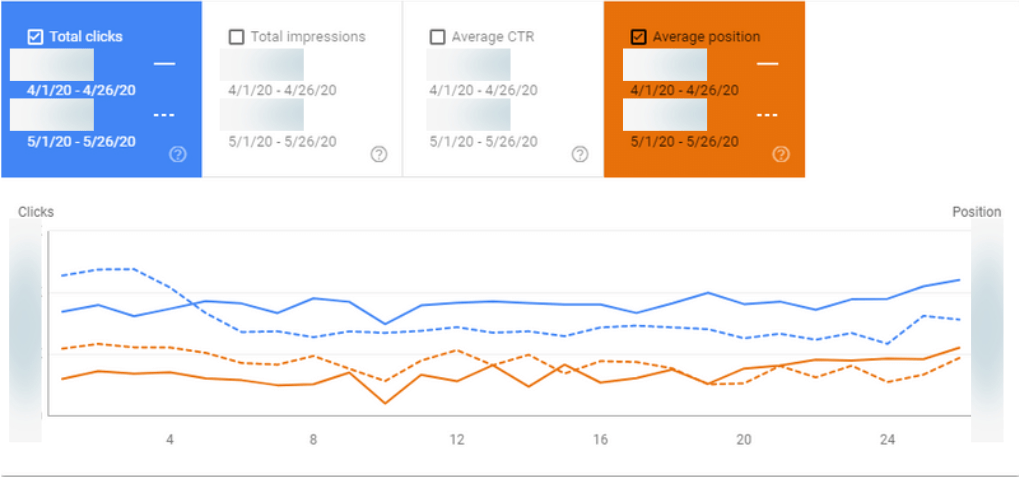
Design source: Databox, data source: Google Search Console
In the second article, many topics such as Page Speed optimization, User Experience, internal linking, site structure, semantic HTML usage, and PageRank distribution will be covered using the same perspective and attitude.
Speed up your search marketing growth with Serpstat!
Keyword and backlink opportunities, competitors' online strategy, daily rankings and SEO-related issues.
A pack of tools for reducing your time on SEO tasks.
Discover More SEO Tools
Backlink Cheсker
Backlinks checking for any site. Increase the power of your backlink profile
API for SEO
Search big data and get results using SEO API
Competitor Website Analytics
Complete analysis of competitors' websites for SEO and PPC
Keyword Rank Checker
Google Keyword Rankings Checker - gain valuable insights into your website's search engine rankings
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.