How To Perform A Niche Analysis Using Our SERP Crawling Tool


2. Crawling Features
3. How To Make A Niche Analysis
- Data Storage And Extension
- Dynamics Of Positions And Traffic Changes By Domain
- What Happens To Keywords In Certain Positions
- Analysis Of Changes In The Top By Phrase
- Comparison With Competitors
- What We Can Do With The Crawling Results
Conclusion
Crawling Overview
- scan Google's top search results;
- choose any region (or several);
- select a convenient scanning schedule;
- obtain data via the API.
- website position (according to the region and schedule you've set);
- domain;
- target URL;
- title;
- description;
- the number of results;
- paid search results on the phrase.
A report looks like this:
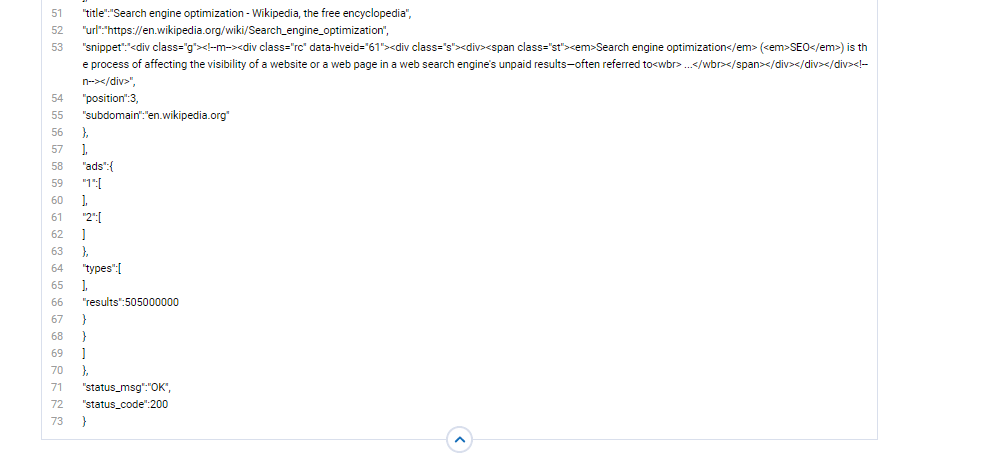
Crawling Features
in addition to positions, we can regularly scan volume on these phrases. Having the frequency and position of the phrase in your domain and competitor domains, it is already possible to predict the approximate traffic both in general and individual categories.
you can find out which categories are in the lead, which fall behind and, accordingly, what are the keywords which make your website fall behind.
which of the competitors came as close as possible to the positions of the promoted site and by what phrases.
sorting phrases/categories that have moved to the top. Based on these data, you can pay attention to these categories while promoting.
you can track regional search volume for keywords to understand in which regions competitors are in the lead and on which topics. It often happens that you are the leader in large cities, but there are cities where niche competitors bypass you on specific topics, and you don't notice that.
crawling will fix the snippets of each site, so you can evaluate the snippets of competitors, learn their weaknesses and improve yours.
How To Analyze A Niche
Data Storage And Extension
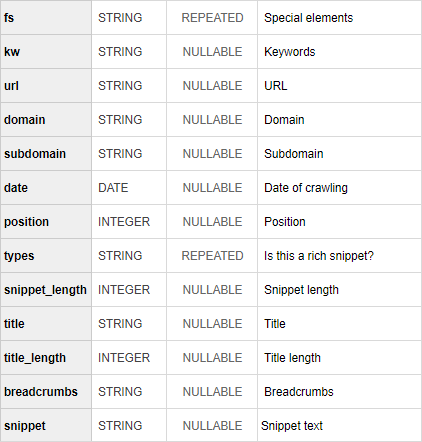
Let's have a look at the example. We'd want to research the SEO niche in Google USA, and we've already received 64 requests in this regard. Every day, we analyzed tops, got volume from the Serpstat API, and, based on the position, found CTR statistics in Google search results. We won't go into the technical implementation of this solution because you can use whichever way you choose to process and store JSON objects. I used the R + Google Sheets + Google BigQuery combination, although Apps Script can be used instead of R.
We'll add three columns to the final table with data — CTR, Queries (frequency) and Traffic. Then it's time to go to Data Studio and build interactive reports based on this table.
Analyzing Crawling Results
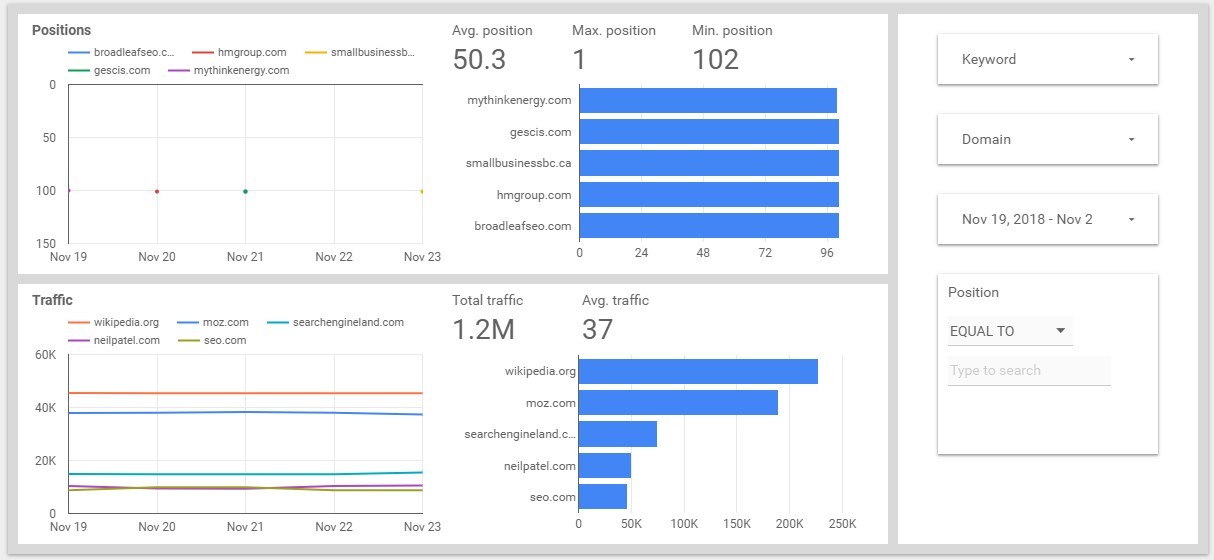
We'll not pay attention to some obvious or non-obvious numbers, but let's see how we can work with such a report. Also, we will not distribute positions and traffic to different sheets of the report — this is how all of our data will be placed in one screen. I created the CTR for this report myself, any reference is coincidental :)
Dynamics Of Positions And Traffic Changes By Domain
What Happens To Keywords In Certain Positions
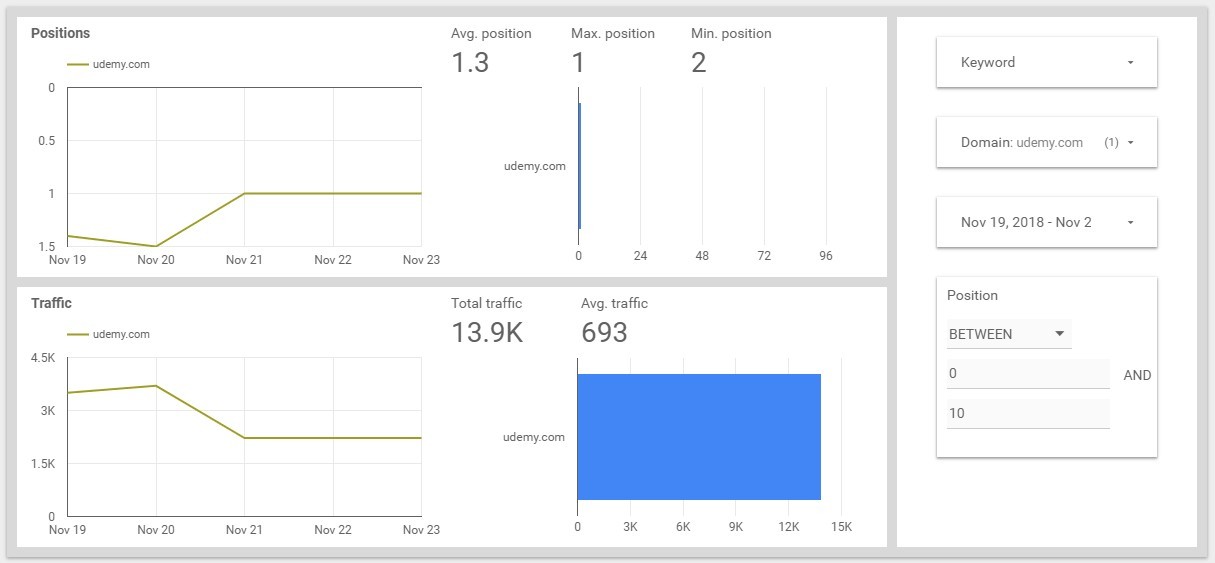
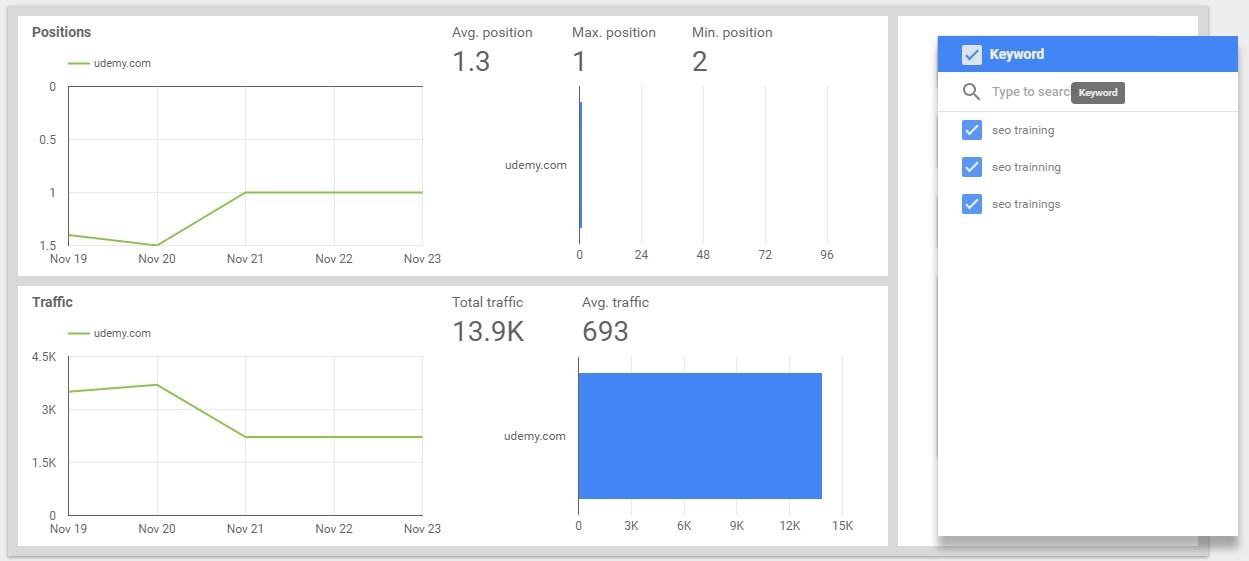
Analysis Of Changes In The Top By Keyword

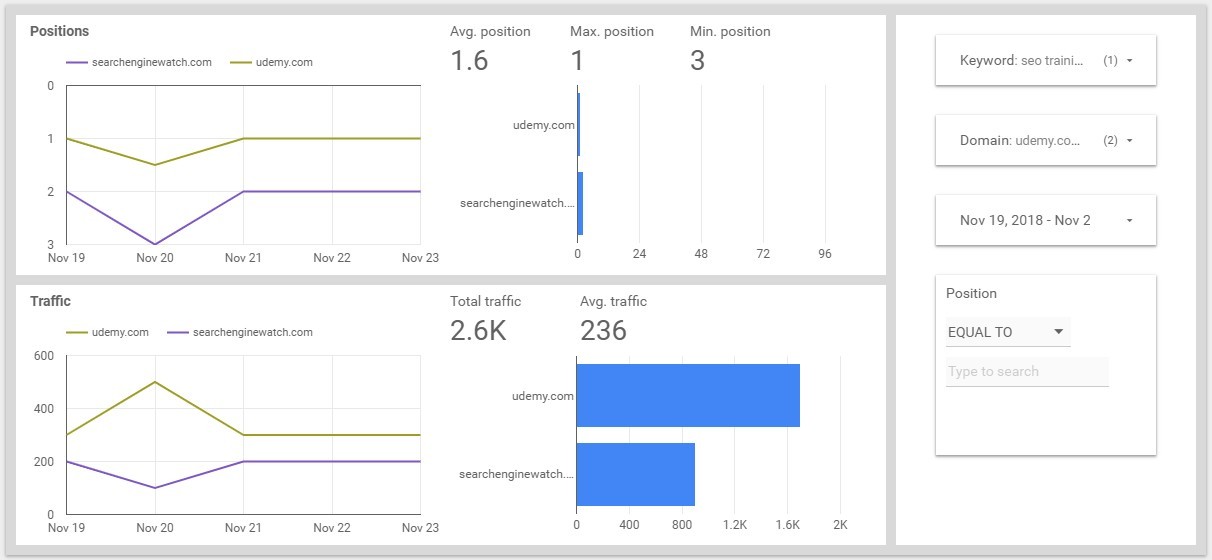
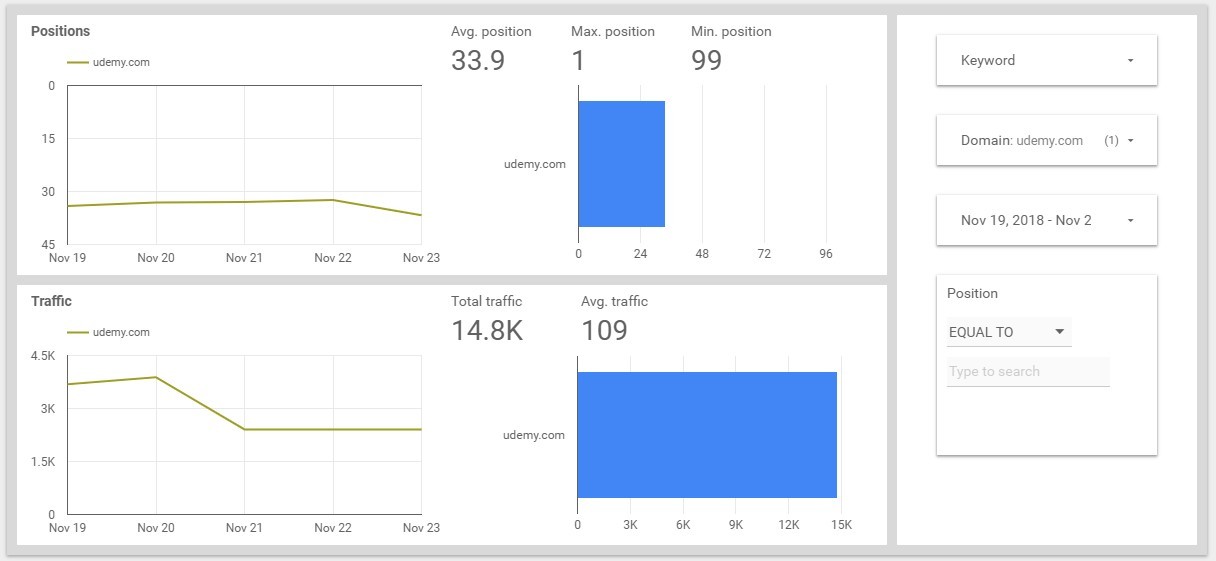
Comparison With Competitors
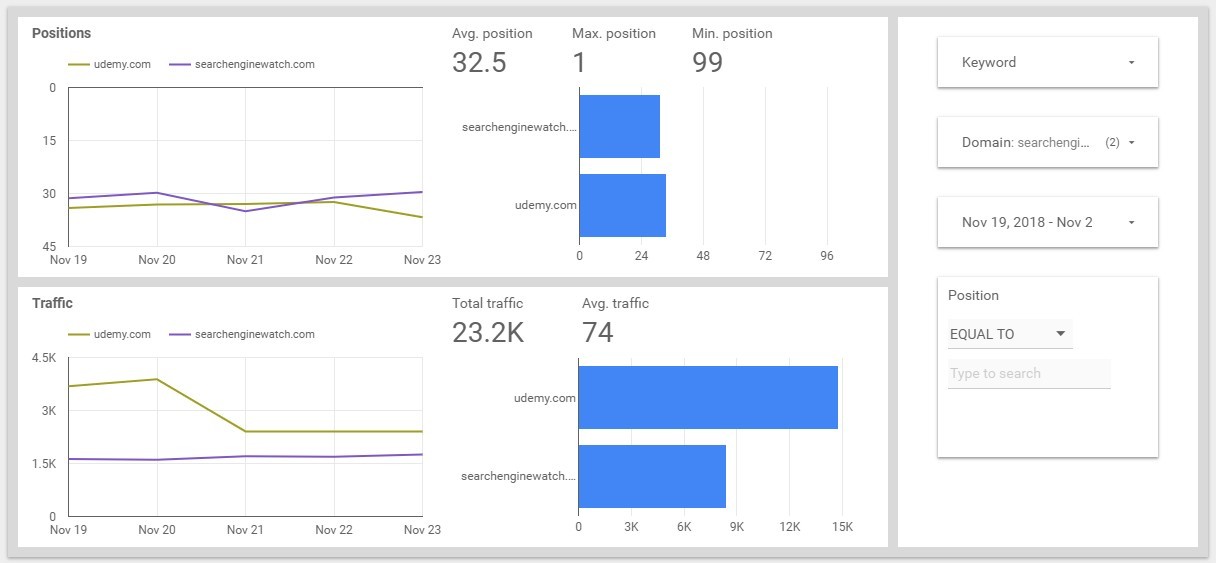
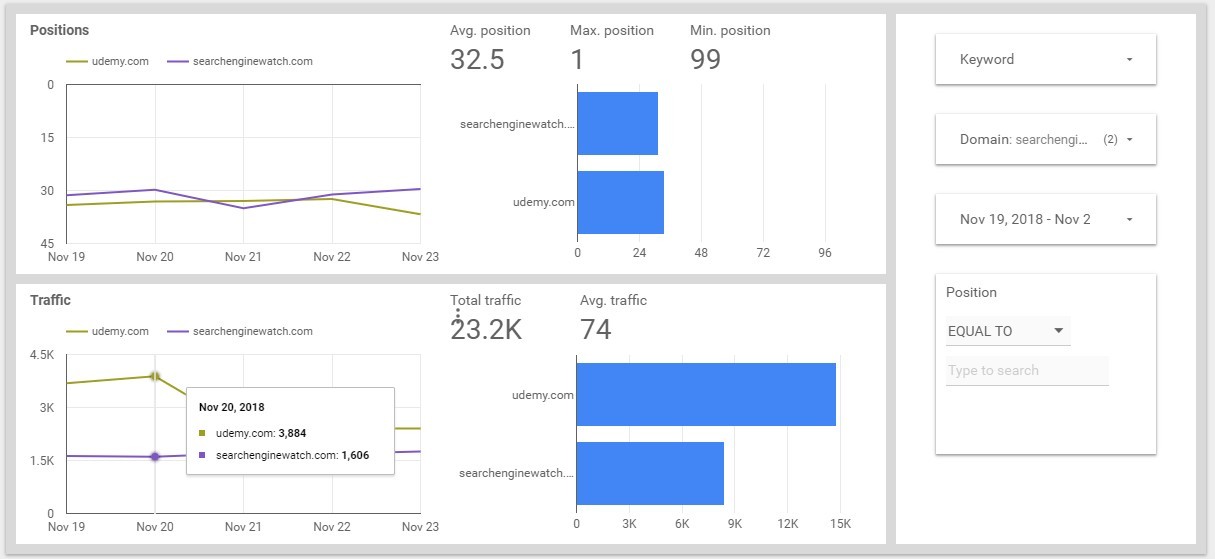
We take the data for November 23. The total traffic is 237.3 thousand. The traffic on Udemy is 2.4 thousand, this is about 1%. At Search Engine Watch traffic is 1.7 thousand, this is 0.7%
What We Can Do With The Crawling Results
We also left out special element analysis and contextual advertising. With this information, you may make CTR corrections based on their availability, allowing you to generate more accurate traffic estimations.
Another possibility is parsing snippets. You can analyze snippets of sites in the top 10 and take additional information from there for optimizing pages. For example, all your competitors offer free shipping directly in the snippet, but you don't, and because of that you lose competitive advantage.
You can add all this information to a report in Data Studio, and it'll turn into a comprehensive top analytics system. Such a thing is always convenient to keep on hand. Start by collecting data and further improve it as needed.
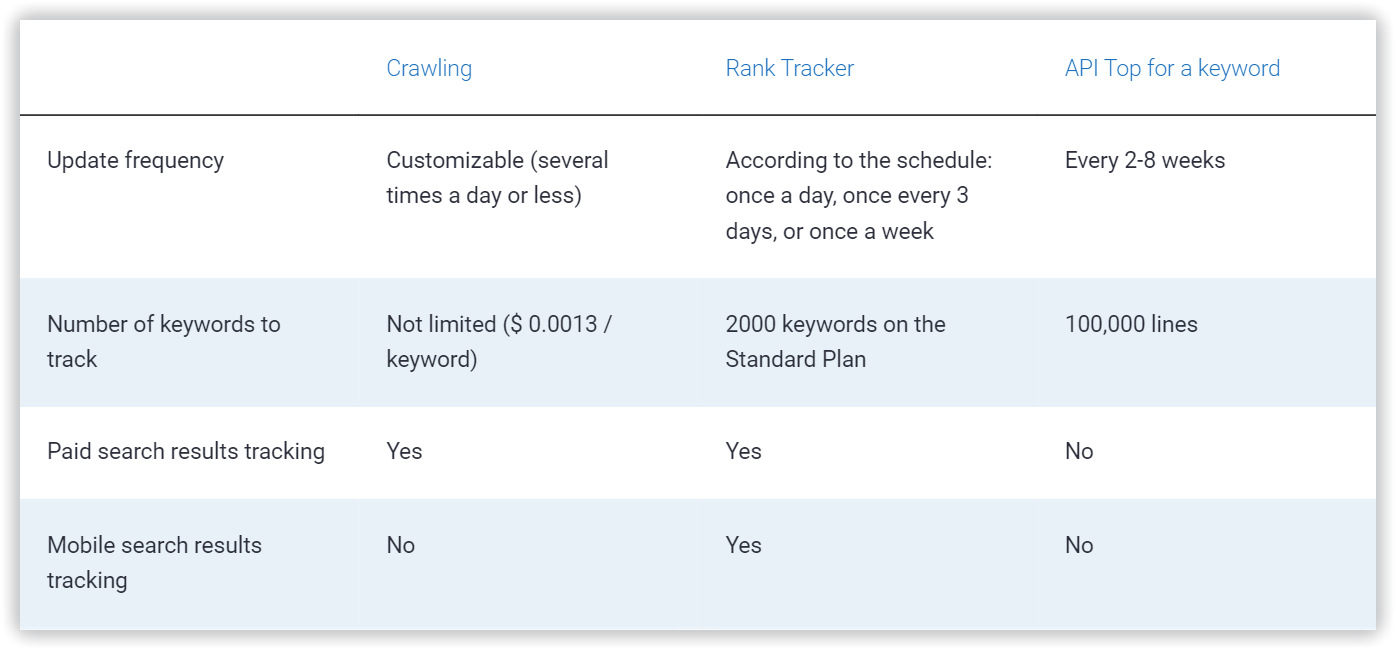
Difference Between Crawling, Rank Tracking And The "Top For A Keyword" API
FAQ
What is SERP crawling?
SERP crawling is a process of collecting data of the search engine results page.
Why you should try Serpstat SERP crawling?
Serpstat SERP crawling allows you to collect big data and build a regularly updated analytics for clients in their personal accounts on your website.
Summing Up
Speed up your search marketing growth with Serpstat!
Keyword and backlink opportunities, competitors' online strategy, daily rankings and SEO-related issues.
A pack of tools for reducing your time on SEO tasks.
Discover More SEO Tools
Backlink Cheсker
Backlinks checking for any site. Increase the power of your backlink profile
API for SEO
Search big data and get results using SEO API
Competitor Website Analytics
Complete analysis of competitors' websites for SEO and PPC
Keyword Rank Checker
Google Keyword Rankings Checker - gain valuable insights into your website's search engine rankings
Recommended posts
Cases, life hacks, researches, and useful articles
Don’t you have time to follow the news? No worries! Our editor will choose articles that will definitely help you with your work. Join our cozy community :)
By clicking the button, you agree to our privacy policy.