Почніть шукати ключові слова
Використовуйте Serpstat, щоб знаходити найкращі ключі
Як підвищити релевантність контенту


Не секрет, що релевантність контенту є одним з найважливіших факторів ранжування. Аналіз причин низької релевантності тексту є складним завданням навіть для досвідчених SEO-спеціалістів.
Ми автоматизували цей рутинний процес. Розглянемо його переваги, випадки використання та як він працює.
Що таке аналітика тексту?
Припустимо, що цільова сторінка не знаходиться в топі за ключовими словами. У такому випадку є сенс змінити зміст сторінки, щоб підвищити її релевантність заданим пошуковим запитам. Мета — створити рекомендаційну базу для оптимізації контенту на сторінці.



Для чого робити аналіз контенту?
№1 Відстежуйте релевантність ключових фраз на сторінці
№2 Збирайте найбільш значущі ключові фрази для Title та H1
№3 Розширюйте семантику сторінки
№4 Створюйте ТЗ для копірайтера
- Довжину тексту.
- Релевантні ключові фрази для Title та H1.
- Фрази для наповнення Body.
Почніть з пробного періоду
Покращуйте релевантність контенту 7 днів безкоштовно. Ознайомтеся з функціями «Кластеризації» та «Текстової аналітики», щоб покращити лендінги, публікації в блогах та описи товарів.
Скасуйте в будь-який час.
ЗареєструватисяАлгоритм дій
1. Поділяємо топ-15 сторінок у видачі за заданими пошуковими запитами на групи, наприклад: відеозаписи, інформаційні статті, каталоги, комерційні сторінки і т.д. і визначаємо до якої групи з них найближчий цільовий URL.
Візьмемо, наприклад, ключове слово «pool». Ось так виглядає пошукова видача Google за цим запитом:
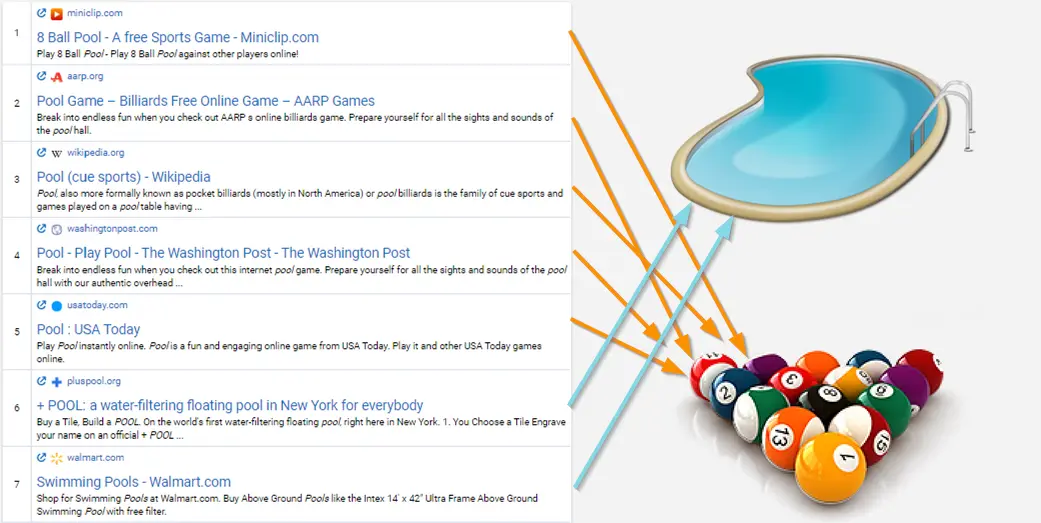
Google пропонує як сторінки про басейни, так і про гру в більярд (з англ. «pool»). Ми ділимо ці результати на дві групи та даємо рекомендації на основі тих URL, які ви додали вручну або обрались автоматично (у «Кластеризації»). Відповідно, якщо сторінка присвячена лише басейнам, ми виключимо зі звіту нерелевантні результати про «pool», як гру в більярд.
Якщо ви не додасте при налаштуваннях цільову сторінку, то рекомендації будуть будуватися на результатах аналізу найбільшої групи конкурентів за фразою. Те саме працює з комерційними та інформаційними запитами. Якщо ви введете macbook у Google, то отримаєте:
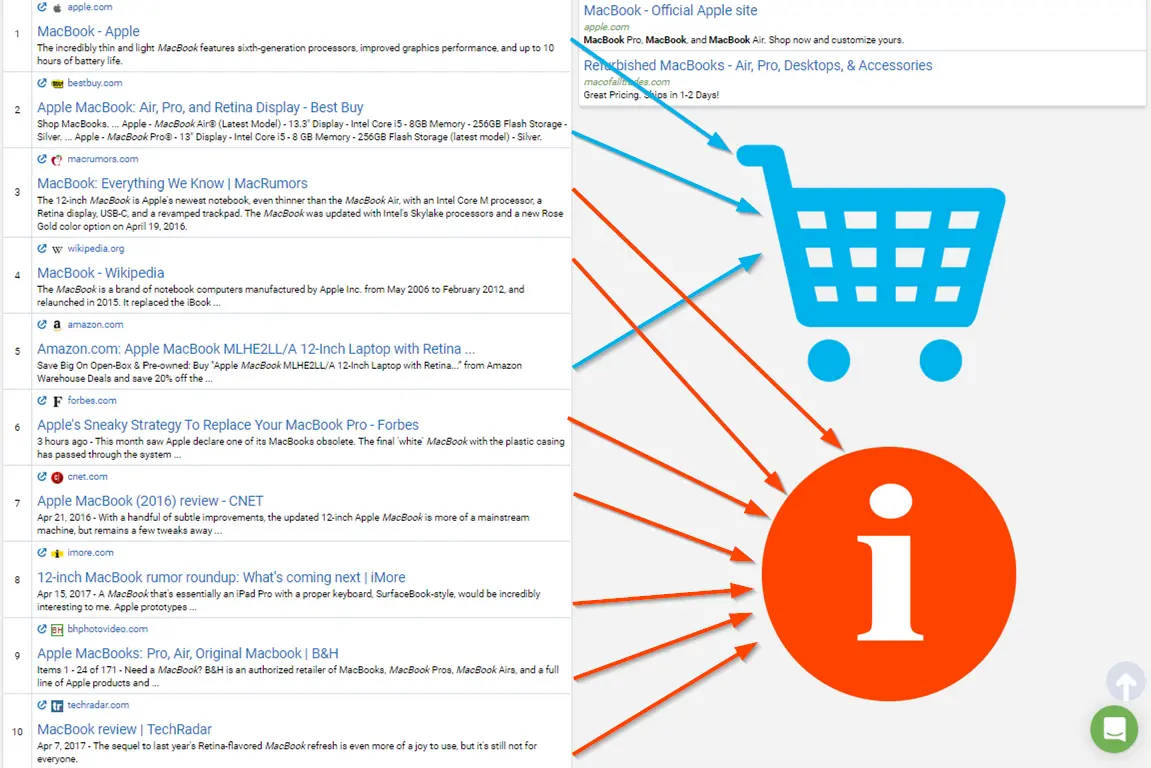
Результати містять як інформаційні сторінки, і комерційні.
Якщо вас цікавить покупка макбуків, Serpstat проаналізує вміст вашої сторінки, відкине нерелевантних інформаційних конкурентів та надасть рекомендації на основі аналізу комерційних.
2. На основі аналізу інших сторінок у цій групі даємо рекомендації щодо покращення текстової складової сторінки та збільшення релевантності сторінки відносно фраз.
На цьому етапі ми налаштовуємо список ключових слів для кожної частини сторінки: Title, H1 та Body. Список ключових слів формується за допомогою трирівневої метрики TF-IDF-CDF (term frequency, inverse document frequency, cluster's document frequency). Її ми застосовуємо для ранжування слів, що визначають тематику цілого кластера.
- TF (Term Frequency) враховує кількість входжень ключа до тексту.
- IDF (Document Frequency) контролює малоінформативні слова — слова, що зустрічаються у великому відсотку текстів, стоп-слова.
- СDF (Cluster's Document Frequency) знаходить найбільш значущі кожному за кластера слова — LSI-слова.

Створіть свій перший проєкт
Почніть 7-денну пробну версію. Не соромтеся звертатися до команди підтримки в разі виникнення будь-яких питань.
Скасуйте в будь-який час.
Зареєструватися


Використовуйте кращі SEO інструменти
Перевірка зворотніх посилань
Швидка перевірка зворотніх посилань вашого сайту та конкурентів
API для SEO
Отримайте швидко великі обсяги даних за допомогою функціонального SЕО API
Аналіз конкурентів
Зробіть повний аналіз сайтів конкурентів для SEO та PPC
Моніторинг позицій
Відстежуйте зміну ранжування цільових запитів використовуючи моніторинг позицій ключів
Рекомендовані статті
Кейси, лайфхаки, дослідження та корисні статті
У вас немає часу стежити за новинами? Не турбуйтеся! Наш редактор підбере статті, які неодмінно допоможуть вам у роботі. Приєднуйтесь до нашої затишної спільноти :)
Натискаючи кнопку, ви погоджуєтеся з нашою Політикою конфіденційності