Как повысить релевантность контента


Ни для кого не секрет, что одним из важнейших факторов ранжирования является текстовый фактор. И даже для опытных SEO-специалистов большую сложность составляет анализ причин низкой релевантности текста.
Что такое анализ релевантности контента?
Допустим, целевая страница сайта плохо ранжируется по нужным ключевым фразам. Это значит, что содержимое страницы необходимо изменить, чтобы повысить ее текстовую релевантность. Именно здесь вам и понадобится инструмент, который формирует рекомендательную базу для оптимизации контента.



Как проводить анализ?
№1 Отслеживайте релевантность ключевых фраз на странице
№2 Собирайте наиболее значимые слова для Title и H1
№3 Расширяйте семантику страницы
№4 Составляйте ТЗ копирайтеру
- Объем текста, который должен быть на странице.
- Все значимые слова тематики, которые должны располагаться в тегах Title и H1.
- Семантику, которая должна быть в Body страницы.
Начните с пробного периода
Улучшайте релевантность контента 7 дней бесплатно. Ознакомьтесь с функциями сервиса, чтобы улучшить лендинги, публикации в блогах и описания товаров.
Отмените в любое время.
ЗарегистрироватьсяАлгоритм анализа
1. Разделяем топ-15 URL-ов в выдаче по заданным поисковым запросам на группы, например: видеозаписи, информационные статьи, каталоги, коммерческие страницы и т.д и определяет к какой группе из них наиболее близок целевой URL.
Возьмем, например, ключевое слово «pool». Вот так выглядит поисковая выдача Google по этому запросу:
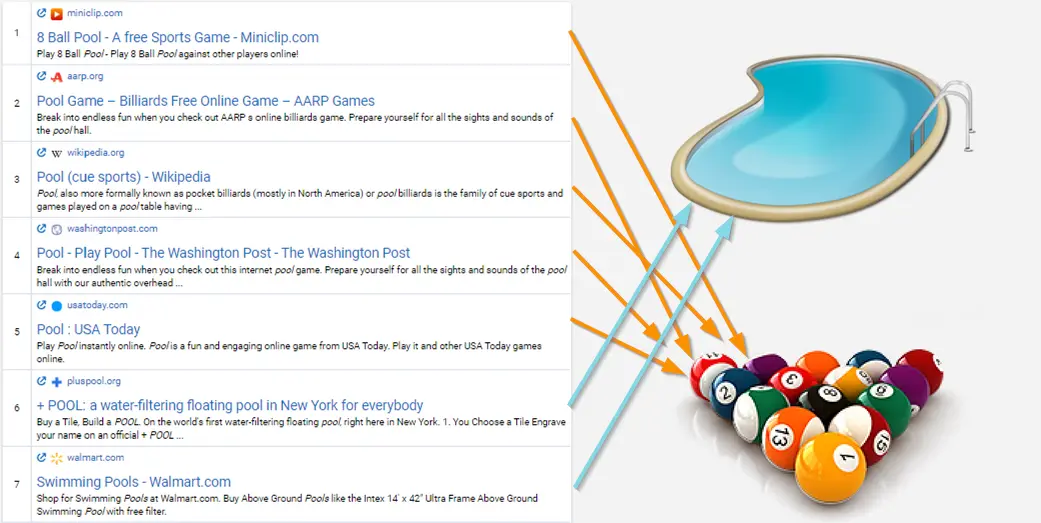
Google предлагает как страницы о бассейнах, так и об игре в бильярд (с англ. «pool»). Мы делим эти результаты на две группы и даем рекомендации на основе тех URL, которые вы добавили вручную или выбрали автоматически (в «Кластеризации»). Соответственно, если страница посвящена только бассейнам, мы исключим из отчета нерелевантные результаты о «pool», как игру в бильярд.
Если вы не добавите при настройках целевую страницу, то рекомендации будут строиться на результатах анализа самой крупной группы конкурентов по фразе.То же самое работает с коммерческими и информационными запросами. Если вы введете macbook в Google, то получите:
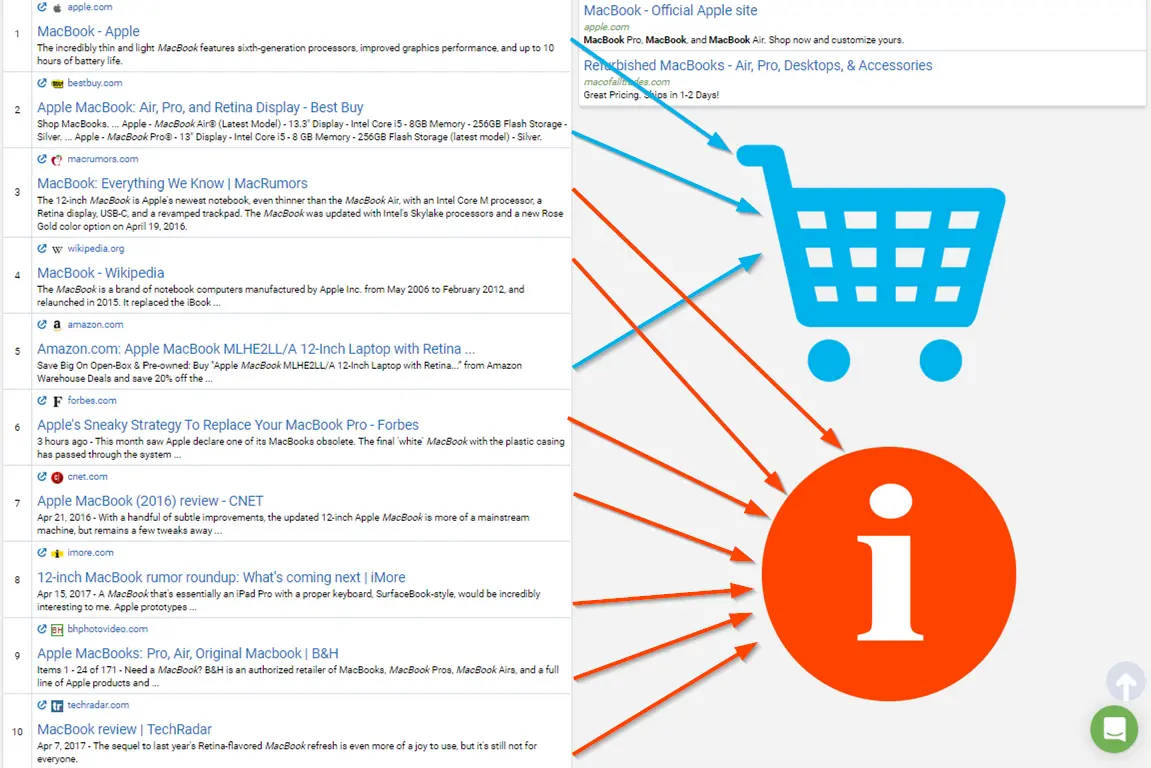
Результаты содержат как информационные страницы, так и коммерческие.
Если вас интересует покупка макбуков, Serpstat проанализирует содержимое вашей страницы, отбросит нерелевантных информационных конкурентов и даст рекомендации на основе анализа коммерческих.
2. На основе анализа других страниц в этой группе даем рекомендации по улучшению текстовой составляющей страницы и увеличения релевантности страницы по отношению к фразам.
На этом этапе мы настраиваем список ключевых слов для каждой области страницы: Title, H1 и Body. Список ключевых слов формируется с помощью трехуровневой метрики «TF-IDF-CDF» (term frequency, inverse document frequency, cluster's document frequency). Ее мы применяем для ранжирования слов, определяющих тематику для целого кластера.
- TF (Term Frequency) учитывает количество вхождений ключа в текст.
- IDF (Document Frequency) контролирует малоинформативные слова — слова встречающиеся в большом проценте текстов, стоп-слова.
- СDF (Cluster's Document Frequency) находит самые значимые для каждого кластера слова — LSI-слова.
Сначала нужно сгруппировать фразы с помощью «Кластеризации». Как это сделать, читайте в статье.

В результате кластеризации мы получаем разные группы ключевых слов. Адреса страниц автоматически назначаются кластерам, если вы указываете домен при создании проекта и если мы находим релевантные кластерам страницы. Если у вас нет сайта и ваша цель — создать контент для будущего домена, можете не добавлять домен или страницу. Далее анализ стоит проводить на основе:
- Целевой страницы, если при настройке вы указали URL.
- Cписка ключевых фраз из кластера, под которые оптимизируется страница.
- Анализа семантики конкурентов из топ-15 выдачи.
Создайте свой первый проект
Начните 7-дневную пробную версию, чтобы бесплатно протестировать инструменты. Используйте эту инструкцию, и не стесняйтесь обращаться к команде поддержки в случае возникновения вопросов.
Отмените триал в любое время.
Зарегистрироваться


Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.