Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Основные ошибки в оптимизации сайта
и как их выявить
и как их выявить


Ну что ж, не буду вас томить, начнем ;)
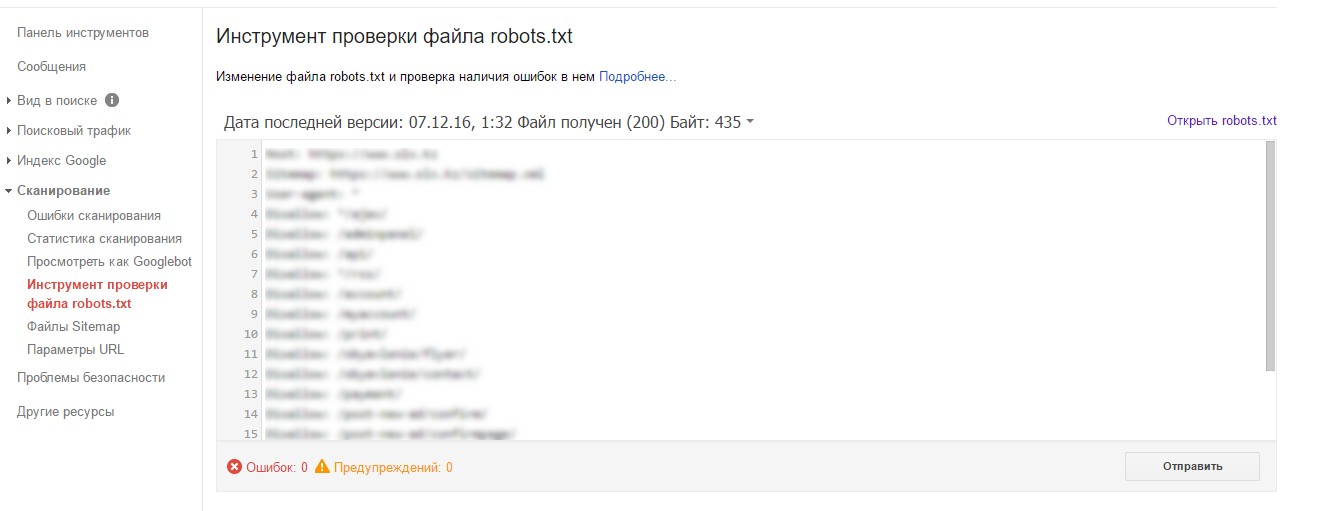
Проверяем файл robots.txt
Запомните, robots.txt — это всего лишь рекомендация, то есть поисковые системы могут игнорировать его — сканировать запрещенные страницы. Тем не менее, файл все равно должен быть правильно составлен.
Что должно быть в robots.txt?
User-agent: *
Allow: /
Sitemap: http://site.com/sitemap/
А для тестового сайта вот что:
User-agent: *
Disallow: /
Host: site.com
Разбираем:

Как закрыть страницу от поисковых систем?
Чтобы закрыть страницу от индексации, используйте атрибут noindex между тегом <head>:
<meta name="robots" content="noindex"> — если нужно закрыть от всех роботов поисковых систем
<meta name="googlebot" content="noindex"> — если нужно закрыть только от робота Google. Однако с Google есть свои нюансы, подробно изучите их в официальной справке.
Также можно использовать технологию SEOHide для всех ссылок, которые ведут на страницы, которые не должен видеть робот. Немного подробней об этой технологии написано ниже.
Какими бывают ошибки при составлении файла robots.txt?
User-agent: *
Disallow: /
Sitemap: http://site.com/sitemap/
В этом случае сайт будет полностью закрыт от сканирования.
И еще один пример:
User-agent: /
Allow: *
Sitemap: http://site.com/sitemap/
В данном случае ничего страшного не произойдет, но лучше придерживаться правильного синтаксиса.
Проверить корректность настройки файла robots.txt можно в сервисе Google Search Console:
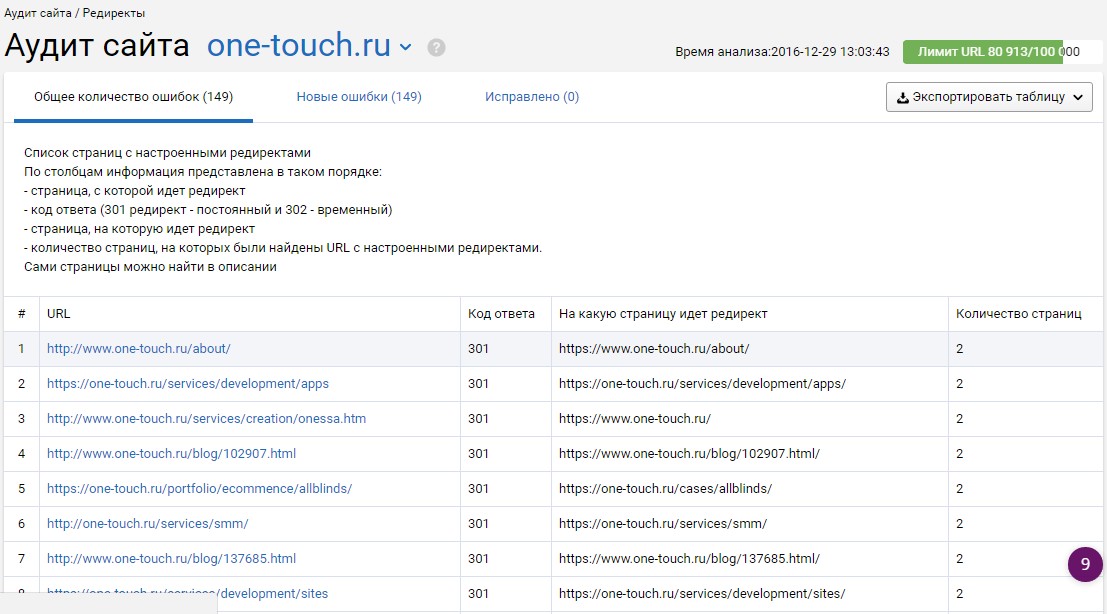
Смотрим редиректы
Проверьте редиректы главной страницы
Проверьте, как поведет себя страница, если убрать слеш в конце
Если страница со слешем не перенаправляет на ту же страницу без слеша или наоборот — это ошибка. Нужно выбрать один вариант, так как поисковые системы будут воспринимать это как две разные страницы, но с одинаковым контентом.
Пример:
http://prom.ua/Odezhda/→ 301 редирект→ http://prom.ua/Odezhda
Поищите внутренние ссылки с несколькими слешами в конце
site.com/cat1////
Если в таком случае не сработает редирект на корректный URL, это плохо. Значит, нужно написать программисту, чтобы сделал редирект на корректный URL.
Проверьте редирект со старых доменов и страниц
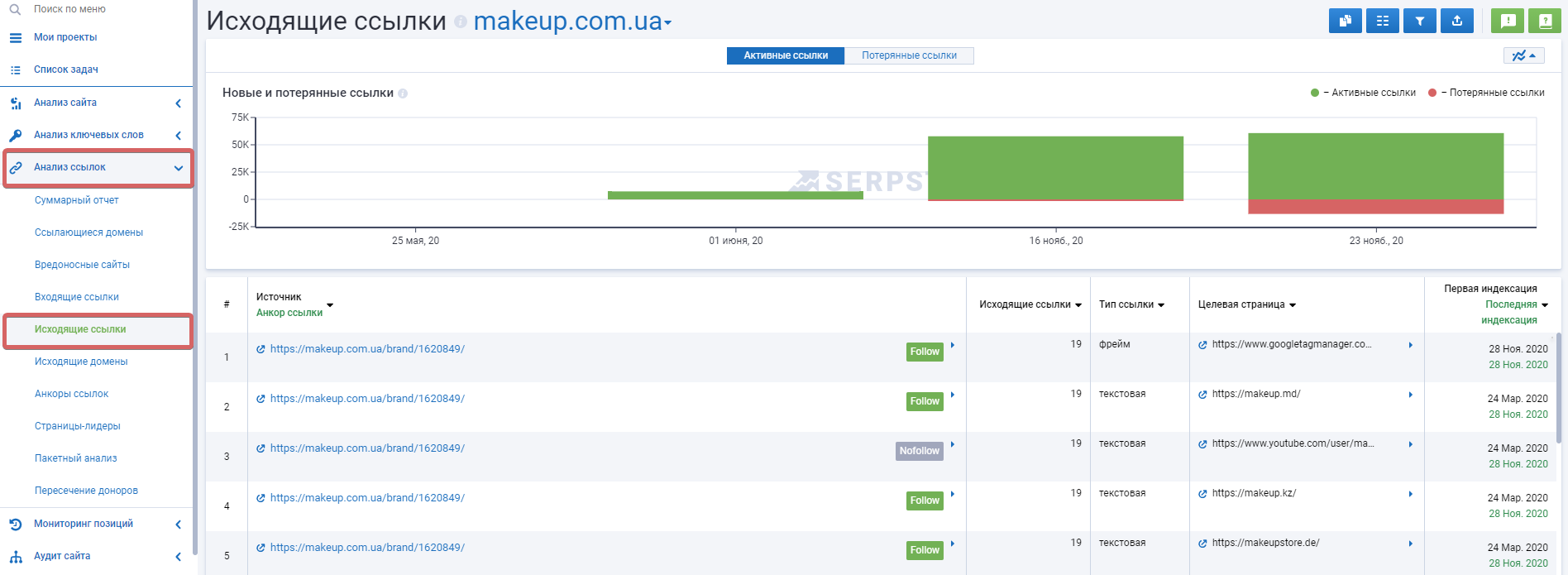
Работаем с исходящими ссылками
Однако нужно помнить, не все исходящие ссылки — это плохо. Например, если у вас информационный сайт и вы отрерайтили новость с другого источника и вставляете на нее ссылку, как на источник — это считается хорошим тоном, и это нормально. Просто следите за количеством исходящих ссылок и контролируйте их качество, с помощью того же Serpstat, например:

Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)
Технология SEOHide
<a hashstring="f45a6597fdf5f85a" hashtype="href">анкор</a>
Тег nofollow для ссылки
Пример закрытой от робота ссылки:
<a href="signin.php" rel="nofollow">Войти</a>
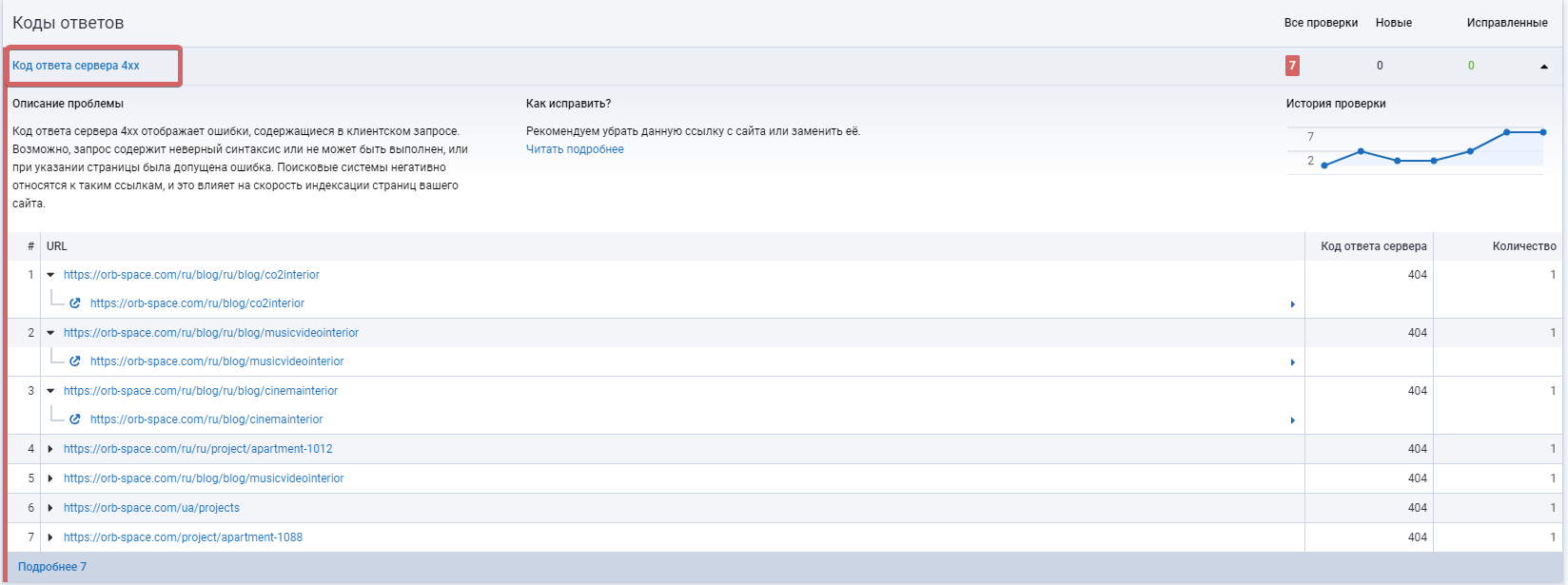
Ищем внутренние ссылки на несуществующие страницы
Как найти ссылки на несуществующие страницы?
Serpstat предоставляет отчет о наличии ссылок на несуществующие страницы:
Как оформить несуществующую страницу?
Хороший пример:
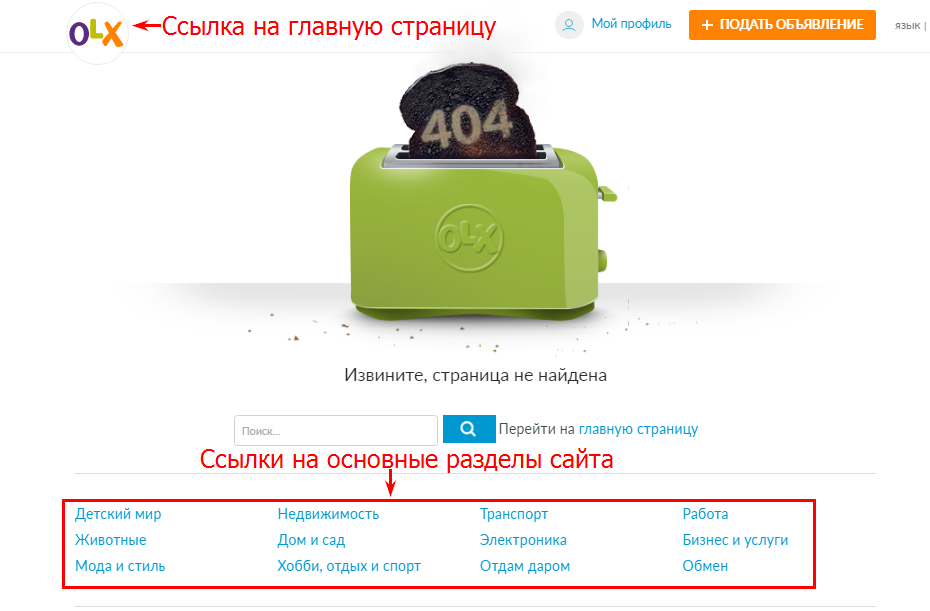
Как проверить какой код отдают несуществующие страницы?
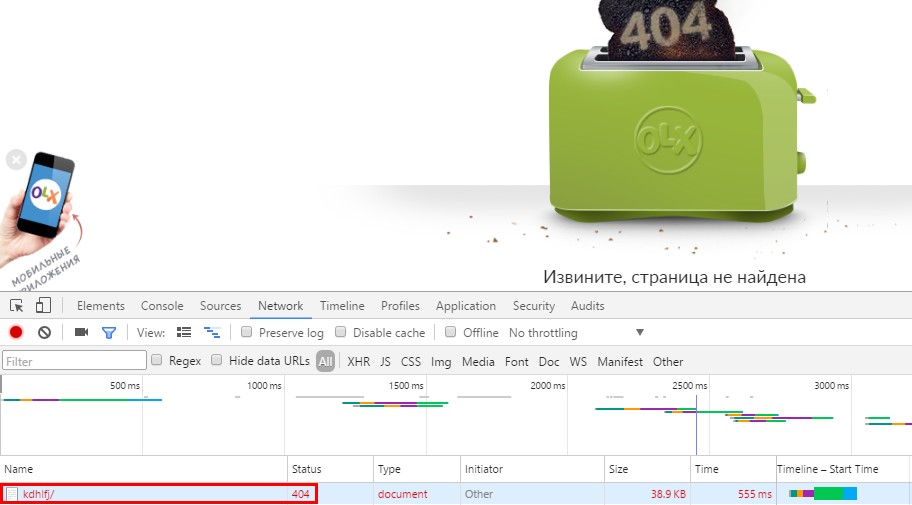
На сайте не должно быть ссылок, которые ведут на 404 страницу. Робот зря переходит по ним и напрасно расходует краулинговый бюджет (количество страниц, которые поисковый бот может обойти за конкретный временной период). А это время он бы мог потратить на сканирование более важных страниц.
Изучаем страницы пагинации
Важно знать: нет идеально метода оптимизации страниц пагинации. У всех вариантов есть свои преимущества и недостатки.
Открываем для сканирования и индексации страницы пагинации
Важные настройки:
Проверяем дубли страниц
Как искать дубли страниц?
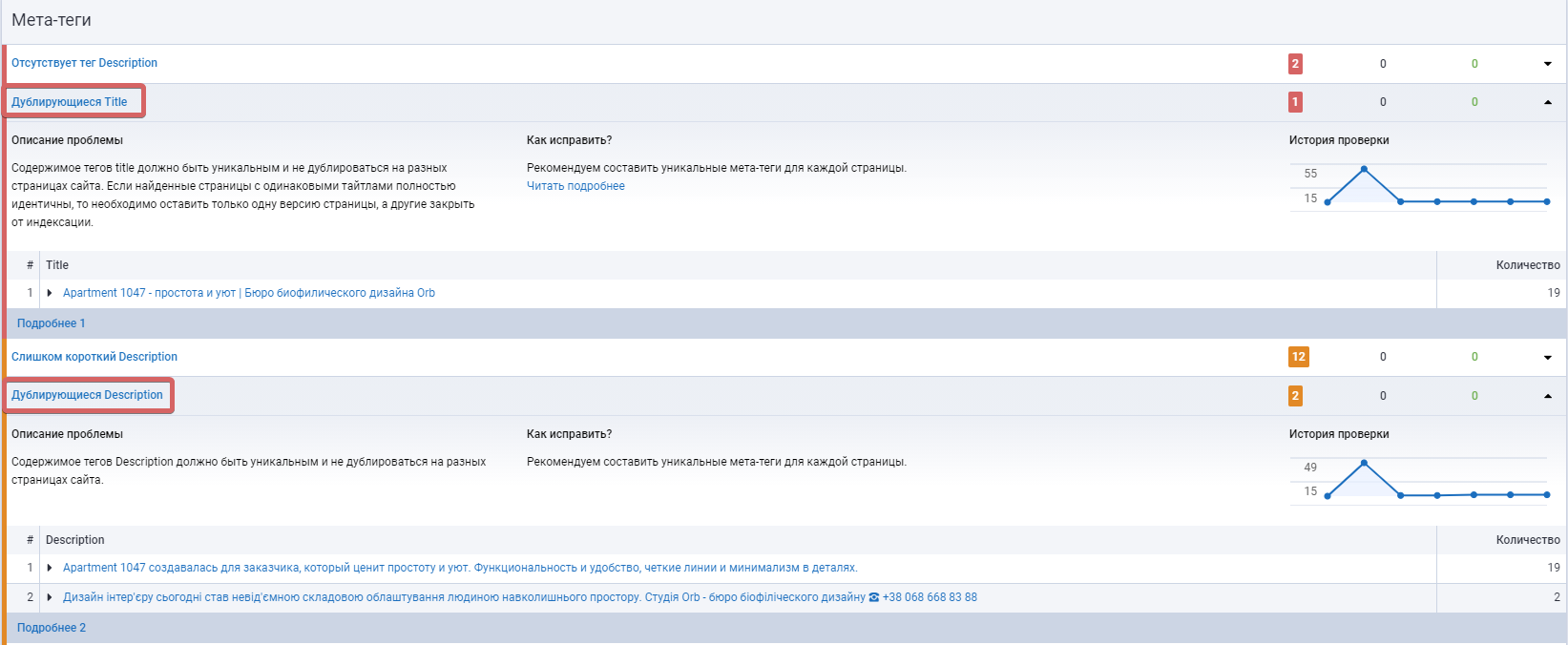
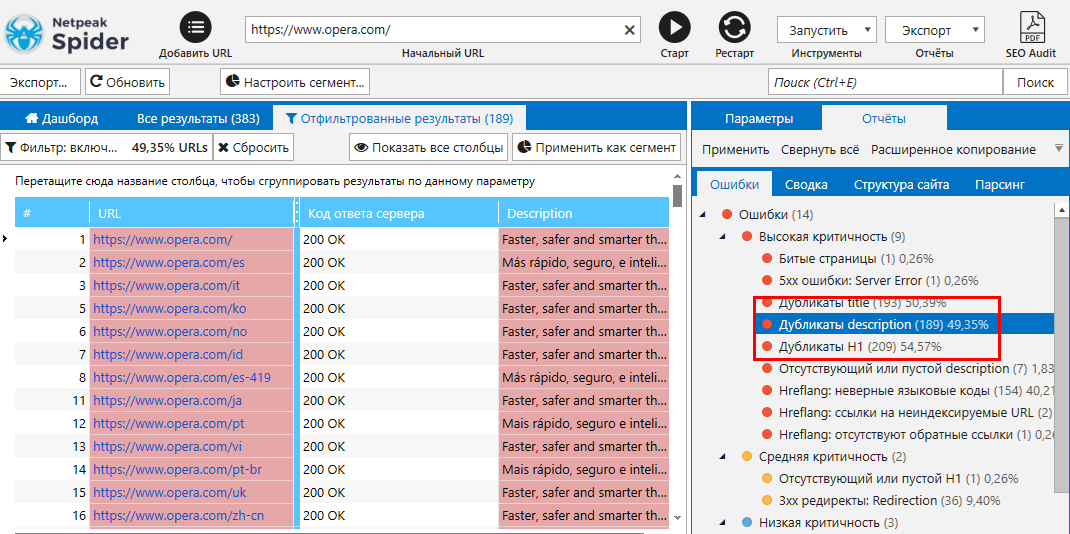
Как бороться с дублями?
<link rel="canonical" href="https://site.com/cat1/" />.
То есть с дублированной страницы бота будет перенаправлять на целевую и будем нам счастье :)
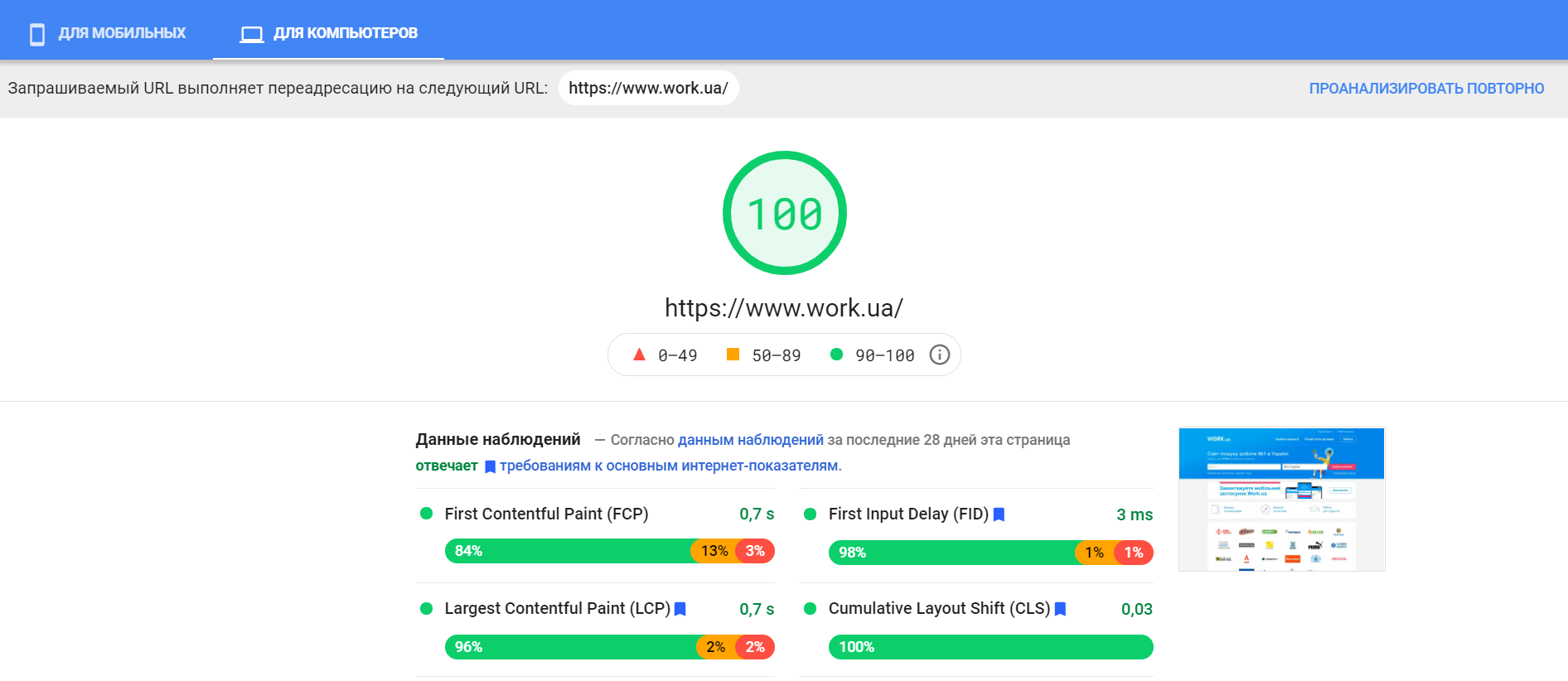
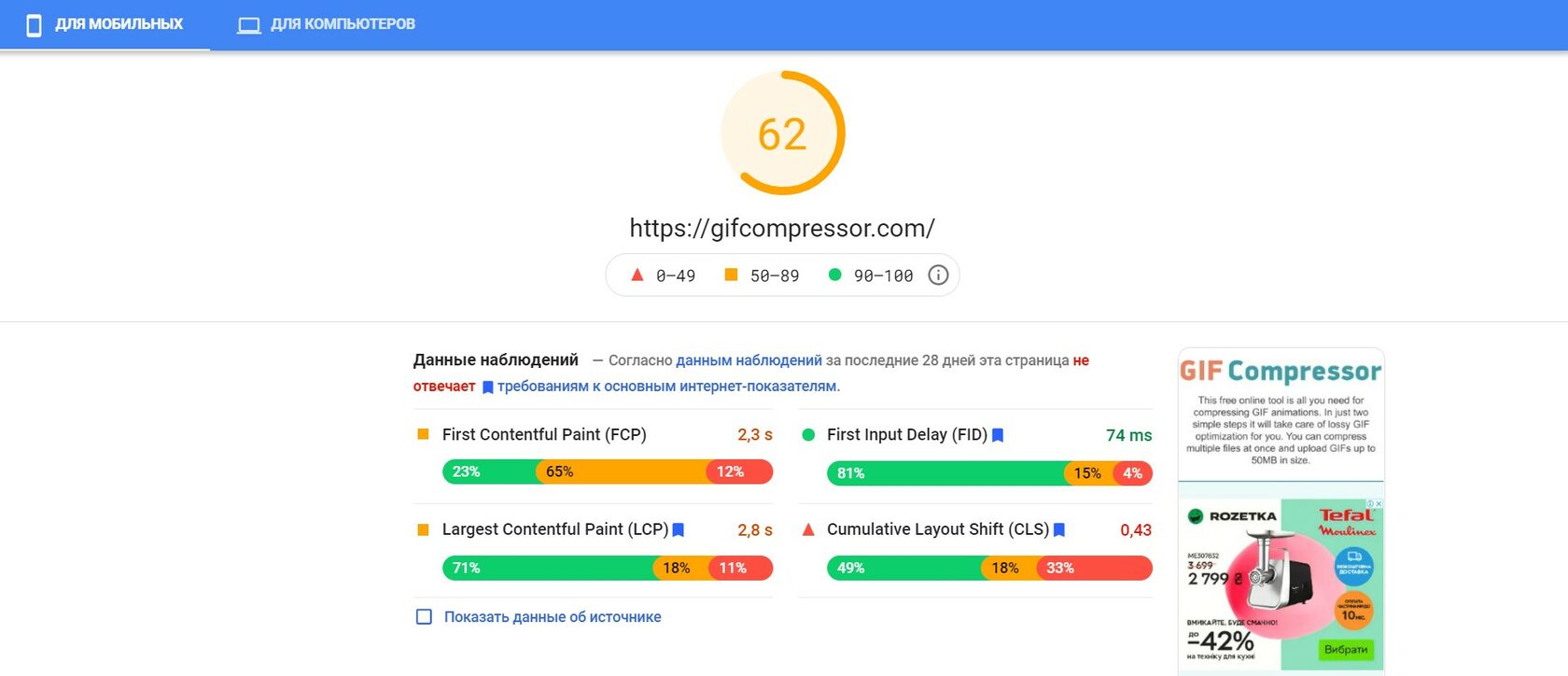
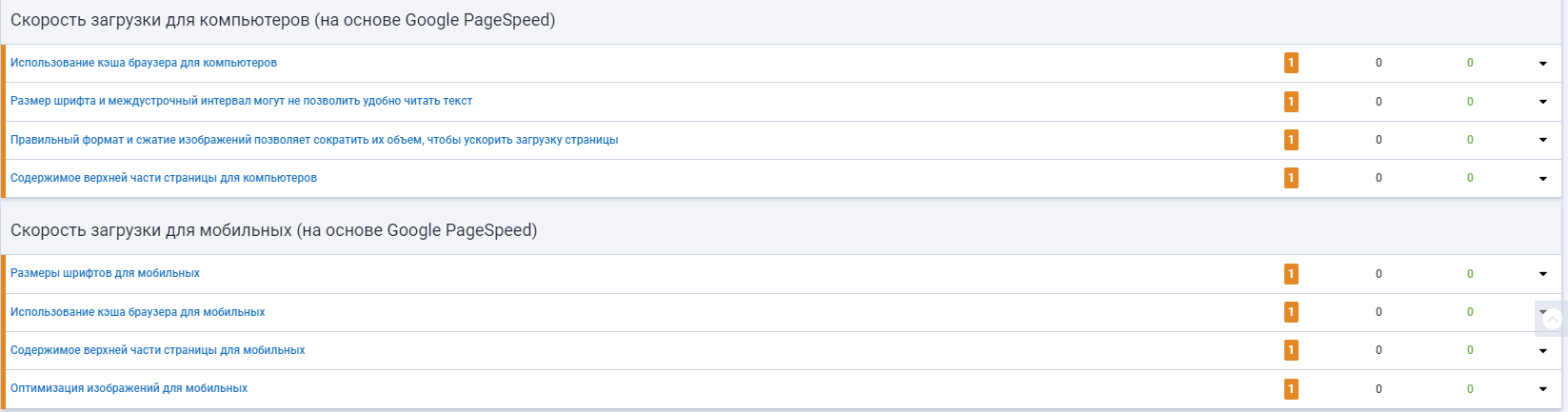
Проверяем скорость сайта
Пример хорошего быстро работающего сайта: www.work.ua
Вместо заключения
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.