10 exotische SEO-Fehler und elegante Lösungen dafür


Mario Schwertfeger
SEO-Experte & Freelanc
Wer ein paar Jahre SEO macht und dabei zahlreiche Seiten analysiert, findet über die Zeit technische SEO-Fehler wie Sand am Meer. Einen bunten Mix an 10 technischen SEO-Fehlern möchte ich mit diesem Artikel vorstellen.
Dabei handelt es sich nicht unbedingt um die 10 typischsten oder häufigsten SEO-Fehler, sondern einfach eine kleine Sammlung an typischen aber auch exotischen Fehlern, die mir in letzter Zeit begegnet sind. Vielleicht ist ja auch der ein oder andere Bereich dabei, den es sich mal lohnt auf eurer Seite zu prüfen oder der bei zukünftigen Projekten einfach schon mit bedacht werden sollte.
Gliederung
- Indexierung der Staging-Umgebung
- Verlinkung auf Testumgebung nach GoLive
- Indexierungssteuerung über die robots.txt
- Falscher Status Code für die robots.txt
- Paginierung und das Canonical-Tag
- Rich Snippet-Spam
- Weiterleitungen per Meta-Refresh
- Unlesbare Inhalte dank JavaScript
- Einbindung von hreflang oder Paginierung im Body
- Noindex-Anweisung für amerikanische IPs
Indexierung der Staging-Umgebung
Die meisten Unternehmen arbeiten mit einer sogenannten Staging-Umgebung, um Änderungen an der Seite zu testen oder bspw. bei einem Relaunch der Seite die Qualitätssicherung vor dem GoLive durchzuführen.
Diese Umgebung ist dabei im Grunde eine 1 zu 1 Kopie der aktuellen oder neuen Seite und liegt häufig auf einer Subdomain wie z. B. staging.domain.com. Diese Seite sollte dabei allerdings nicht für den Googlebot crawlbar sein und keinesfalls indexiert werden (Duplicate Content!).
Sieht man sich allerdings einmal die SERPs per inurl:-Abfrage an, findet man jede Menge indexierte Staging-Umgebungen. Ob die eigene Staging-Umgebung im Index ist, erkennt man z. B. einfach mit der entsprechenden site:-Abfrage in Google. Lautet die Adresse der eigenen Staging bspw. http://staging.domain.com, gibt man einfach folgenden Befehl in Google ein: site:staging.domain.com und schon sieht man, ob die eigene Staging-Umgebung von Google indexiert wurde.
Wie verhindert man die Indexierung? Ein häufig gewählter Ansatz ist das Sperren der Staging-Umgebung über die robots.txt. Was dann passiert sieht man allerdings am Beispiel der Seite cinemacon.com:
Diese Umgebung ist dabei im Grunde eine 1 zu 1 Kopie der aktuellen oder neuen Seite und liegt häufig auf einer Subdomain wie z. B. staging.domain.com. Diese Seite sollte dabei allerdings nicht für den Googlebot crawlbar sein und keinesfalls indexiert werden (Duplicate Content!).
Sieht man sich allerdings einmal die SERPs per inurl:-Abfrage an, findet man jede Menge indexierte Staging-Umgebungen. Ob die eigene Staging-Umgebung im Index ist, erkennt man z. B. einfach mit der entsprechenden site:-Abfrage in Google. Lautet die Adresse der eigenen Staging bspw. http://staging.domain.com, gibt man einfach folgenden Befehl in Google ein: site:staging.domain.com und schon sieht man, ob die eigene Staging-Umgebung von Google indexiert wurde.
Wie verhindert man die Indexierung? Ein häufig gewählter Ansatz ist das Sperren der Staging-Umgebung über die robots.txt. Was dann passiert sieht man allerdings am Beispiel der Seite cinemacon.com:

Zumindest die Startseite der Staging-Version landet im Google Index – theoretisch könnten bei entsprechender externer Verlinkung aber auch alle anderen Seiten in den Index gelangen. Doch dazu später mehr.
Der sicherste Weg, um die Staging-Umgebung folglich aus dem Index zu halten ist ein Passwortschutz.
Der sicherste Weg, um die Staging-Umgebung folglich aus dem Index zu halten ist ein Passwortschutz.
Verlinkung auf Staging nach GoLive
Ein weiterer häufiger Fehler, den man bei einem Relaunch oftmals sieht, ist die Verlinkung der neuen Seite auf die Testumgebung.
Die neue Seite wurde im Rahmen des Relaunches folglich live geschalten, einige dieser Links verlinken dabei aber auf die Testumgebung. Dies passiert häufig, wenn auf der Testumgebung mit absoluten Links statt mit relativen Links gearbeitet wurde.
Dabei muss es sich aber nicht ausschließlich um interne Links handeln, auch das hreflang oder Canonical-Tags verweisen nach einem Relaunch oftmals noch auf die Testumgebung.
Hier hilft nur ein ausgiebiges Testen der neuen Version und eine Überprüfung auf fehlerhafte Links, Canonical-Tags und hreflang-Anweisungen.
Die neue Seite wurde im Rahmen des Relaunches folglich live geschalten, einige dieser Links verlinken dabei aber auf die Testumgebung. Dies passiert häufig, wenn auf der Testumgebung mit absoluten Links statt mit relativen Links gearbeitet wurde.
Dabei muss es sich aber nicht ausschließlich um interne Links handeln, auch das hreflang oder Canonical-Tags verweisen nach einem Relaunch oftmals noch auf die Testumgebung.
Hier hilft nur ein ausgiebiges Testen der neuen Version und eine Überprüfung auf fehlerhafte Links, Canonical-Tags und hreflang-Anweisungen.
Indexsteuerung über die robots.txt
Ein weiterer Fehler, welcher einem im SEO-Alltag häufig begegnet, ist die falsche Annahme, dass die robots.txt ein geeignetes Tool ist, um die Indexierung von bestimmten Seiten zu verhindern.
Dabei ist die robots.txt lediglich ein Mittel zur Crawlersteuerung – und auch hierfür ist es sicherlich nicht das beste Mittel der Wahl.
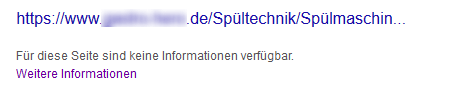
Wird eine Seite, welche in der robots.txt gesperrt ist intern oder extern verlinkt, dann findet der Googlebot diese URL und indexiert sieht. Da der Bot aber selbst nicht auf die URL geht, kann er weder Title noch Description auslesen. Als Title wird daher, wie im nachfolgenden Screenshot ersichtlich, dann der Linktext verwendet, als Description kommt lediglich der Hinweis, dass keine Informationen für diese Seite verfügbar sind.
Dabei ist die robots.txt lediglich ein Mittel zur Crawlersteuerung – und auch hierfür ist es sicherlich nicht das beste Mittel der Wahl.
Wird eine Seite, welche in der robots.txt gesperrt ist intern oder extern verlinkt, dann findet der Googlebot diese URL und indexiert sieht. Da der Bot aber selbst nicht auf die URL geht, kann er weder Title noch Description auslesen. Als Title wird daher, wie im nachfolgenden Screenshot ersichtlich, dann der Linktext verwendet, als Description kommt lediglich der Hinweis, dass keine Informationen für diese Seite verfügbar sind.

Falscher Status Code für die robots.txt
Fehler Nummer 4 ist wohl eher ein exotischer, aber nicht minder gravierender Fehler: ein falscher Status Code für die robots.txt.
Während vor einigen Jahren noch die Empfehlung galt, dass jede Seite eine robots.txt benötigt, sagt Google mittlerweile, dass eine robots.txt nicht zwingend notwendig ist. Wenn Google also unter im Root-Verzeichnis domain.com/robots.txt keine robots.txt findet, crawlt es die Seite dennoch.
Folglich sollte es zwei mögliche Szenarien geben. Entweder die Adresse domain.com/robots.txt spielt einen Status Code 200 aus und es wurde unter diese Adresse eine robots.txt hinterlegt. Oder aber Google bekommt beim Aufruf dieser Adresse einen Status Code 404 zurückgespielt, weiß somit, dass keine robots.txt hinterlegt ist und crawlt die Seite anschließend.
Ein sehr exotischer Fehler, welcher mir dabei im letzten Jahr begegnet ist, war der Fall, dass keine robots.txt hinterlegt wurde und der Aufruf der Adresse aber einen Status Code 500 (Serverfehler) zurückgegeben hat.
Dies führte dazu, dass Google sofort das Crawling einstellte und die Seite während diesem Zeitraum nicht mehr crawlte. Der Grund hierfür ist, dass Google bei einem 5xx Statuscode davon ausgehen muss, dass die Seite aufgrund eines Serverfehlers derzeit nicht erreichbar ist, aber auf dieser Seite eine robots.txt mit Sperr-Anweisungen hinterlegt sein könnte (siehe hierzu auch die entsprechenden Spezifikationen von Google).
Während vor einigen Jahren noch die Empfehlung galt, dass jede Seite eine robots.txt benötigt, sagt Google mittlerweile, dass eine robots.txt nicht zwingend notwendig ist. Wenn Google also unter im Root-Verzeichnis domain.com/robots.txt keine robots.txt findet, crawlt es die Seite dennoch.
Folglich sollte es zwei mögliche Szenarien geben. Entweder die Adresse domain.com/robots.txt spielt einen Status Code 200 aus und es wurde unter diese Adresse eine robots.txt hinterlegt. Oder aber Google bekommt beim Aufruf dieser Adresse einen Status Code 404 zurückgespielt, weiß somit, dass keine robots.txt hinterlegt ist und crawlt die Seite anschließend.
Ein sehr exotischer Fehler, welcher mir dabei im letzten Jahr begegnet ist, war der Fall, dass keine robots.txt hinterlegt wurde und der Aufruf der Adresse aber einen Status Code 500 (Serverfehler) zurückgegeben hat.
Dies führte dazu, dass Google sofort das Crawling einstellte und die Seite während diesem Zeitraum nicht mehr crawlte. Der Grund hierfür ist, dass Google bei einem 5xx Statuscode davon ausgehen muss, dass die Seite aufgrund eines Serverfehlers derzeit nicht erreichbar ist, aber auf dieser Seite eine robots.txt mit Sperr-Anweisungen hinterlegt sein könnte (siehe hierzu auch die entsprechenden Spezifikationen von Google).
Paginierung und das Canonical-Tag
Gerade Online-Shops, die aus Performance-Gründen nicht alle Artikel auf eine Seite darstellen wollen, nutzen eine Paginierung, um die Produkte über mehrere Seiten verteilt darzustellen.

Da sich auf diesen Seiten nur die Produkte selbst unterscheiden, bergen diese Seiten die Gefahr durch Google als Near Duplicate Content gewertet zu werden.
Die Empfehlung von Google lautet hierfür die Seiten entsprechend mit und rel="next" auszuzeichnen. Dadurch erkennt Google den Zusammenhang und indexiert (zumindest in der Theorie) nur die wichtigste Seite, welche im Normalfall die erste Seite ist. Oftmals werden zur Sicherheit auch noch die Folgeseiten auf „noindex" gesetzt.
Einen häufig beobachteten Fehler, den man bei der Paginierung aber keinesfalls machen sollte, ist das Setzen eines Canonicals von allen Folgeseiten jeweils auf Seite 1.
Dies führt dazu, dass der Linkjuice gebündelt auf Seite 1 weitergeleitet wird und dadurch die Produkte auf den Folgeseiten keinen Linkjuice erhalten.
Die Empfehlung von Google lautet hierfür die Seiten entsprechend mit und rel="next" auszuzeichnen. Dadurch erkennt Google den Zusammenhang und indexiert (zumindest in der Theorie) nur die wichtigste Seite, welche im Normalfall die erste Seite ist. Oftmals werden zur Sicherheit auch noch die Folgeseiten auf „noindex" gesetzt.
Einen häufig beobachteten Fehler, den man bei der Paginierung aber keinesfalls machen sollte, ist das Setzen eines Canonicals von allen Folgeseiten jeweils auf Seite 1.
Dies führt dazu, dass der Linkjuice gebündelt auf Seite 1 weitergeleitet wird und dadurch die Produkte auf den Folgeseiten keinen Linkjuice erhalten.
Rich Snippet-Spam
Eine beliebte Methode, um mit Produktseiten mehr Aufmerksamkeit in den SERPs zu bekommen, ist die Auszeichnung der Produkt-Reviews (Sternebewertungen) mit strukturierten Daten.
Dadurch besteht die Möglichkeit, dass Google diese Sterne in den Suchergebnissen in Form von Rich Snippets einbindet:
Dadurch besteht die Möglichkeit, dass Google diese Sterne in den Suchergebnissen in Form von Rich Snippets einbindet:
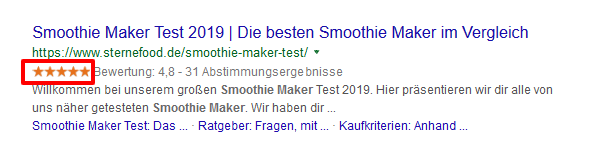
Wichtig ist hierbei jedoch, dass tatsächlich nur Reviews ausgezeichnet werden dürfen, welche auch für den Nutzer auf der Seite sichtbar sind!
Die Auszeichnung von nicht auf der Seite vorhandenen Reviews ist ein klarer Verstoß gegen die Structured Data Guidelines und kann zu einer manuellen Penalty inklusive erheblichem Sichtbarkeits- und Trafficeinbruch führen, wie dies bei zahlreichen Seiten im Jahr 2017 der Fall war.
Über eine derartige manuelle Penalty wird man dann direkt in der Google Search Console benachrichtigt. Hat man den Rich Snippet Spam dann beseitigt und einen erfolgreichen Reconsideration-Request gestellt, dauert es ca. 2 Wochen bis Rankings und Traffic sich wieder vollkommen erholt haben.
Die Auszeichnung von nicht auf der Seite vorhandenen Reviews ist ein klarer Verstoß gegen die Structured Data Guidelines und kann zu einer manuellen Penalty inklusive erheblichem Sichtbarkeits- und Trafficeinbruch führen, wie dies bei zahlreichen Seiten im Jahr 2017 der Fall war.
Über eine derartige manuelle Penalty wird man dann direkt in der Google Search Console benachrichtigt. Hat man den Rich Snippet Spam dann beseitigt und einen erfolgreichen Reconsideration-Request gestellt, dauert es ca. 2 Wochen bis Rankings und Traffic sich wieder vollkommen erholt haben.
Weiterleitungen per Meta-Refresh
Ein weiter kurioser Fehler ist mir im letzten Jahr begegnet, als ich bei einem Neukunden entdeckt habe, dass zahlreiche seit Jahren veraltete URLs im Index waren, von denen der Websitebetreiber sicher war, dass sie passend weitergeleitet wurden.
Hat man anschließend in den SERPs auf derartige Seiten geklickt, wurden diese augenscheinlich auch auf eine passende neue URL weitergeleitet.
Hat man die Weiterleitung allerdings mit einem Tool wie dem Link Redirect Trace von LRT geprüft, hat man schnell gesehen, dass es sich um keine serverseitige Weiterleitung handelte, sondern der Nutzer lediglich per Meta-Refresh auf die neue Seite geschickt wurde. Google konnte diesen Weiterleitungen also nie folgen, sdass diese veralteten URLs niemals aus dem Index verschwinden konnten.
Wichtig ist daher regelmäßig auch mal den Index zu prüfen (oder die Logfiles), um eventuelle Altlasten zu identifizieren und zudem veraltete Inhalte immer per 301 Redirect auf das neue Ziel zu leiten.
Hat man anschließend in den SERPs auf derartige Seiten geklickt, wurden diese augenscheinlich auch auf eine passende neue URL weitergeleitet.
Hat man die Weiterleitung allerdings mit einem Tool wie dem Link Redirect Trace von LRT geprüft, hat man schnell gesehen, dass es sich um keine serverseitige Weiterleitung handelte, sondern der Nutzer lediglich per Meta-Refresh auf die neue Seite geschickt wurde. Google konnte diesen Weiterleitungen also nie folgen, sdass diese veralteten URLs niemals aus dem Index verschwinden konnten.
Wichtig ist daher regelmäßig auch mal den Index zu prüfen (oder die Logfiles), um eventuelle Altlasten zu identifizieren und zudem veraltete Inhalte immer per 301 Redirect auf das neue Ziel zu leiten.
Unlesbare Inhalte dank JavaScript
Der Einsatz von JavaScript in der Webentwicklung nimmt in den letzten Jahren deutlich zu. Auch Google bekennt sich regelmäßig dazu, wie gut man darin geworden sei JavaScript zu lesen und zu crawlen:
„Google has gotten really good at reading & processing JavaScript-based content for web-search." (John Mueller)
Hierauf sollte man allerdings nicht blind vertrauen. Wichtig ist es vor allem auch die Seiten und das JavaScript aus Sicht von Google zu testen, wobei man auf mehrere Werkzeuge zurückgreifen sollte, wie z. B. als ersten Einstieg die Rendering Funktion im Screaming Frog, das Mobile Friendly Testing Tool, um sich das gerenderte DOM darstellen zu lassen oder vor allem auch den Chrome 41-Browser, um die Darstellung der Inhalte aus Sicht von Google zu simulieren.
Gerade mit letzterem „Tool" sieht man beim Aufruf von Javascript-lastigen Websites oftmals auf den ersten Blick Seitenbereiche, die nicht geladen bzw. dargestellt werden.
Wer sich ausgiebig mit dem Thema Testing von JavaScript-Webseiten beschäftigen will, sollte sich unbedingt den englischsprachigen Guide von Elephate oder den deutschsprachigen Guide von Artur Kosch ansehen.
„Google has gotten really good at reading & processing JavaScript-based content for web-search." (John Mueller)
Hierauf sollte man allerdings nicht blind vertrauen. Wichtig ist es vor allem auch die Seiten und das JavaScript aus Sicht von Google zu testen, wobei man auf mehrere Werkzeuge zurückgreifen sollte, wie z. B. als ersten Einstieg die Rendering Funktion im Screaming Frog, das Mobile Friendly Testing Tool, um sich das gerenderte DOM darstellen zu lassen oder vor allem auch den Chrome 41-Browser, um die Darstellung der Inhalte aus Sicht von Google zu simulieren.
Gerade mit letzterem „Tool" sieht man beim Aufruf von Javascript-lastigen Websites oftmals auf den ersten Blick Seitenbereiche, die nicht geladen bzw. dargestellt werden.
Wer sich ausgiebig mit dem Thema Testing von JavaScript-Webseiten beschäftigen will, sollte sich unbedingt den englischsprachigen Guide von Elephate oder den deutschsprachigen Guide von Artur Kosch ansehen.

Einbindung von hreflang oder Paginierung im Body
Hin und wieder erlebt man als SEO auch, dass die IT stolz berichtet, dass bspw. das hreflang-Attribut oder rel="prev" und rel="next" nun eingebunden sei. Allerdings ist es mit der alleinigen Einbindung dieser Elemente irgendwo auf der Seite nicht getan. Wichtig ist, dass diese auch an der richtigen Stelle eingebunden werden.
So verfällt die Wirkung der hreflang-Attribute oder von rel="prev" und rel="next", wenn diese im <body> der Seite eingebunden werden – dort werden sie von Google schlicht ignoriert. Hier also immer darauf achten und prüfen, ob die IT diese Elemente tatsächlich auch im <head> der Seite eingebaut hat.
So verfällt die Wirkung der hreflang-Attribute oder von rel="prev" und rel="next", wenn diese im <body> der Seite eingebunden werden – dort werden sie von Google schlicht ignoriert. Hier also immer darauf achten und prüfen, ob die IT diese Elemente tatsächlich auch im <head> der Seite eingebaut hat.
Noindex-Anweisung für amerikanische IPs
Wichtig ist auch beim Auditing darauf zu achten, möglichst genau den Blick von Google auf eine Seite zu simulieren.
Dies bedeutet die Seite möglichst mit einem Google-User-Agenten zu crawlen, dabei idealerweise aber auch eine amerikanische IP (per Proxy / VPN) zu nutzen.
Möchte man nur einzelne Seiten betrachten, ist auch hier das Mobile-Friendly-Testing-Tool eine Quick-and-Dirty-Lösung.
Hier einfach die zu prüfende URL eingeben, im Testergebnis auf HTML klicken, Code in einen Editor hineinkopieren und schon lässt sich in Ruhe der Quellcode aus Sicht von Google analysieren.
Dies bedeutet die Seite möglichst mit einem Google-User-Agenten zu crawlen, dabei idealerweise aber auch eine amerikanische IP (per Proxy / VPN) zu nutzen.
Möchte man nur einzelne Seiten betrachten, ist auch hier das Mobile-Friendly-Testing-Tool eine Quick-and-Dirty-Lösung.
Hier einfach die zu prüfende URL eingeben, im Testergebnis auf HTML klicken, Code in einen Editor hineinkopieren und schon lässt sich in Ruhe der Quellcode aus Sicht von Google analysieren.
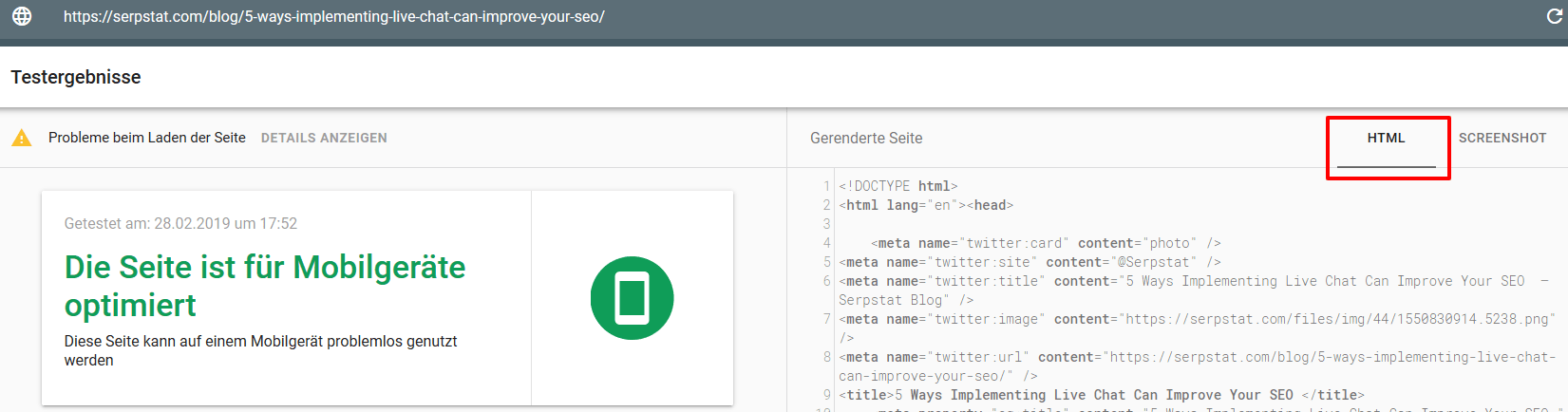
Hier gab es durchaus schon Fälle, bei welchen man dann gesehen hat, dass aus der „index"-Anweisung, welche die manuelle Prüfung ergab, eine „noindex"-Anweisung für Abrufe mit amerikanischer IP wurde.
blog_main_page_trial_form_header
article_trial_block_first_line
article_trial_block_second_line
Die Beiträge der Gastautoren können nicht mit der Meinung der Serpstat-Redaktion übereinstimmen.
Hast du einen Fehler gefunden? Markiere diesen und betätige Ctrl + Enter, um es uns mitzuteilen
discover_more_seo_tools
seo_seo_block_title_1
seo_seo_block_text_1
seo_seo_block_title_2
seo_seo_block_text_2
seo_seo_block_title_3
seo_seo_block_text_3
seo_seo_block_title_4
seo_seo_block_text_4
Empfehlungen
Cases, Lifechaks, Studien und nützliche Artikel
Hast du keine Zeit, um auf dem Laufenden zu bleiben? Kein Problem! Unsere Lieblingsredakteurin Stacy sammelt für dich die besten Artikel, die dir unbedingt bei der Arbeit helfen. Trete unserer Community bei :)
Wenn du auf die Schaltfläche zum Absenden klickst, stimmst du den Nutzungsbedingungen und der Datenschutz-Policy von Serpstat zu.