How to Fix Crawl Errors in Google Search Console
Crawl errors appear when the search engine cannot access the page of the website. This happens because of the errors in the server settings, CMS failures, changes in the URL structure, and other reasons. Errors can affect the website ranking in search results, as well as the users' attitude to the resource.
Before we jump into the topic, let us remind you about opportunities that Serpstat can propose to your business if you are looking to enhance site SEO:
- Keyword Research. Pick the right keywords for SEO and PPC campaigns that attract your audience.
- Keyword Clustering. Organize keywords by thematic similarity.
- Website SEO Audit. Find and fix on-site issues to boost your Google rankings.
- Competitor Analysis. Analyze competitors' sites in SEO and PPC strategy.
- AI Content Generation. Generate articles and meta tags.
Where to Check the Website Crawl?
The Google Search Console tools have everything you need to check your website. The console contains reports on web resource crawl statistics, a number of impressions and clicks, as well as average position in the search.
You may find errors in crawl reports. It also gives a brief explanation for the webmaster: reasons why they appeared and how to solve them.
Information in the Search Console is delayed. Therefore, it can display information about errors that have already been fixed several weeks ago.
In addition to consoles, it is necessary to check the website using other crawling and auditing methods.
Crawling Errors in the Search Console
Google divides errors into two types:
- site errors: appear if the bot cannot bypass the entire resource;
- URL errors: indicate an issue on separate pages.
The first should be fixed as quickly as possible: they affect the promotion process. If the website is not optimized, fixing these errors will have little effect on the ranking in search results.
Website Errors
This is how the webmaster panel looks like without errors:
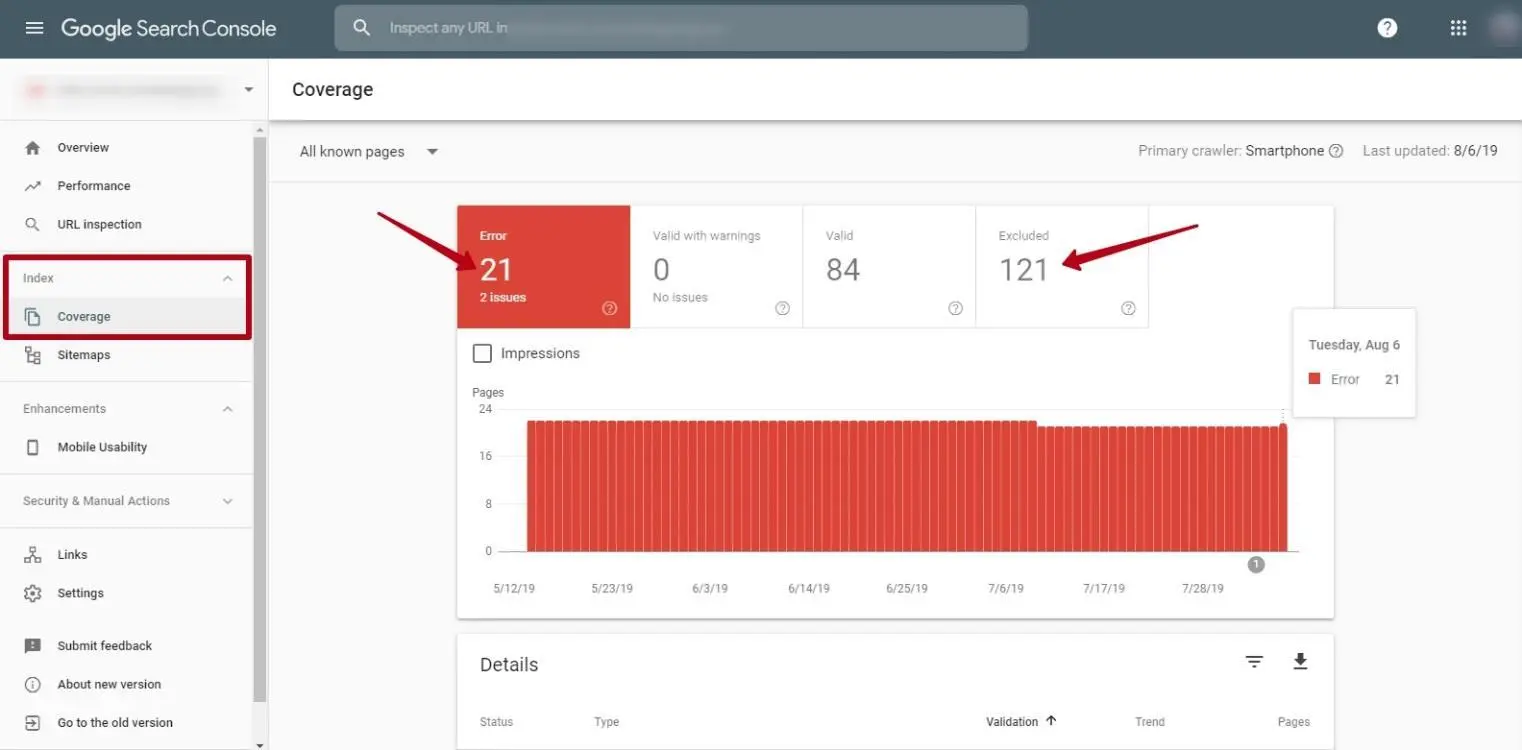
If there are problems, you will see blocks with details specified:
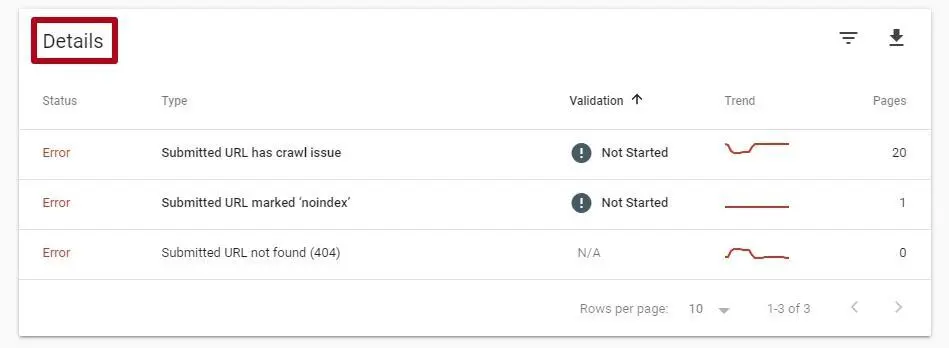
The screenshot below shows that Sitemap.xml is a URL that is blocked by the noindex tag. Just remove this tag to set up a crawl:
But errors appear for other reasons as well.
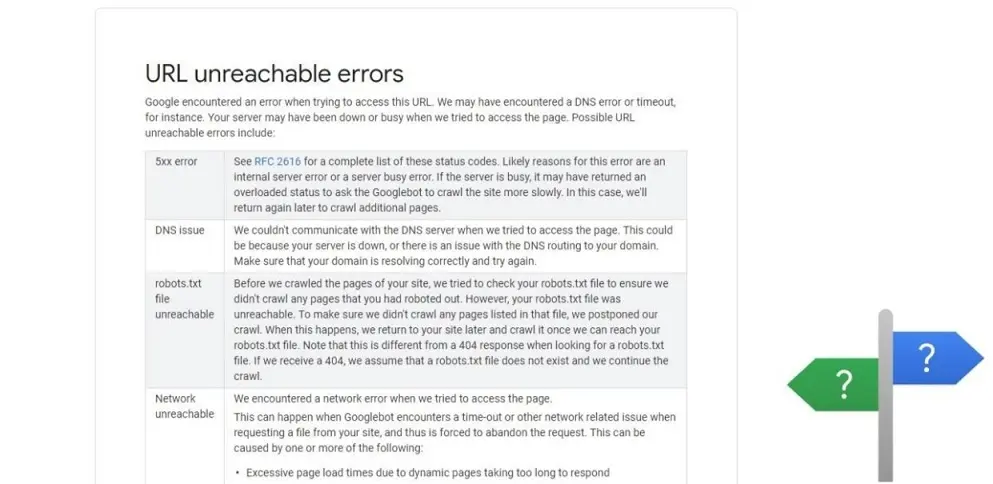
DNS Errors
DNS is a domain name system, which data is used by robots when visiting resources. If DNS errors occur, then the search engine cannot connect to the site, and users cannot find and open it.
Google doesn't report any error at once: it may return a couple of times, and if all attempts failed, it would display a message in the console.
Google developers say that most DNS errors don't affect promotion because they don't interfere with crawling. But they still should be fixed asap, otherwise, users may leave the website due to slow page loading.
How to fix DNS errors?
1) Contact the DNS provider through the hosting provider or DNS registrar and find out if there are any problems on their side.
2) Use the "View as Googlebot" tool: the crawl function will show that the website connection is normal. Currently, this function is available only in the old version of the console, but at the end of March 2019, Google will disable it, and it's still a secret whether it will remain in its current view.
3) See if the server gives HTTP 404 and 500 error codes via web-sniffer. Based on the results, fix the errors with the help of a developer.
4) Make sure the website is accessible to visitors. Use the downforeveryoneorjustme service. It helps to check the availability of the website, not only on your device.
5) Configure website availability monitoring through special services. This will help to receive notifications that the website is unavailable in any convenient way.
Want to get maximum profit from your website? Discover how LoudGrowth leveraged Serpstat to reach 20x revenue growth in 4 months.
Server Errors
Errors occur if the server takes a long time to process a request for information about a page from a search robot. The main reasons include:
1) Inappropriate server.
2) The server can be down from DDOS attacks.
3) The server may fail to cope if it's crawled by Google or someone using an auditor. See point 1 in the list.
4) Hosters can artificially limit the amount of processed traffic per month.
It is necessary to take a responsible approach when choosing a hosting provider; it must ensure uninterrupted operation in any situation.
Server errors also need to be fixed first. If the website is currently running (check through the Google crawler, which will be available until March 2019), and an error message appears in the console, it may have been detected earlier.
The webmaster's task is to make sure that the situation doesn't happen again. If the new version of the console does not introduce a similar tool, use crawler software. For example, Netpeak Spider.
What can happen?
- timeout: occurs if the connection timed out, error code 408;
- truncated headers: the robot connected, but didn't completely receive the server response headers, error code 304;
- connection reset: the request was processed by the server, but the bot didn't manage to get the result, error code 205;
- truncated response body: not completely received due to premature shutdown, error code 206;
- connection failure: occurs if the CDN or the content delivery network cannot connect to the web servers, error code 522. In other words, the computer cannot connect to the server;
- the lack of response means that the server or proxy server didn't receive a response from the upstream server to complete its request, error code 504;
- the timeout period expired: the robot cannot connect for the time period set by the system, error code 502. That is, the timeout period expired before the operation was completed. Either the server didn't respond, because the time elapsed before the connection was successful, or all connections have already been used.
The difference between this point and the first timeout is that it has connected to the host, but the desired result hasn't been received. This is not a connection issue: it can be both in the request and in the host itself.

When displaying these errors, check through the Google crawler in the console whether the search engine can now access the resource. If you fixed everything, but the error occurred again, you should contact the hoster. This happens due to incorrect settings or server overload.
Access Error to robots.txt
This error appears when the file is not available for the search robot. An "unavailable" error occurs when the firewall is blocking Google. If it is not fixed, crawling will be delayed.
The root document robots.txt for a web resource is created in order to prescribe directives and close visits to search robots to technical web pages and other pages that don't contain useful and unique information. Also, adjust the crawling process and provide a path to the sitemap for a better crawl.
This file allows reducing the number of requests to your server, respectively, the website load.
Google perceives the information in the file as a directive, not a direct indication.
To fix the issue, check if robots.txt is configured correctly:
- whether the sections and documents prohibited to process are specified correctly;
- whether the file is available or gives a 404 server response.
URL Errors
If there are URL errors, there is an issue of crawling the page. Similar pages will not be displayed in the search. To establish this fact, you should read the report from the Google Search Console "URL Errors".
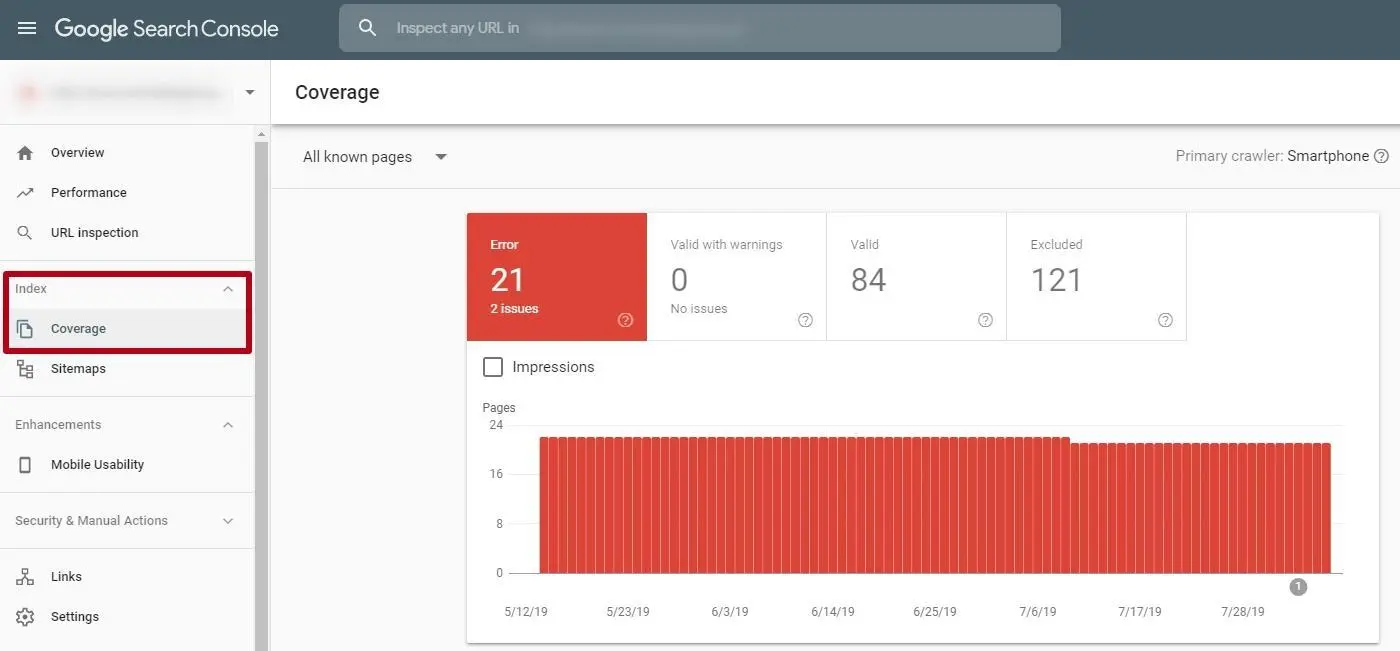
These errors appear when Googlebot is unable to process individual pages due to incorrect redirects (chains of endless redirects, redirects to broken pages), and errors of a non-updated sitemap.xml. The report can be obtained in the Search Console. To do this, go to the Coverage section from the main menu, as shown in the screenshot above.
It is easier to fix such issues: when analyzing them, you can see the specific pages that have issues.
URL errors display a list from most important to minor issues. They need to be fixed since the robot has a certain "crawling budget": if it spends all its time viewing non-existent pages, the website won't have useful pages crawled (or it will take a long time to index them).
"Soft 404" error. It appears when:
- the page that was deleted doesn't return an HTTP 404 response code at the request of the user or bot;
- non-existent page redirects users to an irrelevant page. For example, if you set a redirect from the bikes category to the motorcycles category;
- when the page is blank, there is no content on it.
In order to fix these errors, you should do the following:
1) Remove broken links.
2) Configure redirects correctly.
3) Configure 404 response code for non-existent pages.
4) Close from indexing or delete pages that don't have content.
Similar errors occur when setting up a 301 redirect to irrelevant URLs. Google may misinterpret them. At the same time, it is undesirable to redirect many outdated pages to the main page of the web resource, since it's better to put links to similar pages or similar content. So it is more likely that the user will receive the correct result to his request.
404 error. It occurs when the robot crawls a non-existent page because it was referenced in other documents, including sitemap.xml. There are internal and external 404 errors:
- if the link to the remote page is inside the website, developers can remove it themselves;
- if the link is external, developers, together with the SEO specialist or content manager, can configure 301 redirects in the .htaccess file to transfer its link weight to any relevant page.
Access denied. This error appears when the robot doesn't have access to the URL. For example, the directives are used in the robots.txt file, a ban on crawling the entire resource or individual directories and sections. Or the hoster has blocked access to the website.
To fix this issue, just remove the reason that prevents access:
- enable opening the page without authorization;
- generate the robots.txt file correctly and make it available for the search robot;
- check through Google's crawler how the search engine sees the website from its part.
Transition suspended errors. It usually occurs by redirect errors as well as JavaScript. How to fix them:
- check redirect chains through online services, for example, redirectdetective.com. Note that the number of redirects should be minimal, it is advisable to limit it to one;
- work with the website structure: at least one static link should lead to each page. To do this, check everything manually or use crawler systems/crawler tools if your site has more than 1000 pages;
- replace the redirected URLs found in the service with the destination URL by recording in the Sitemap.
Conclusion
Crawler errors can appear due to the fault of the webmaster or for other reasons: hosting and domain, CMS, content managers, communication with other API, services, databases, and other issues.
In order to preserve the search engine ranking, you should regularly check on the presence of any errors and fix them as soon as possible.
FAQ
What are crawl errors in Google Search Console?
Google Search Console crawl errors occur when the Googlebot cannot access certain pages on your website, which can affect visibility in search results. Common Google crawl errors include DNS issues, server errors, and inaccessible URLs.
What does it mean if a recrawl request failed in Google Search Console?
If a recrawl request fails, it means that Googlebot was unable to access the requested page or section of your website for re-indexing.
How to check crawl errors?
You can use Google Search Console as a crawl errors checker, which provides detailed reports on any issues Googlebot encounters while crawling your site.
What does it mean if links are not crawlable on my website?
It means that search engines cannot access these links to follow them and index the content.
What causes a crawl issue, and why are some pages not crawled?
Crawl issues occur when search engines encounter obstacles in accessing certain pages, resulting in pages not being crawled. Common causes include blocked pages in the robots.txt file, server errors, or incorrect URL structures. To fix this, review crawl settings in Google Search Console and ensure all essential pages are accessible to search engines.
To stay up to date with all the news from the Serpstat blog, subscribe to our newsletter. Also, follow us on Twitter, LinkedIn or join our private Facebook group to get all the insights!
Find Technical Issues on Your Website With the SEO Audit Tool
Get Your Free AccessDiscover More SEO Tools
Tools for Keywords
Keywords Research Tools – uncover untapped potential in your niche
Serpstat Features
SERP SEO Tool – the ultimate solution for website optimization
Keyword Difficulty Tool
Stay ahead of the competition and dominate your niche with our keywords difficulty tool
Check Page for SEO
On-page SEO checker – identify technical issues, optimize and drive more traffic to your website
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.