Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как найти и удалить дубли страниц на сайте: инструкция для новичков


Дубликаты: в чем опасность?

Сложно, не правда ли? Ведь оба плода на картинке — это яблоки, и оба они красные. То есть, они одинаково релевантны запросу, а выбрать нас просят один, максимально точно соответствующий.
Конечно, поисковик учитывает и другие параметры при ранжировании, такие как внешние и внутренние ссылки, поведение пользователей, но факт остается фактом: из нескольких одинаково красных яблок, Google или других поисковых систем должны выбрать одно. В этом-то и состоит вся трудность.
Возникновение такой дилеммы может привести к различным негативным последствиям:
Какими бывают дубли?
- Полные дублиКогда одна и та же страница размещена по 2-м и более адресам.
- Частичные дублиКогда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Полные дубликаты — откуда они берутся?
Такую проблему еще часто называют: «Не выбрано главное зеркало сайта».
http://mysite.com/index,
http://mysite.com/index/,
http://mysite.com/index.php,
http://mysite.com/index.php/,
http://mysite.com/index.html,
http://mysite.com/index.html/.
Один из этих URL может быть адресом главной страницы по умолчанию.
Когда пользователь приходит по URL адресу с параметром «?ref=…», должно происходить автоматическое перенаправление на URL без параметра, что, к сожалению, часто забывают реализовать разработчики.
Так, например, один и тот же товар может быть доступен по четырем разным URL-адресам:
https://mysite.com/catalog/dir/tovar.php,
https://mysite.com/catalog/tovar.php,
https://mysite.com/tovar.php,
https://mysite.com/dir/tovar.php.
http://mysite.com/olololo-test-olololo
где текст, выделенным красным — это любой набор латинских символов и цифр.
Данные метки нужны для того, чтобы передавать некоторые дополнительные данные в системы контекстной рекламы и статистики. Несмотря на то, что, по идее, они не должны индексироваться поисковыми системами, частенько можно встретить полный дубль страницы с utm-меткой в выдаче.
Полные дубли представляют серьезную опасность с точки зрения SEO, так как критично воспринимаются поисковыми системами и могут привести к серьезным потерям в ранжировании и даже к наложению фильтра, пессимизирующего весь сайт.
Частичные дубликаты — что
представляют из себя?
представляют из себя?
Как правило, каким-то образом меняя выводимый товарный ассортимент на странице категории магазина, страница изменяет свой URL (фактически все случаи, когда вывод не организован посредством скриптов). При этом SEO-текст, заголовки, часто и мета-данные — не меняются. Например:
http://mysite.com/catalog/category/ — стартовая страница категории товаров
http://mysite.com/catalog/category/?page=2 — страница пагинации
При том, что URL адрес изменился и поисковая система будет индексировать его как отдельную страницу, основной SEO-контент будет продублирован.
Достаточно часто можно встретить ситуацию, когда при выборе соответствующей вкладки на странице товара, происходит добавление параметра в URL-адрес, но сам контент фактически не меняется, а просто открывается новый таб.
Данные страницы полностью дублируют ценный SEO-контент основных страниц сайта, но имеют упрощенную версию по причине отсутствия большого количества строк кода, обеспечивающего работу функционала. Например:
http://mysite.com/main/hotel/al12188 — страница отеля
http://mysite.com/main/hotel/al12188/print — ЧБ версия для печати
http://mysite.com/main/hotel/al12188/print?color=1 — Цветная версия для печати.

Найти их можно заменив в оригинальном URL-адресе страницы «!#» на «?_escaped_fragment_=». Как правило, в индекс такие страницы попадают только тогда, когда были допущены ошибки в имплементации метода индексации AJAX страниц посредством перенаправления бота на страницу-слепок и робот обрабатывает два URL-адреса: основной и его Html-версию.
Основная опасность частичных дублей в том, что они не приводят к резким потерям в ранжировании, а делают это постепенно и незаметно для владельца сайта. То есть найти их влияние сложнее и они могут систематически, на протяжении долгого времени «отравлять жизнь» оптимизатору.
C помощью каких инструментов искать дубли?
Мониторинг выдачи посредством оператора «site:»

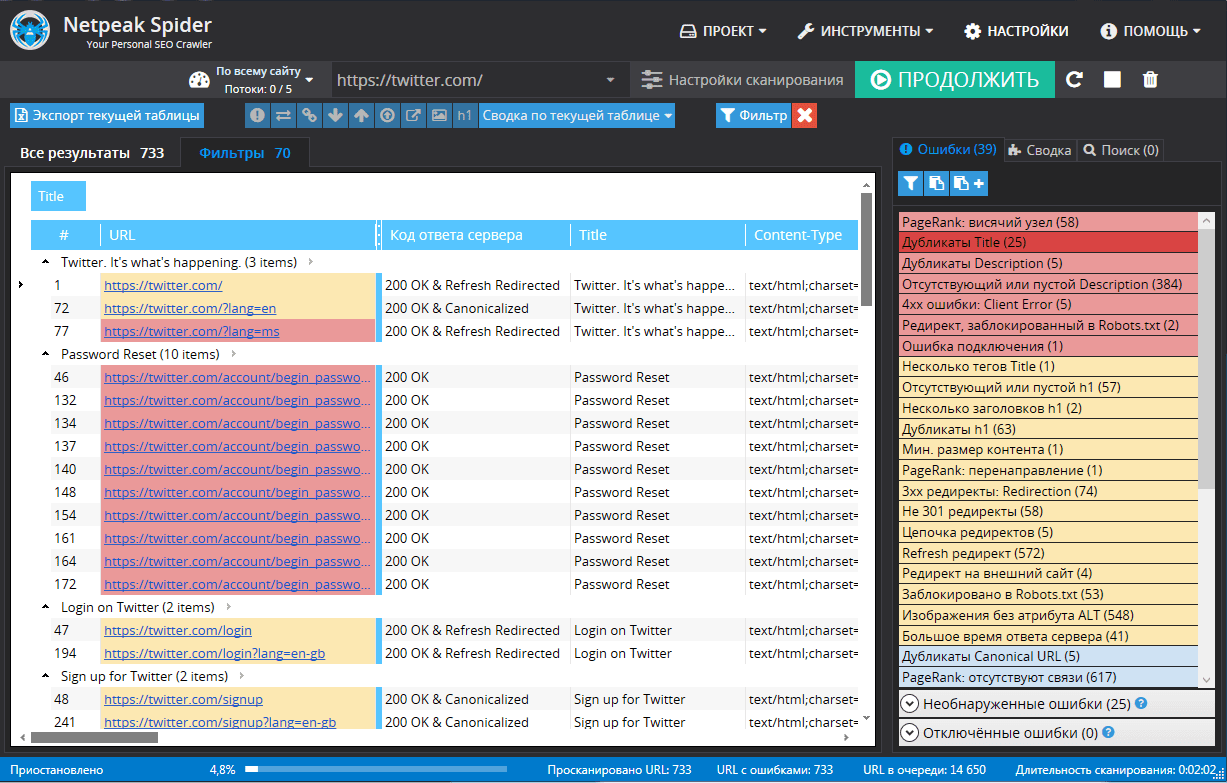
Десктопные программы-парсеры и сервисы
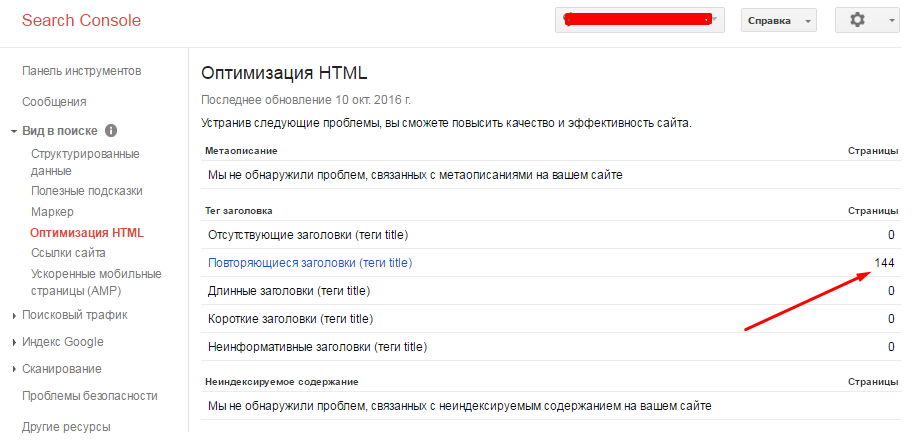
Поисковая консоль Google
Ручной поиск непосредственно на сайте
Как побороть и чем?

Пример установки тега на странице пагинации:
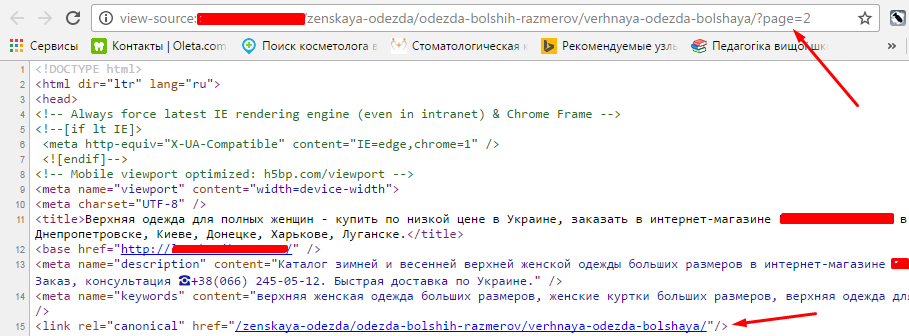
Быстро проанализировать robots.txt, состояние тега canonical поможет:
Как быстро найти дубли страниц на сайте с помощью Serpstat
Аудит сайта Serpstat работает по тому же принципу, что и поисковый робот. Проверка укажет на слабые места вашего сайта, в которых он не соответствует требованиям поисковых систем, и предложит способы исправления этих ошибок. Также можно провести аудит одной страницы.
Для того, чтобы провести проверку сайта на ошибки, необходимо сначала создать проект и сделать соответствующие настройки. Подробнее об этом читайте в статье.
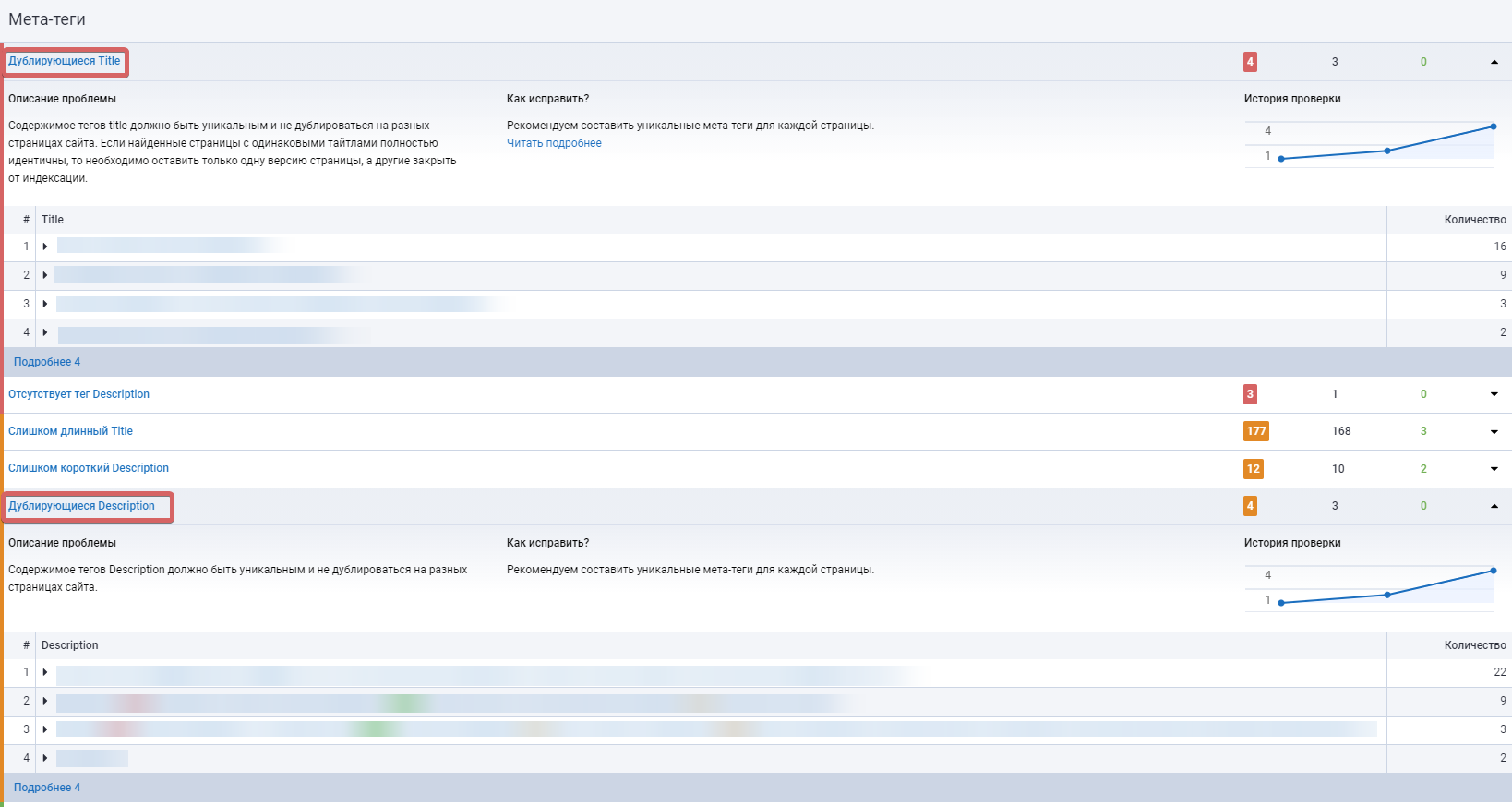
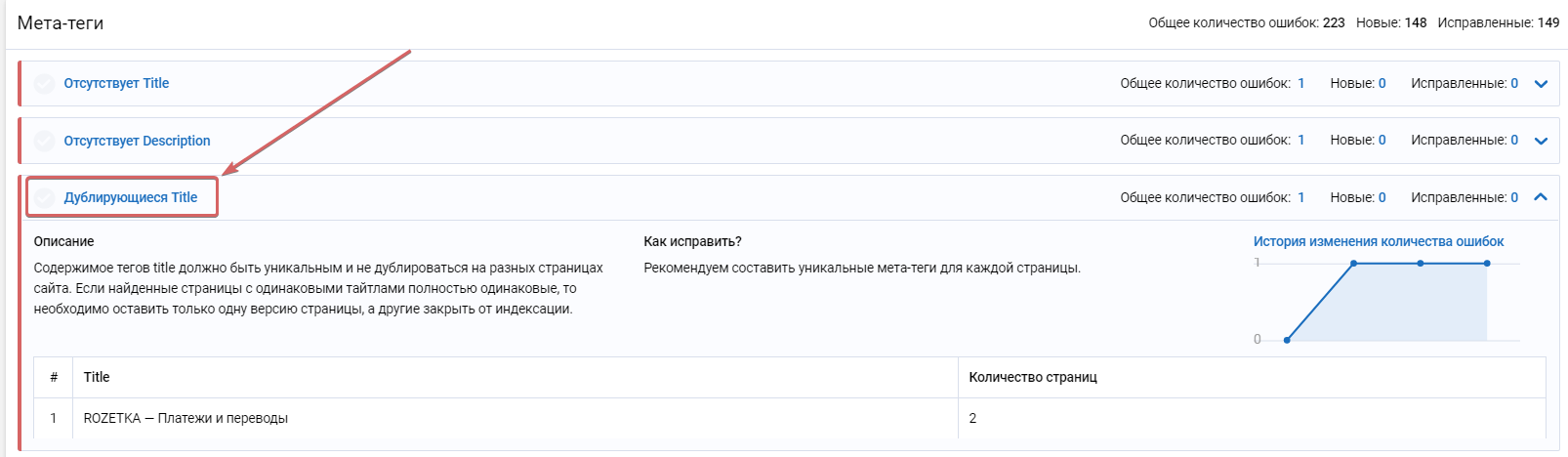
Чтобы найти дубли страниц, в сводке по ошибкам необходимо перейти в раздел «Метатеги» и найти пункт «Дублирующийся Title». Если возле него чек-бокс будет окрашен в серый цвет, значит на вашем сайте найдены такие неполадки.
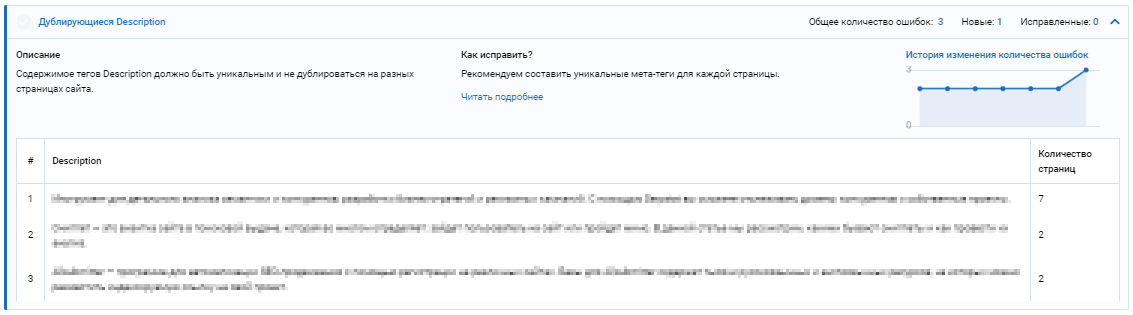
Также косвенно можно найти дубли с помощью пункта «Дублирующийся Description» Следуйте рекомендациям и постарайтесь устранить ошибку как можно скорее.
Заключение
Запомните следующее:
- 1Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
- 2Полные дубли — это когда одна и та же страница размещена по 2-м и более адресам.Частичные дубли — это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
- 3Полные дубликаты нетрудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
- 4Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
- 5Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
- 6Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots.txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name="robots" content="noindex, nofollow"».
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.