Start Exploring Keyword Ideas
Use Serpstat to find the best keywords for your website
How To Identify And Fix Duplicate Content Issues With SEO Tools


If you’ve had problems getting your site to rank for a particular keyword, it might be because search bots detect duplicate content, causing you to rank lower on search engines like Google. In this article, you’ll learn how to fix these issues.
Why Does Ranking Lower Matter?
What Causes Duplicate Content?
How To Fix Duplicate Content Issues
- Find Duplicate Content On Your Website Via Serpstat
- Use a Plagiarism Checker
- Paraphrase Your Content
- Use A 301 Redirect
- Use Rel="canonical"
- Meta Robots Noindex
Conclusion
What is Duplicate Content?
When you have duplicate content on your website, you don’t get penalized for it. But it does confuse the part of a search engine’s crawling mechanisms. That’s because they see two pieces of content that are exactly alike and can’t decide which one to rank for a particular keyword.
As a result, you nor the duplicate website don’t get the count on that piece of content. This doesn’t only occur with websites where strings of phrases might be similar. It also occurs when content is “appreciably similar,” as Google would call it. In cases like this, the content sounds much alike except for a few synonyms here and there. These occasions can still confuse crawl bots and cause your site to rank lower for specific strategic keywords.
So Why Does Ranking Lower Matter?
When you strategize your content to hit specific keywords, you’ll end up higher on search results, getting you more eyeballs and clicks to your page. Naturally, people will click on the highest results in search. So the higher you go, the more visitors your website, blogs, and other content pieces will get.
Duplicate content prevents this from happening. In effect, that lowers the number of organic visitors you get through search engines. About 93% of all search traffic comes via a search engine, meaning you lose a lot of potential by ranking lower for keywords.
You can track your website's positions in search results via Serpstat Rank Tracker, learn more about it in the following article:
Serpstat Rank Tracker: A Complete Guide
What Causes Duplicate Content?
Using Article IDs as Identifiers
A search engine, however, uses a URL as a unique identifier for online content. So developers need to start matching identifiers that search engines use instead of what makes sense development-wise.
Session IDs
Each session gets a unique ID called the Session ID. That content needs to be stored somewhere. Some systems might add the Session ID to the URL, giving each session ID the same content as the rest of your sessions. That results in duplicate content that confuses indexing bots and causes your page not to rank or lose ranking.
Tracking Parameters
The same goes for all tracking parameters you might use on your website. Those trackers cause multiple URLs for the same content, affecting your ranking on search engines.
Scrapers and Content Syndication
This problem usually occurs when your blog post or website starts getting popular. In cases like these, you need to ensure that scrapers are either linking back to you or restructuring the content instead of just copy-pasting them to your site. However, these two things are very often hard to control.
Comment Pagination
Printer-friendly pages
WWW vs. non-WWW
Filters and Sorting
Pages With And Without A Slash At The End
mysite.com/stores/
mysite.com/stores
Referral Link Duplicates
How To Fix Duplicate Content Issues
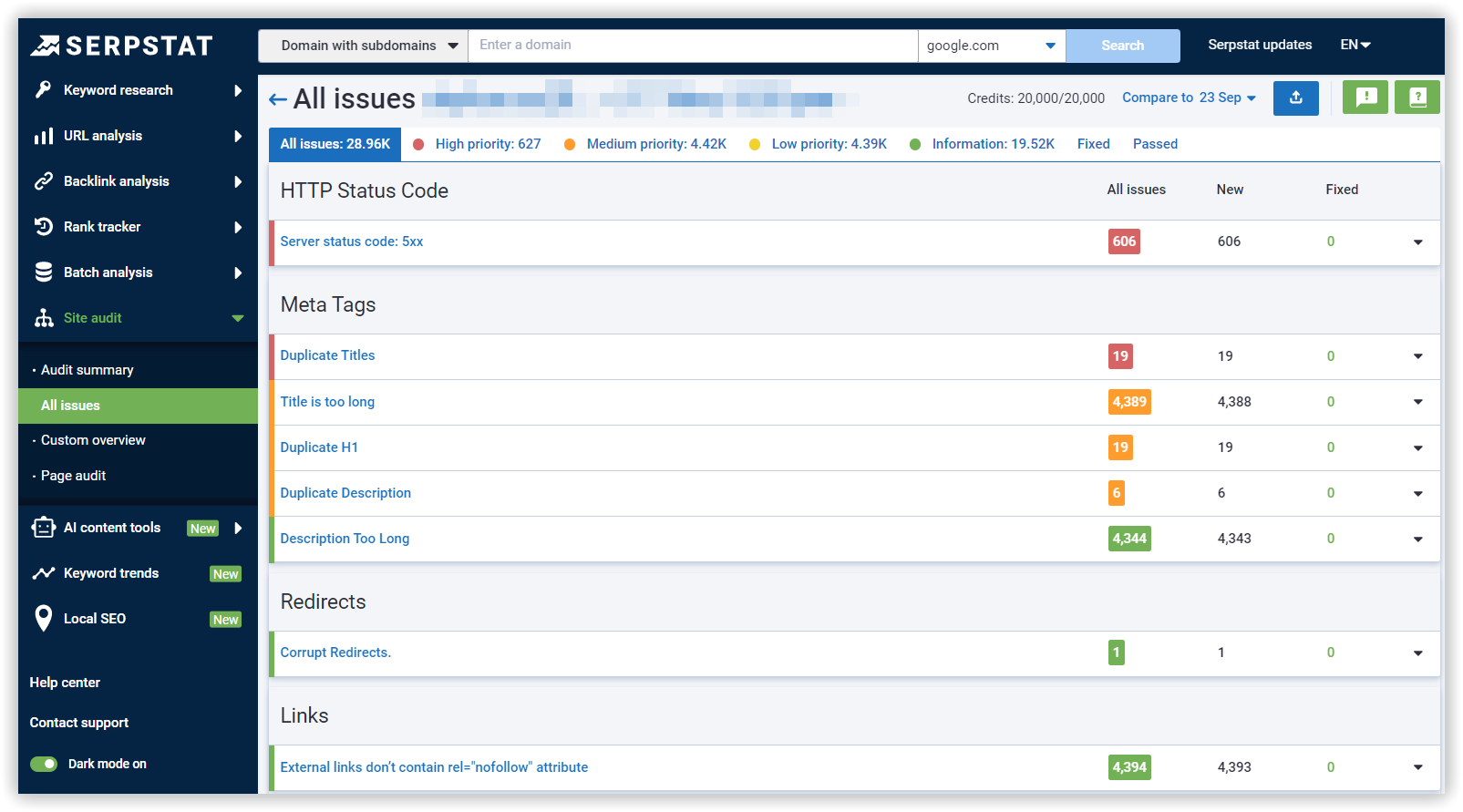
Find Duplicate Content On Your Website Via Serpstat
All you need to do is type in your domain name, customize the settings to your needs (number of pages to scan, scanning type, scanning speed, etc.), and click Start Audit. After the scanning is complete, you will see your website's Domain Health score (SDO) and the list of all technical issues on your website, including duplicate content:
Use a Plagiarism Checker
Once you spot copies, you can proceed to reach out to these other sites to add a backlink or paraphrase their content. You also have the option of paraphrasing your own content if you’d like.
You should also use plagiarism checkers when creating new content to ensure you’re not the one duplicating someone else’s content. Without it, you could be unknowingly creating a duplicate that will hurt your and someone else’s rankings.
How To Check Your Text For Plagiarism — Tips, Tricks and Tools To Avoid It
Paraphrase Your Content
When paraphrasing, try to use a keyword guide to ensure you’re still hitting the right keywords to help you rank better. The best SEO tools for content will guide you when making new content, so you don’t lose track of your search engine optimization goals. There are even AI tools that can automatically paraphrase content for you. But check the paraphrased version first to ensure the quality is still good.
How To Automate Content Creation And Paraphrasing With an Artificial Intelligence
Use A 301 Redirect
Adding a 301 redirect to a duplicate will combine tracking and crawling into one page. That way, your duplicate pages will stop competing with each other. Using a 301 could have a potentially constructive impact on your site because it improves relevance and popularity signals.
You can use an SEO tool to spot any of your pages competing with one another. You can add 301 redirects by either adding them through your domain’s htaccess file. If you’re using WordPress, you can also download a plugin that will handle your 301 redirects for your site.
Configuring Redirects On A Website: How To Avoid Mistakes
Use Rel="canonical"
Here’s an example of what that might look like in your HTML header:
<head><link href="URL OF ORIGINAL PAGE" rel="canonical" /></head>You can add the code through a WordPress plugin or edit it directly into your website’s header codes. Don’t do it yourself if you aren’t confident in your coding skills. You could end up ruining the whole website. Consider hiring a developer or SEO agent to take care of these steps for you.
How to use rel="canonical" tag for SEO
Meta Robots Noindex
This tag allows search engines to crawl a link but instructs them to keep from including those links in indices. That way, you don’t restrict crawls on a site, which is something that Google doesn’t like to see.
Here’s how a Meta Robots tag can go on your header:
<head><meta name="robots" content="noindex,follow"></head>Using CRM Software in Your SEO Efforts
Guest Blogging Management
Using a CRM tool’s pipeline, you can develop a funnel that allows you to track, follow up, and complete guest blogging initiatives so you have more active traffic coming to your website.
Link Insertion Opportunities
Reach out to Content Syndicators
If you want to use a CRM tool to help with SEO and link-building tasks, we recommend trying HubSpot. Check out this HubSpot CRM review to learn more about the tool and what it can do for you.
Conclusion
There are many reasons why duplicate content can appear, some of which we have listed in this article, and it's crucial to fix them promptly.
Speed up your search marketing growth with Serpstat!
Keyword and backlink opportunities, competitors' online strategy, daily rankings and SEO-related issues.
A pack of tools for reducing your time on SEO tasks.
Discover More SEO Tools
Backlink Cheсker
Backlinks checking for any site. Increase the power of your backlink profile
API for SEO
Search big data and get results using SEO API
Competitor Website Analytics
Complete analysis of competitors' websites for SEO and PPC
Keyword Rank Checker
Google Keyword Rankings Checker - gain valuable insights into your website's search engine rankings
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.