Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как использовать API Serpstat для анализа ниши и постановки гипотез в SEO — опыт WebX.page


По ходу будет рассмотрен общий алгоритм работы и получены ответы на вопросы «Важно ли большое количество обратных ссылок для попадания в поисковый топ?», «Важен ли DomainRank для той же цели?» и «Играет ли роль количество страниц в индексе?». Обладая этими базовыми знаниями можно развивать собственные решения для анализа требуемых показателей.
В частности то, о чем пойдет речь в статье — одни из первых наработок, которые позволяли осмотреть новые ниши целиком, имея достаточно большой набор данных. При этом — быстро, доступно и с заявкой на расширение в дальнейшем.
Предлагаю пройтись по предпринятым шагам и посмотреть, как это работает.
Здесь есть важный момент: результаты прямого парсинга и CSE могут отличаться, но за несколько тысяч ключевых слов я пока не заметил разительных отличий, искажающих данные. Чтобы потом не отвлекаться, можно сразу получить Google Developer API Key и Google Custom Search Engine ID (путем создания новой поисковой системы).
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)

С помощью Serpstat API будем брать данные из раздела getSummaryData, поскольку он возвращает около 30 параметров (всего 51, но некоторые уже неактивны и будут выпилены в ближайших обновлениях) и забирает совсем мало лимитов (по 1 на каждый анализируемый URL). Также стоит отметить, что адреса очень крупных сайтов (Google, Wikipedia, Youtube и т.п.) не поддерживаются и присылают ошибки (об этом дальше).
Если вы хотите ознакомиться с моим решением, то для последующих шагов нужно:
Базовая настройка в консоли достаточно проста, основных моментов, на которые нужно обратить внимание, два:
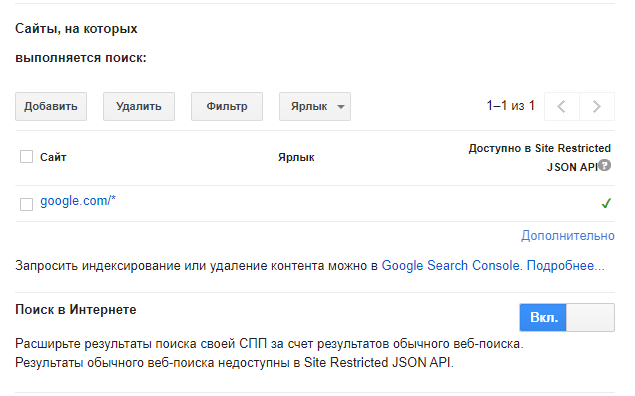
Основные моменты, если вы будете писать собственное решение:
На момент написания статьи через API в отчете getSummaryData можно получить 51 параметр + немного общей информации: сколько осталось лимитов, сколько страниц в текущих результатах, какой порядок сортировки и прочие, которые для нас сейчас ценности не представляют.
Пример запроса:
Endpoint: https://api.serpstat.com/v4/?token=YOUR_TOKEN_HERE
POST body:
{
"id": {{webx.page}}, /*id может быть любым набором букв и чисел, я обычно использую домен рабочего проекта*/
"method": "SerpstatBacklinksProcedure.getSummary", /*используемый метод*/
"params": {
"query" : {{domain}} /*анализируемый домен, полученный ранее в CSE*/
}
}
Пример полученного ответа (без устаревших, только полезные данные):
{"id":"webx.page",
"result":{
"data":{"referringDomains":320,
"referringSubDomains":30,
"referringLinks":153445,
"totalIndexed":1591,
"externalDomains":321,
"noFollowLinks":21219,
"doFollowLinks":219879,
"referringIps":71,
"referringSubnets":57,
"outlinksTotal":50330,
"outlinksUnique":525,
"typeText":240651,
"typeImg":447,
"typeRedirect":0,
"typeAlt":0,
"referringDomainsDynamics":1,
"referringSubDomainsDynamics":0,
"referringLinksDynamics":210,
"totalIndexedDynamics":0,
"externalDomainsDynamics":0,
"noFollowLinksDynamics":2,
"doFollowLinksDynamics":1009,
"referringIpsDynamics":2,
"referringSubnetsDynamics":1,
"typeTextDynamics":1011,
"typeImgDynamics":0,
"typeRedirectDynamics":0,
"typeAltDynamics":0,
"threats":0,
"threatsDynamics":0,
"mainPageLinks":393,
"mainPageLinksDynamics":0,
"domainRank":26.006519999999998}
}
}Для начала вполне хватит 1500 доступных в минимальном тарифном плане запросов, которые дадут нам исчерпывающую информацию по 75 ключевым словам (20 результатов выдачи для каждого).

Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)
На самом деле существуют готовые и кастомизируемые решения (PowerBI, Tableau и т.п.), но они зачастую платные и не до конца кастомизируемые. В конце концов, делать все вручную, затрачивая минимум времени — гораздо интереснее.
В Rstudio интерфейс может показаться немного громоздким на первый взгляд, но это ощущение должно пройти уже после первого построенного собственноручно графика :)
Чтобы не морочиться с третьей базой данных — просто сделаем join (для связки используется id, поскольку при связывании по домену могут вылезти ошибки из-за дублей). Чтобы пользоваться SQL-базами в ходе работы с R, необходимо установить дополнительную библиотеку RMySQL. Общий набор данных назовем «Results».
Первый скрипт будет выглядеть так:
install.packages('RMySQL')
library(RMySQL)
#пишем запрос
#gr - google_results, sr - serpstat_results
#обратите внимание, что для избежания дублирования столбцов нужно явно
#указать какие столбцы из serpstat_results берем в работу
Query <- "
select
gr.*,
sr.referringDomains,
sr.referringSubDomains,
sr.referringLinks,
sr.totalIndexed,
sr.externalDomains,
sr.noFollowLinks,
sr.doFollowLinks,
sr.referringIps,
sr.referringSubnets,
sr.trustRank,
sr.citationRank,
sr.domainZoneEdu,
sr.domainZoneGov,
sr.outlinksTotal,
sr.outlinksUnique,
sr.facebookLinks,
sr.pinterestLinks,
sr.linkedinLinks,
sr.vkLinks,
sr.typeText,
sr.typeImg,
sr.typeRedirect,
sr.typeAlt,
sr.referringDomainsDynamics,
sr.referringSubDomainsDynamics,
sr.referringLinksDynamics,
sr.totalIndexedDynamics,
sr.externalDomainsDynamics,
sr.noFollowLinksDynamics,
sr.doFollowLinksDynamics,
sr.referringIpsDynamics,
sr.referringSubnetsDynamics,
sr.trustRankDynamics,
sr.citationRankDynamics,
sr.domainZoneEduDynamics,
sr.domainZoneGovDynamics,
sr.outlinksTotalDynamics,
sr.outlinksUniqueDynamics,
sr.facebookLinksDynamics,
sr.pinterestLinksDynamics,
sr.linkedinLinksDynamics,
sr.vkLinksDynamics,
sr.typeTextDynamics,
sr.typeImgDynamics,
sr.typeRedirectDynamics,
sr.typeAltDynamics,
sr.threats,
sr.threatsDynamics,
sr.mainPageLinks,
sr.mainPageLinksDynamics,
sr.domainRank
from google_results gr join serpstat_results sr on gr.id = sr.id
;
"

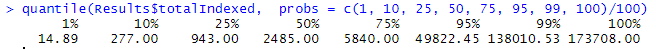
Большой прелестью R в данном случае является то, что у нас остался исходный объект (Results, содержащий импортированные данные из БД), новый (df, dataframe с теми же результатами) и мы можем использовать при необходимости любой из них. Поэтому теперь ничто не мешает заняться анализом.
Также я не буду описывать базовый синтаксис (который легко гуглится или находится в официальной документации) и применяемые математические модели (тут желательно заполнить прорехи базового матанализа, если таковые есть, или пройти подходящий курс. Или как я — просить Data Scientist объяснить моменты, которые непонятны :) )
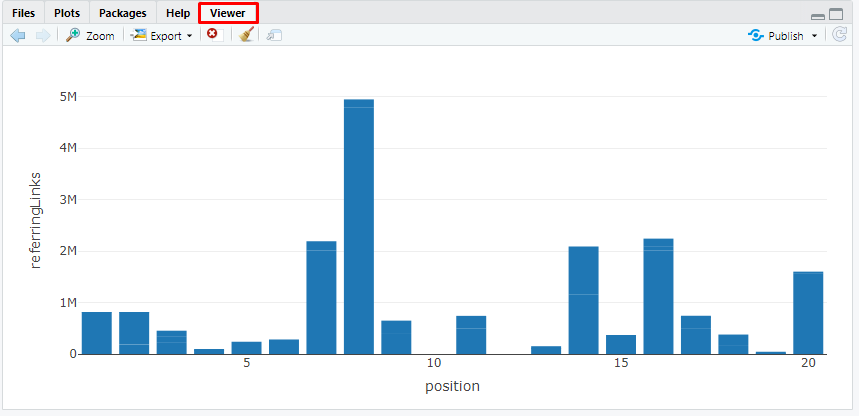
Например, можно построить график позиций в выдаче по выбранным ключевым словам и посмотреть количество входящих ссылок на домен, суммарное для каждой позиции (помните про ограничение Serpstat? Это как раз тот момент, где данные могут быть немного неточными).
library(plotly)
pg <- plot_ly(df, x = ~position, y = ~referringLinks, type = 'bar')
pg
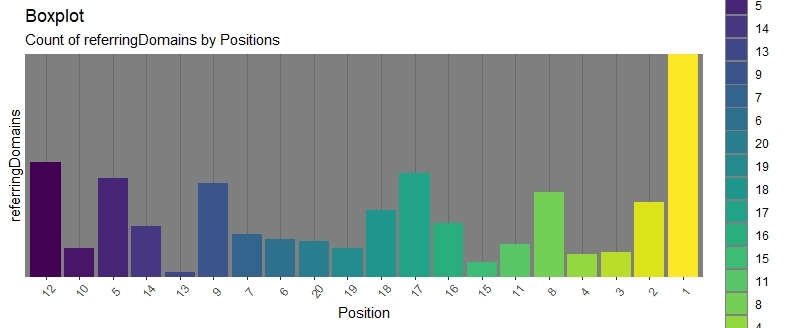
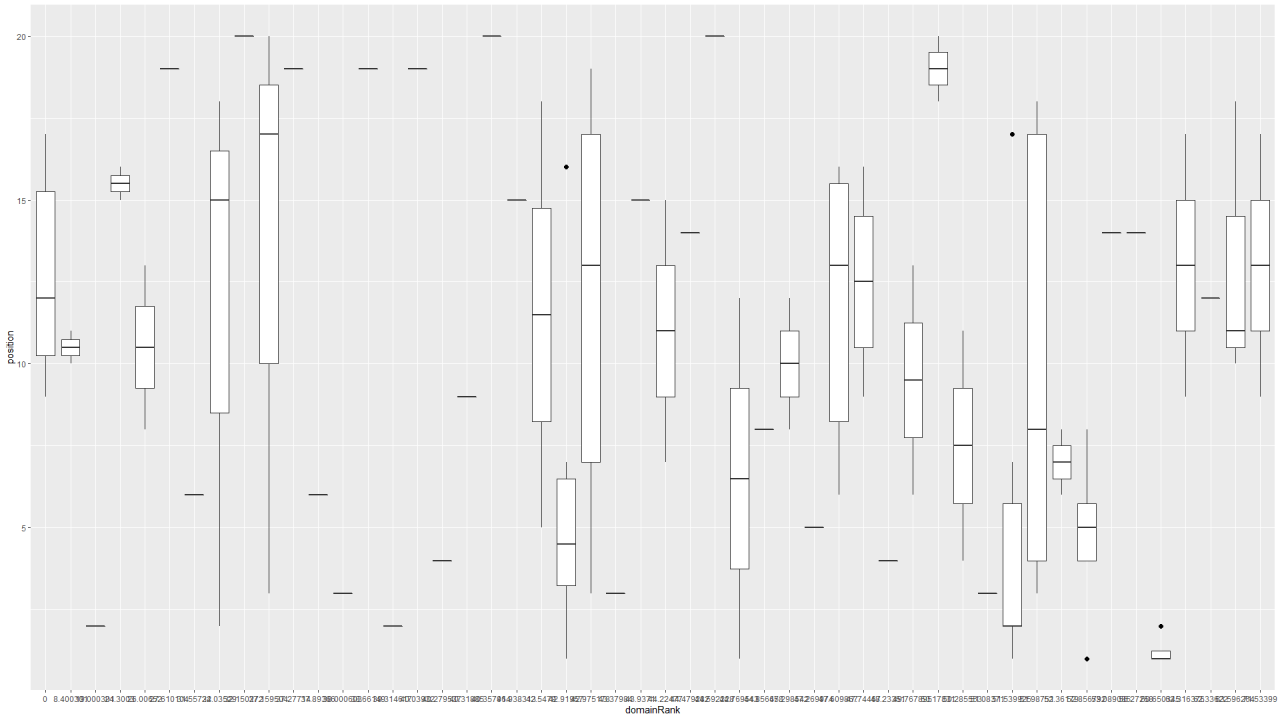
Здесь точки и полосы все основных боксов и их «усов» обозначают максимальную позицию в пределах выбранного диапазона обратных ссылок, а горизонтальные полоски внутри боксов — медианное значение позиции в выдаче при соответствующем количестве обратных ссылок. Исходя из этого можно заметить большой разброс и предположить 2 вещи:
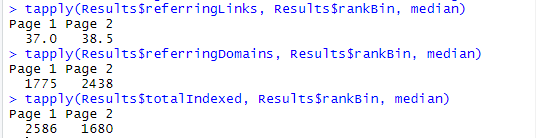
Например, с помощью tapply мы можем посмотреть медианные значения количества обратных ссылок для доменов, уникальных доменов и проиндексированных страниц, находящихся на первой и второй страницах выдачи:
Но не ссылками едиными. У Serpstat есть интересный параметр — domainRank (как он считается мы, вероятно, никогда не узнаем), по которому можно поставить несколько разного рода гипотез.
Для начала убедимся, что эти данные также подгрузились корректно и мы можем ими оперировать:
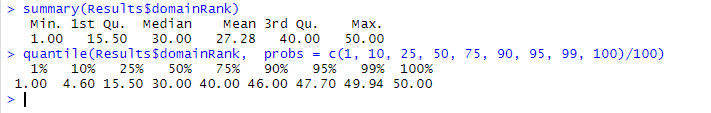
И проверим с помощью tapply базовую информацию:

Значит, вне топа достаточно много активных конкурентов, которые наращивают показатели и готовятся войти в топ-10.
Можем посмотреть то же, но в разрезе позиций, а не целых страниц, чтобы убедиться в правильности расчетов:

После открытия доступа к данным по конкретной ссылке можно будет делать более точные прогнозы (например, считать медиану обратных ссылок для выхода на первую позицию), которые более благотворно повлияют на работу. Или же исследовать оставшиеся показатели для выявления других закономерностей.
Что важно — за минимальное количество затраченного времени и средств (только за доступ к API Serpstat) появилась возможность использовать мощные аналитические инструменты в работе SEO. Также это является основой для других, более объемных данных, которые можно постепенно наслаивать.
Важно помнить, что алгоритмы ранжирования поисковых систем все время меняются как в целом, так и в отдельных нишах (вспомните, например, медицинский апдейт), поэтому нужно успевать отслеживать происходящие изменения. Аналитика данных из разных источников позволяет это делать своевременно и даже немного забегая наперед.
Желаю всем высоких позиций, отсутствия санкций и хорошего поведения пользователей на сайтах! :)
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.