Как задать в robots.txt директивы для роботов Google

ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ROBOTS.TXT

Файл robots.txt — это текстовый файл, в котором содержатся инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет. В данной статье рассмотрим, где можно найти robots.txt, как его редактировать и какие правила по его использовать в SEO-продвижении.
Содержание
1. Зачем robots.txt нужен на сайте
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
- Disallow
- Allow
- Sitemap
- Crawl-delay
7. Как проверить работу файла robots.txt
- В Google Search Console
Заключение
2. Где можно найти файл robots.txt и как его создать или редактировать
3. Как создать и редактировать robots.txt
4. Инструкция по работе с robots.txt
5. Синтаксис в robots.txt
6. Директивы в Robots.txt
- Disallow
- Allow
- Sitemap
- Crawl-delay
7. Как проверить работу файла robots.txt
- В Google Search Console
Заключение
Зачем robots.txt нужен на сайте
Командами robots.txt называются директивы, которые разрешают либо запрещают сканировать отдельные участки веб-ресурса. С помощью файла вы можете разрешать или ограничивать сканирование поисковыми роботами вашего веб-ресурса или его отдельных страниц, чем можете повлиять на позиции сайта. Пример того, как именно директивы будут работать для сайта:
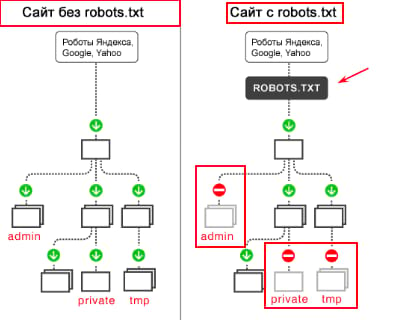
На картинке видно, что доступ к определенным папкам, а иногда и отдельным файлам, не допускает к сканированию поисковыми роботами. Директивы в файле носят рекомендательный характер и могут быть проигнорированы поисковым роботом, но как правило, они учитывают данное указание. Техническая поддержка также предупреждает вебмастеров, что иногда требуются альтернативные методы для запрета индексирования:


Где можно найти файл robots.txt и как его создать или редактировать
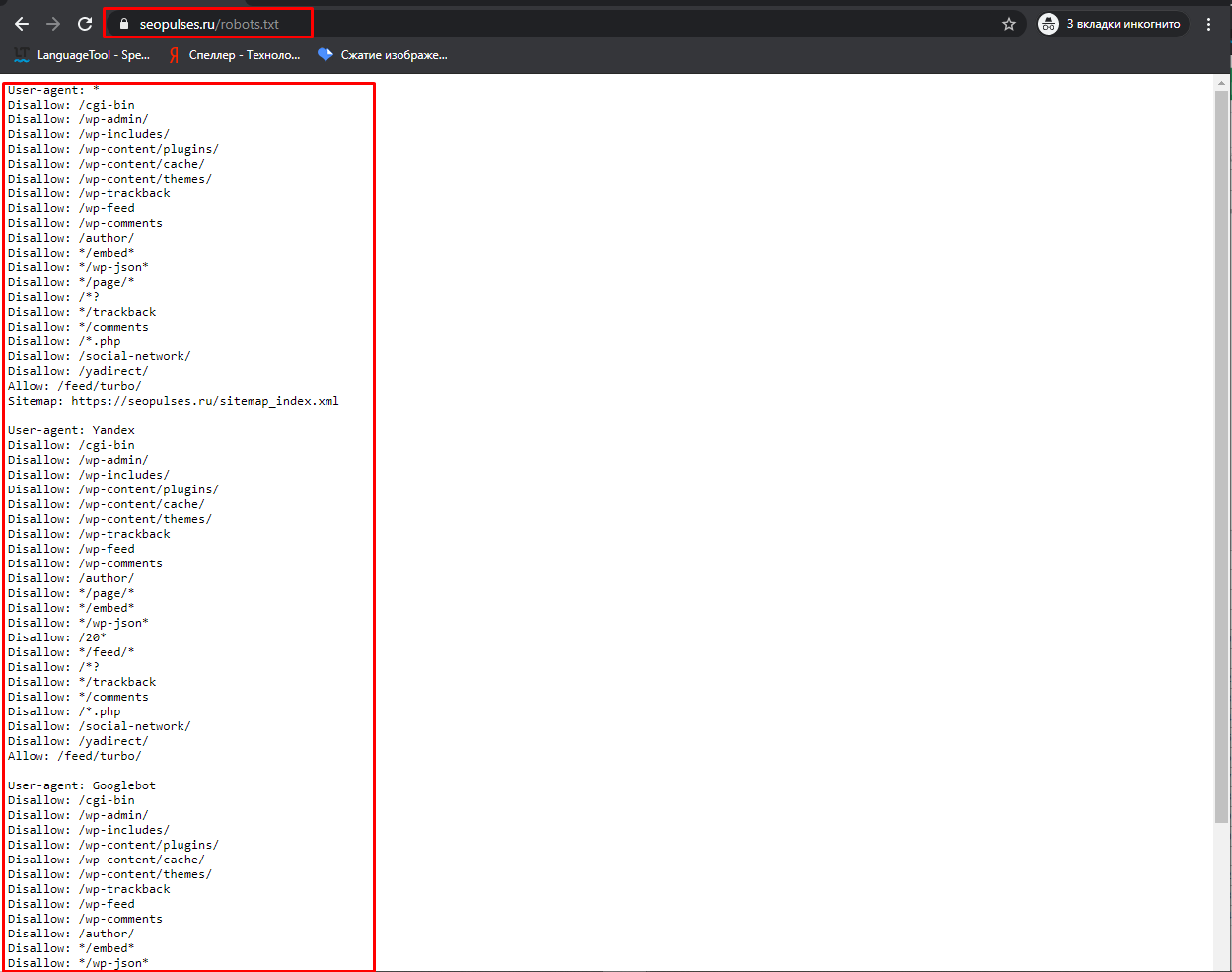
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
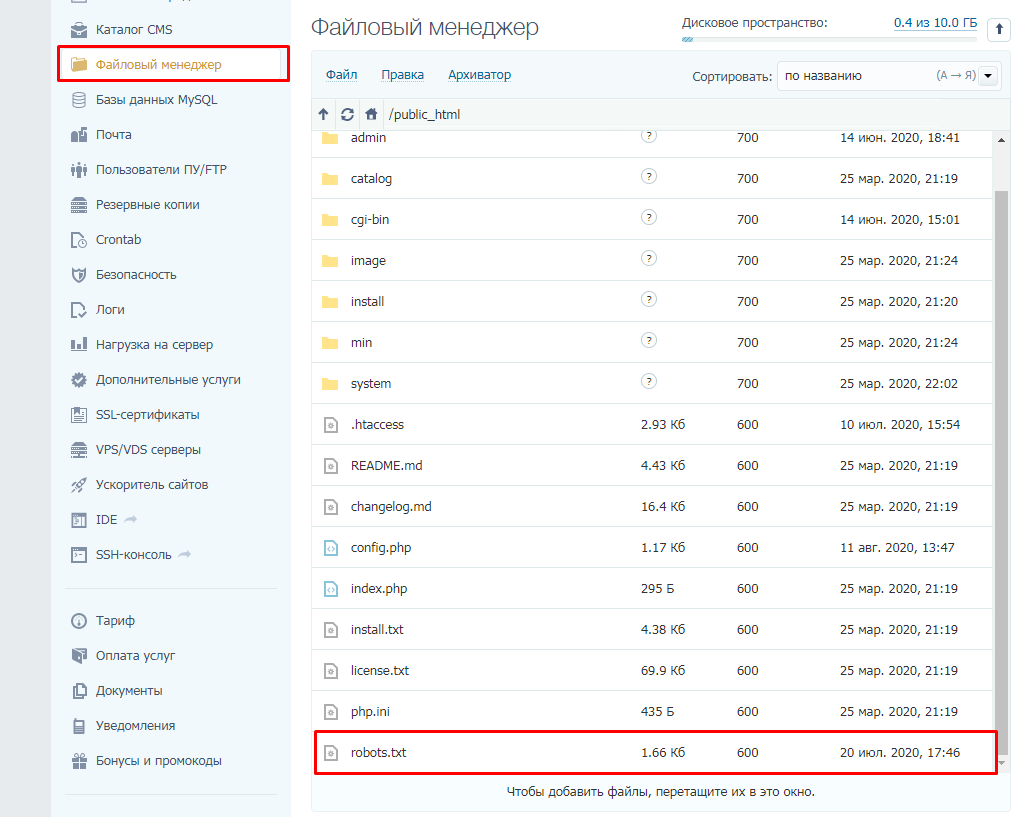
Далее открываем сам файл и можно его редактировать.
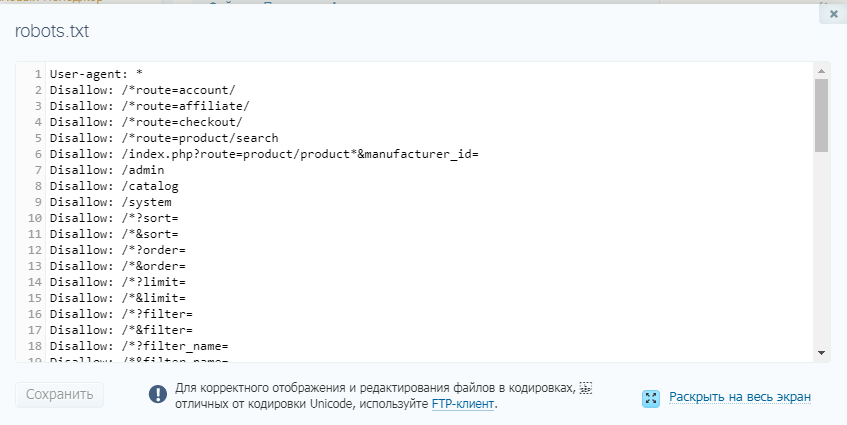
Если его нет, то достаточно создать новый файл.
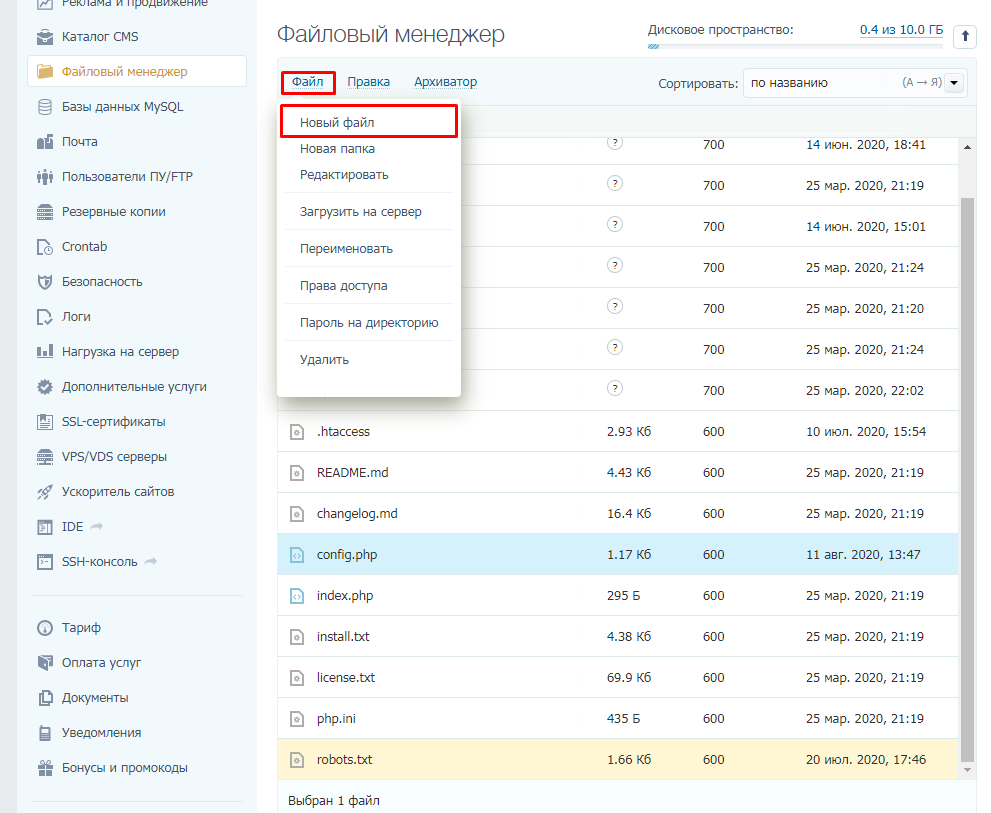
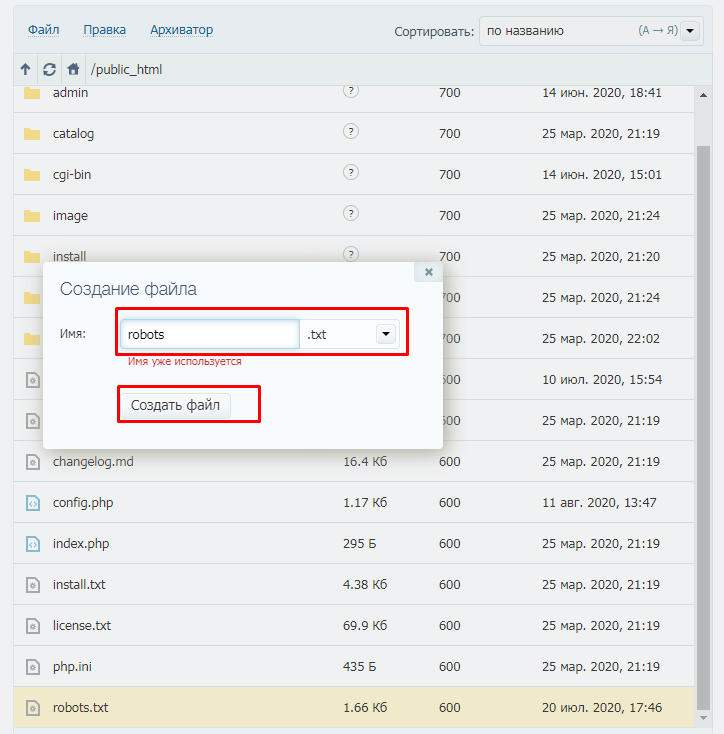
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
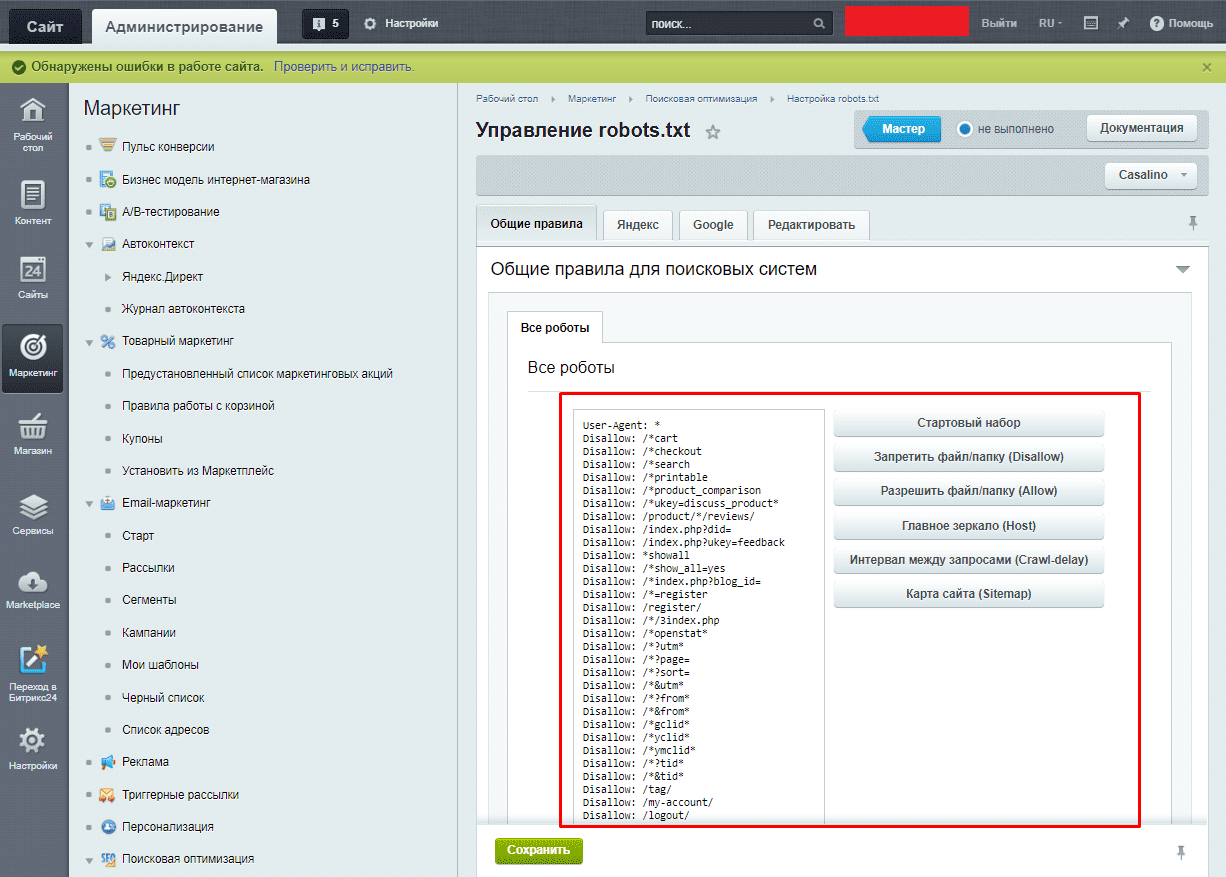
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Googlebot — в случае с краулером Google;
Обращения в robots.txt для Google:
- Googlebot — краулер, индексирующий страницы веб-сайта;
- Googlebot Image — сканирует изображения и картинки;
- Googlebot Video — сканирует всю видео информацию;
- AdsBot Google — анализирует качество размещенной рекламы на страницах для компьютеров;
- AdsBot Google Mobile — анализирует качество рекламы мобильных версий сайта;
- Googlebot News — оценивает страницы для использования в Google Новости;
- AdsBot Google Mobile Apps — расценивает качество рекламы для приложений на андроиде, аналогично AdsBot.
Синтаксис в robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category2/$
User-agent: *
Disallow: /category2/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
Crawl-delay
Важно! Данная директива не поддерживается в Google 1 сентября 2019 года, но работает с другими роботами.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Crawl-delay: 3
Хотите узнать, как использовать Serpstat для поиска ошибок на сайте?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)

Как проверить работу файла robots.txt
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
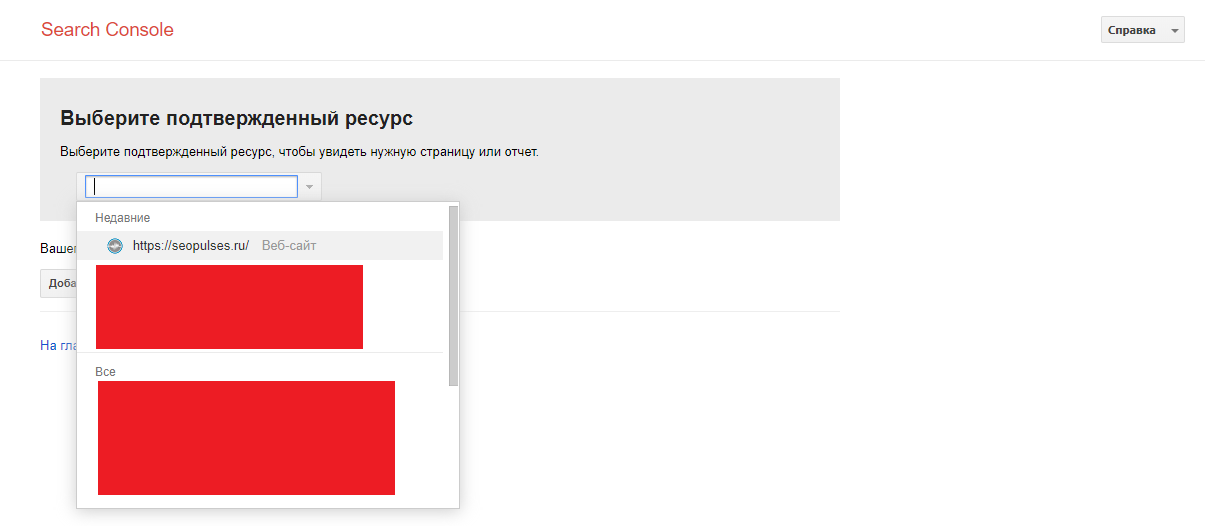
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
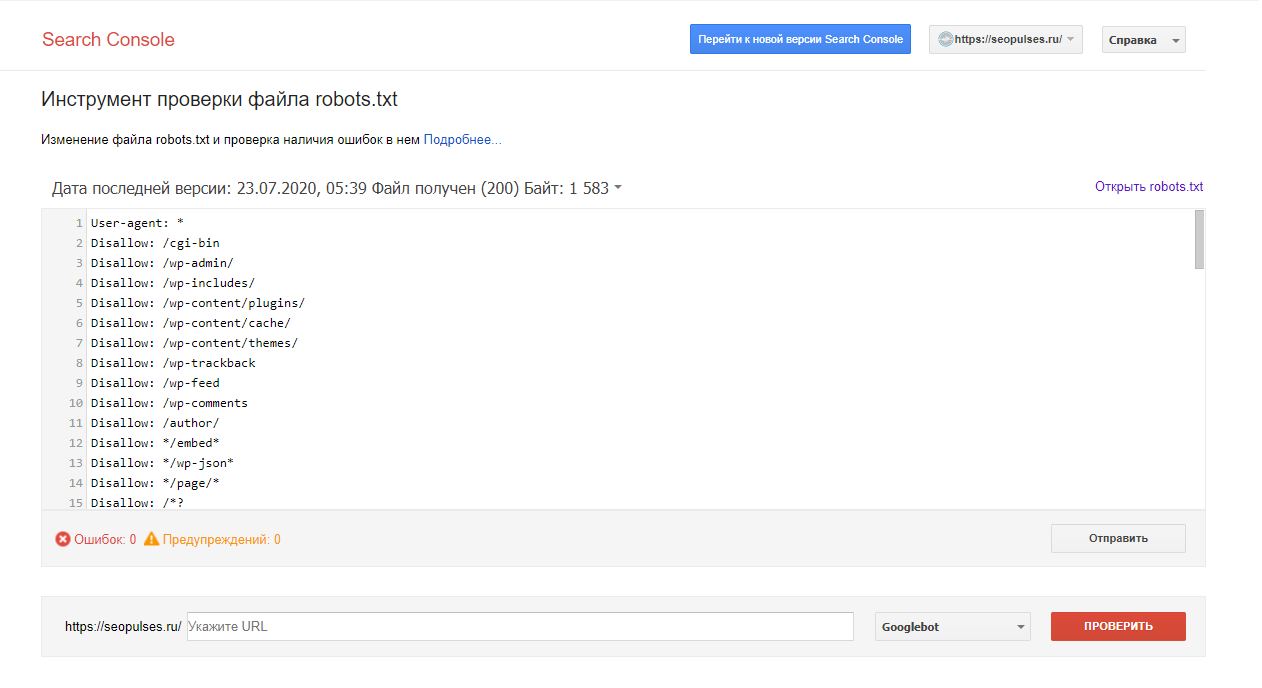
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
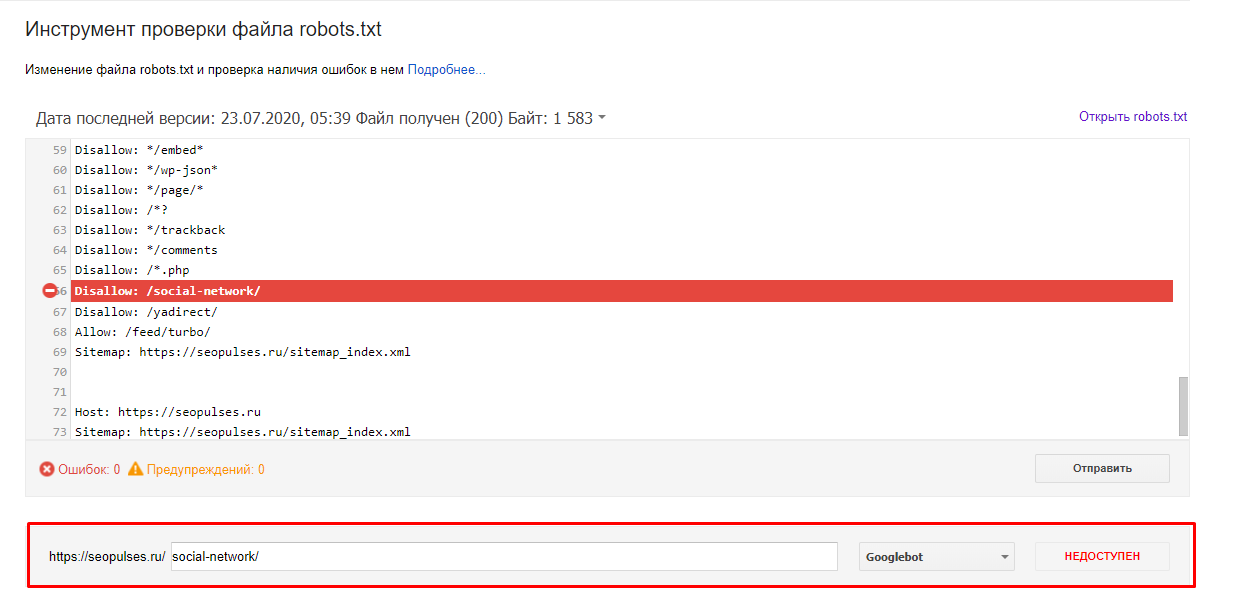
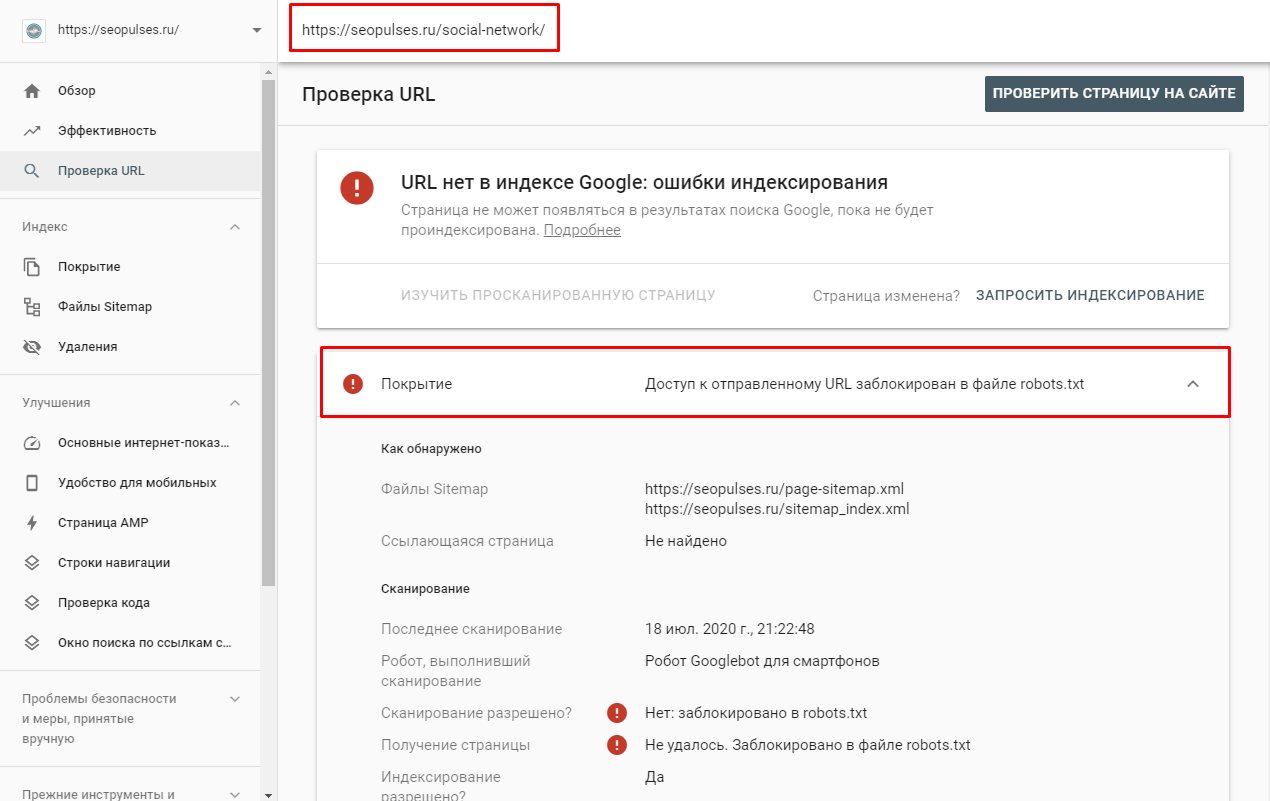
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Заключение
Robots.txt необходим для ограничения сканирования определенных страниц вашего сайта, которые не нужно включать в индекс, так как они носят технический характер. Для создания такого документа можно воспользоваться Блокнотом или Notepad++.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
Пропишите к каким поисковым роботам вы обращаетесь и дайте им команду, как описано выше.
Далее, проверьте его правильность через встроенные инструменты Google. Если не возникает ошибок, сохраните файл в корневую папку и еще раз проверьте его доступность, перейдя по ссылке http://yoursiteadress.com/robots.txt. Активная ссылка говорит о том, что все сделано правильно.
Помните, что директивы носят рекомендательный характер, а для того чтобы полностью запретить индексирование страницы нужно воспользоваться другими методами.
Эта статья — часть модуля «Список задач» в Serpstat

«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.