Кластеризация семантического ядра: алгоритмы и подходы популярных SEO-инструментов


Кластеризация ключевых слов в SEO — это объединение похожих запросов в группы для удобной оптимизации сайта. Эти действия помогают собрать семантическое ядро, разделив ключи для продвижения на удобные целевые группы на основании определенных исходных параметров.
Кластеризация применяется в различных областях: для сегментации рынка, анализа социальных сетей, группировки результатов поиска, медицинской визуализации, сегментации изображений и обнаружения аномалий. В этой статье, мы углубимся в алгоритмы кластеризации не только с точки зрения SEO, но и с позиций кластерного анализа, как важного метода машинного обучения.
Кластеризация применяется в различных областях: для сегментации рынка, анализа социальных сетей, группировки результатов поиска, медицинской визуализации, сегментации изображений и обнаружения аномалий. В этой статье, мы углубимся в алгоритмы кластеризации не только с точки зрения SEO, но и с позиций кластерного анализа, как важного метода машинного обучения.
Что такое кластеризация и для чего она нужна в SEO?
В чем преимущества автоматической кластеризации ключевых слов?
Алгоритмы кластеризации в машинном обучении
Как собрать данные для своего проекта с помощью кластеризации Serpstat?
В чем преимущества автоматической кластеризации ключевых слов?
Алгоритмы кластеризации в машинном обучении
- Общие математические подходы
- Подходы на основе систем искусственного интеллекта
- Логический подход
- Теоретико-графовый подход
Как собрать данные для своего проекта с помощью кластеризации Serpstat?
- Основные настройки кластеризации
- Особенности модуля кластеризации Serpstat
- Практический кейс-исследование
Что такое кластеризация и для чего она нужна в SEO?
Работа с семантическим ядром является основной задачей подготовки любой SEO-стратегии. Для поиска наиболее релевантных запросов в ранжировании, как самого трудоемкого этапа, нужны особые подходы, которые помогут сэкономить время и деньги.
Подготовка SEO-контента с помощью кластеризации, помимо основных преимуществ, делает ваш сайт более понятным для алгоритмов Google.
В широком понимании, кластеризация — это процесс разделения набора объектов на группы, называемые кластерами. Однотипные объекты должны попадать в одну группу, в то же время объекты в разных кластерах должны максимально отличаться. Кластеризация в SEO помогает определить наиболее релевантные ключевые слова и отфильтровать менее приоритетные для лучшего ранжирования.
В 2013 году Google выпустил Hummingbird и этот алгоритм начал фокусироваться на фразах, а не на отдельных ключевых словах, понимая их смысл. В 2015 году появился апдейт RankBrain, способный определять темы поисковых запросов и находить похожие ключевые слова.
Кроме всего прочего, создание кластеров дает больше возможностей для добавления внутренних ссылок на ваш сайт, что повышает вовлеченность пользователей. Перелинковка по темам внутри сайта помогает Google понять, какие страницы являются наиболее важными.
Если у вашего бизнеса есть мультипродуктовые и мультисервисные направления — вы сможете создать больше кластеров на сайте, перелинковать их. В случае продвижения одного продукта или услуги, количество выявленных кластеров будет меньше, но при соответствующих настройках автоматической кластеризации, ваше семантическое ядро можно разбить на подмножества. Изучение основных тематических направлений и расширение семантики большим количеством полезного контента может улучшить вашу конкурентоспособность.
Одним из ключевых принципов эффективного анализа семантики, является понимание мотивов посетителей вашего сайта. Для этого нужно проанализировать не только ключи, которые ваши посетители используют чтобы попасть на сайт, а и термины, которые они ищут находясь на сайте (поиск по сайту).
Подготовка SEO-контента с помощью кластеризации, помимо основных преимуществ, делает ваш сайт более понятным для алгоритмов Google.
В широком понимании, кластеризация — это процесс разделения набора объектов на группы, называемые кластерами. Однотипные объекты должны попадать в одну группу, в то же время объекты в разных кластерах должны максимально отличаться. Кластеризация в SEO помогает определить наиболее релевантные ключевые слова и отфильтровать менее приоритетные для лучшего ранжирования.
В 2013 году Google выпустил Hummingbird и этот алгоритм начал фокусироваться на фразах, а не на отдельных ключевых словах, понимая их смысл. В 2015 году появился апдейт RankBrain, способный определять темы поисковых запросов и находить похожие ключевые слова.
Кроме всего прочего, создание кластеров дает больше возможностей для добавления внутренних ссылок на ваш сайт, что повышает вовлеченность пользователей. Перелинковка по темам внутри сайта помогает Google понять, какие страницы являются наиболее важными.
Если у вашего бизнеса есть мультипродуктовые и мультисервисные направления — вы сможете создать больше кластеров на сайте, перелинковать их. В случае продвижения одного продукта или услуги, количество выявленных кластеров будет меньше, но при соответствующих настройках автоматической кластеризации, ваше семантическое ядро можно разбить на подмножества. Изучение основных тематических направлений и расширение семантики большим количеством полезного контента может улучшить вашу конкурентоспособность.
Одним из ключевых принципов эффективного анализа семантики, является понимание мотивов посетителей вашего сайта. Для этого нужно проанализировать не только ключи, которые ваши посетители используют чтобы попасть на сайт, а и термины, которые они ищут находясь на сайте (поиск по сайту).
В SEO существует два основных типа кластеризации ключевых слов:
на основе лемм (по сходству значений ключевых слов и морфологическим совпадениям);
на основе SERPов (совпадения на страницах результатов поисковой системы)
Мы исследуем оба подхода и протестируем несколько платформ. Один и тот же набор данных будет разбит на кластеры алгоритмами, которые опираются на поисковую выдачу, и на леммы. В заключение, готовые кластеры с похожими алгоритмами мы проверим с помощью Текстовой аналитики, чтобы увидеть текстовую релевантность таких групп.
В чем преимущества автоматической кластеризации ключевых слов?
Автоматическая кластеризация, основанная на машинном обучении, экономит ваше время и выполняет задачу с высокой точностью. Автоматизированные подходы к кластеризации более точны, чем ручные за счет ряда человеческих факторов. SEO-специалисту требуется до трех дней, чтобы кластеризовать тысячу фраз вручную. Высока вероятность добавления фразы в ложный кластер, а также случайная потеря ключевых слов из вашего набора данных. В зависимости от количества ключевых слов и настроек проекта, при использовании автоматической кластеризации подобная задача может быть выполнена за три часа.
- Кластеризация позволяет объединять фразы по смыслу и провести более глубокий анализ вашего пула ключевых слов.
- На основе кластеризации, вы можете создать контент-план и упорядочить наиболее релевантные наборы фраз для продвижения определенных составляющих вашего контента.
- Кластеризация помогает лучше понять интент пользователя. SEO, ориентированное на тематику, предлагает более тщательный ответ на запрос пользователя, т.к. вы ориентируетесь на намерения, а не на охват одного ключевого слова.
- Полученные кластеры помогут вам определить, как должны быть связаны отдельные сегменты вашего контента. Это позволяет вам оценить семантические связи между вашими страницами в общей архитектуре сайта.
- Кластеризация ключевых слов позволит вам создавать более эффективные целевые страницы, что положительно повлияет на привлечение трафика. С помощью иерархической кластеризации можно организовать структуру своего веб-сайта с нуля.
- Кластеризация помогает облегчить общую структуру вашего веб-сайта и UX, сделать его более удобным для посетителей.
- Ключевые слова из одного кластера можно размещать на соответствующей странице без риска каннибализации трафика или появления смешанного контента на сайте.
- Некластеризованные ключевые слова можно использовать для других целей. Благодаря группировке ключевых слов вы можете повысить видимость и авторитет вашего сайта как для пользователей, так и для поисковых систем.
- Автоматическая кластеризация ключевых слов дает вам все вышеперечисленные преимущества быстро и эффективно.
Существуют различные подходы к автоматической группировке ключевиков. Например, используя «Soft» кластеризацию, некоторые инструменты ориентируются на ключевое слово с наибольшей частотностью и сравнивают определенный топ из выдачи по этой фразе, с результатами, показанными для других ключевых слов. Таким образом, результат кластеризации зависит от количества совпавших URL-адресов в выдаче по каждой фразе, с выдачей по высокочастотному ключу — центроиду этого кластера. Когда количество общих URL-адресов достигает уровня заданной точности группировки ключевых слов, ключевые фразы будут сгруппированы. При таких подходах группы ключевых фраз связаны, но не обязательно близки по интенту.
Существует также метод «Hard» кластеризации, который требует связи между всеми элементами внутри кластера. Недостатком этого алгоритма является то, что при его использовании возникает часто чрезмерное количество небольших кластеров, которые можно объединить в более крупные. Высокоточная «Hard» кластеризация может игнорировать сходство между несколькими группами. Таким образом, семантически близкие ключевые слова, которые алгоритм распределил в отдельные кластеры, могут быть объединены в еще один кластер. Интеллектуальная иерархическая кластеризация объединяет кластеры в суперкластер.
В случае присутствия в списке многозначных ключевых слов, возникновении коллизии, привязка к какой-либо группе будет происходить случайным образом. В теории может получиться так, что один и тот же набор ключевых слов будет попадать в разные кластеры при каждом новом запуске кластеризации.
При использовании ручной кластеризации, вам потребуется разбить каждое ключевое слово на термины, определить их назначение и составить списки ключевых слов на основе необходимых вам параметров. Но проблема по-прежнему в словосочетаниях с разным интентом, особенно сложно перераспределить омонимы и слова с широким значением.
В этом контексте, стоит выделить ключевые слова, которые изменили свое значение в ходе истории. Такие фразы могут способствовать возникновению неожиданных результатов в выдаче, со смешанным интентом, в зависимости от персонализированной выдачи, а также региональных факторов. Примеры таких ключевых слов:
Существует также метод «Hard» кластеризации, который требует связи между всеми элементами внутри кластера. Недостатком этого алгоритма является то, что при его использовании возникает часто чрезмерное количество небольших кластеров, которые можно объединить в более крупные. Высокоточная «Hard» кластеризация может игнорировать сходство между несколькими группами. Таким образом, семантически близкие ключевые слова, которые алгоритм распределил в отдельные кластеры, могут быть объединены в еще один кластер. Интеллектуальная иерархическая кластеризация объединяет кластеры в суперкластер.
В случае присутствия в списке многозначных ключевых слов, возникновении коллизии, привязка к какой-либо группе будет происходить случайным образом. В теории может получиться так, что один и тот же набор ключевых слов будет попадать в разные кластеры при каждом новом запуске кластеризации.
При использовании ручной кластеризации, вам потребуется разбить каждое ключевое слово на термины, определить их назначение и составить списки ключевых слов на основе необходимых вам параметров. Но проблема по-прежнему в словосочетаниях с разным интентом, особенно сложно перераспределить омонимы и слова с широким значением.
В этом контексте, стоит выделить ключевые слова, которые изменили свое значение в ходе истории. Такие фразы могут способствовать возникновению неожиданных результатов в выдаче, со смешанным интентом, в зависимости от персонализированной выдачи, а также региональных факторов. Примеры таких ключевых слов:
- «Тесла»;
- «Корона» (как вирус, светлое пиво или программное обеспечение);
- «Кафка» (как писатель и платформа для потоковой передачи событий);
- «Байрактар» (как и известные тактические беспилотники и турецкая фамилия, с турецкого переводится как «Знаменосец»).
Кластеризация служит цели обнаружения основных тем и распределения условий поиска на разные группы. Этот процесс лучше отработает для сценария, когда темы неизвестны. Классификация, в свою очередь, больше подойдет для известных критериев — размеченных данных, по которым вы хотите сгруппировать ключевые слова. Классификация имеет существенное преимущество перед кластеризацией, поскольку позволяет нам воспользоваться собственными знаниями о задаче, которую мы пытаемся решить. Вместо того, чтобы просто позволить алгоритму кластеризации определить, какими должны быть группы, мы можем сообщить классификатору то, что мы уже знаем об этих данных, к примеру их количество. Алгоритм классификации направлен на то, чтобы найти элементы для наиболее подходящих моделей, классы.
Особенности взаимодействия между компьютерами и человеческим языком изучаются в области науки, называемой Natural Language Processing (NLP, обработка естественного языка). Чтобы дать компьютерам возможность понимать текст и речь почти так же, как люди, развиваются отдельные направления внутри сферы AI (искусственный интеллект; англ. artificial intelligence). Все эти меры помогают оценить, как программы и компьютеры могут обрабатывать и анализировать большие объемы данных на естественном языке. Google совершил исторический сдвиг в понимании интента пользовательского поиска, выпустив BERT (Bidirectional Encoder Representations from Transformers), алгоритм-нейросеть с возможностью предварительного обучения.
NLP сочетает в себе вычислительную лингвистику со статистическими моделями, машинным обучением и моделями глубокого обучения. Лучший пример такой модели — Siri, часть операционной системы iOS. NLP в действии: устройства Alexa и Google Home, автозаполнение в поиске Google и Gmail, программное обеспечение для языкового перевода, проверка орфографии и грамматики, спам-фильтры, поиск и чат-боты.
Особенности взаимодействия между компьютерами и человеческим языком изучаются в области науки, называемой Natural Language Processing (NLP, обработка естественного языка). Чтобы дать компьютерам возможность понимать текст и речь почти так же, как люди, развиваются отдельные направления внутри сферы AI (искусственный интеллект; англ. artificial intelligence). Все эти меры помогают оценить, как программы и компьютеры могут обрабатывать и анализировать большие объемы данных на естественном языке. Google совершил исторический сдвиг в понимании интента пользовательского поиска, выпустив BERT (Bidirectional Encoder Representations from Transformers), алгоритм-нейросеть с возможностью предварительного обучения.
NLP сочетает в себе вычислительную лингвистику со статистическими моделями, машинным обучением и моделями глубокого обучения. Лучший пример такой модели — Siri, часть операционной системы iOS. NLP в действии: устройства Alexa и Google Home, автозаполнение в поиске Google и Gmail, программное обеспечение для языкового перевода, проверка орфографии и грамматики, спам-фильтры, поиск и чат-боты.
Модели обучения без учителя используются для выполнения трех основных задач — кластеризации, ассоциации и уменьшения размерности. Кластеризация — это метод интеллектуального анализа данных для группировки неразмеченных данных на основе их сходств и различий. Этот метод подходит как для сегментации рынка и сжатия изображений, так и для автоматизирования рутинных SEO задач. Ассоциация — это метод обучения без учителя, который использует определенные правила для определения взаимосвязей между переменными и заданным набором данных. Эти методы часто используются для анализа покупательского поведения, создания рекомендаций и выдачи товаров в категории «Вместе с этим товаром, покупают…». Уменьшение размерности — это метод, который используется, когда в определенном наборе данных слишком много измерений, к примеру на этапе предварительной обработки, чтобы удалить шум из визуальных данных и улучшить качество изображения.
Цель обучения без учителя — извлечь полезную информацию из огромного количества новых данных. При обучении с учителем же алгоритм «обучается», делая прогнозы на основе обучающего набора данных и корректируя их до тех пор, пока не получит правильный ответ. Хотя модели обучения с учителем обычно более точны, они требуют прямого вмешательства человека и точной разметки данных. Например, модель контролируемого обучения может рассчитать, сколько времени потребуется, чтобы добраться до работы, в зависимости от времени суток, погодных условий и т. д.
Обучение без учителя требует мощных инструментов для работы с большими объемами неклассифицированных данных. Эти модели самостоятельно изучают внутреннюю структуру неразмеченной информации. Однако они по-прежнему требуют незначительного вмешательства человека для проверки. Например, такая модель неконтролируемого обучения может предположить, что покупатели онлайн-магазина часто покупают определенные продукты одновременно, но специалисту по обработке данных необходимо проверить, имеет ли смысл группировать эти товары и выводить в рекомендации..
Возвращаясь к кластеризации, как методу обучения без учителя, стоит упомянуть, что общепринятой и унифицированной ее классификации не существует. Можно выделить несколько подходов, но некоторые из них относятся сразу к нескольким условным группам. Методологически такие группы имеют значительные различия.
Цель обучения без учителя — извлечь полезную информацию из огромного количества новых данных. При обучении с учителем же алгоритм «обучается», делая прогнозы на основе обучающего набора данных и корректируя их до тех пор, пока не получит правильный ответ. Хотя модели обучения с учителем обычно более точны, они требуют прямого вмешательства человека и точной разметки данных. Например, модель контролируемого обучения может рассчитать, сколько времени потребуется, чтобы добраться до работы, в зависимости от времени суток, погодных условий и т. д.
Обучение без учителя требует мощных инструментов для работы с большими объемами неклассифицированных данных. Эти модели самостоятельно изучают внутреннюю структуру неразмеченной информации. Однако они по-прежнему требуют незначительного вмешательства человека для проверки. Например, такая модель неконтролируемого обучения может предположить, что покупатели онлайн-магазина часто покупают определенные продукты одновременно, но специалисту по обработке данных необходимо проверить, имеет ли смысл группировать эти товары и выводить в рекомендации..
Возвращаясь к кластеризации, как методу обучения без учителя, стоит упомянуть, что общепринятой и унифицированной ее классификации не существует. Можно выделить несколько подходов, но некоторые из них относятся сразу к нескольким условным группам. Методологически такие группы имеют значительные различия.
Алгоритмы кластеризации в машинном обучении
Обучение с учителем (Supervised learning) — это подход к машинному обучению, основанный на использовании размеченных наборов данных. Такие наборы данных более точно предсказывают результаты. С размеченными входными и выходными данными модель может сопоставлять информацию для постепенного обучения. Такой подход содержит в себе два метода: классификацию и регрессию.
При решении задач классификации, например для перераспределения спама в отдельную папку электронной почты, алгоритмы используются с целью категоризации тестовых данных. Линейные классификаторы, опорные вектора, деревья решений и случайный лес — все это распространенные алгоритмы классификации. Модели регрессионного анализа помогают прогнозировать, к примеру будущий доход от продаж, основываясь на точечных данных.
В контексте машинного обучения кластеризация относится к обучению без учителя (Unsupervised learning), система обучается самостоятельно и без предварительно размеченных данных. Эти алгоритмы машинного обучения выявляют закономерности в данных без вмешательства человека. Такие модели создаются для обнаружения аномалий, улучшения рекомендаций, прогнозирования поведения клиентов и т. д.
При решении задач классификации, например для перераспределения спама в отдельную папку электронной почты, алгоритмы используются с целью категоризации тестовых данных. Линейные классификаторы, опорные вектора, деревья решений и случайный лес — все это распространенные алгоритмы классификации. Модели регрессионного анализа помогают прогнозировать, к примеру будущий доход от продаж, основываясь на точечных данных.
В контексте машинного обучения кластеризация относится к обучению без учителя (Unsupervised learning), система обучается самостоятельно и без предварительно размеченных данных. Эти алгоритмы машинного обучения выявляют закономерности в данных без вмешательства человека. Такие модели создаются для обнаружения аномалий, улучшения рекомендаций, прогнозирования поведения клиентов и т. д.
Общие математические подходы
К-means
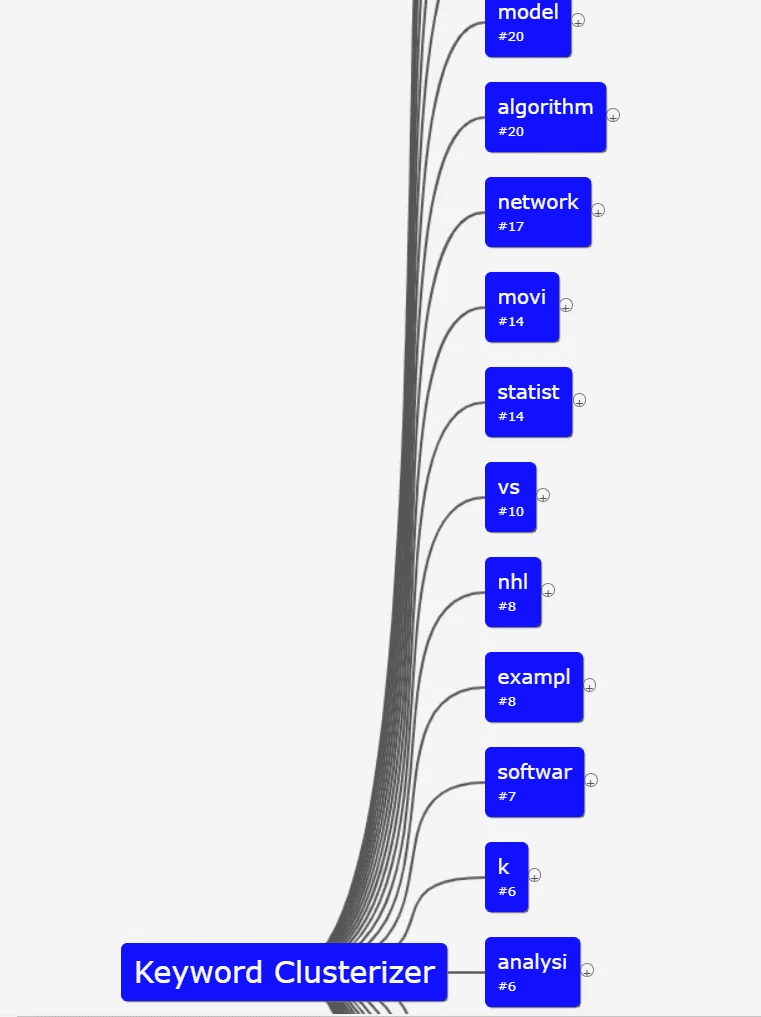
«K» — количество кластеров, заданных для набора данных. Это означает, что перед кластеризацией вы должны знать предполагаемое количество будущих групп. Этот метод можно использовать для рекомендаций, поиска спама или фейковых новостей. Такая кластеризация используется стриминговым сервисом Netflix: вам предоставляется набор фильмов и список отзывов, которые дал каждый оценщик; ваша цель — создать около сотни групп связанных фильмов. Каждая начальная точка «k» служит центральной точкой для одного из таких «k наборов».
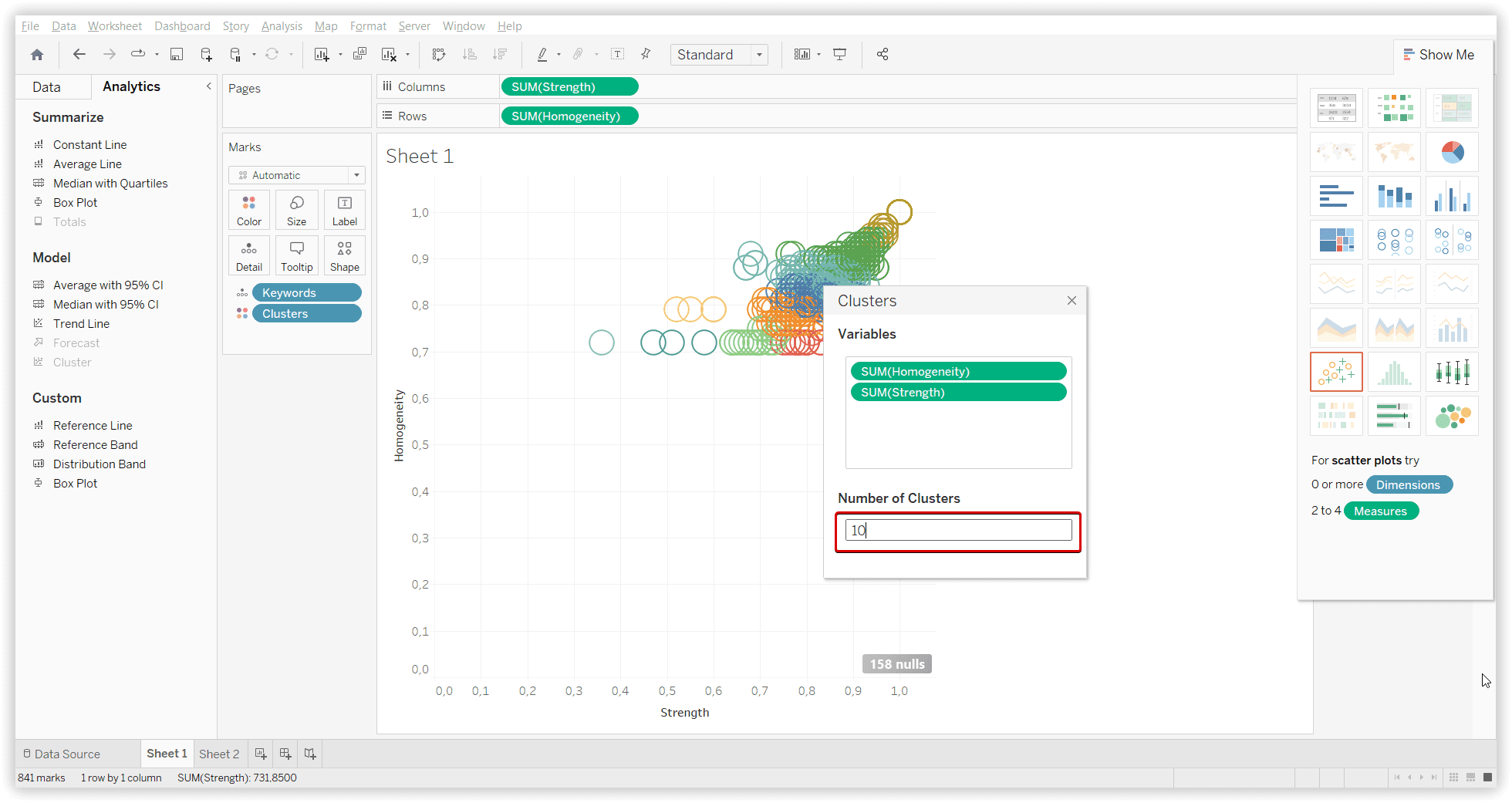
При использовании данного алгоритма всегда необходимо указать примерное количество необходимых кластеров. Вы можете попробовать преобразовать данные ключевых слов в векторы, чтобы узнать, как этот подход работает с ранжированием Google для применения в SEO.
Результат применения K-means кластеризации на наборе данных из Serpstat, с учетом однородности (10 кластеров):
«K» — количество кластеров, заданных для набора данных. Это означает, что перед кластеризацией вы должны знать предполагаемое количество будущих групп. Этот метод можно использовать для рекомендаций, поиска спама или фейковых новостей. Такая кластеризация используется стриминговым сервисом Netflix: вам предоставляется набор фильмов и список отзывов, которые дал каждый оценщик; ваша цель — создать около сотни групп связанных фильмов. Каждая начальная точка «k» служит центральной точкой для одного из таких «k наборов».
При использовании данного алгоритма всегда необходимо указать примерное количество необходимых кластеров. Вы можете попробовать преобразовать данные ключевых слов в векторы, чтобы узнать, как этот подход работает с ранжированием Google для применения в SEO.
Результат применения K-means кластеризации на наборе данных из Serpstat, с учетом однородности (10 кластеров):
Необходимые параметры, Легенда
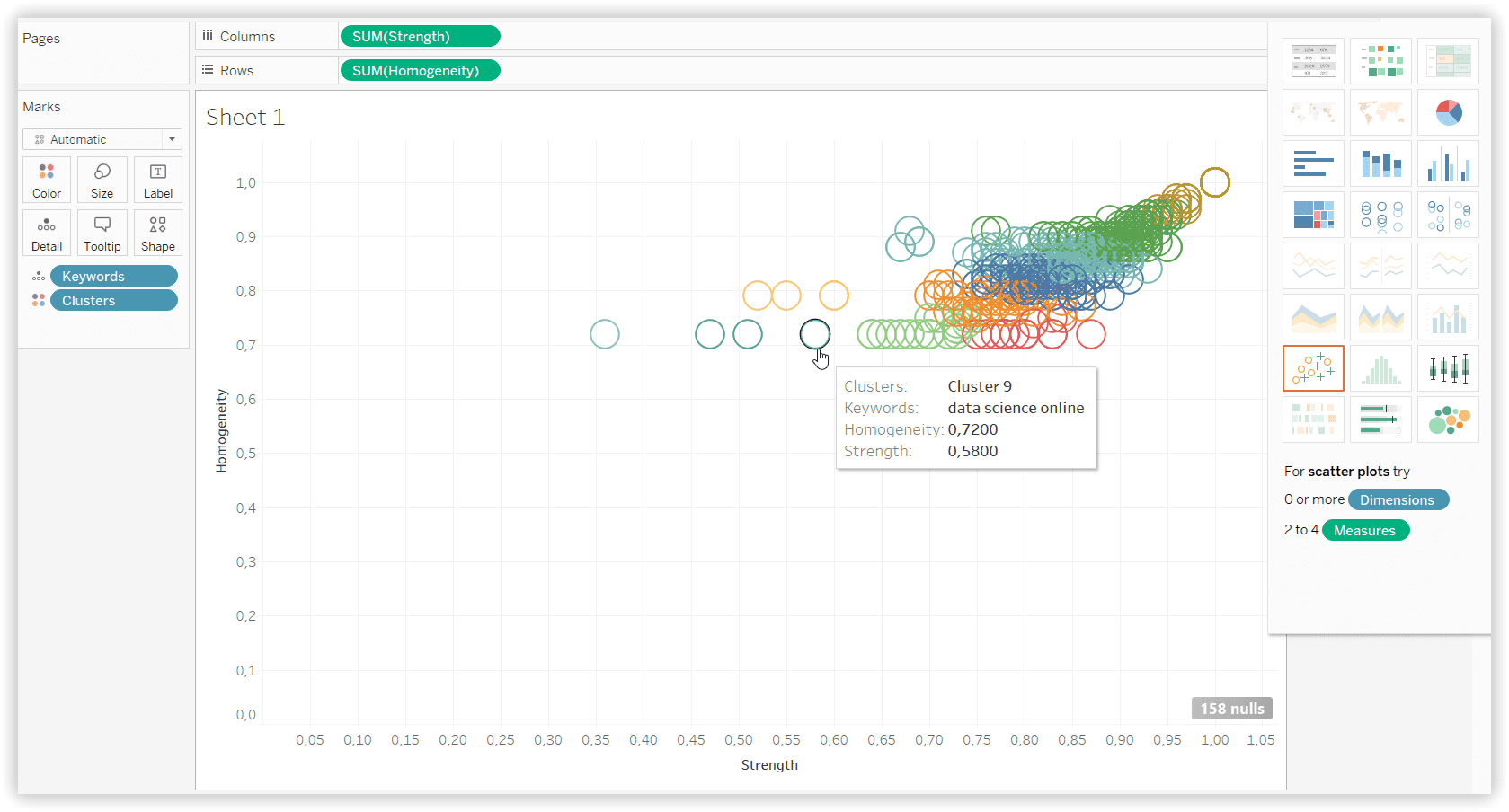
Результат применения K-means
• K-medians
Метод k-медиан чаще всего используется для измерения среднего дохода, по сути медиана представляет собой среднюю точку. Такой подход также не имеет сфер применения в SEO.
Метод k-медиан чаще всего используется для измерения среднего дохода, по сути медиана представляет собой среднюю точку. Такой подход также не имеет сфер применения в SEO.
Подходы на основе систем искусственного интеллекта
- Метод нечеткой кластеризации (C-средние). При таком подходе создают k кластеров, а затем назначают данные каждому кластеру по существующему фактору, определяющему, насколько сильно данные принадлежат этой группе.
Логический подход
Главный подход такого вида – построение дендрограммы, осуществляется с помощью дерева решений. В этом случае дендрограмма показывает ключевые слова по их собственным кластерам, начиная с двух общих групп, которые разбиваются на более мелкие кластеры с наиболее похожими ключевыми словами.
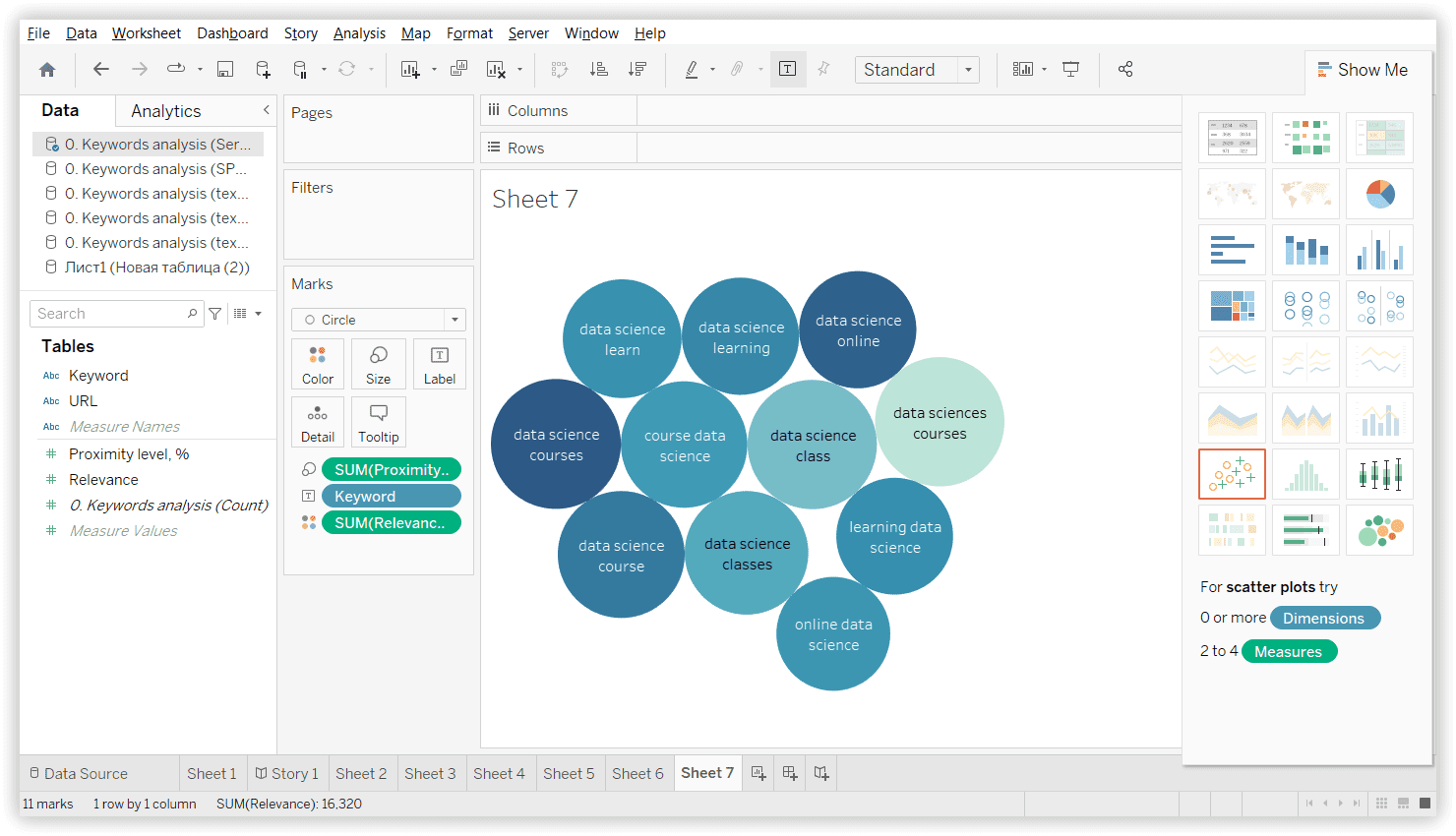
Визуализацию такого подхода можно найти в сервисе Keyword Cupid.
Визуализацию такого подхода можно найти в сервисе Keyword Cupid.
Теоретико-графовый подход
В теории графов, разделе математики, кластер образуется из вершин графов, где расположены объекты, а ребра соответствуют расстояниям между этими объектами, за счет схожих характеристик и связей разные точки могут создавать группы.
Иерархическая кластеризация (также графовые алгоритмы кластеризации и иерархический кластерный анализ) представляет собой набор алгоритмов для создания иерархии вложенных кластеров. Иерархический подход предполагает наличие групп с вложенностями (кластеров разного порядка). Эвристическая кластеризация включает в себя разделение данных на группы на основании некоторой степени сходства с возможностью дальнейшего сужения. Второй метод, наоборот, идет от уникальных объектов и последовательно объединяет эти данные в более крупные группы.
Иерархическая кластеризация (также графовые алгоритмы кластеризации и иерархический кластерный анализ) представляет собой набор алгоритмов для создания иерархии вложенных кластеров. Иерархический подход предполагает наличие групп с вложенностями (кластеров разного порядка). Эвристическая кластеризация включает в себя разделение данных на группы на основании некоторой степени сходства с возможностью дальнейшего сужения. Второй метод, наоборот, идет от уникальных объектов и последовательно объединяет эти данные в более крупные группы.
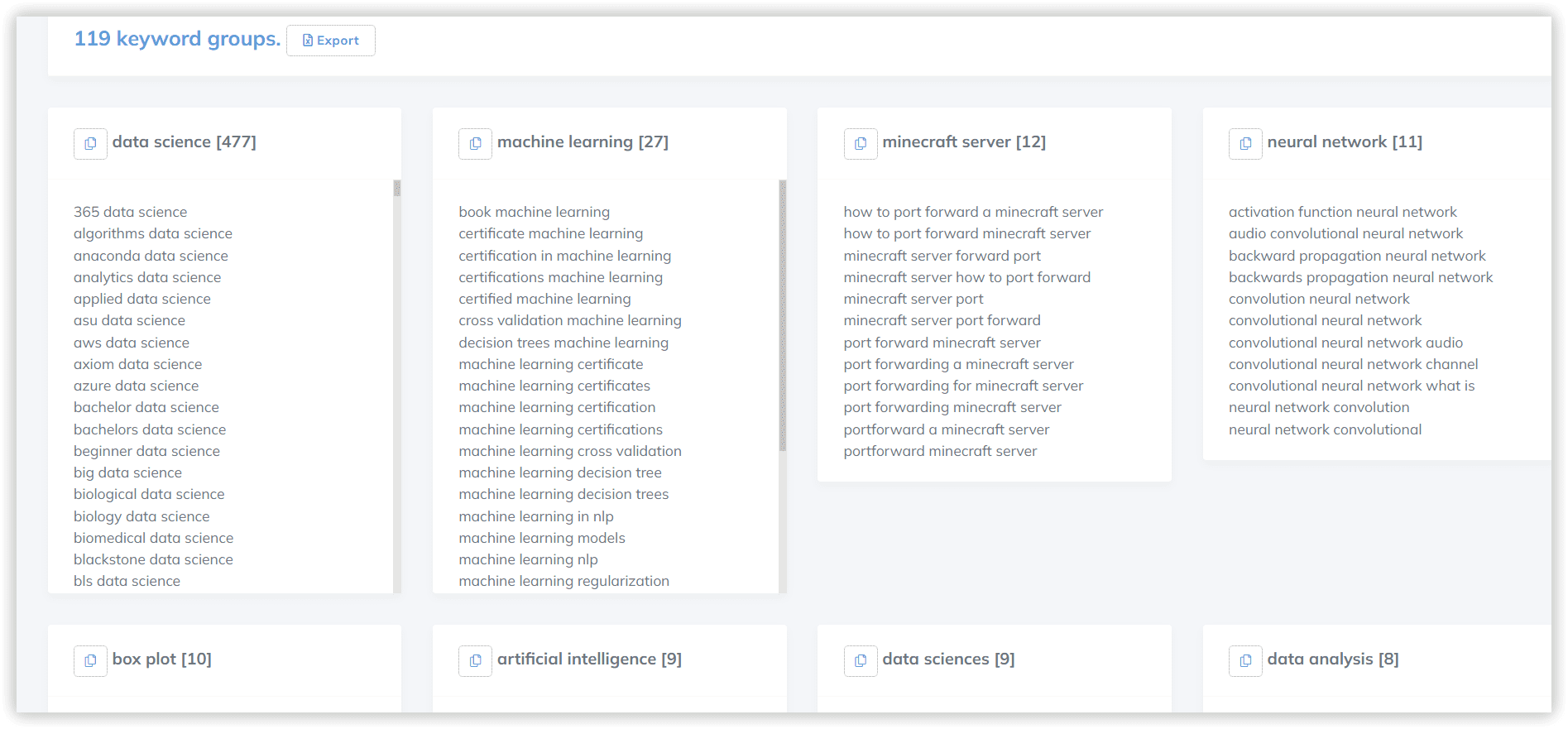
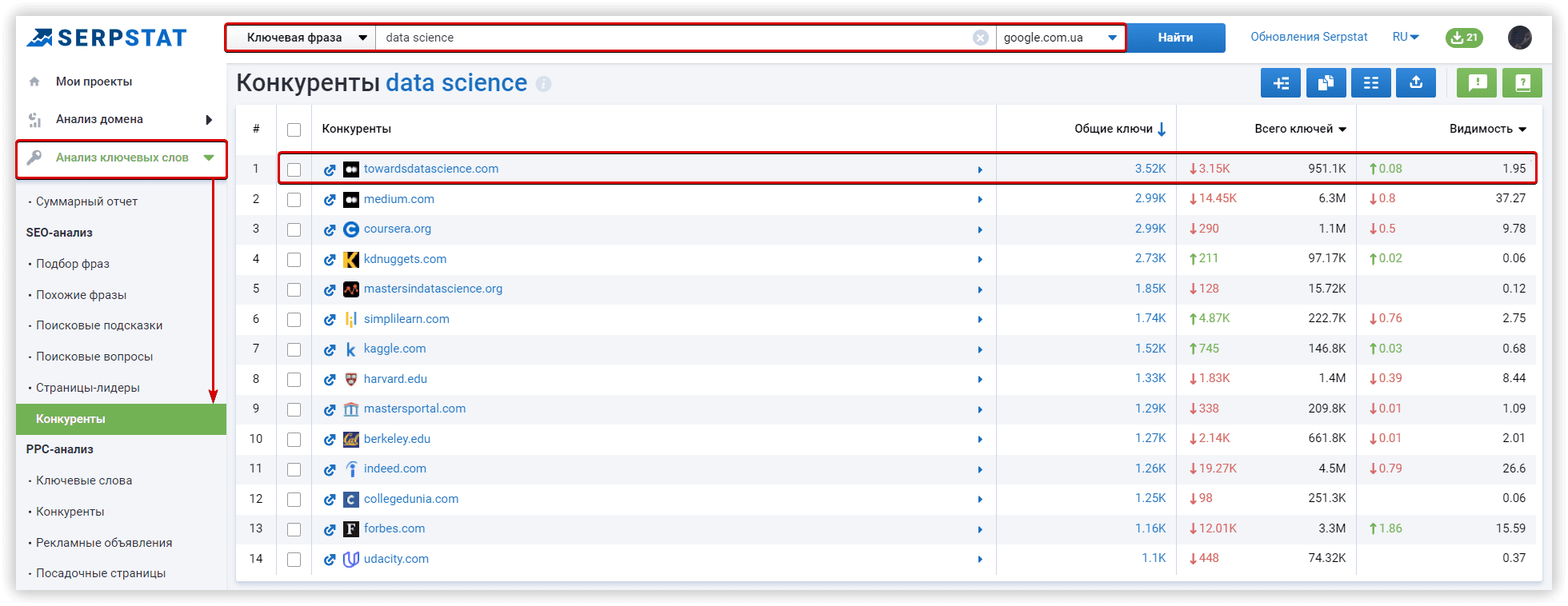
Алгоритмы кластеризации популярных SEO-инструментов
Serpstat
Большинство SEO-сервисов используют ключевые слова с наибольшей частотностью в качестве своеобразных центроидов для кластеров, полагаясь на похожие страницы в выдаче поисковой системы. Однако Serpstat считает такой эвристический метод неточным, так как, следуя этой логике, для создания проекта кластеризации будет достаточно нескольких высокочастотных ключевых фраз. Мы используем комбинацию алгоритмов, основанную на теоретико-графовом подходе иерархической кластеризации.
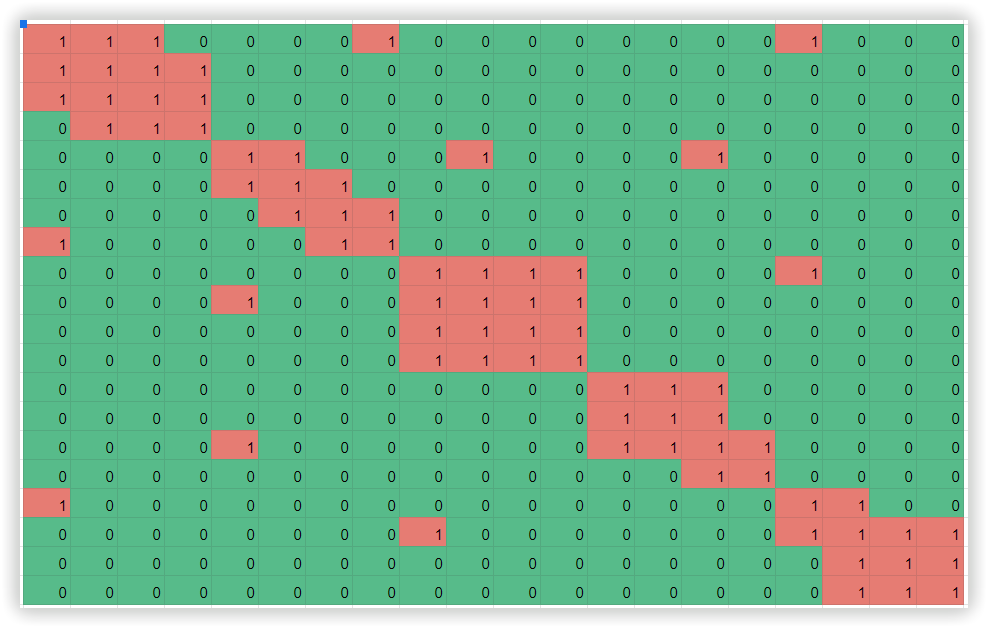
Для подсчета мы строим матрицу смежности в соответствии с количеством общих URL-адресов для группы фраз. Допустим, ключевое слово «неттоп» будет иметь то же количество общих URL-адресов в выдаче, что и фраза «неттоп игровой», таких общих страниц в выдаче может быть 12. А два ключевых слова «неттоп» и «Mac Mini» будут иметь только 5 общих URL-адресов в рамках анализируемого топа 30 результатов поисковой выдачи. Теперь, мы преобразуем матрицу так, чтобы относительные числовые значения были расположены ближе друг к другу. Если присвоить каждому числовому значению цвет, мы получим классическую диаграмму Чекановского. Пример такой матрицы:
Для подсчета мы строим матрицу смежности в соответствии с количеством общих URL-адресов для группы фраз. Допустим, ключевое слово «неттоп» будет иметь то же количество общих URL-адресов в выдаче, что и фраза «неттоп игровой», таких общих страниц в выдаче может быть 12. А два ключевых слова «неттоп» и «Mac Mini» будут иметь только 5 общих URL-адресов в рамках анализируемого топа 30 результатов поисковой выдачи. Теперь, мы преобразуем матрицу так, чтобы относительные числовые значения были расположены ближе друг к другу. Если присвоить каждому числовому значению цвет, мы получим классическую диаграмму Чекановского. Пример такой матрицы:
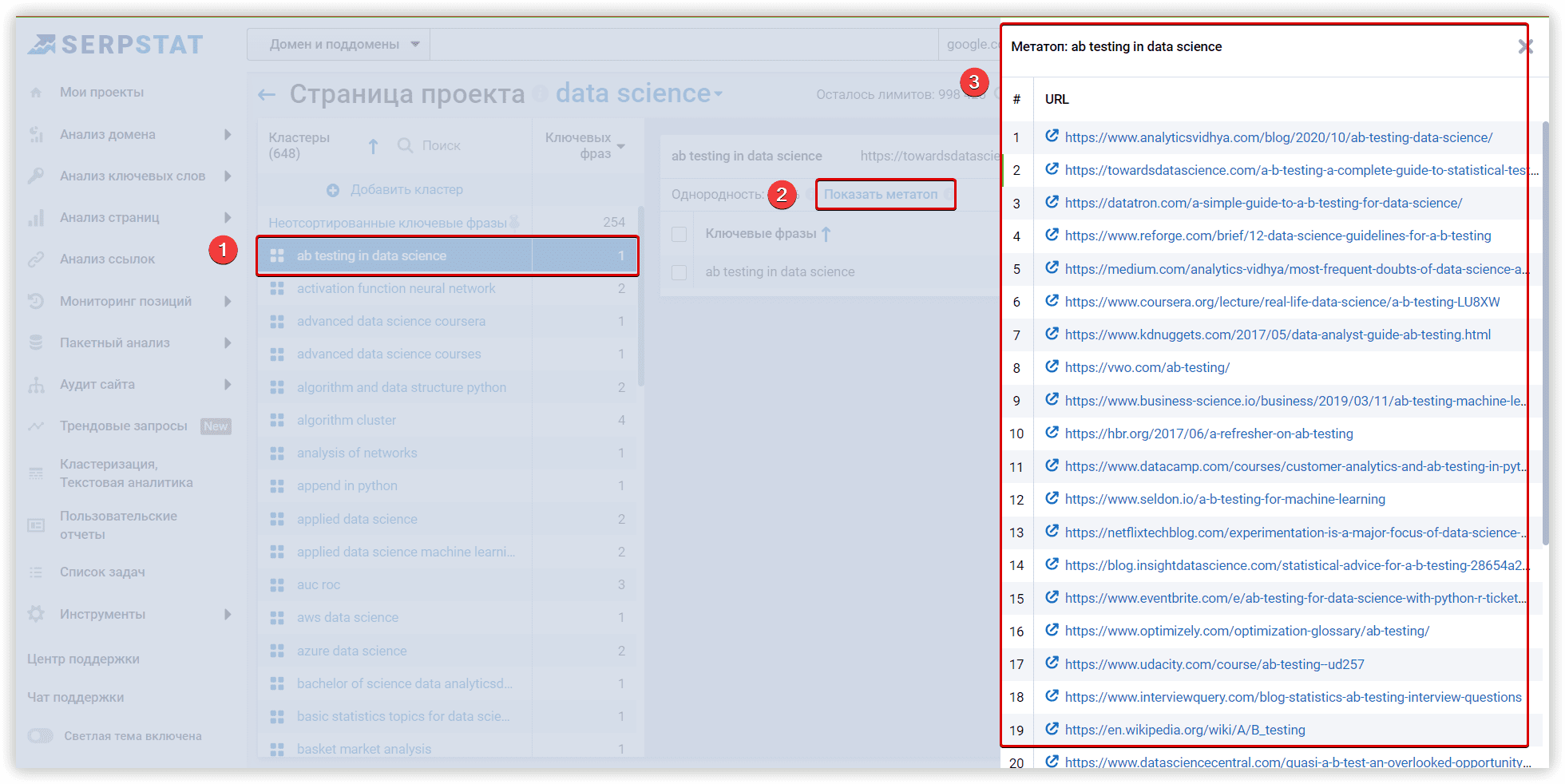
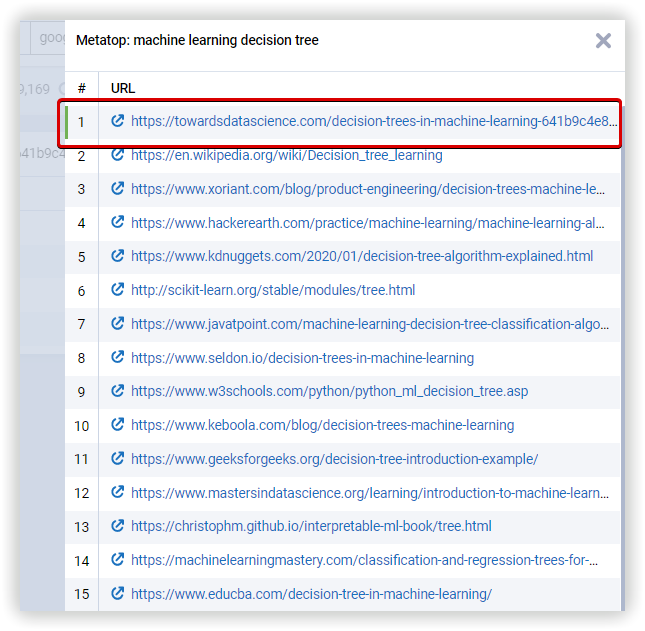
Список проверенных страниц в выдаче поисковой системы в процессе кластеризации, можно увидеть в блоке «Метатоп». Чем выше анализируемый URL в метатопе, тем релевантнее эта страница тематике кластера.
При использовании метода Чекановского более вероятно, что исследуемый метатоп, то есть набор URL-адресов, представляющих кластер, будет выступать в роли центроида. Близость ключевого слова к тематике кластера рассчитывается с учетом схожести результатов поисковой выдачи по ключевому слову и анализируемого метатопа. Serpstat разработал уникальный итерационный алгоритм, позволяющий находить и исправлять неточности кластеризации.
SEO-платформа использует специальные метрики для описания итоговых кластеров:
Однородность (%) показывает, как ключевые слова в кластере связаны друг с другом. Этот показатель оценивает SERP для каждого ключевого слова.
Сила связи, по шкале от 0 до 100, отражает сходство между метатопом и поисковой выдачей определенного ключевого слова (насколько близко ключевое слово из кластера к основной теме кластера).
Чтобы проверить, как работают разные подходы к кластеризации, мы проведем Текстовую аналитику в Serpstat на кластерах, которые удалось получить с помощью SEO-платформ, использующих одинаковый алгоритм — SERP анализ.
Текстовая аналитика в Serpstat (ТА) — это инструмент, который помогает повысить релевантность контента на основе парсинга и анализа текстового наполнения сайтов-конкурентов из ТОП-15 выдачи. Этот инструмент также покажет вхождение определенных ключевых слов в ваш контент и позволит понять, не перенасыщен ли текст отдельными фразами. Если же вы не включили некоторые релевантные ключевые слова в свой текст, вы увидите их в качестве рекомендаций. Кроме того, если вы прикрепили целевую страницу к проекту ТА, в результатах можно увидеть возможные технические проблемы, которые влияют на вашу оптимизацию и провести дальнейший аудит.
Для анализа текста, а также для улучшенного понимания интента, Serpstat использует алгоритм TF-IDF-CDF (TF — частота слова, IDF — обратная частота документа и наш собственный показатель, CDF — частота документа для кластера). Этот подход помогает определить статистические показатели для ключевых слов, определяющих тему для всего кластера:
TF — учитывает количество вхождений ключевого слова в текст;
IDF – контролирует неинформативные ключевые слова, встречающиеся в большом проценте текста, стоп-слова;
СDF — находит самые мощные ключевые слова для каждого кластера.
Благодаря текстовой аналитике, можно получить наиболее ценные ключевые слова, к примеру для будущей структуры веб-сайта. Затем, вы можете использовать эти фразы в проекте Мониторинга позиций и наблюдать за эффективностью продвижения вашего веб-ресурса.
Чтобы отследить качество кластеров, выполненных различными инструментами, мы также сравним метрики из Текстовой аналитики. Для чистоты эксперимента, один и тот же набор данных и подобные настройки кластеризации будут использоваться для всех анализируемых SEO-платформ.
При использовании метода Чекановского более вероятно, что исследуемый метатоп, то есть набор URL-адресов, представляющих кластер, будет выступать в роли центроида. Близость ключевого слова к тематике кластера рассчитывается с учетом схожести результатов поисковой выдачи по ключевому слову и анализируемого метатопа. Serpstat разработал уникальный итерационный алгоритм, позволяющий находить и исправлять неточности кластеризации.
SEO-платформа использует специальные метрики для описания итоговых кластеров:
Однородность (%) показывает, как ключевые слова в кластере связаны друг с другом. Этот показатель оценивает SERP для каждого ключевого слова.
Сила связи, по шкале от 0 до 100, отражает сходство между метатопом и поисковой выдачей определенного ключевого слова (насколько близко ключевое слово из кластера к основной теме кластера).
Чтобы проверить, как работают разные подходы к кластеризации, мы проведем Текстовую аналитику в Serpstat на кластерах, которые удалось получить с помощью SEO-платформ, использующих одинаковый алгоритм — SERP анализ.
Текстовая аналитика в Serpstat (ТА) — это инструмент, который помогает повысить релевантность контента на основе парсинга и анализа текстового наполнения сайтов-конкурентов из ТОП-15 выдачи. Этот инструмент также покажет вхождение определенных ключевых слов в ваш контент и позволит понять, не перенасыщен ли текст отдельными фразами. Если же вы не включили некоторые релевантные ключевые слова в свой текст, вы увидите их в качестве рекомендаций. Кроме того, если вы прикрепили целевую страницу к проекту ТА, в результатах можно увидеть возможные технические проблемы, которые влияют на вашу оптимизацию и провести дальнейший аудит.
Для анализа текста, а также для улучшенного понимания интента, Serpstat использует алгоритм TF-IDF-CDF (TF — частота слова, IDF — обратная частота документа и наш собственный показатель, CDF — частота документа для кластера). Этот подход помогает определить статистические показатели для ключевых слов, определяющих тему для всего кластера:
TF — учитывает количество вхождений ключевого слова в текст;
IDF – контролирует неинформативные ключевые слова, встречающиеся в большом проценте текста, стоп-слова;
СDF — находит самые мощные ключевые слова для каждого кластера.
Благодаря текстовой аналитике, можно получить наиболее ценные ключевые слова, к примеру для будущей структуры веб-сайта. Затем, вы можете использовать эти фразы в проекте Мониторинга позиций и наблюдать за эффективностью продвижения вашего веб-ресурса.
Чтобы отследить качество кластеров, выполненных различными инструментами, мы также сравним метрики из Текстовой аналитики. Для чистоты эксперимента, один и тот же набор данных и подобные настройки кластеризации будут использоваться для всех анализируемых SEO-платформ.
Cluster army
Cluster Army — это бесплатный инструмент для создания кластеров на основе сходства лемм ключевых слов. Алгоритм пытается найти часть слова, отвечающую за его лексическое значение.
Cluster Army потребуется произвести несколько шагов для успешной кластеризации:
Изучить импортированный список;
Cluster Army потребуется произвести несколько шагов для успешной кластеризации:
Изучить импортированный список;
- Найти частотность по лемме, удалить стоп-слова;
- Найти принадлежность для каждого отдельного термина;
- Найти принадлежность для всех пар ключей;
- Найти принадлежность для трех терминов;
- Создать таблицу с начальным ключевым словом, связанным с ним высокочастотным, а затем и группами по 2-3 фразы;
- Наконец, инструмент создаст кластеры, которые вы можете использовать в своем проекте.

Spy fu
Еще один пример кластеризации, основанный на лемматическом сходстве. Этот подход будет полезен для создания тематических кластеров, подбора статей для перелинковки, страниц, связанных основной темой. Инструмент кластеризации SpyFu работает следующим образом:
- Вы можете импортировать свои брендовые запросы, а также ключи «с длинным хвостом». Spy Fu добавит в них данные, чтобы получить полную картину по тематике.
- Затем нужно отсортировать ключевые слова, чтобы увидеть, как новые данные влияют на полученные результаты, или отфильтровать, формируя автоматические группы.
- Наконец, создается новый список ключевых слов для проверки в других платформах или добавления во встроенный инструмент внутри Spy fu.
Contadu
Это базовый инструмент группировки ключевых фраз, основанный на алгоритмах обработки текста с очень простым методами.
Процесс кластеризации в Contadu состоит из нескольких шагов:
Процесс кластеризации в Contadu состоит из нескольких шагов:
- Сбор вариантов ключевых слов, основываясь на импортируемых данных.
- Проверка частотности, трендов, CPC и значений показателя конкуренции.
- Поиск результатов по всем вариантам ключевых слов.
- Построение матрицы сходства между ключевыми словами.
- Кластеризация на основе сходства.

Umbrellum
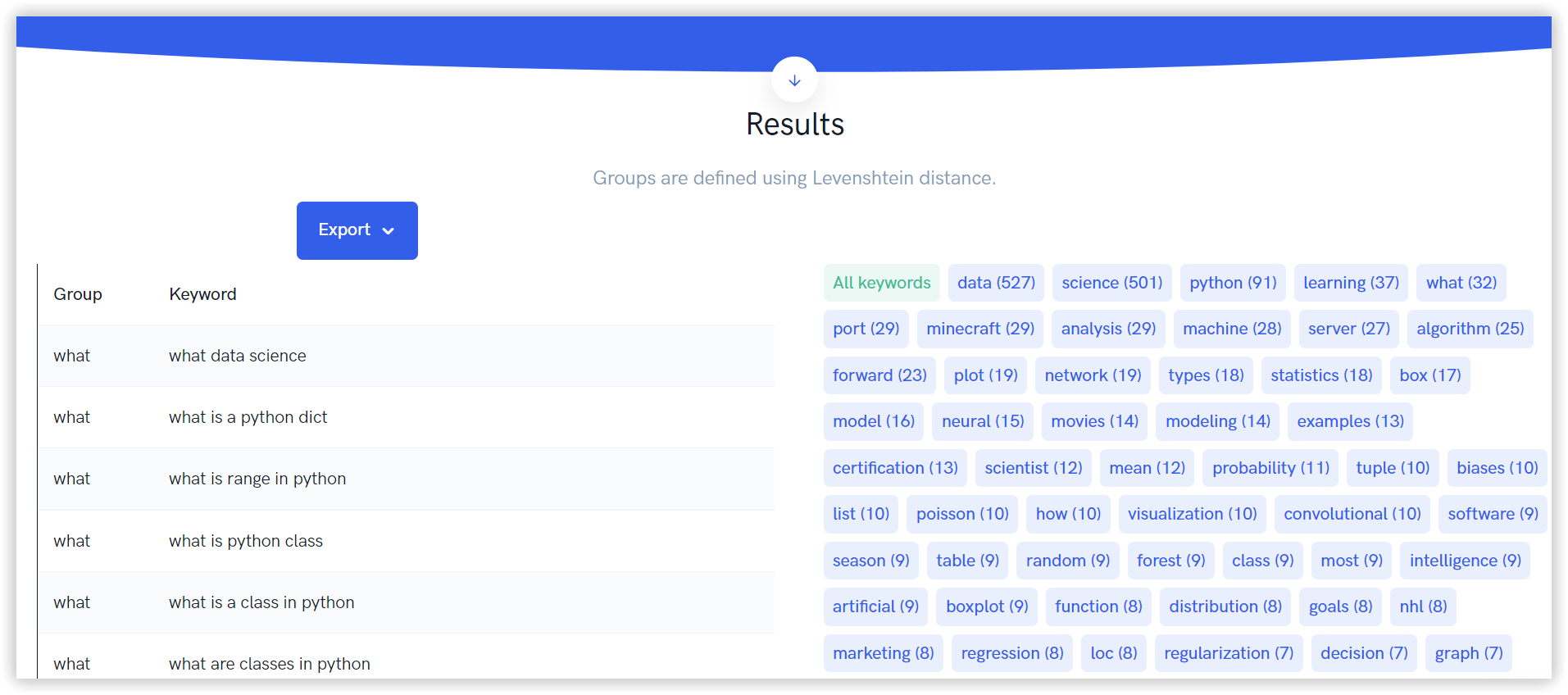
Этот сервис является примером адаптивной иерархической кластеризации. Алгоритм основан на спектральной кластеризации, которая идентифицирует структуру набора данных и группирует их в соответствии со степенью сходства.
Для этого Umbrellum использует кластеризацию с расстоянием Левенштейна. Это расстояние можно рассчитать, как минимальное необходимое количество правок, необходимое для замены одного слова другим. Технически, это число отображает, насколько различны два ключевых слова. Чем выше этот показатель, тем больше различий между двумя словами.
Для этого Umbrellum использует кластеризацию с расстоянием Левенштейна. Это расстояние можно рассчитать, как минимальное необходимое количество правок, необходимое для замены одного слова другим. Технически, это число отображает, насколько различны два ключевых слова. Чем выше этот показатель, тем больше различий между двумя словами.
Simple SEO tool
Этот сервис лемма-кластеризации позволяет группировать до 10 000 фраз за короткое время. Simple SEO работает в два этапа: сначала создается приоритетная группа слов, затем дальнейшая выборка группируется по семантическому сходству.

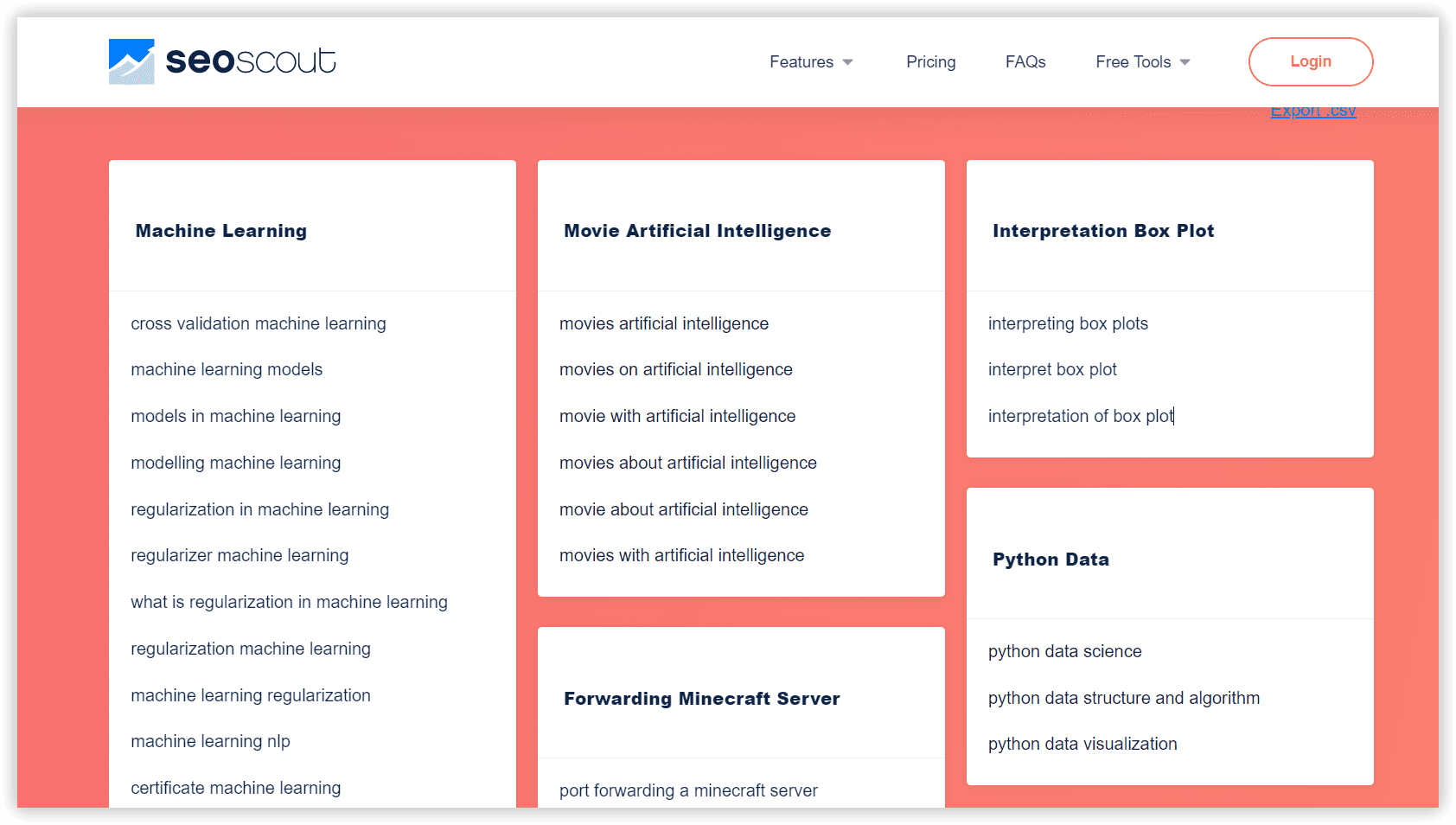
SEO Scout
Инструмент автоматически собирает запросы, ключевые слова и предложения из нашего списка и группирует их по схожим темам.
В SEO Scout вы можете задавать диапазон ключевых слов с длинным хвостом, представляющих каждую группу, а также их минимальную частотность. Готовые группы можно пересмотреть и отправить копирайтеру, вместе с ТЗ и набросками запланированных публикаций.
В SEO Scout вы можете задавать диапазон ключевых слов с длинным хвостом, представляющих каждую группу, а также их минимальную частотность. Готовые группы можно пересмотреть и отправить копирайтеру, вместе с ТЗ и набросками запланированных публикаций.
Работая с сервисами кластеризации на основе такого семантического сходства, нужно учитывать важность предварительной подготовки данных для соответствия целям и ожидаемой релевантности групп. Важно собирать ключевые слова, которые приведут на сайт пользователей, заинтересованных в ваших продуктах или услугах, запросы, которые положительно повлияют на показатель конверсии.
Критерии, которые вы должны учитывать для группировки в кластеры:
В отличии от лемматической, кластеризация на основе SERP-ов создает группы ключевых слов, которые могут не иметь морфологических совпадений, но соответствуют результатам в выдаче поисковой системы. Используя алгоритмы такой кластеризации, SEO-специалисты могут создавать группы ключевых слов, которые соответствуют требованиям поисковых систем.
Наше основное исследование будет сосредоточено на алгоритмах Serpstat, Keyword Cupid и Spy SERP, которые опираются на выдачу поисковых систем.
Критерии, которые вы должны учитывать для группировки в кластеры:
- Семантическая релевантность. Ключевые слова в кластерах должны иметь схожий поисковой интент.
- Частотность и цена за клик. Основные ключевые слова в кластерах должны иметь высокую частотность и хороший потенциал конверсии (с учетом CPC).
- Сложность продвижения в органическом поиске (KD). Подбирайте только те ключевые слова, по которым ваш сайт имеет реальные шансы ранжироваться.
В отличии от лемматической, кластеризация на основе SERP-ов создает группы ключевых слов, которые могут не иметь морфологических совпадений, но соответствуют результатам в выдаче поисковой системы. Используя алгоритмы такой кластеризации, SEO-специалисты могут создавать группы ключевых слов, которые соответствуют требованиям поисковых систем.
Наше основное исследование будет сосредоточено на алгоритмах Serpstat, Keyword Cupid и Spy SERP, которые опираются на выдачу поисковых систем.

Хотите узнать, как Serpstat проведет кластеризацию вашей семантики?
Начните тестовый период и проверьте возможности инструмента на реальных проектах!
Начните тестовый период и проверьте возможности инструмента на реальных проектах!
Персональная демонстрация
Оставьте заявку и мы проведем для вас персональную демонстрацию сервиса, предоставим пробный период и предложим комфортные условия для старта использования инструмента
Как собрать данные для своего проекта с помощью кластеризации Serpstat?
Чтобы разбить ключевые слова по тематическим группам, вам необходимо собрать наиболее полный список ключевых слов. Это первая фундаментальная задача в процессе создания нового сайта, а также, необходимая мера для расширения семантики и улучшения ранжирования уже существующего. Этот процесс поможет понять, что пользователи ищут в вашей нише и как конкуренты работают с похожей семантикой.
Существует множество, как бесплатных, так и платных инструментов внутри Serpstat, которые помогут вам найти ключевые слова для вашего сайта. Используйте отчет Трендовые запросы, чтобы отслеживать актуальные тенденции и высокочастотные ключи по городам и странам.
Обратите внимание, что существуют разные типы поисковых запросов: вы можете различать их по специфическим характеристикам (таким, как длина, ключевые слова с длинным хвостом) и по интенту пользователя (навигационные, информационные, транзакционные). Коммерческие и информационные ключи не желательно указывать на одной странице. Учитывая интенсивность конкуренции с определенными запросами, вы сможете создать более подходящее семантическое ядро.
Отчеты, которые вы можете использовать для расширения и сбора семантики:
Сбор семантики для проекта в Кластеризации мы начали с модуля «Поисковая аналитика» в Serpstat, дальнейшие действия описаны в пошаговой инструкции.
Дополнительные настройки внутри Кластеризации — в следующем разделе статьи.
Существует множество, как бесплатных, так и платных инструментов внутри Serpstat, которые помогут вам найти ключевые слова для вашего сайта. Используйте отчет Трендовые запросы, чтобы отслеживать актуальные тенденции и высокочастотные ключи по городам и странам.
Обратите внимание, что существуют разные типы поисковых запросов: вы можете различать их по специфическим характеристикам (таким, как длина, ключевые слова с длинным хвостом) и по интенту пользователя (навигационные, информационные, транзакционные). Коммерческие и информационные ключи не желательно указывать на одной странице. Учитывая интенсивность конкуренции с определенными запросами, вы сможете создать более подходящее семантическое ядро.
Отчеты, которые вы можете использовать для расширения и сбора семантики:
- Подбор фраз ( ключевые слова в органической выдаче, связанные с искомой фразой),
- Похожие фразы (все поисковые запросы, семантически связанные с искомым ключевым словом);
- Поисковые подсказки и Поисковые вопросы (запросы, предлагаемые пользователям под строкой поиска и дополняющие формулировку исходного запроса; вопросы, на которое пользователи ищут ответ с учетом анализируемого слова).
Сбор семантики для проекта в Кластеризации мы начали с модуля «Поисковая аналитика» в Serpstat, дальнейшие действия описаны в пошаговой инструкции.
Дополнительные настройки внутри Кластеризации — в следующем разделе статьи.
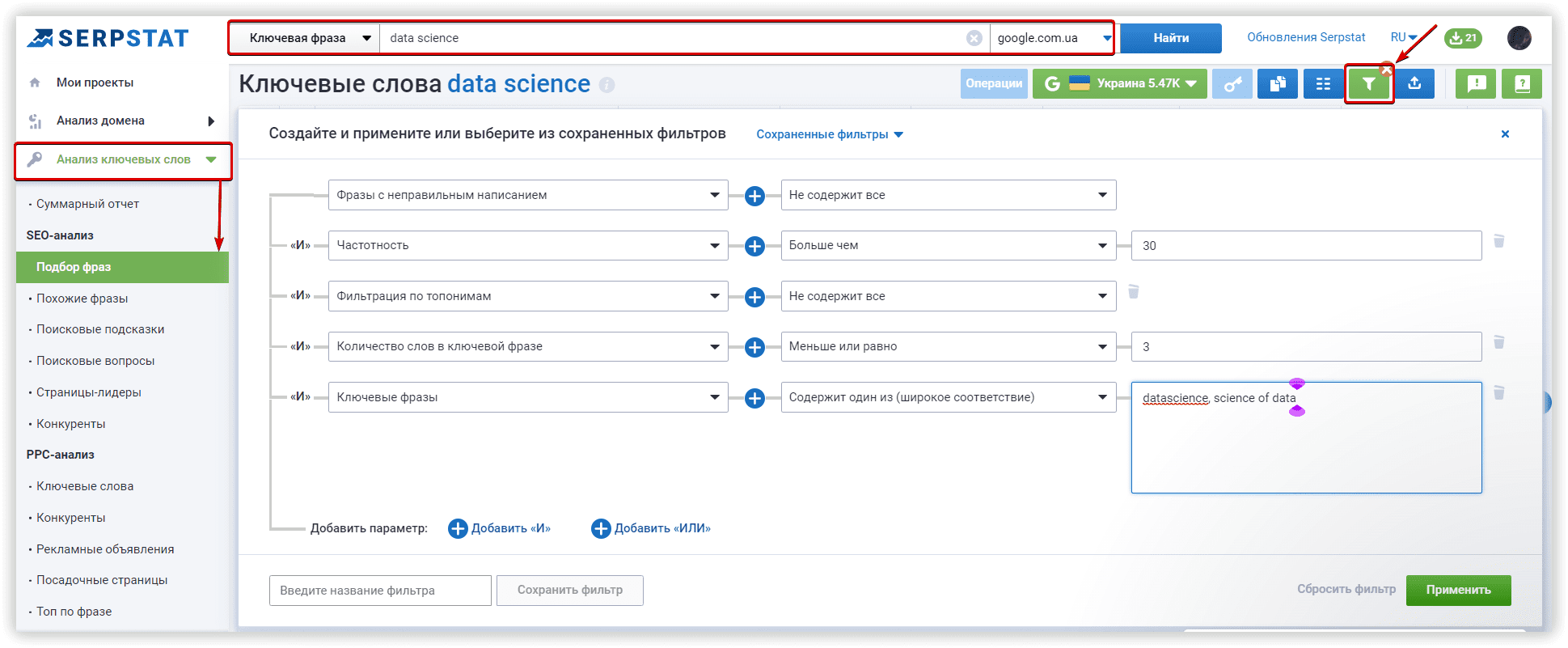
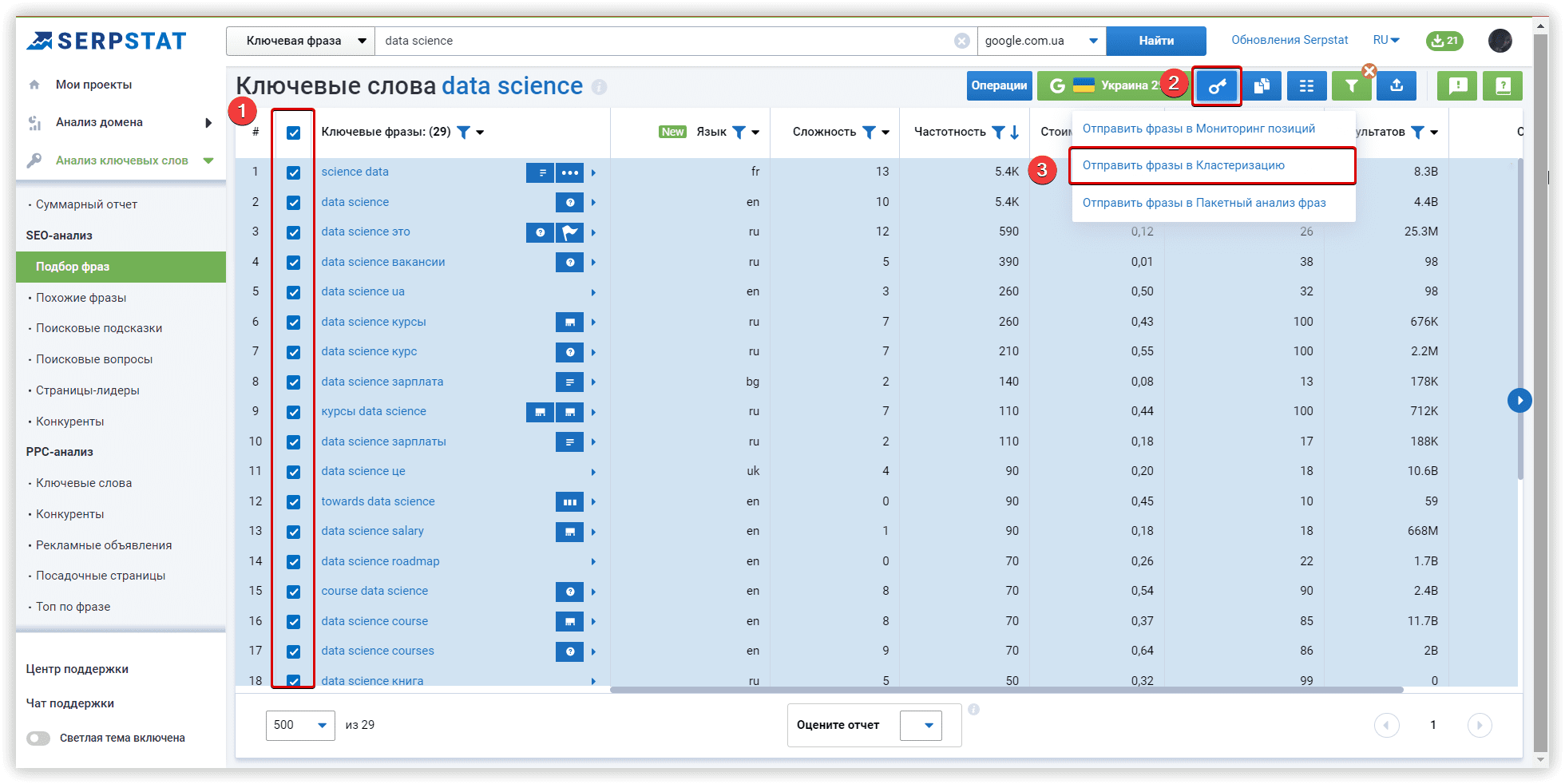
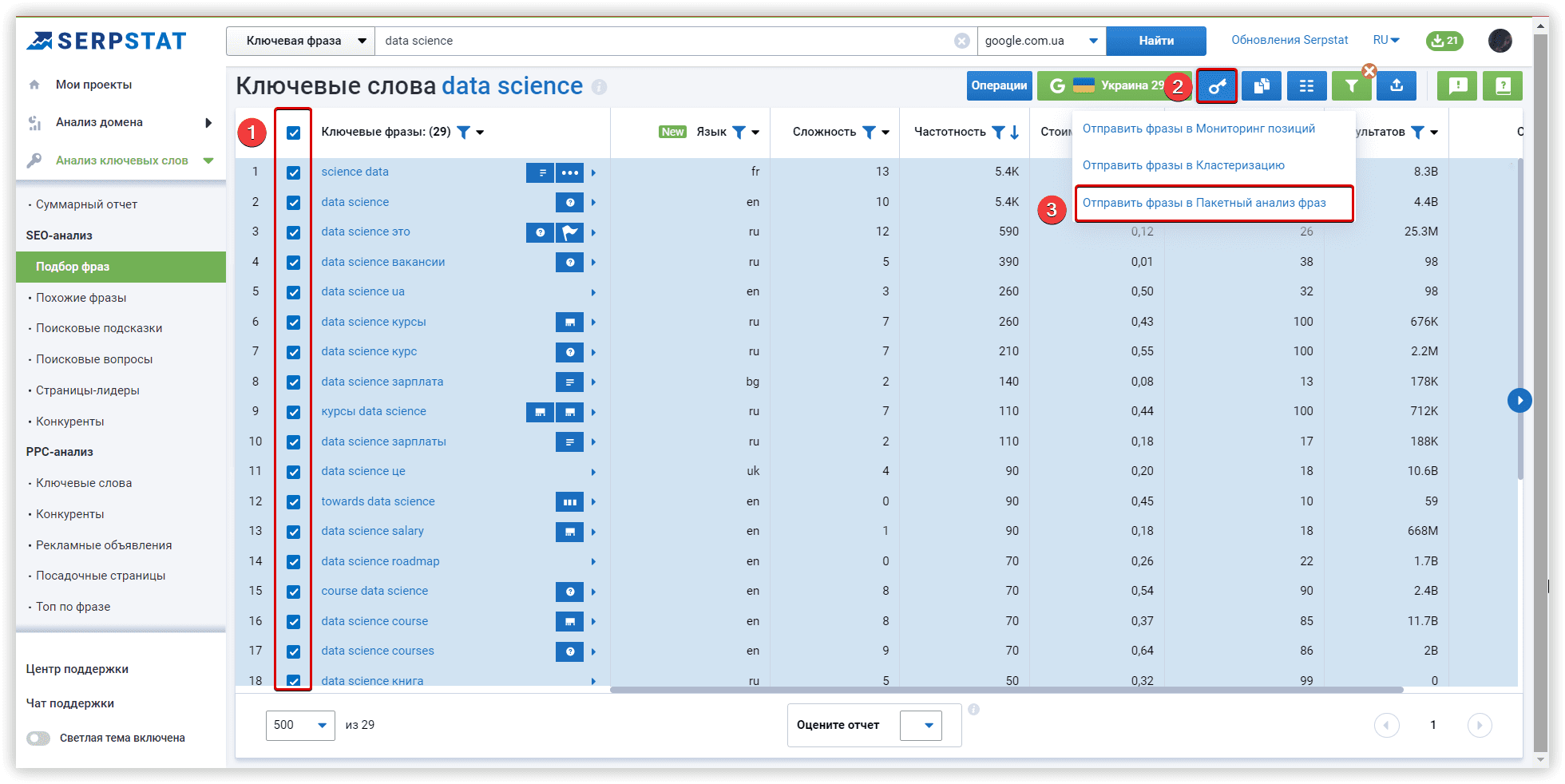
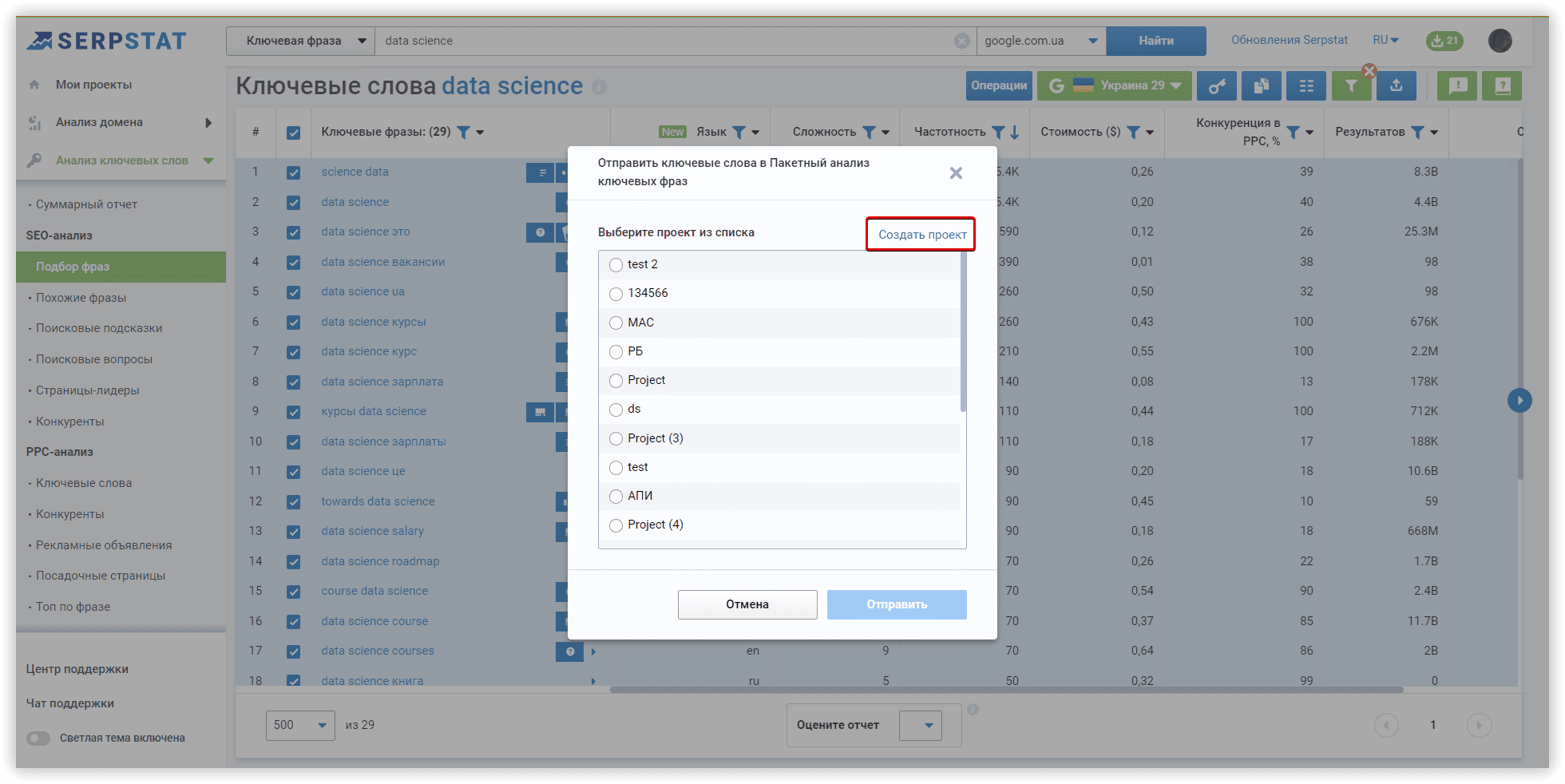
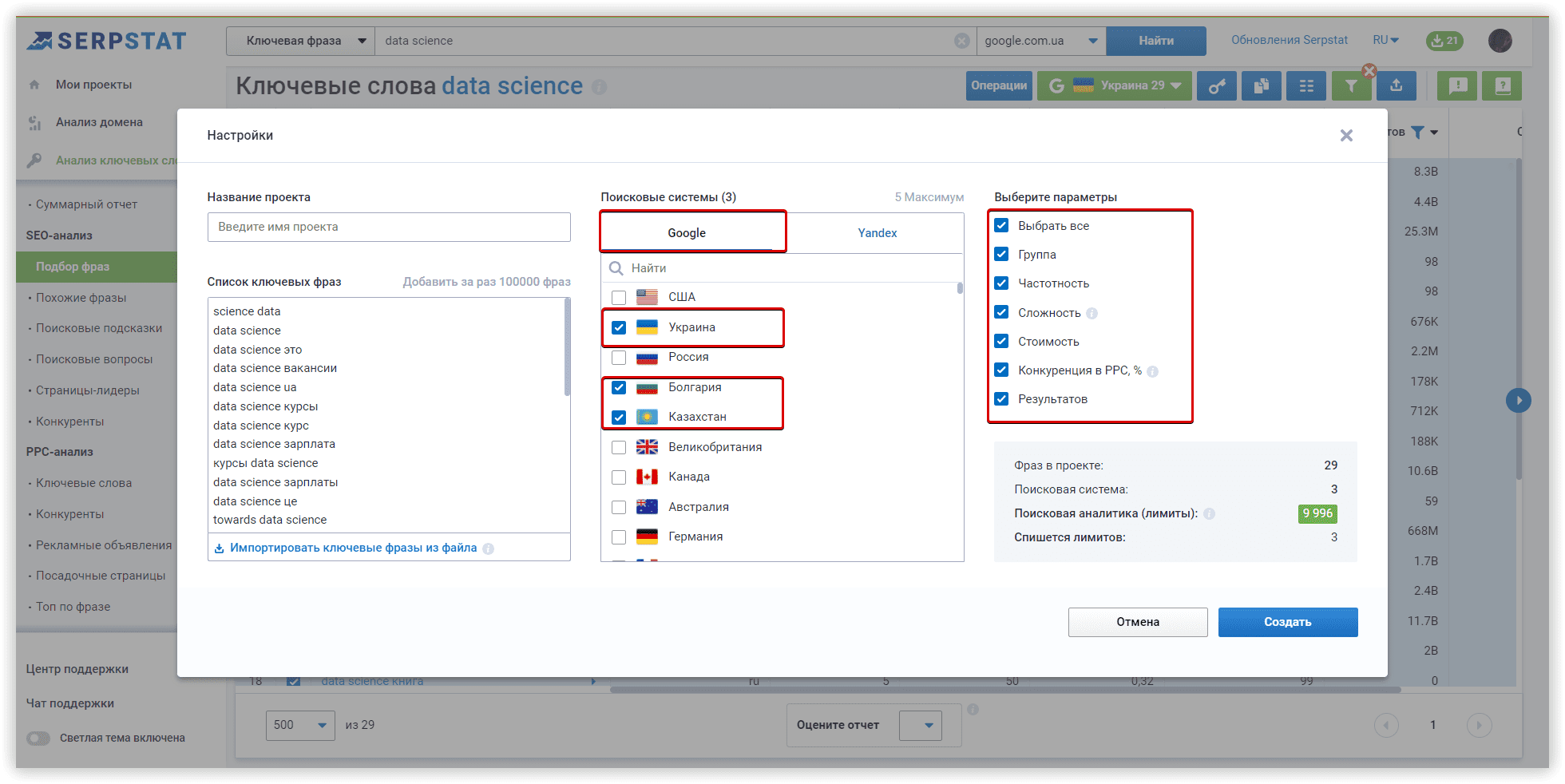
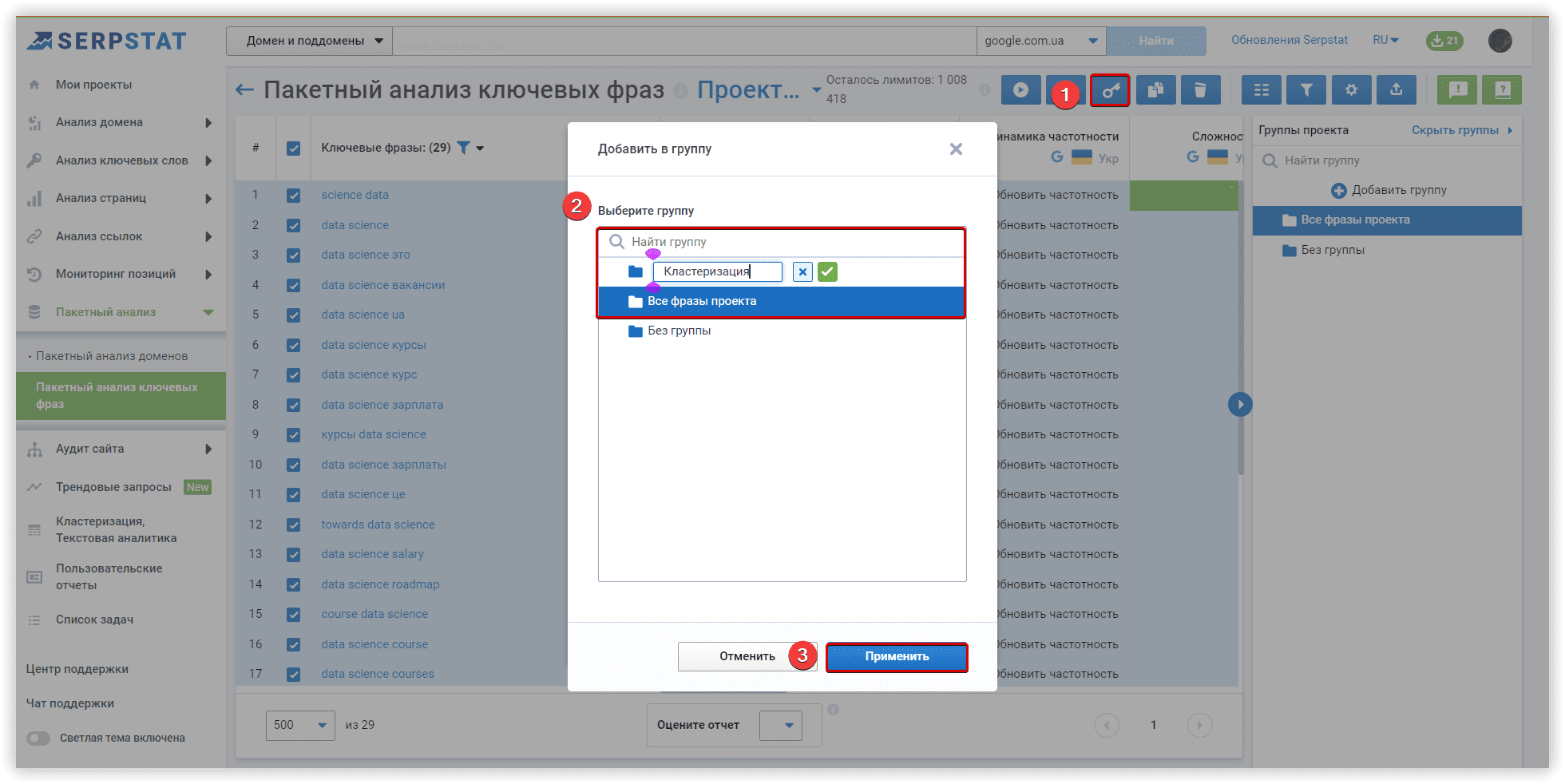
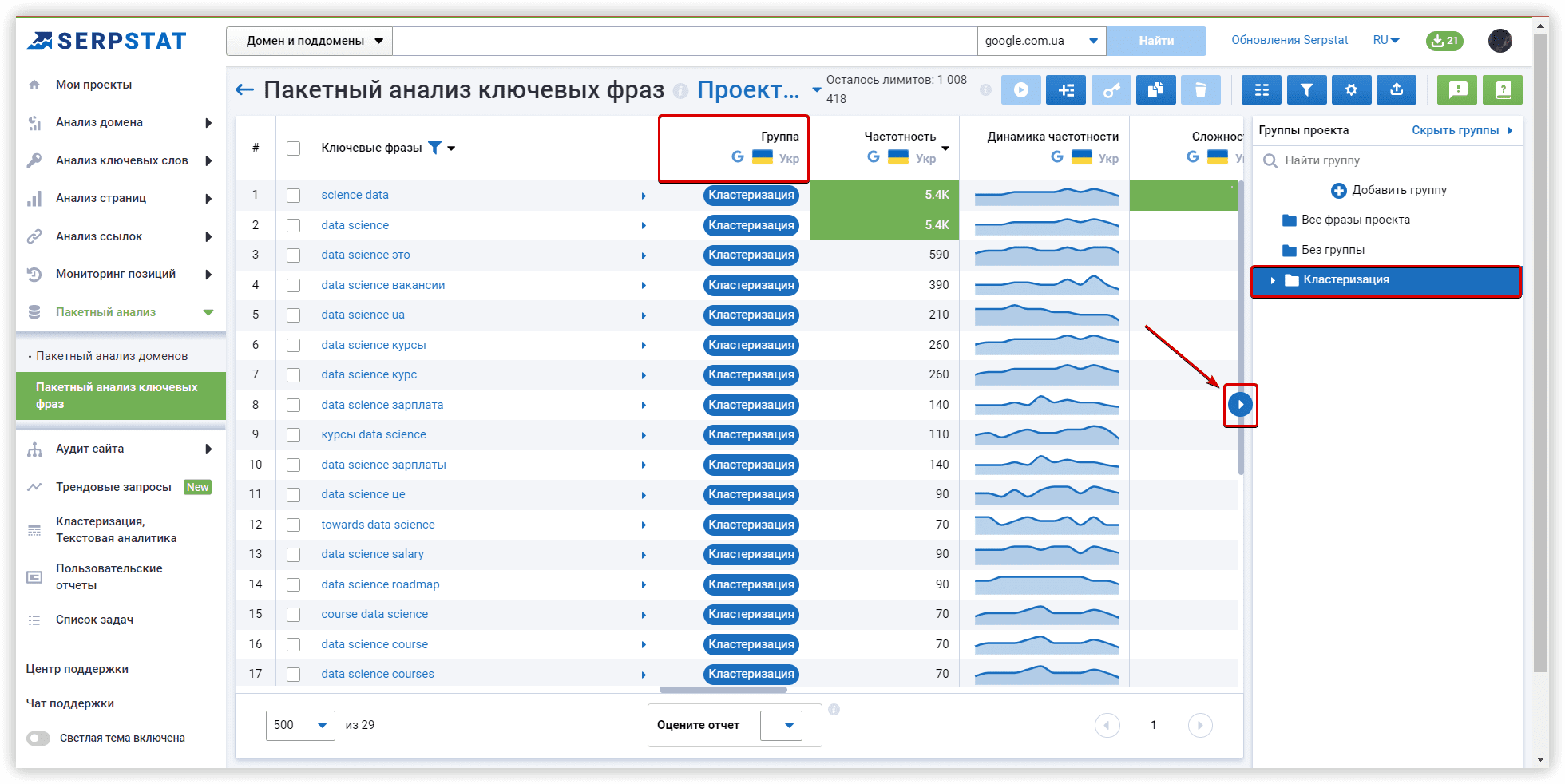
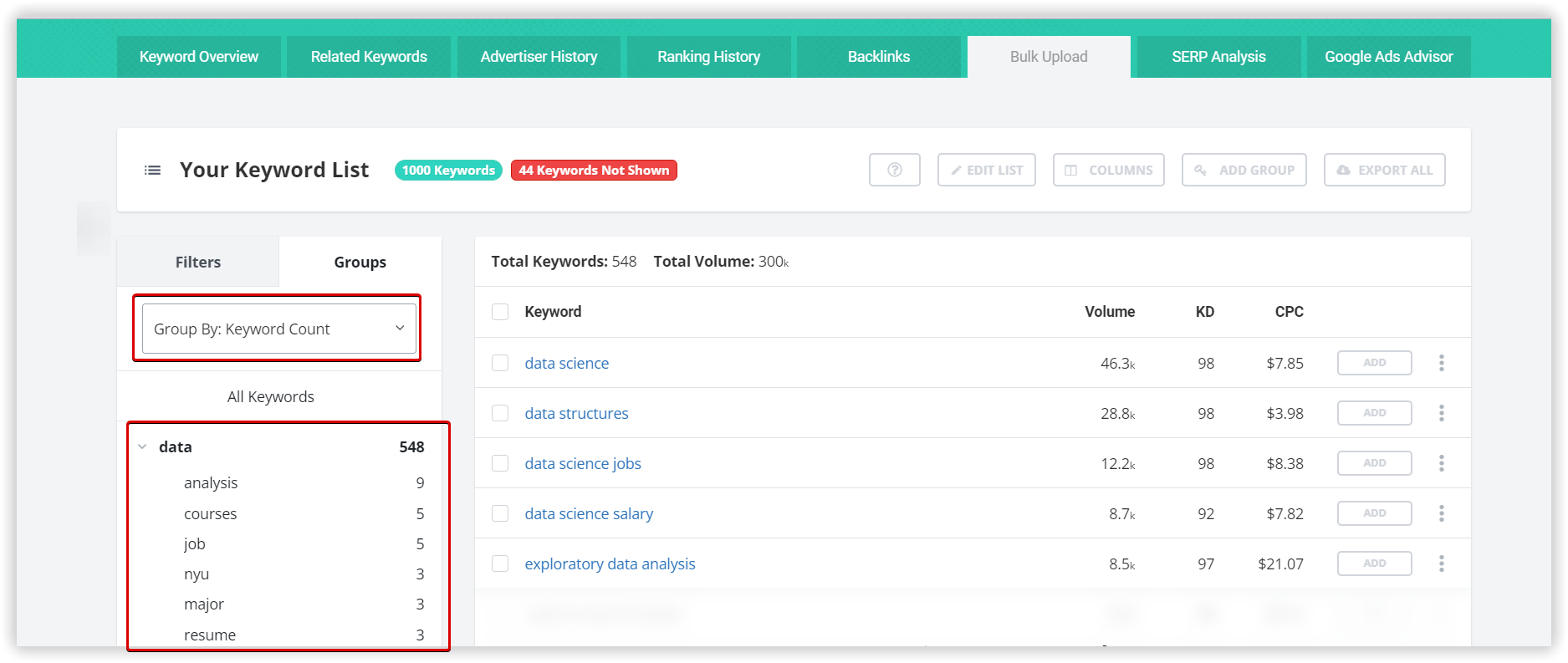
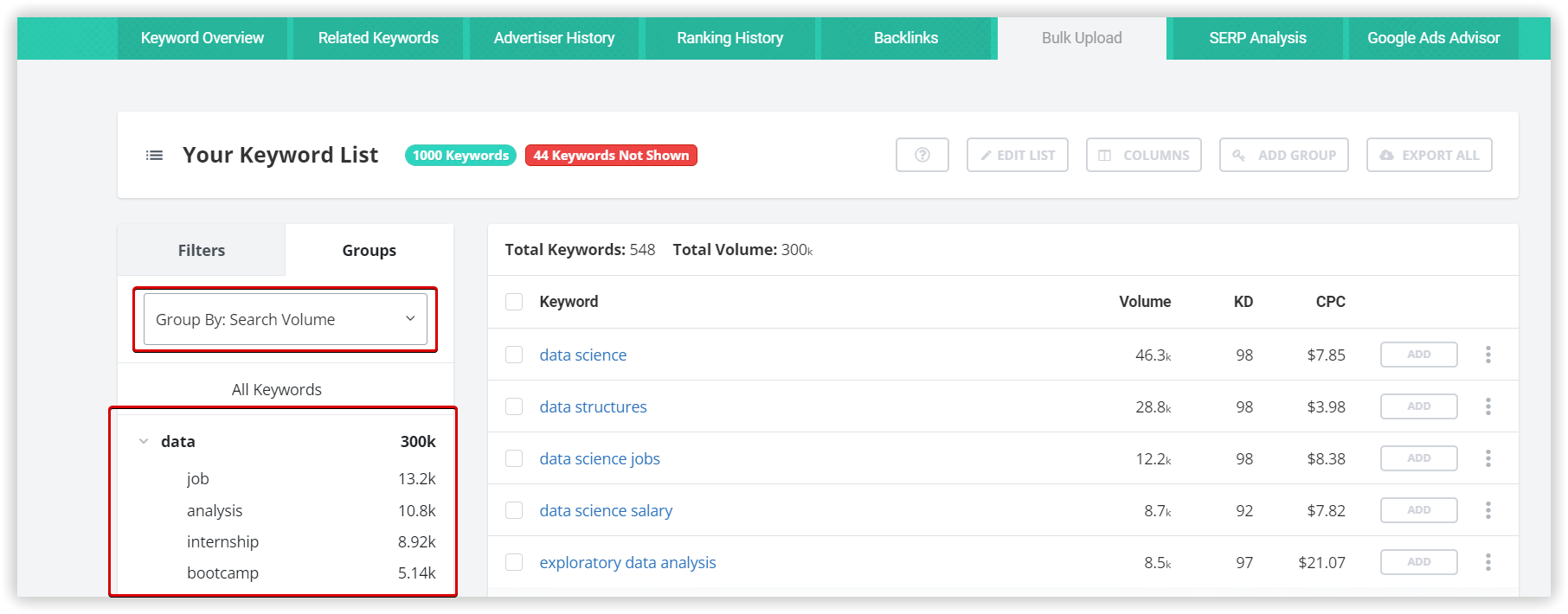
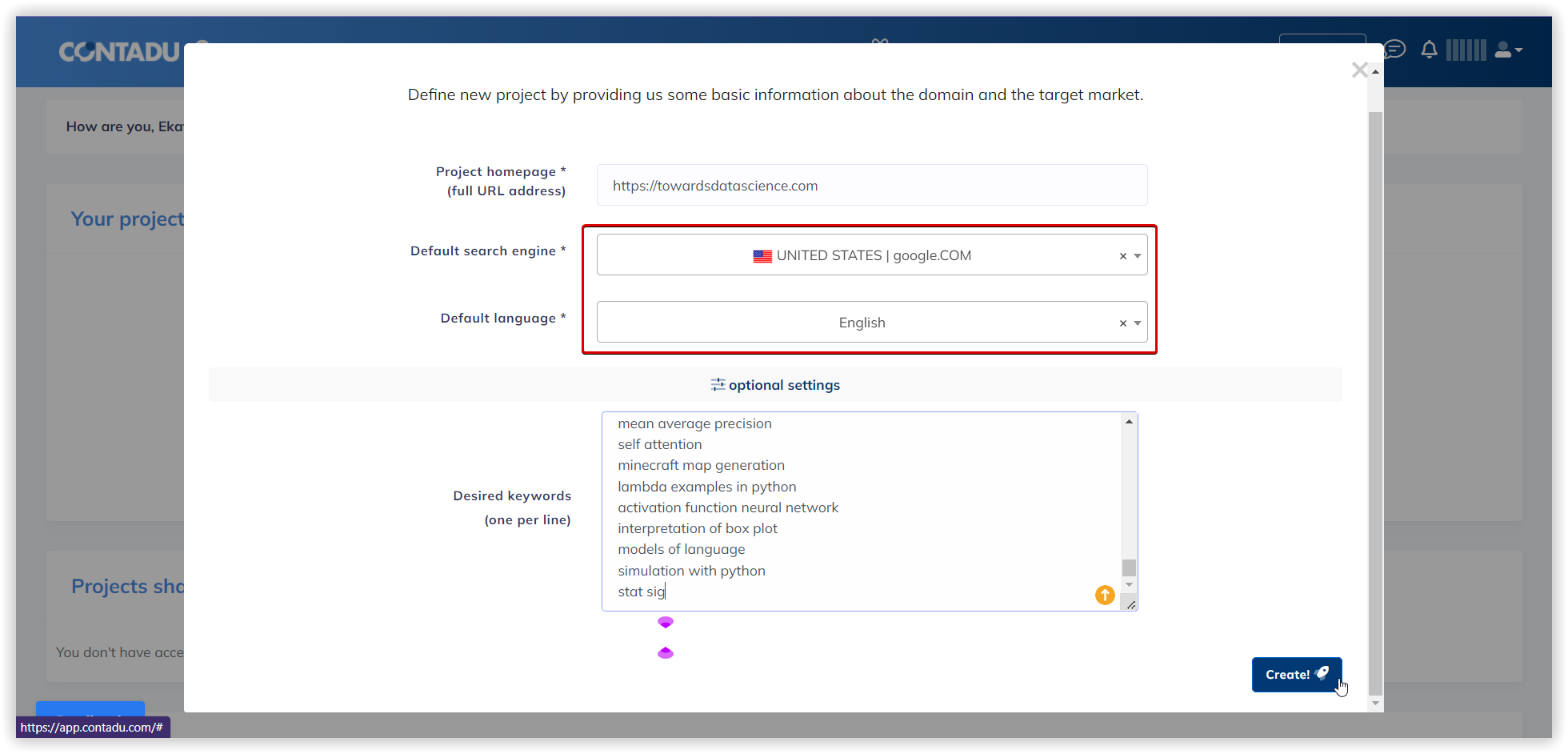
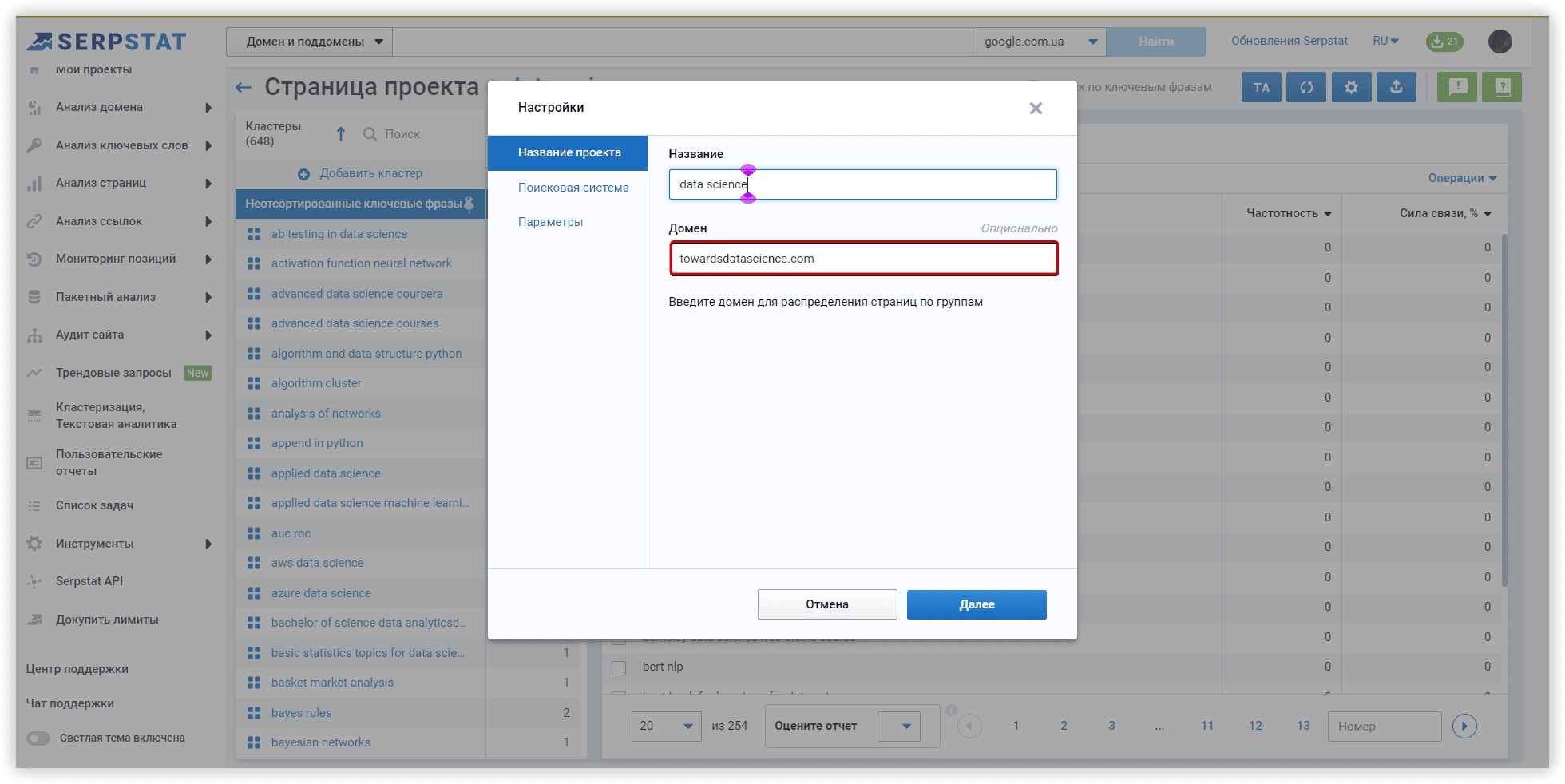
Основные настройки кластеризации
Мы будем использовать домен towardsdatascience.com, как целевой, внутри основного проекта Кластеризации. Это первый этап настройки, который поможет нам перераспределить кластеры по страницам сайта, если наша цель — расширить семантику.
Далее задаем регион и поисковую систему для анализа (Google/US/California/East Palo Alto):
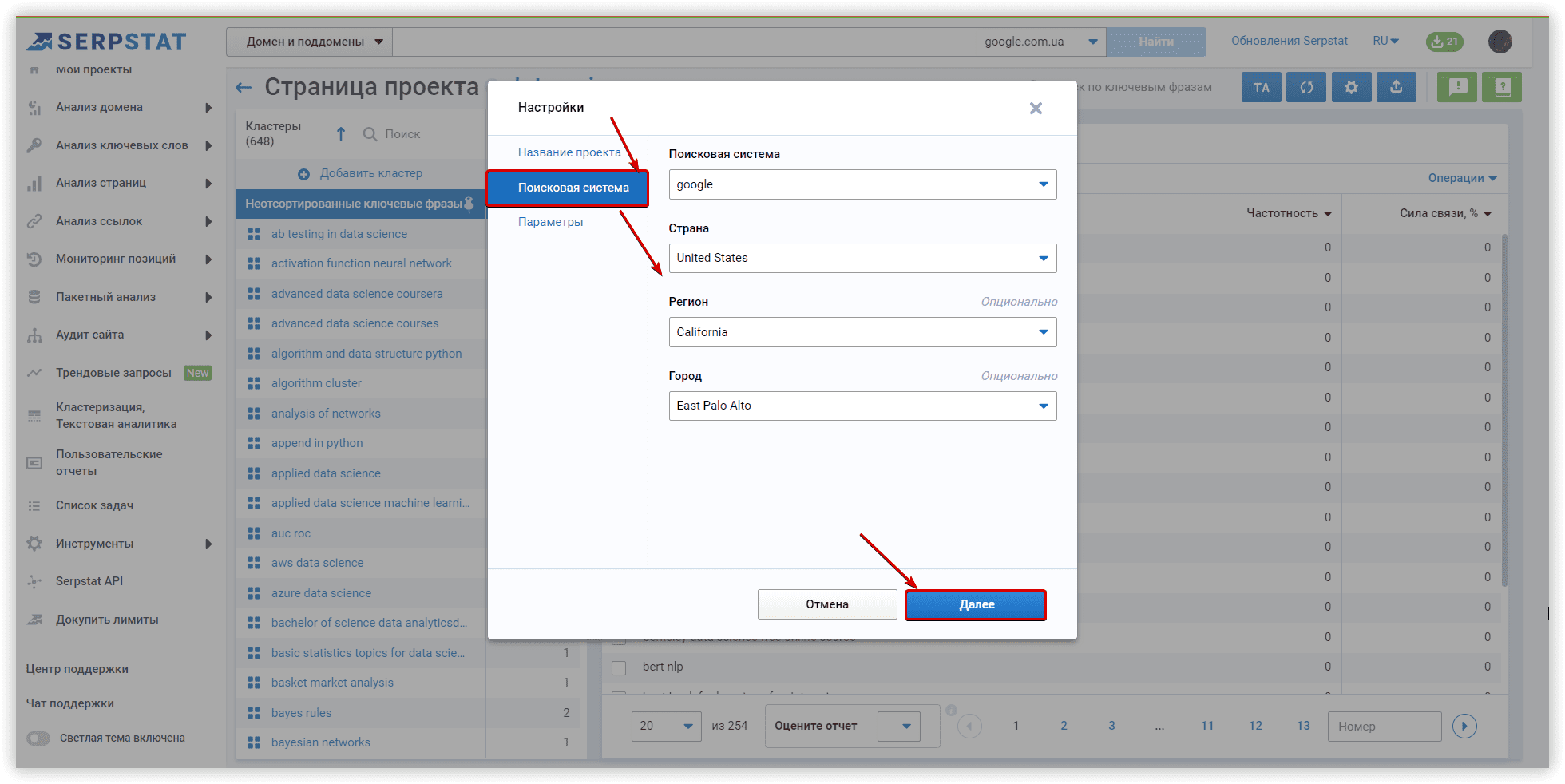
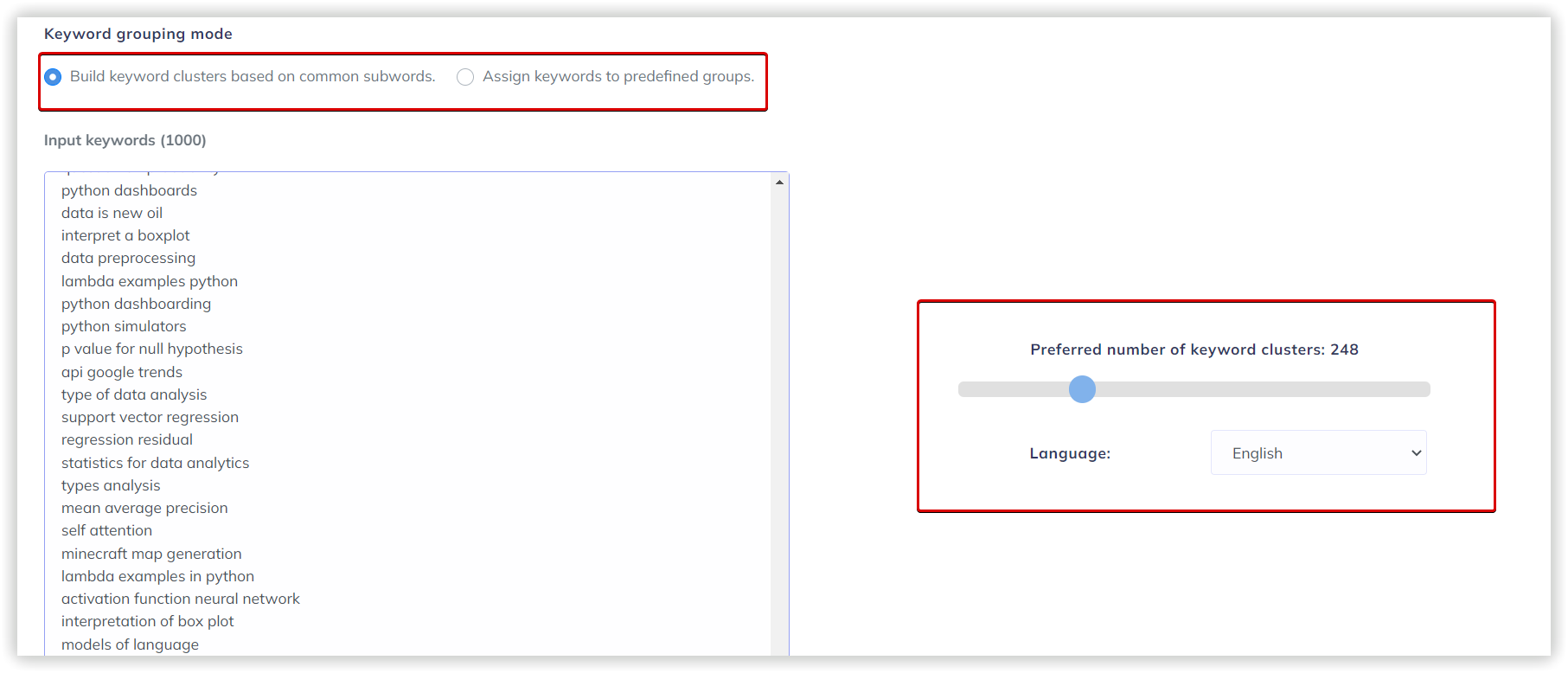
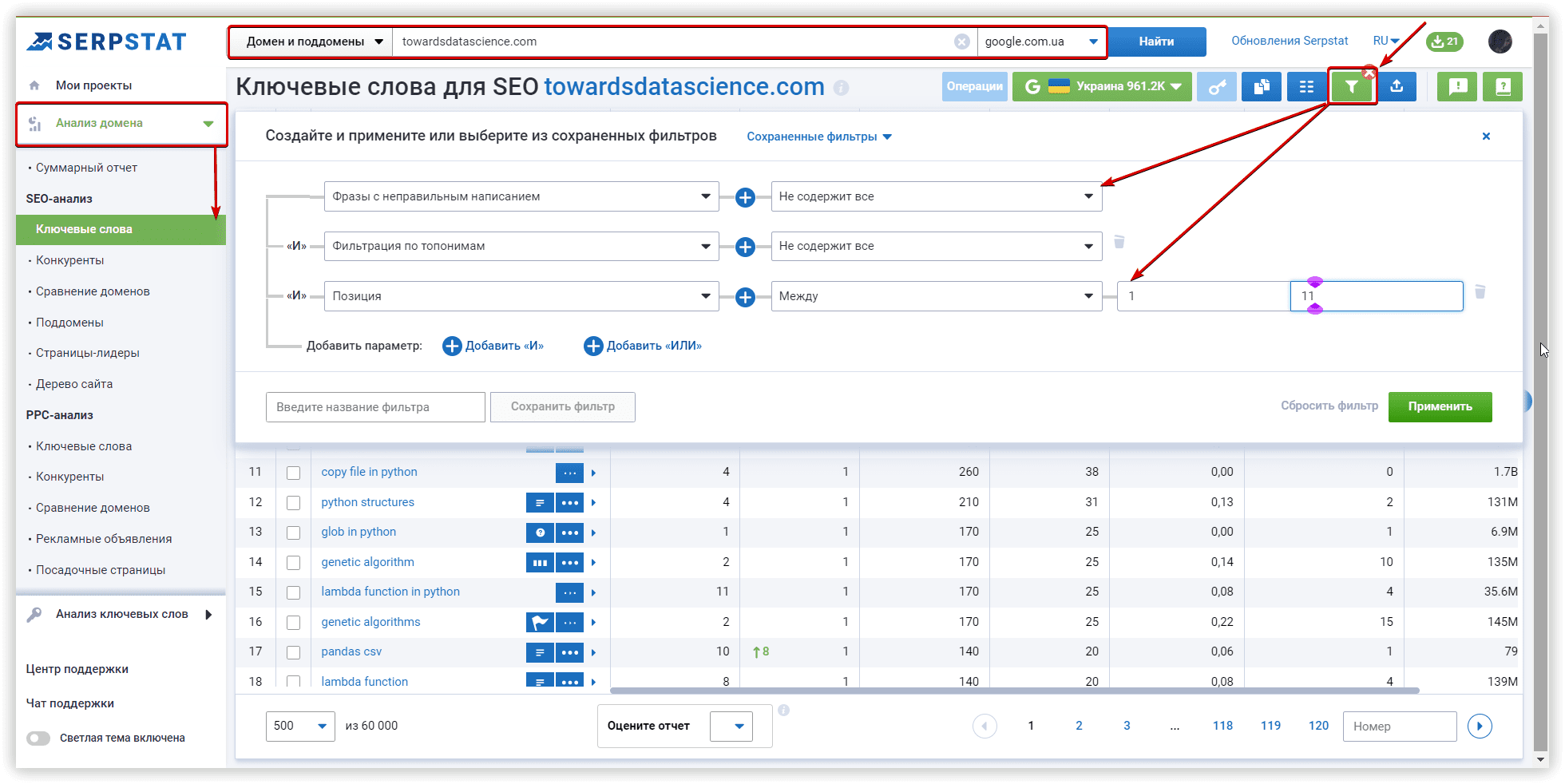
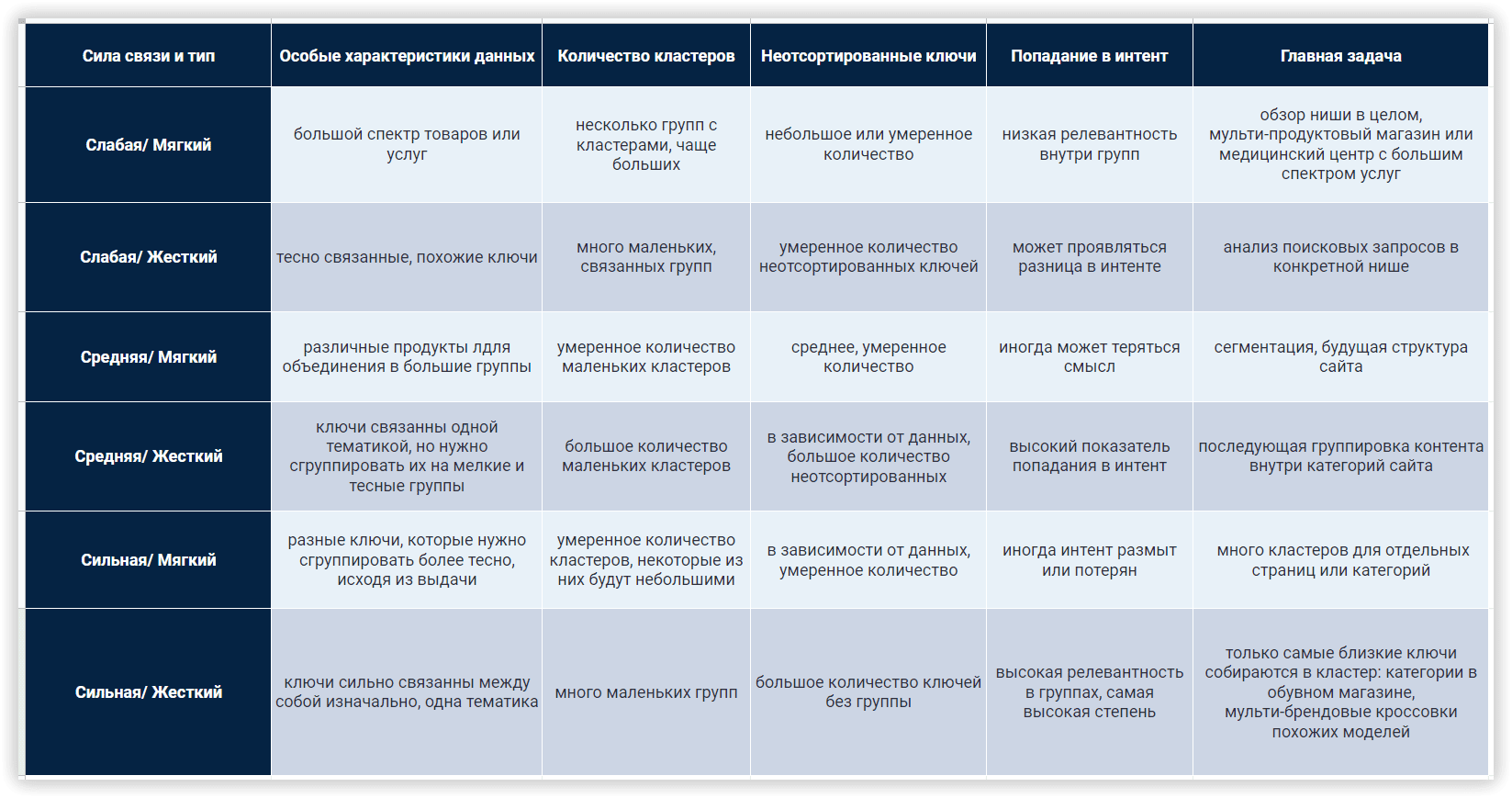
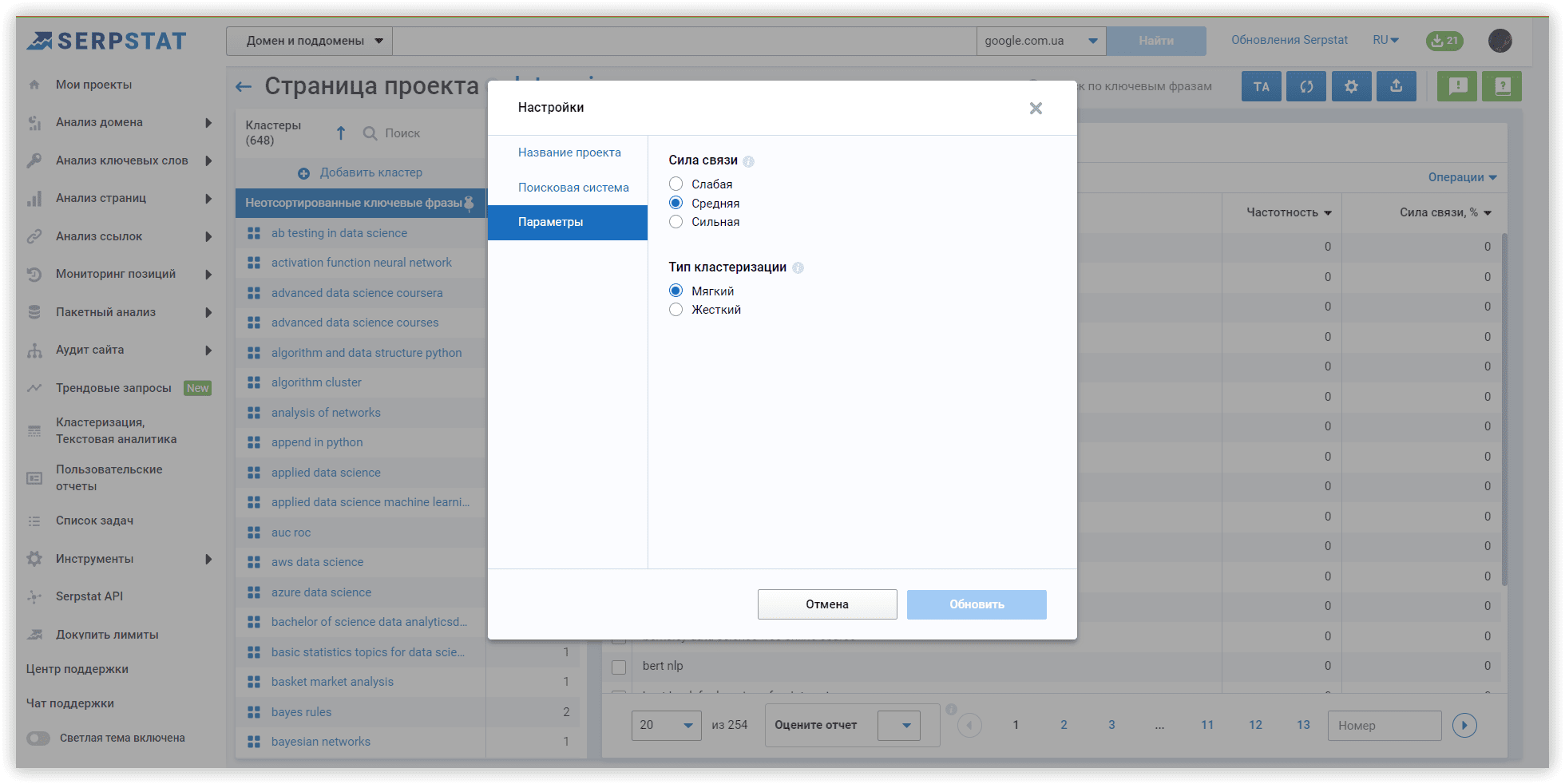
Рассмотрим параметры кластеризации более детально. Под «Силой связи» подразумевается количество общих URL в топ-30 результатов по ключевым словам. Требования при «Слабой силе связи» — 3 общих URL в выдаче для того, чтобы фразы попали в один кластер, вариант для «Средней силы связи» — не менее 8 общих URL-адресов, для «Сильной силы связи» потребуется минимум 12 общих страниц в выдаче, чтобы сгруппировать ключи в одном кластере. Стоит помнить, что при такой настройке критерии для фраз в одной группе ужесточаются, следовательно — кластеров будет меньше, а большое количество ключей попадут в неотсортированные группы, без пар.
Тип кластеризации определяет то, как ключи будут собираться в кластер. «Мягкий тип» — для создания кластера нам не нужны общие URL-адреса для ВСЕХ ключевых слов в группе. Визуализацию этого типа кластеризации, можно представить так:
Тип кластеризации определяет то, как ключи будут собираться в кластер. «Мягкий тип» — для создания кластера нам не нужны общие URL-адреса для ВСЕХ ключевых слов в группе. Визуализацию этого типа кластеризации, можно представить так:

Если же вам нужны более плотные, хоть и не такие большие группы, где у каждого ключа в кластере будут общие URL-адреса, выбирайте «Жесткий тип». При таком типе часть ключей останется неотсортированной из-за отсутствия общих URL для объединения в кластер. Это обязательный параметр соответствующий этим настройкам.

Чтобы подобрать настройки под ваши задачи, воспользуйтесь этой таблицей:
В рамках нашего обзора алгоритмов, проверим кластеризацию со средней силой связи и мягким типом кластеризации. Проекты в двух других сервисах также запущены с аналогичными настройками.
Если у вас скопились новые ключи для кластеризации, вы можете добавить их до запуска группировки, или же, сделать это позже, перезапустив проект с новыми ключевыми словами.
Если в вашем списке могут оказаться невалидные фразы, рекомендуем активировать соответствующий чекбокс.
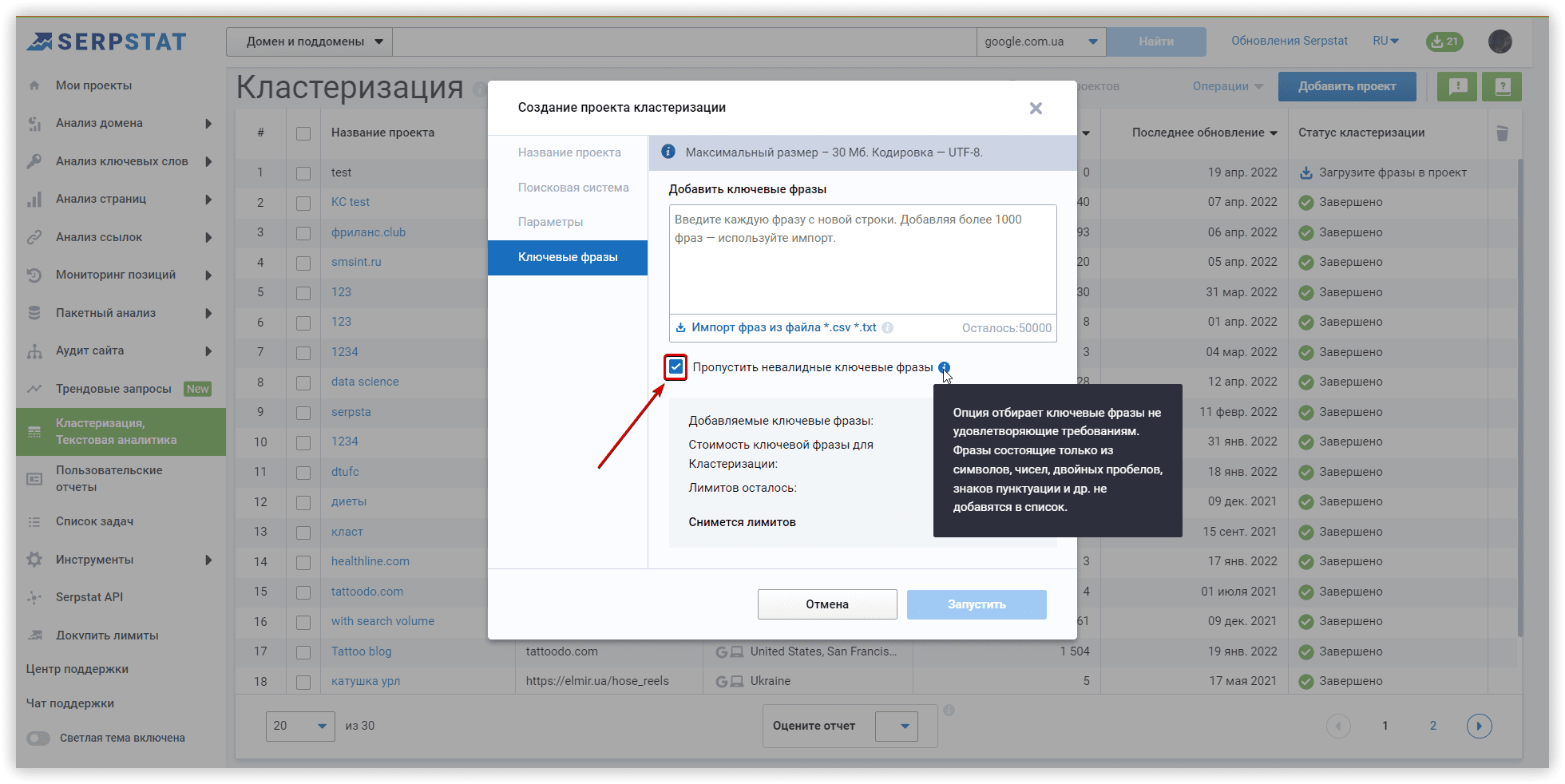
В Serpstat вы можете кластеризовать до 50 тысяч ключевых слов в одном проекте. Наличие крупных отдельных групп, составляющих ваше семантическое ядро, может максимизировать количество фраз, по которым ранжируется ваш контент. Вы можете добавить больше ключей, когда определите кластеры, соответствующие определенному разделу вашего сайта или странице. Изучение уже сгруппированной семантики позволит вам найти новые подходы для большего охвата. Таким образом, вы построите свой контент, основываясь на ожиданиях пользователей.
Длительность кластеризации в Serpstat — от нескольких минут до нескольких часов, в зависимости от количества ключевых фраз в проекте.
Визуализацию кластеризации, которую мы получили с помощью Serpstat по однородности и размеру групп, можно изобразить следующим образом:
Длительность кластеризации в Serpstat — от нескольких минут до нескольких часов, в зависимости от количества ключевых фраз в проекте.
Визуализацию кластеризации, которую мы получили с помощью Serpstat по однородности и размеру групп, можно изобразить следующим образом:
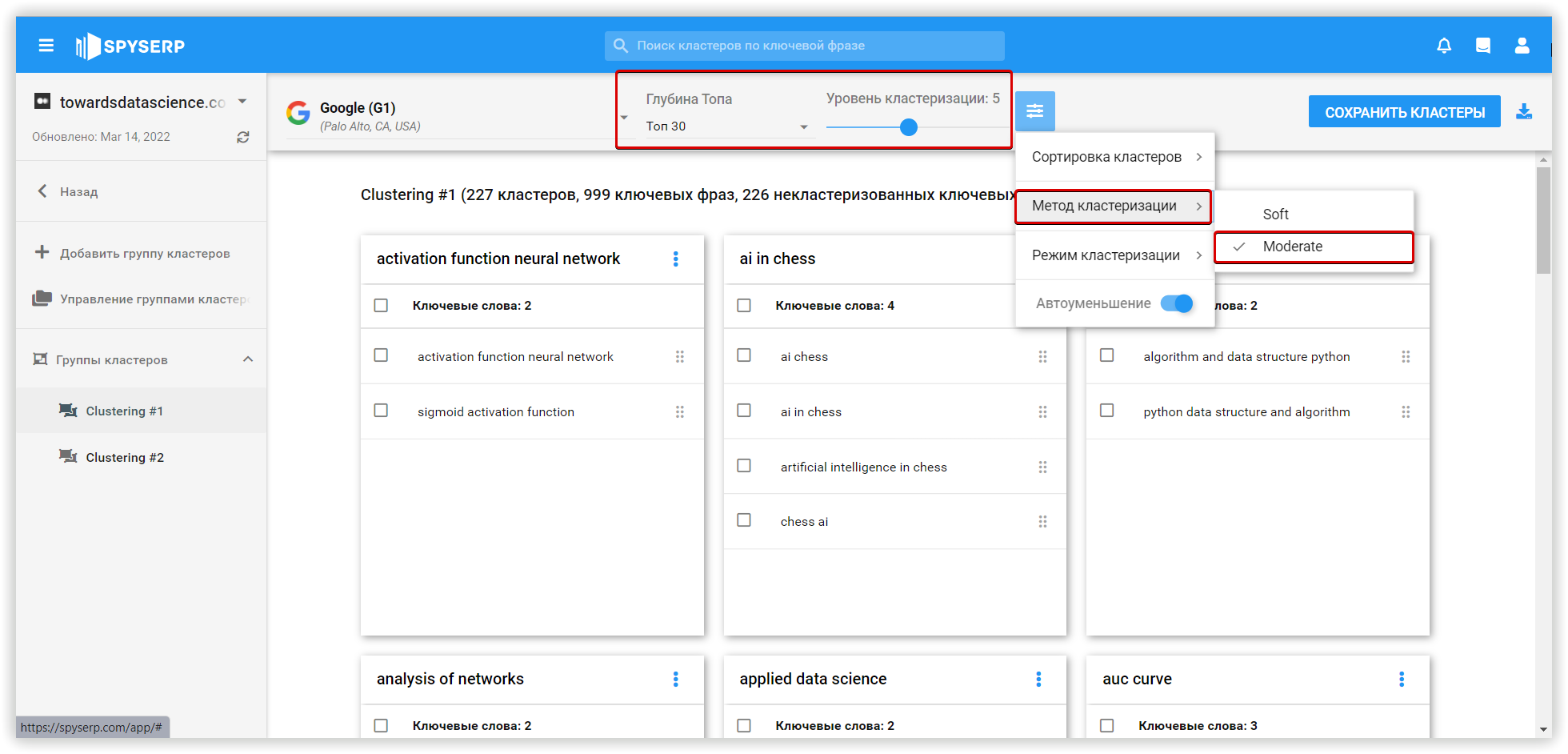
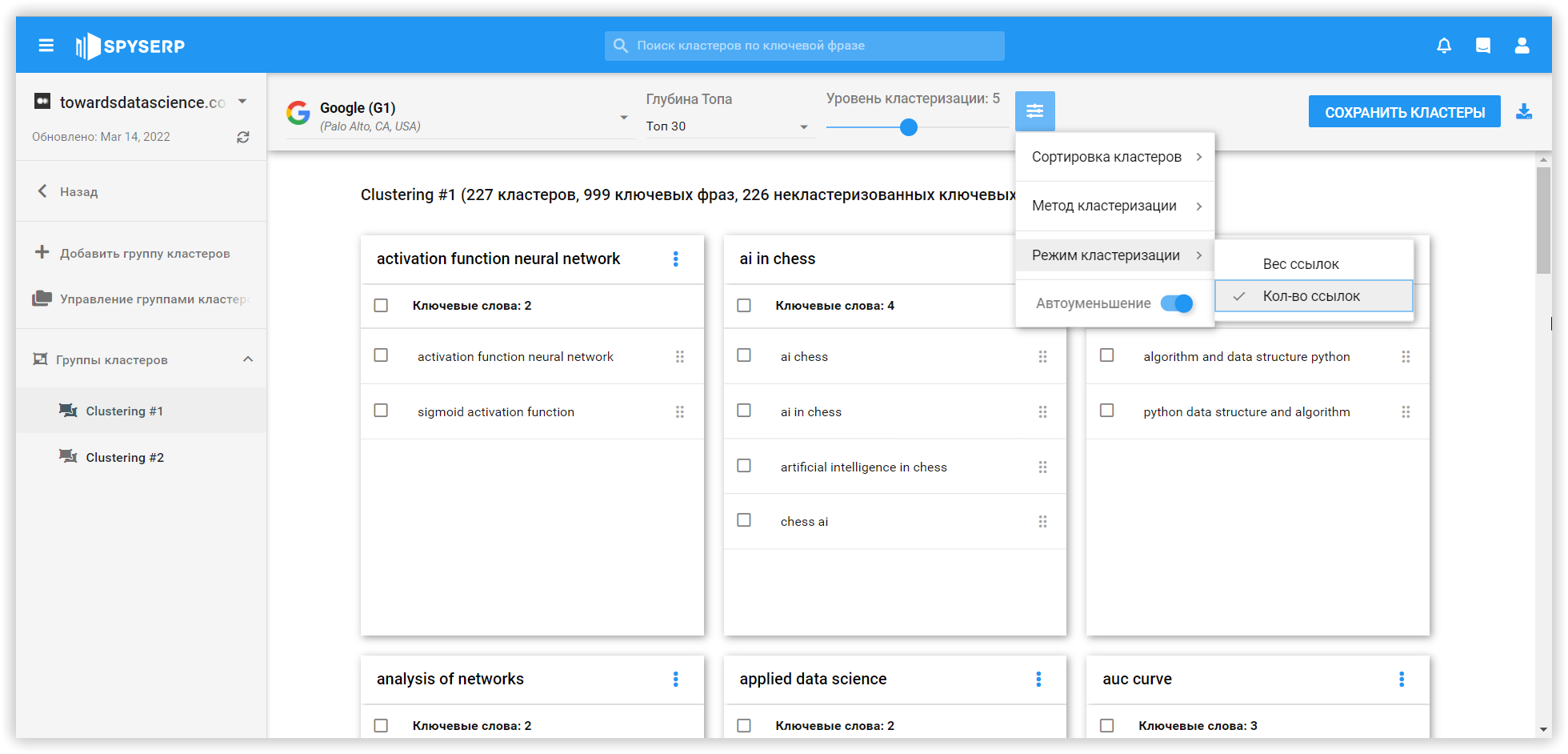
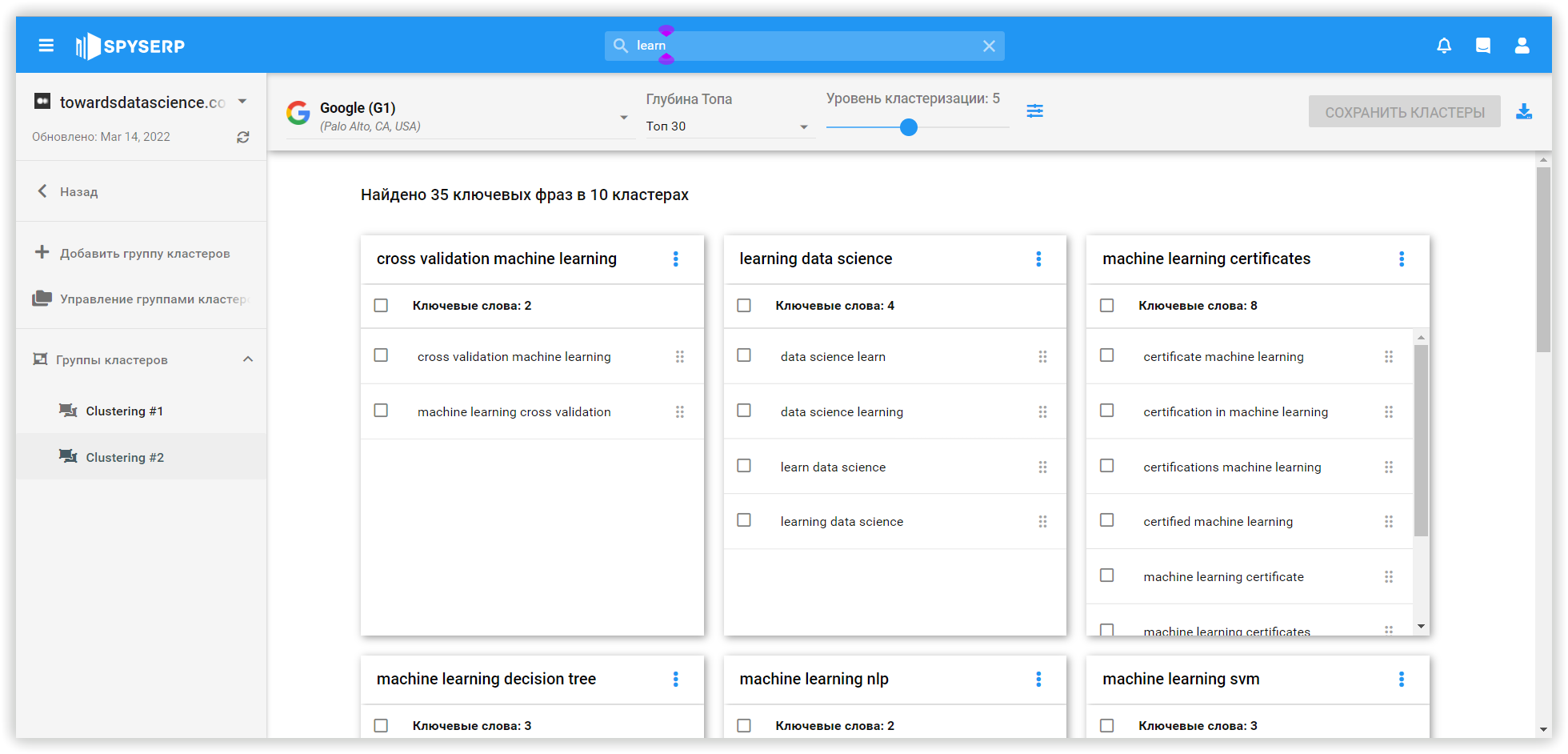
Следующей исследуемой платформой кластеризации на основе SERP-ов, является Spy SERP. Кластеризация в сервисе выполняется в несколько этапов:
«Soft» кластеризация в Spy SERP — это тип группировки ключевых слов вокруг нескольких кластеров с учетом популярности ключевых слов. В «Moderate» варианте — результаты поиска сравниваются друг с другом, моделируя более тесные связи. Этот тип основан на релевантности ключевых слов.
- Запуск проекта в мониторинге позиций, чтобы получить данные напрямую, из SERPов. В соответствии с вашими настройками, инструмент собирает данные и сопоставляет страницы из поисковой выдачи по каждому ключевому слову (от топа 3 до топ 100).
- Если одним и тем же страницам присвоены разные ключевые слова с несколькими совпадениями, бот группирует ключи по этому признаку. Есть возможность установить мощность кластеризации (минимальное количество совпадений). Чем ниже этот показатель, тем большее количество кластеров будет создано.
- Если для ключевых слов в поисковой выдаче нет совпадений, они группируются отдельно.
«Soft» кластеризация в Spy SERP — это тип группировки ключевых слов вокруг нескольких кластеров с учетом популярности ключевых слов. В «Moderate» варианте — результаты поиска сравниваются друг с другом, моделируя более тесные связи. Этот тип основан на релевантности ключевых слов.
Последней платформой, проверенной для сравнения алгоритмов, стала Keyword Cupid, о которой мы упоминали выше. Этот SEO-сервис анализирует первые 5-10 страниц Google (настройка зависит от ниши и количества ожидаемых результатов в выдаче). Так, алгоритм Keyword Cupid создает своеобразную плоскость, чтобы понять, насколько тесно связаны анализируемые ключевые слова. Логично предположить, что придавать больше значения стоит совпадениям на 1-й странице, а не на 5-й.
Подход сервиса уникален из-за использования двух видов программируемых нейронных сетей. Первая сеть фокусируется на группировке импортируемых ключевых слов в очень тесные тематические кластеры, чтобы гарантировать, что дальнейшая группировка будет корректной в случае возникновения коллизий.
Вторая нейронная сеть фокусируется на группировке созданных кластеров и использует набор определенных правил, чтобы обеспечить более «гибкие» связи.
Keyword Cupid не использует алгоритм NLP, TF-IDF или показатели релевантности для кластеризации. Кроме того, сервис не считает ссылки, отвечающие за «тесность связей» в кластере. Если Google выпустит апдейт, улучшающий попадание в интент в выдаче, результаты кластеризации тоже улучшатся. Название кластера служит разметкой для группы результатов, используется как центр внутри узла (блока или темы).
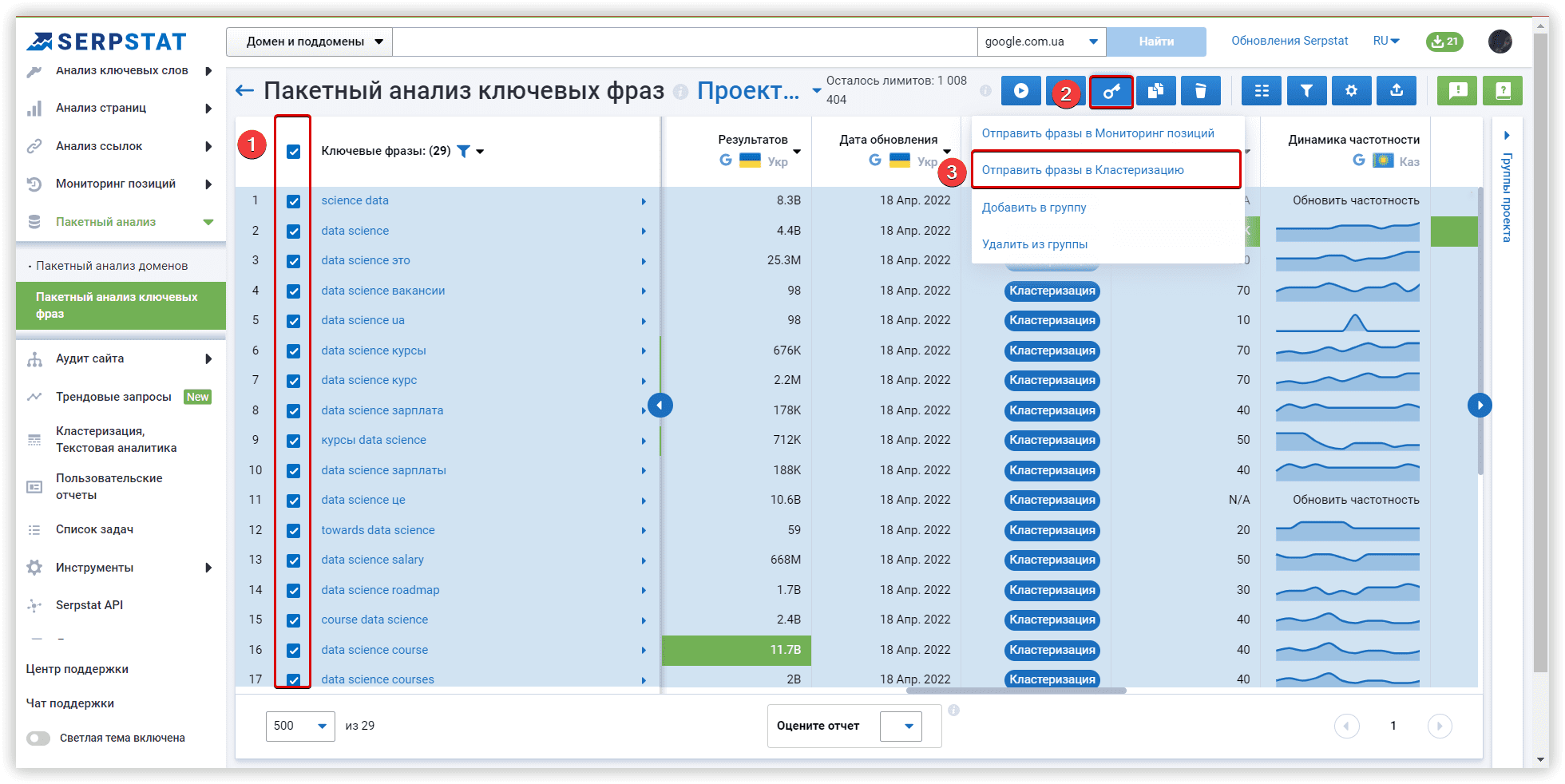
Чтобы начать кластеризацию данных в Keyword Cupid, нужно подготовить файл с основными показателями по ключам: сложностью (KD), стоимостью за клик (CPC) и частотностью. В этом вам снова поможет Пакетный анализ ключевых фраз.
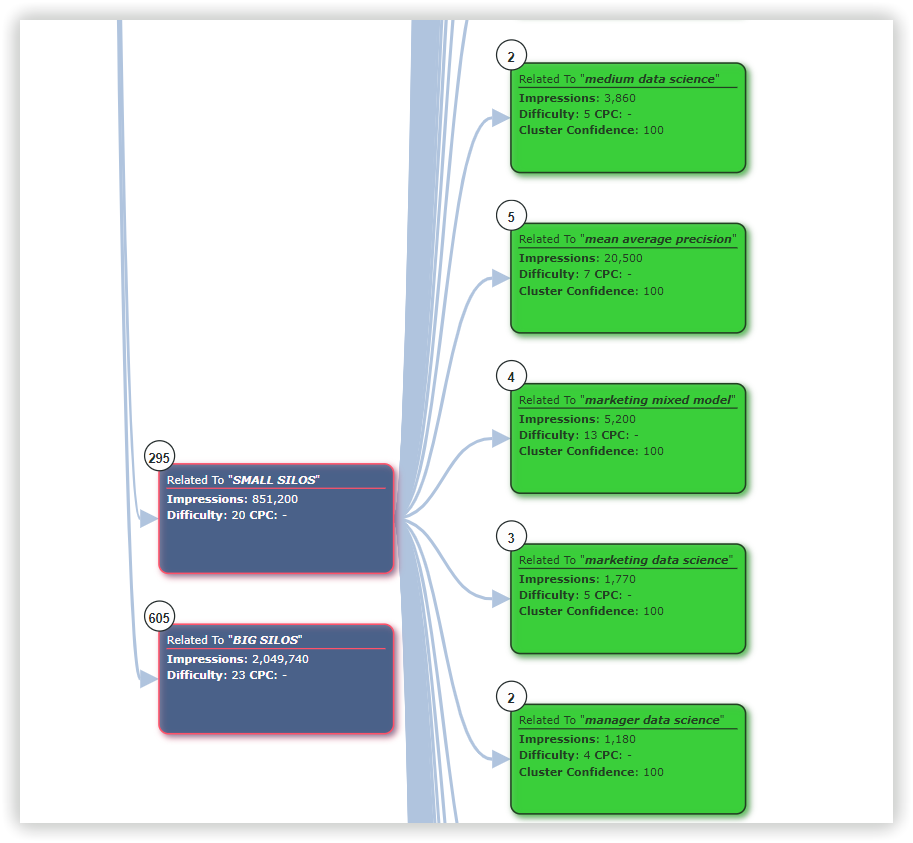
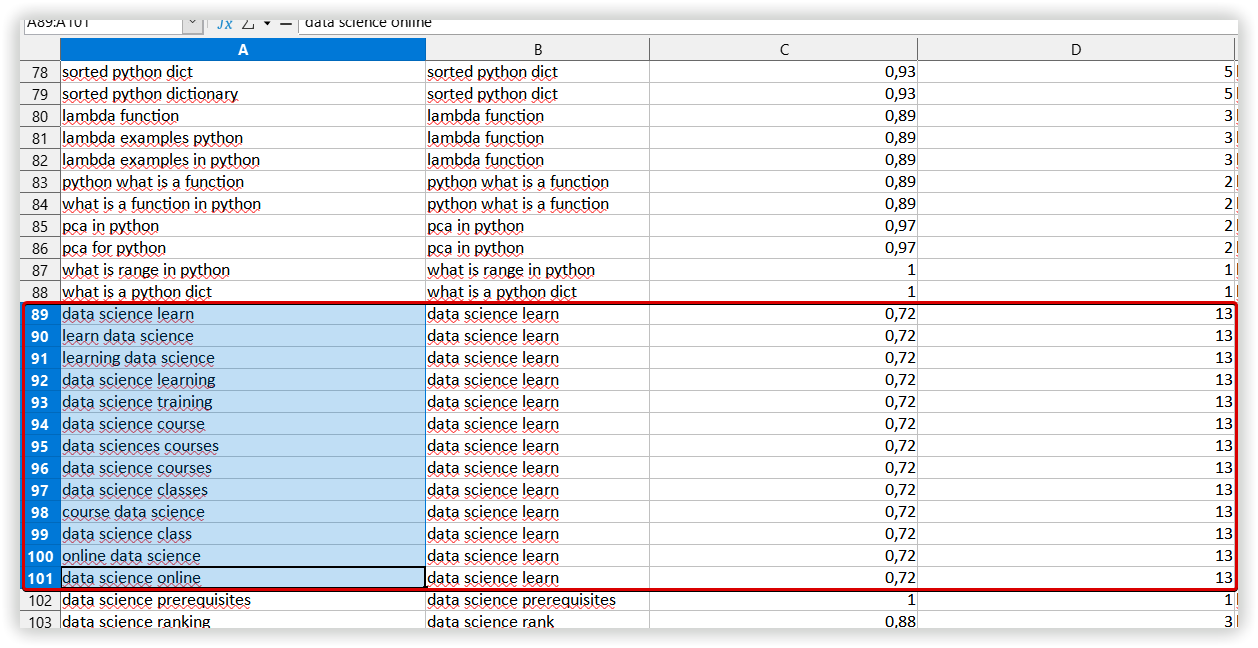
Для проверки качества созданных кластеров мы выбрали один случайный кластер, общий для всех инструментов. В Serpstat это было «Data science learning» — 13 ключевых слов:
Подход сервиса уникален из-за использования двух видов программируемых нейронных сетей. Первая сеть фокусируется на группировке импортируемых ключевых слов в очень тесные тематические кластеры, чтобы гарантировать, что дальнейшая группировка будет корректной в случае возникновения коллизий.
Вторая нейронная сеть фокусируется на группировке созданных кластеров и использует набор определенных правил, чтобы обеспечить более «гибкие» связи.
Keyword Cupid не использует алгоритм NLP, TF-IDF или показатели релевантности для кластеризации. Кроме того, сервис не считает ссылки, отвечающие за «тесность связей» в кластере. Если Google выпустит апдейт, улучшающий попадание в интент в выдаче, результаты кластеризации тоже улучшатся. Название кластера служит разметкой для группы результатов, используется как центр внутри узла (блока или темы).
Чтобы начать кластеризацию данных в Keyword Cupid, нужно подготовить файл с основными показателями по ключам: сложностью (KD), стоимостью за клик (CPC) и частотностью. В этом вам снова поможет Пакетный анализ ключевых фраз.
Для проверки качества созданных кластеров мы выбрали один случайный кластер, общий для всех инструментов. В Serpstat это было «Data science learning» — 13 ключевых слов:
1
data science learn
2
learn data science
3
learning data science
4
data science learning
5
data science training
6
data science course
7
data sciences courses
8
data science courses
9
data science classes
10
course data science
11
data science class
12
online data science
13
data science online
Однородность: 72%
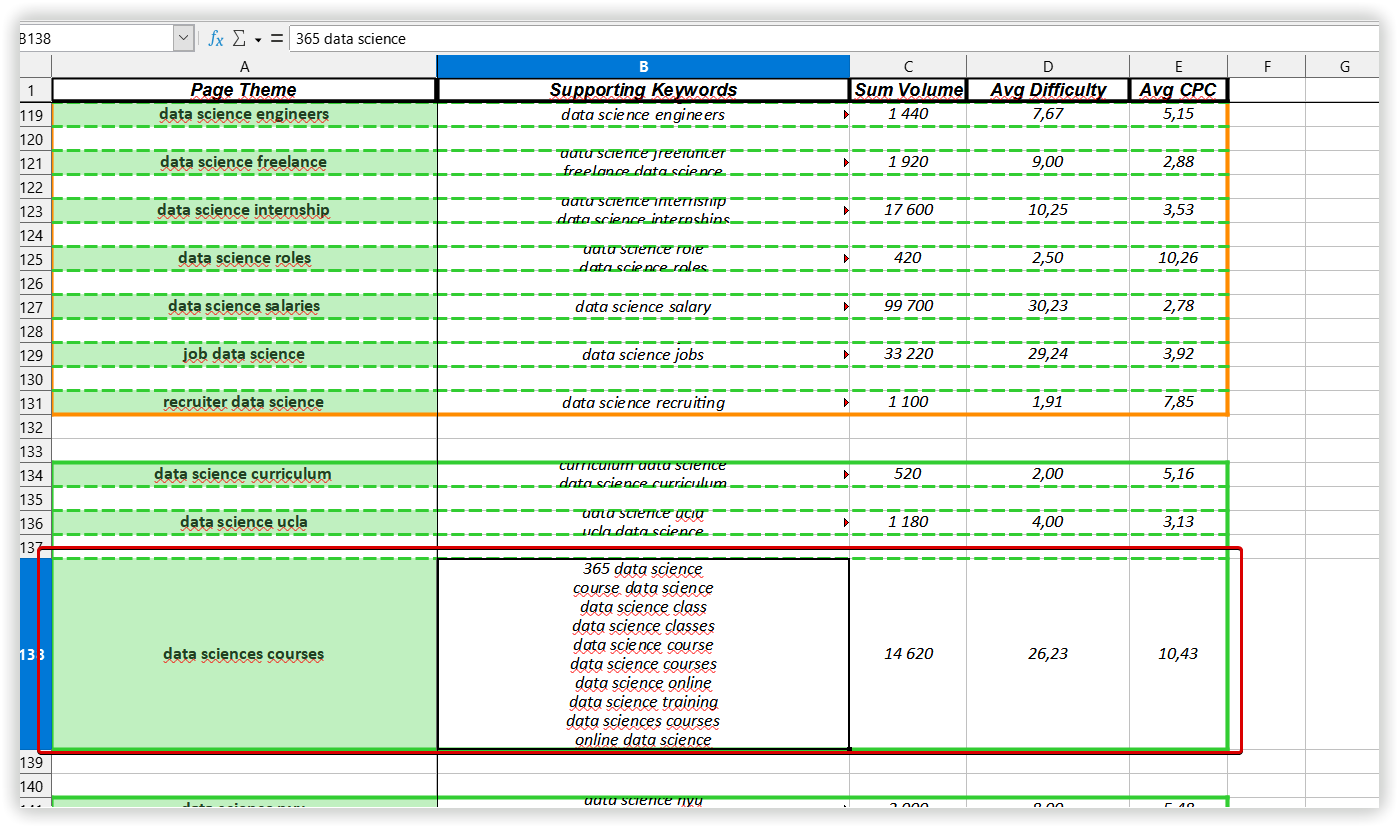
В Keyword Cupid — «Data sciences courses» на 10 ключей:
1
365 data science
2
course data science
3
data science class
4
data science classes
5
data science course
6
data science courses
7
data science online
8
data science training
9
data sciences courses
10
online data science
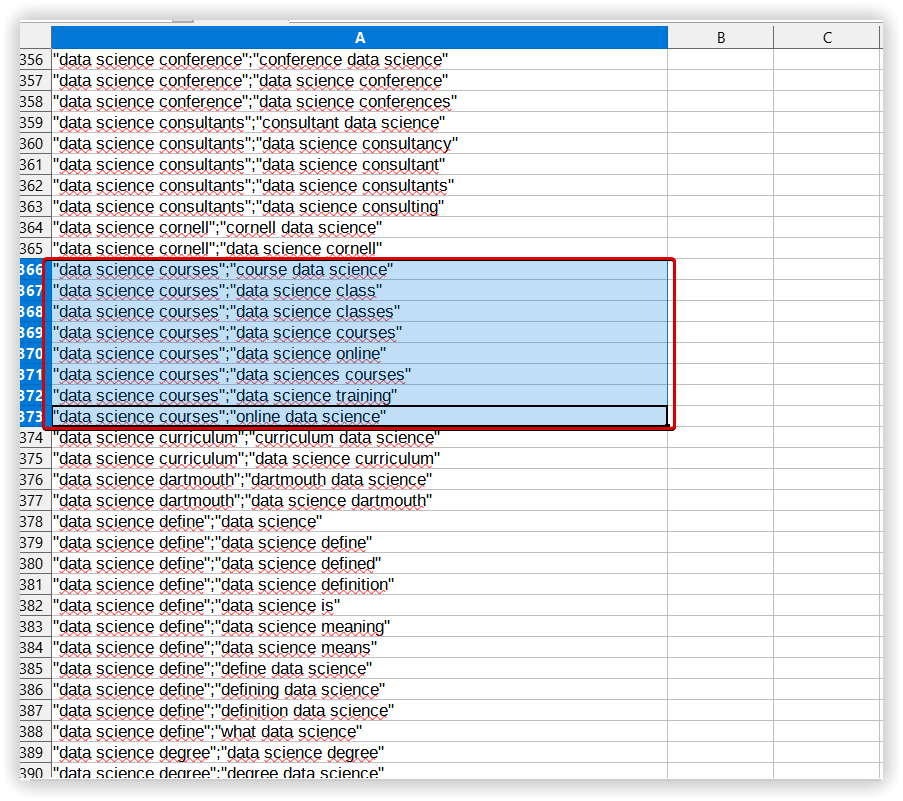
В Spy SERP — «Data science courses» на 8 ключевых слов:
1
course data science
2
data science class
3
data science classes
4
data science courses
5
data science online
6
data sciences courses
7
data science training
8
online data science
Следующий шаг — провести Текстовую аналитику и проанализировать результаты.
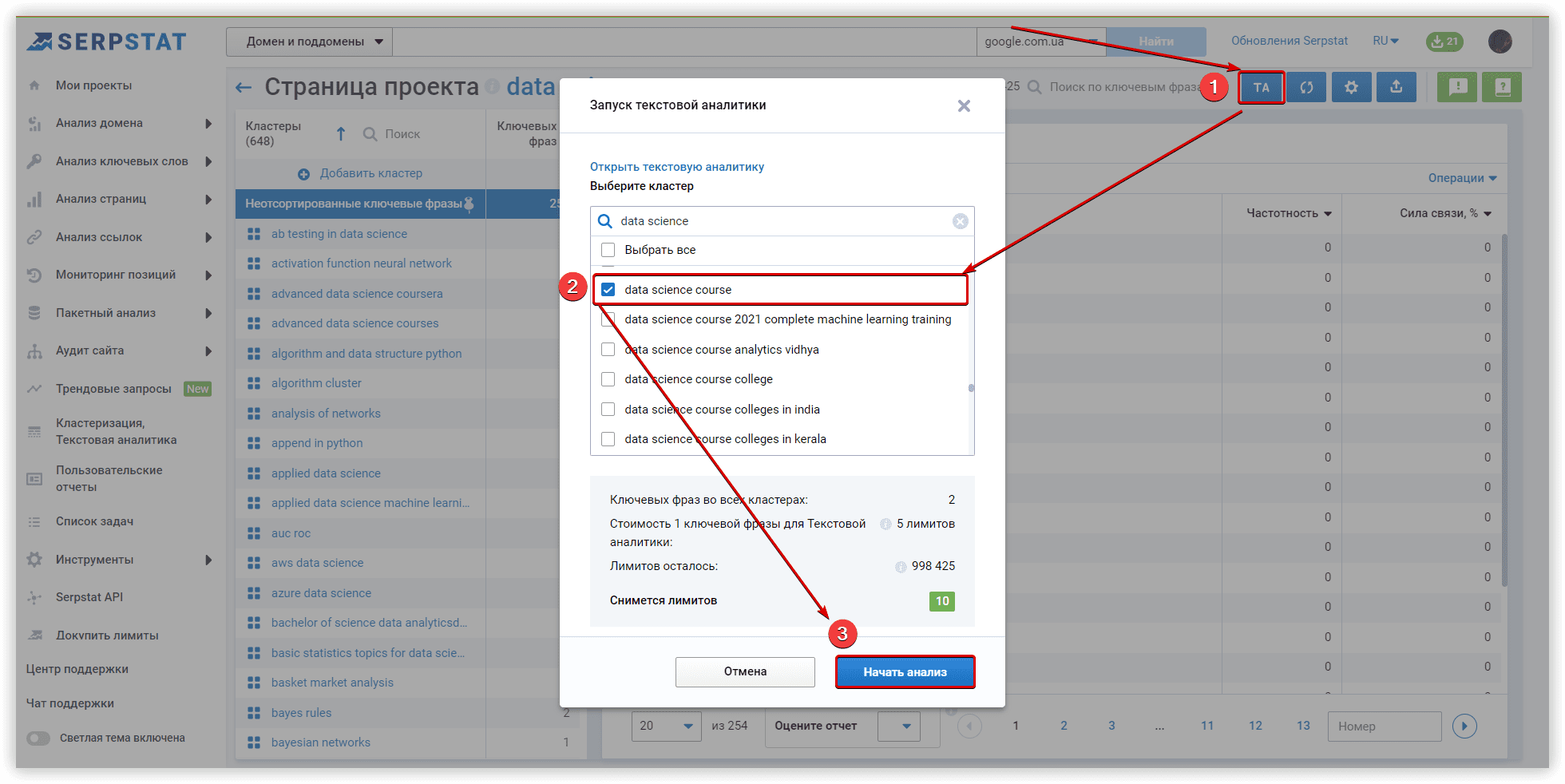
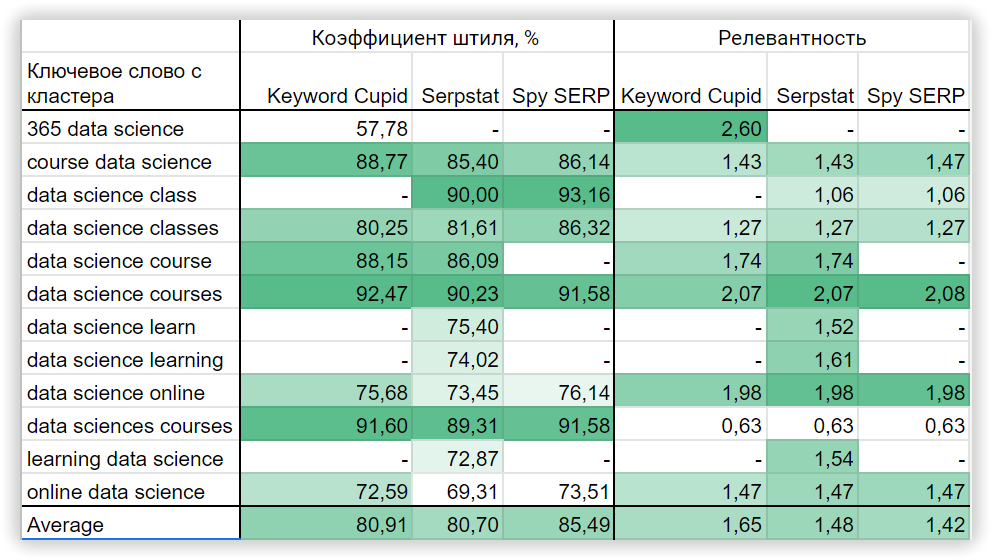
Анализ контента из ТОП-15 URL-адресов в поисковой выдаче и подсчет результатов может продолжаться нескольких часов, в зависимости от количества ключевых слов в кластере. Далее, мы сравним характеристики кластеров внутри ТА и проверим релевантность текста по каждому анализируемому кластеру, который мы получили в результате работы с исследуемыми инструментами.
Коэффициент штиля, % — указывает на силу связи ключевого слова с другими ключевыми словами в группе, основываясь на тематике.
Релевантность — это соответствие ключевого слова теме целевой страницы. По формуле TF-IDF рассчитывается важность каждого ключевого слова в заголовках конкурентов в метатопе. После этого выводится среднее значение по каждому ключевому слову.
Значимость, % — важность ключевого слова для Title/H1/Body в контексте анализируемой тематики. Эта метрика рассчитывается как отношение ключевого слова к набору ключевых слов, используемых в контенте конкурентов.
Популярность, % — показывает, сколько конкурентов используют данное ключевое слово. Метрика отражает важность используемого ключевого слова.
Покрытие — показывает, как часто используется ключевое слово в точном вхождении, есть ли вероятность того, что в вашем тексте ключ используется слишком часто, или же, что вы пока не добавили рекомендуемые слова из контента конкурентов.
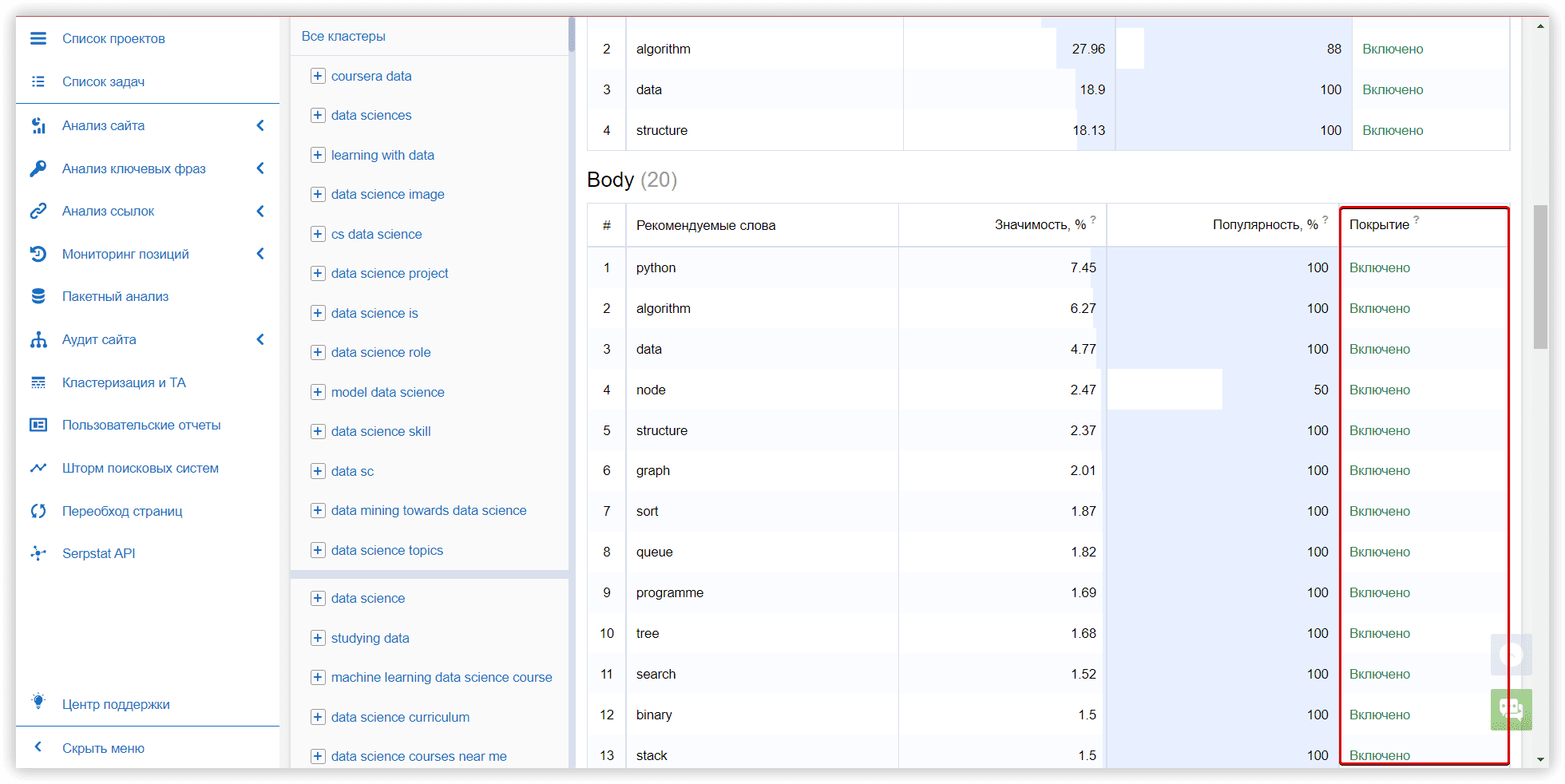
Пример данных в текстовой аналитике для кластера Serpstat:
Коэффициент штиля, % — указывает на силу связи ключевого слова с другими ключевыми словами в группе, основываясь на тематике.
Релевантность — это соответствие ключевого слова теме целевой страницы. По формуле TF-IDF рассчитывается важность каждого ключевого слова в заголовках конкурентов в метатопе. После этого выводится среднее значение по каждому ключевому слову.
Значимость, % — важность ключевого слова для Title/H1/Body в контексте анализируемой тематики. Эта метрика рассчитывается как отношение ключевого слова к набору ключевых слов, используемых в контенте конкурентов.
Популярность, % — показывает, сколько конкурентов используют данное ключевое слово. Метрика отражает важность используемого ключевого слова.
Покрытие — показывает, как часто используется ключевое слово в точном вхождении, есть ли вероятность того, что в вашем тексте ключ используется слишком часто, или же, что вы пока не добавили рекомендуемые слова из контента конкурентов.
Пример данных в текстовой аналитике для кластера Serpstat:
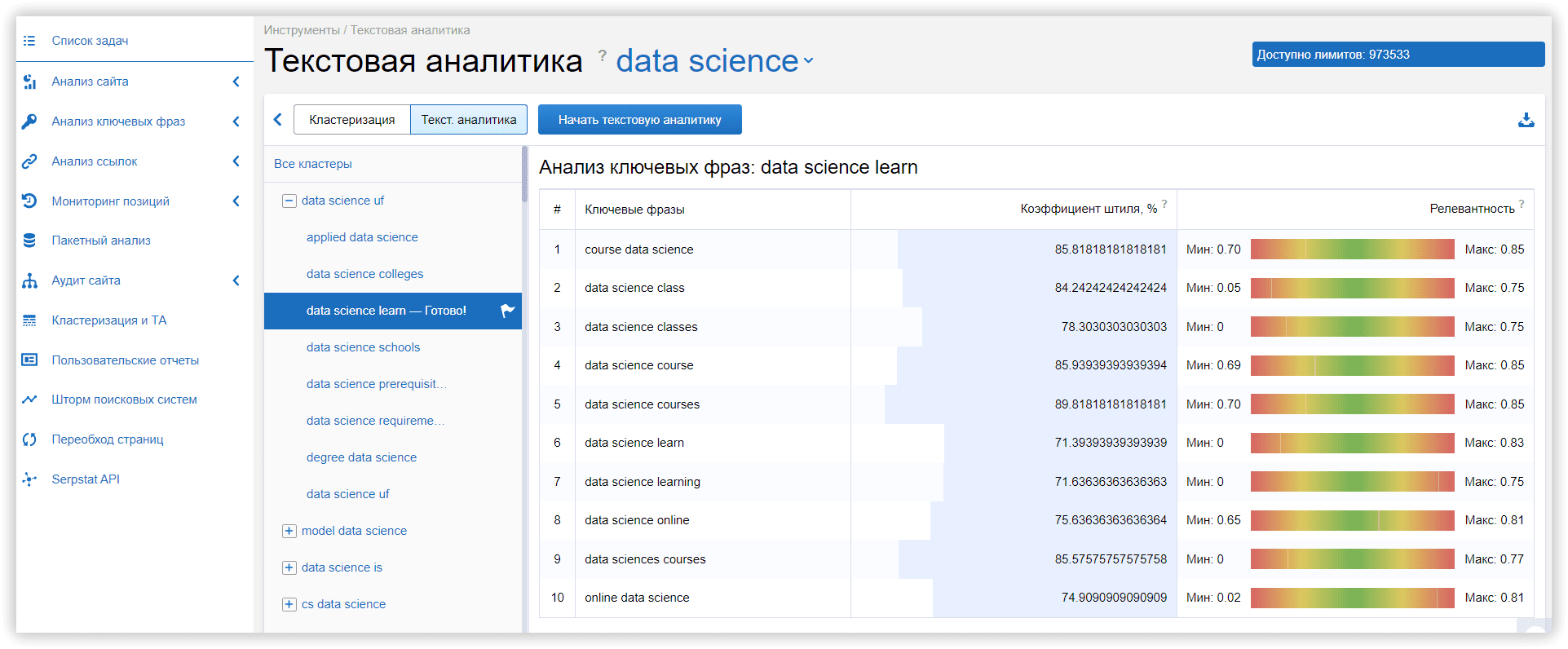
Serpstat добавил возможность создания кастомных кластеров в одном из последних релизов, это дает возможность повторить внутри инструмента кластеры для двух других платформ.
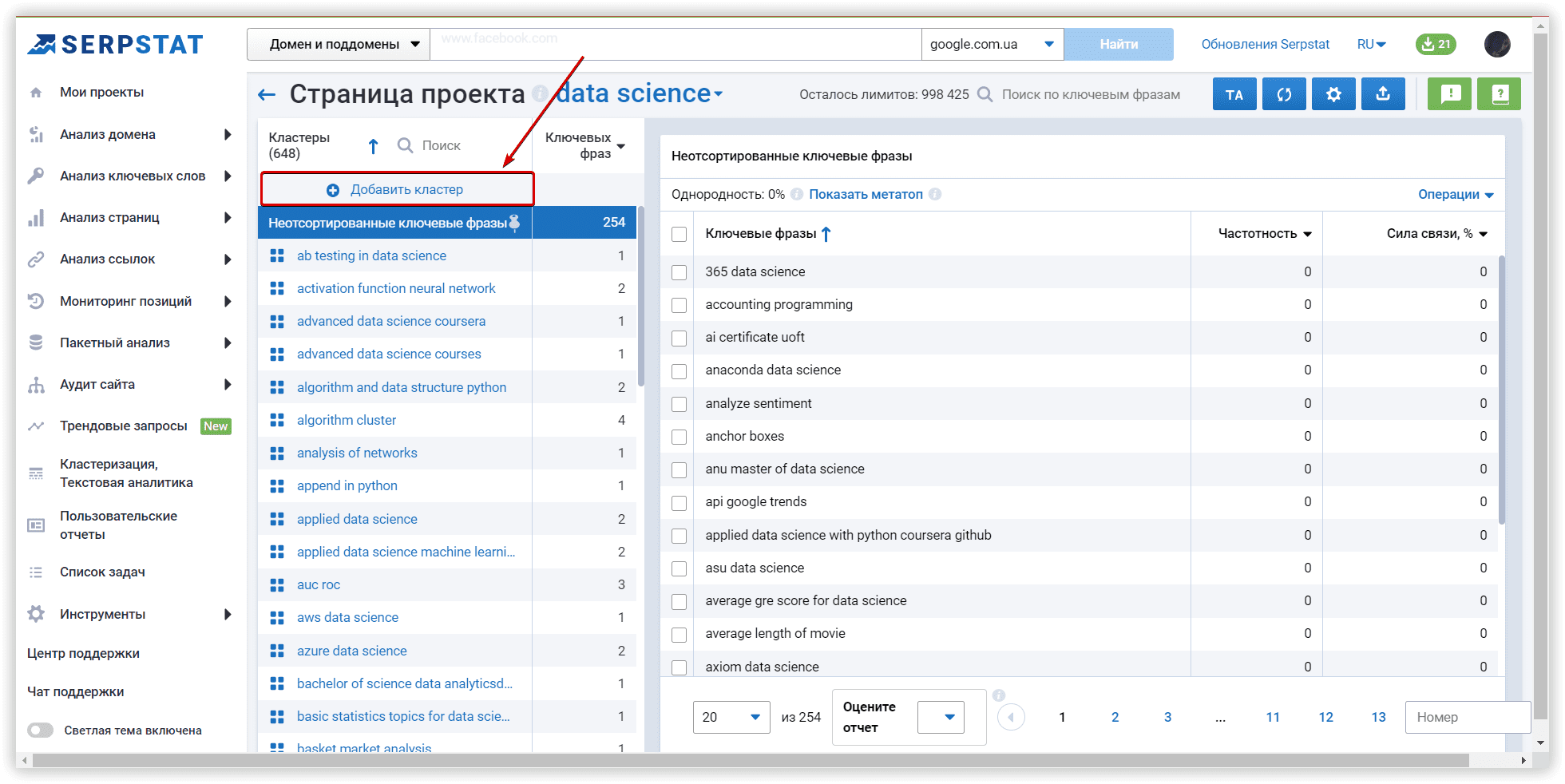
Для добавления нового кластера используйте соответствующую кнопку:
Для добавления нового кластера используйте соответствующую кнопку:
После завершения первого текстового анализа, можно перенести необходимые ключевые слова в новые кластеры для Keyword Cupid и Spy SERP, чтобы начать анализ с новым набором данных.
Чтобы переместить ключевые слова в новый кластер из кластеров Serpstat,можно использовать меню «Операции»:
Чтобы переместить ключевые слова в новый кластер из кластеров Serpstat,можно использовать меню «Операции»:
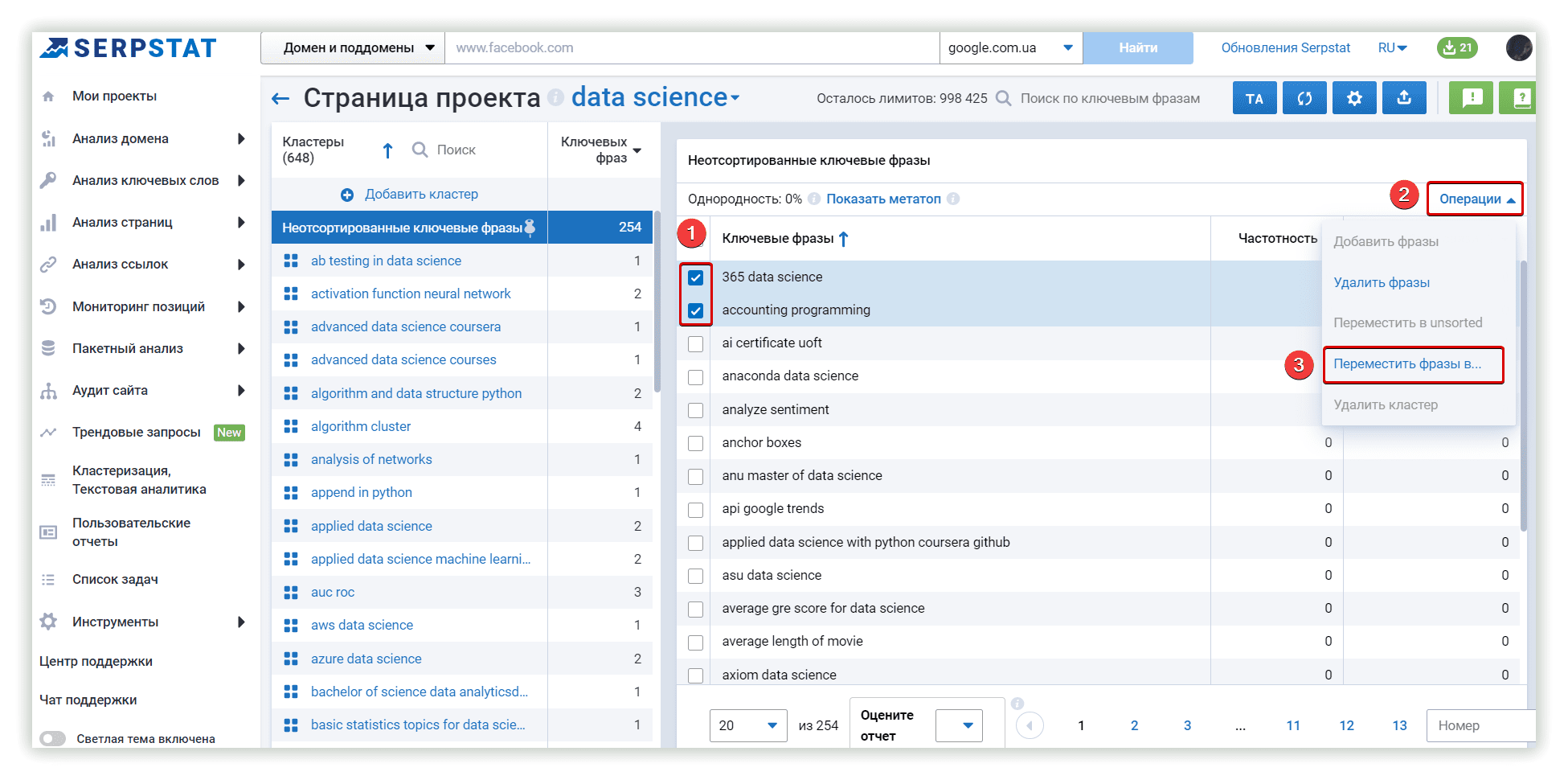
Ключевое слово «365 data science» было в кластере «Неотсортированные ключевые фразы» в Serpstat, Keyword Cupid использовал этот ключ в основном анализируемом кластере.
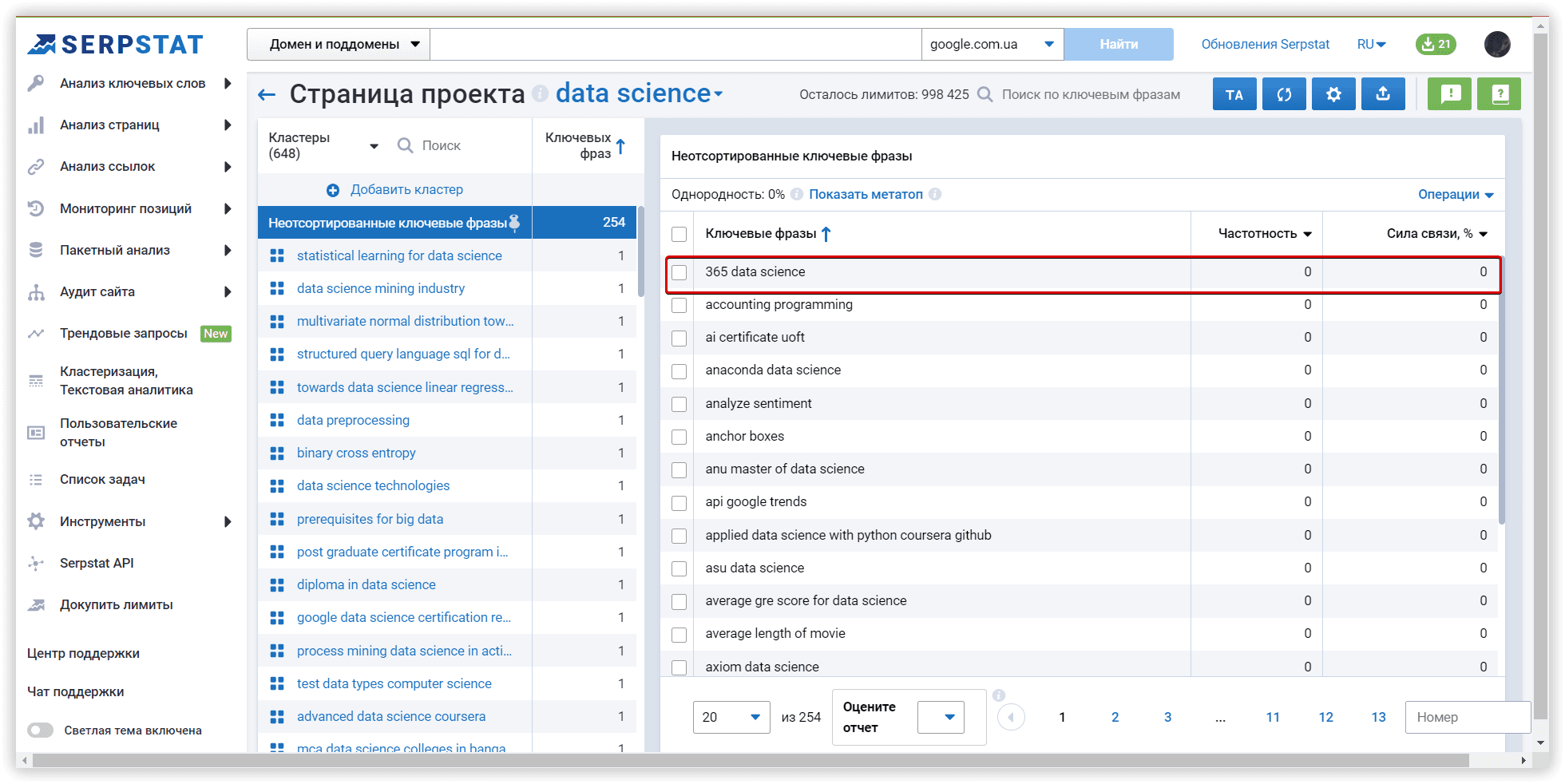
Из 10 ключевых слов от Keyword Cupid, 8 ключей Serpstat обнаружил в ТОП-15 выдачи.
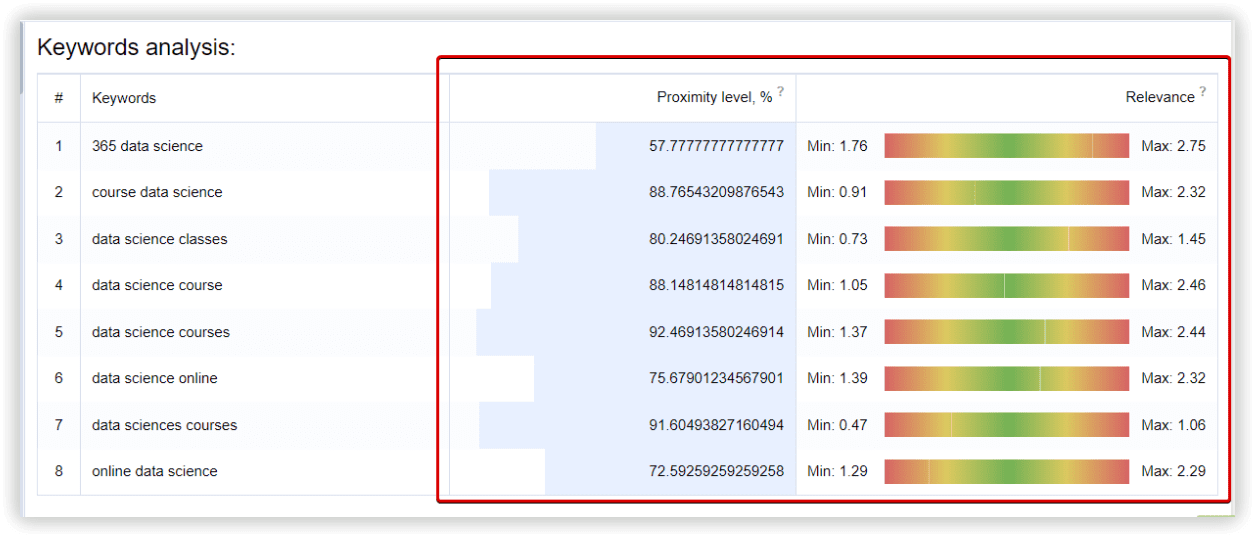
Согласно результату Текстовой аналитики, «365 data science» — не самый подхолящий ключ для этого кластера, его не стоит использовать в контенте, вместе с остальными.
Дальше, повторяем кластер Spy SERP и запускаем аналитику. Этот сервис не учитывал ключи «365 data science» и «data science course». Последний ключ попал в кластер не отсортированных ключей в отчете SpySERP.
Дальше, повторяем кластер Spy SERP и запускаем аналитику. Этот сервис не учитывал ключи «365 data science» и «data science course». Последний ключ попал в кластер не отсортированных ключей в отчете SpySERP.
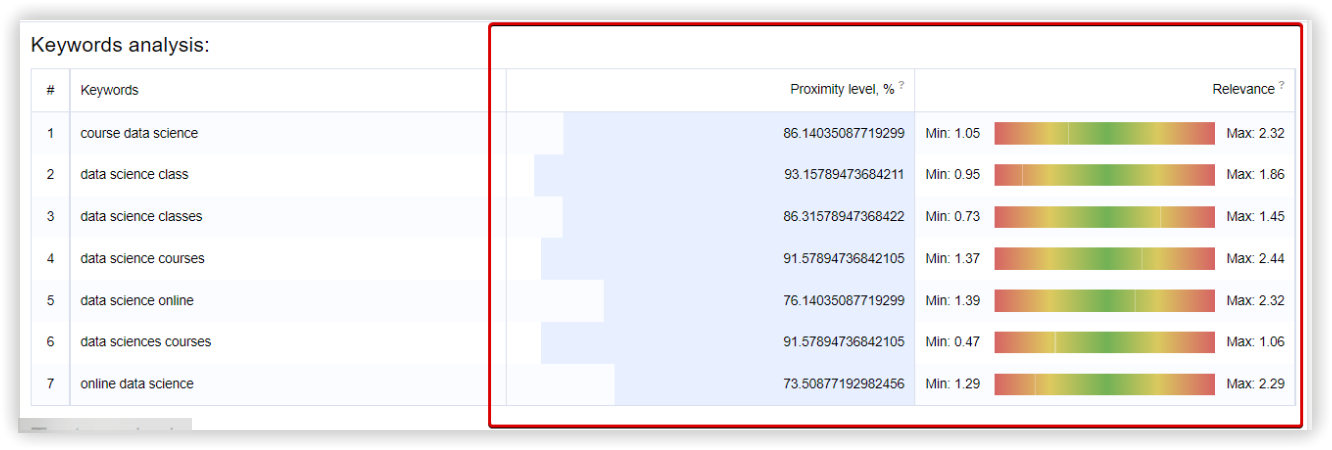
Можно увидеть, что ключ с высокой релевантностью «data science course» не попал в кластер, в то время как менее релевантный «online data science» присутствует в отчете.
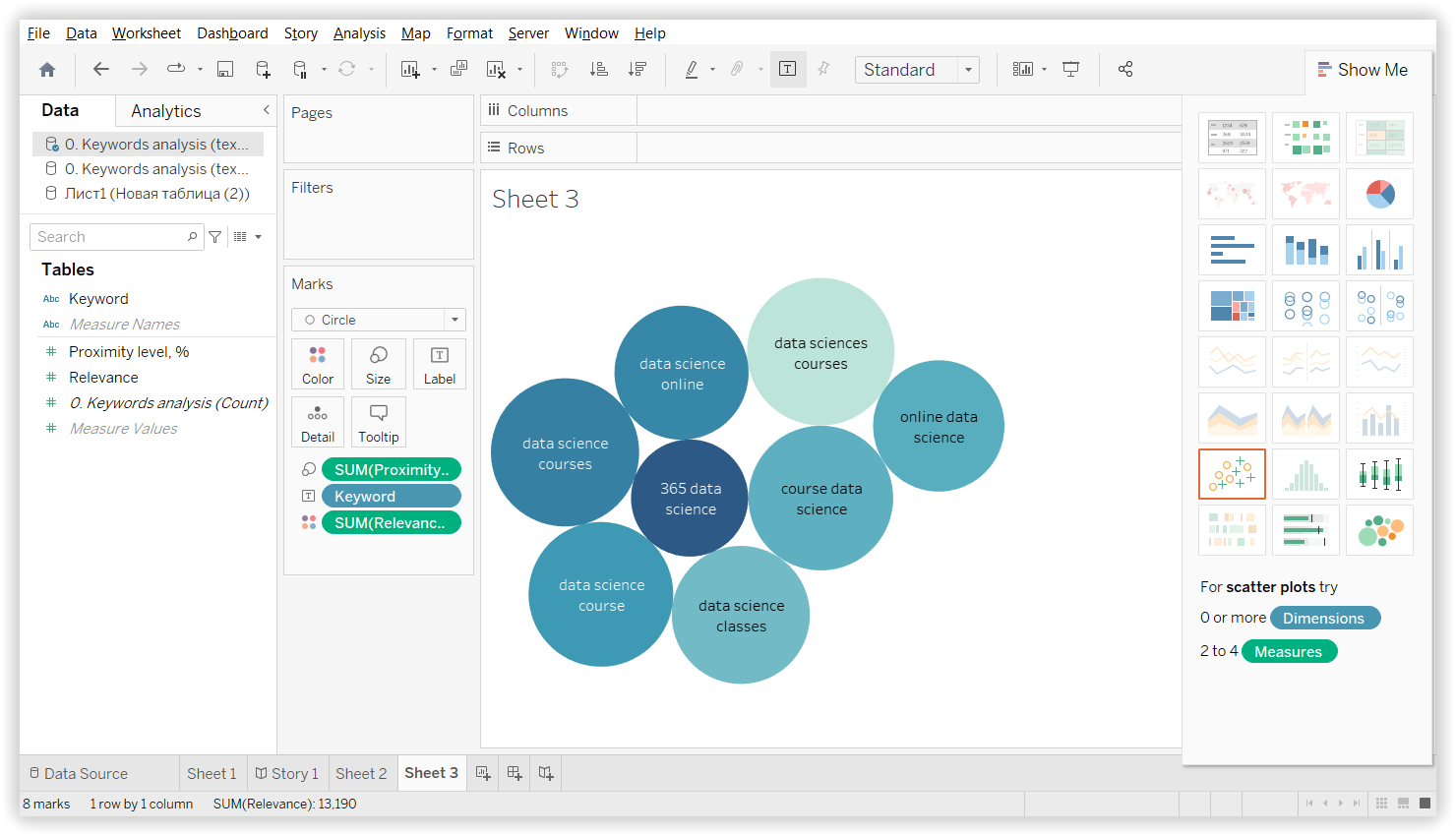
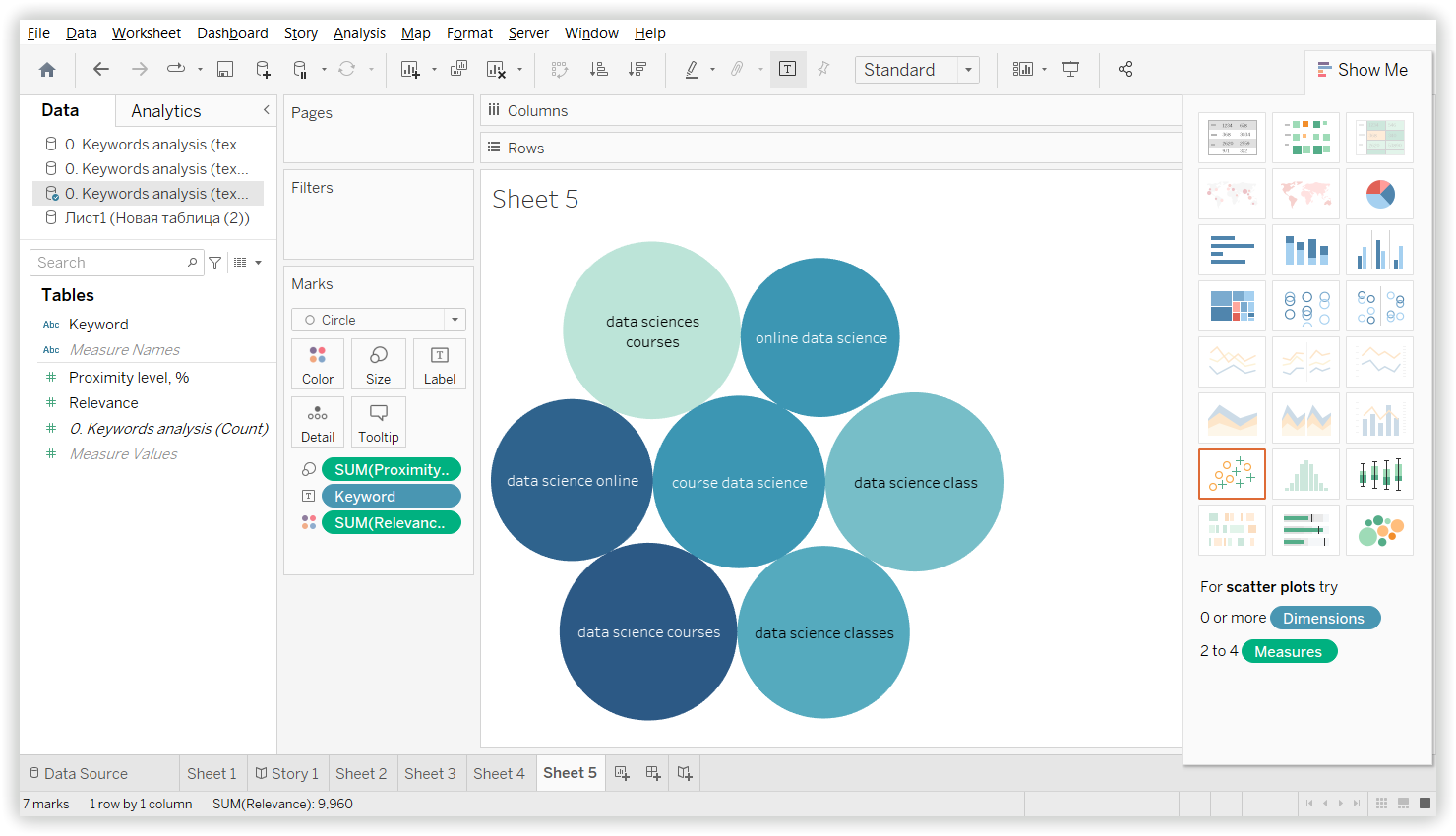
Результаты из всех платформ
Особенности модуля кластеризации Serpstat
Алгоритмы на основе поисковой выдачи предоставляют вам больше возможностей для кластеризации. С использованием общих URL-адресов в качестве параметров, этот процесс становится более прозрачным и понятным. Serpstat быстро объединяет ключевые слова в группы, анализирует уже опубликованный контент и создает группы ключевых слов, наиболее релевантные страницам сайта. Вы можете увидеть метатоп, используемый во время кластеризации и для подсчета основных характеристик кластера, нажав на соответствующую кнопку.
Целевые страницы в метатопе окрашены в зеленый цвет.
Целевые страницы в метатопе окрашены в зеленый цвет.
Таким образом, вы также можете отслеживать позицию анализируемой страницы в регионе. В отличии от многих других инструментов, Serpstat собирает данные для группировки внутри кластеризации, эти параметры подобны результатам Парсинга топа. Весь процесс проходит в фоновом режиме.
С помощью другого полезного инструмента, Текстовой аналитики, вы можете проверять ошибки на целевой странице. Если ошибка окрашена в серый цвет, это значит, что она обнаружена на целевой странице. Далее, узнать дополнительные детали, можно с помощью расширения Serpstat SEO Checker, а также Аудита одной страницы.
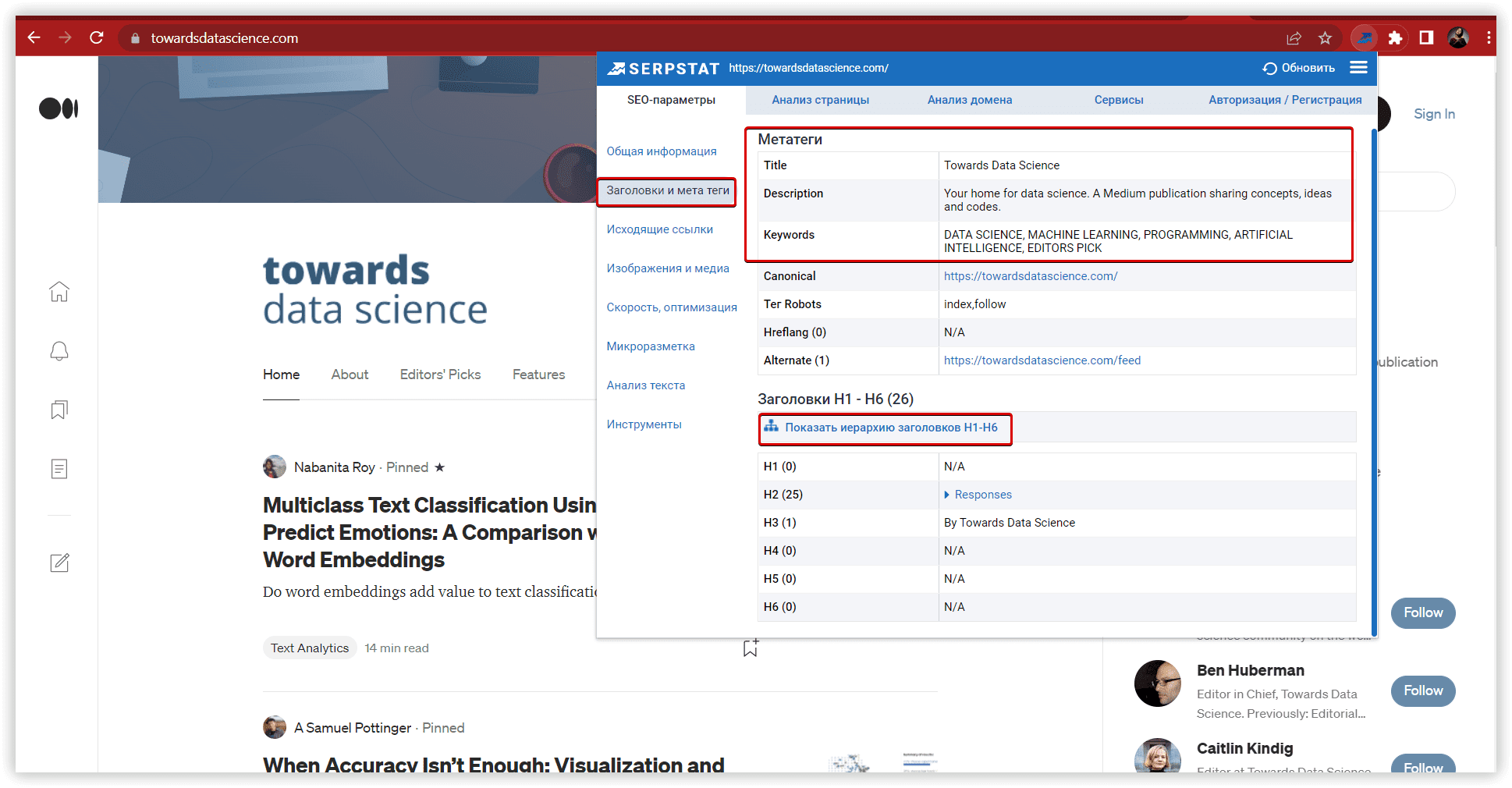
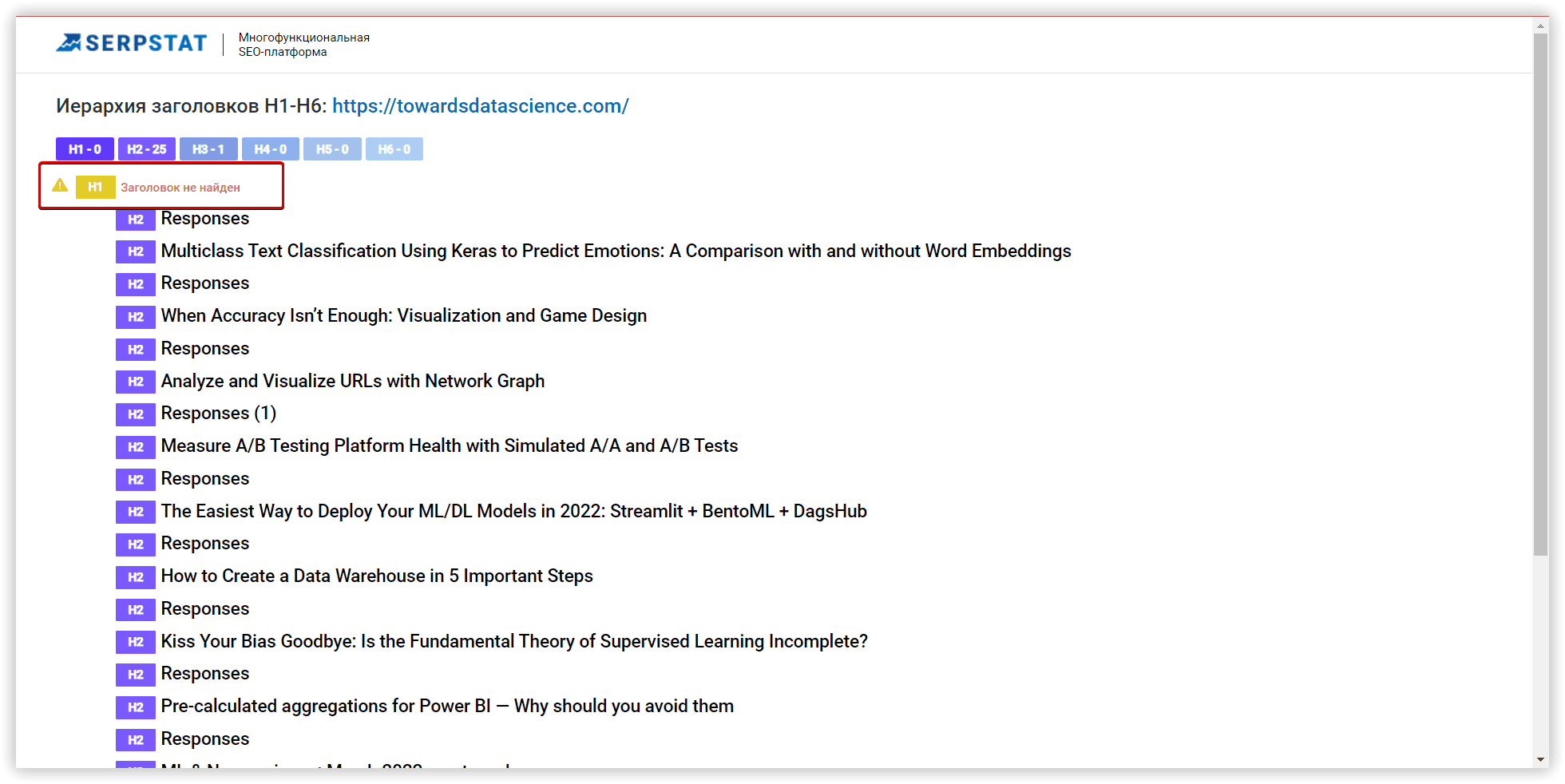
Увидеть избыточные или «упущенные» ключевые слова, можно на странице результатов ТА:
Практический кейс-исследование
Наглядный пример использования Serpstat для запуска нового сайта можно привести в качестве дополнительного эксперимента с кластеризацией. В ходе прохождения SEO-курсов от специалистов агентства Netpeak, мне удалось создать свой MVP — интернет-магазин по продаже тату-оборудования. Работая с кластеризацией Serpstat, чтобы создать структуру для будущего сайта, мне удалось продумать проект с нуля и прописать техническое задание для последующего контента в соответствии с целевыми страницами.
Какие задачи мне нужно было выполнить?
Составляя семантическое ядро, создать наиболее подходящую структуру для интернет-магазина тату-оборудования.
Следовать этой структуре, подбирая наиболее релевантные и высокочастотные запросы для лучшего ранжирования в Google US.
Следовать этой структуре, подбирая наиболее релевантные и высокочастотные запросы для лучшего ранжирования в Google US.
Как Serpstat помог в решении этих задач?
1
Составление семантического ядра началось с исследования ключевых фраз по тематике сайта в Serpstat, анализа доменов-конкурентов и сбора основных данных по ключам. Нужно было найти бенчмарк-примеры в тату-бизнесе и собрать семантику таких сайтов.
2
Далее, указав в качестве региона Google US/Калифорния, я указала желаемую силу связи и тип кластеризации Сильная/Жесткий.
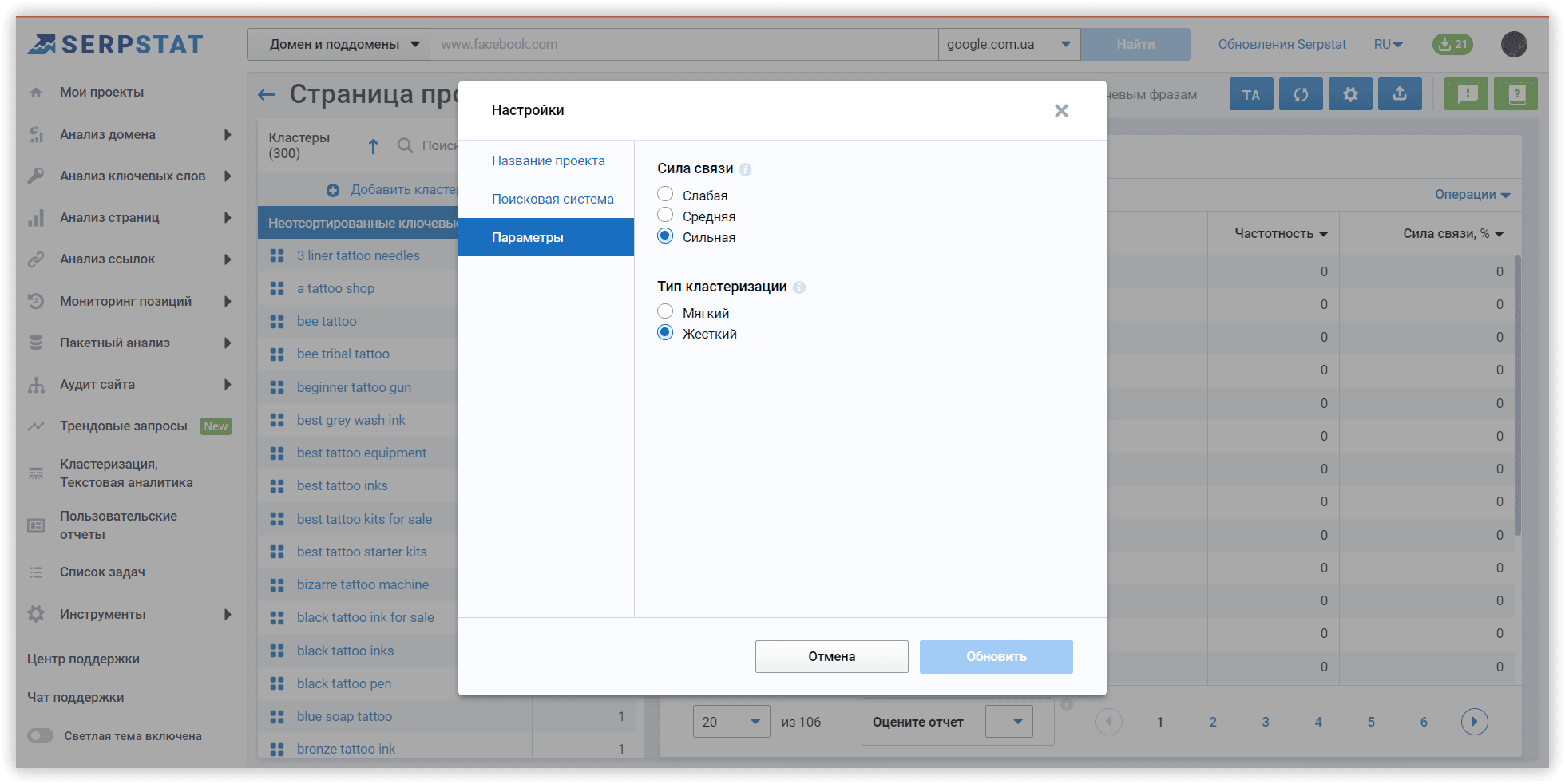
3
После экспорта результатов кластеризации, работы с фильтрацией и сортировкой, удалось получить прототип структуры моего будущего сайта:
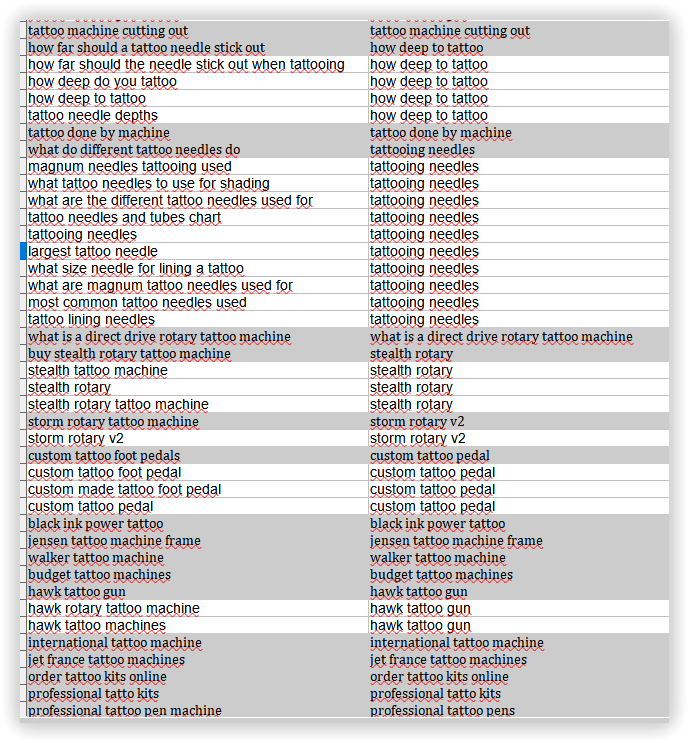
4
Дальше — создание схематической карты сайта.
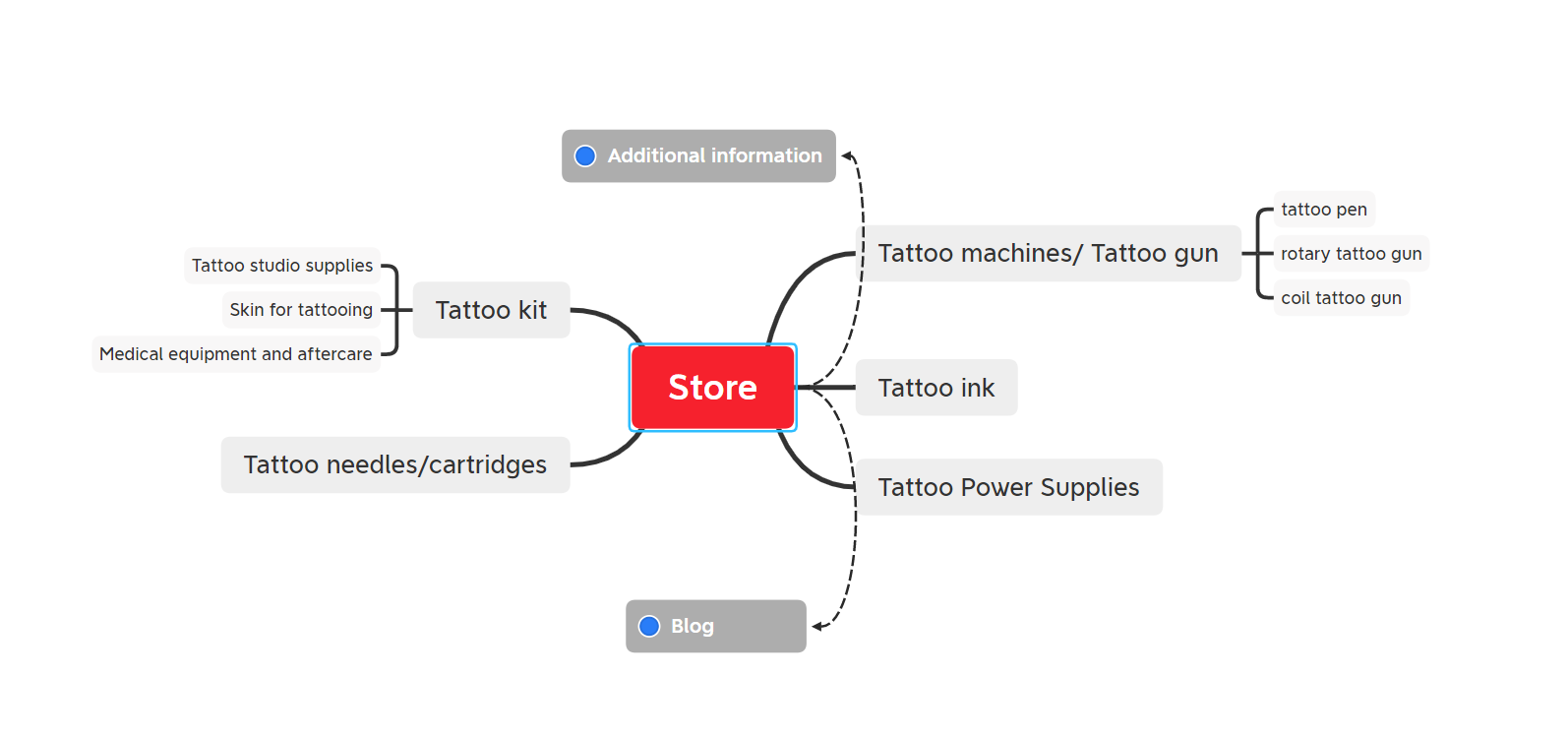
5
После этого этапа, нужно было приступить к написанию технического задания.

6
Категории и контент были созданы, а сайт открыт для индексации, чтобы помочь Serpstat распределить ключи для кластеров, распределить их на существующих страницах, проверить релевантность в текстовой аналитике, а также, чтобы поработать с Google Analytics и Tag Manager.

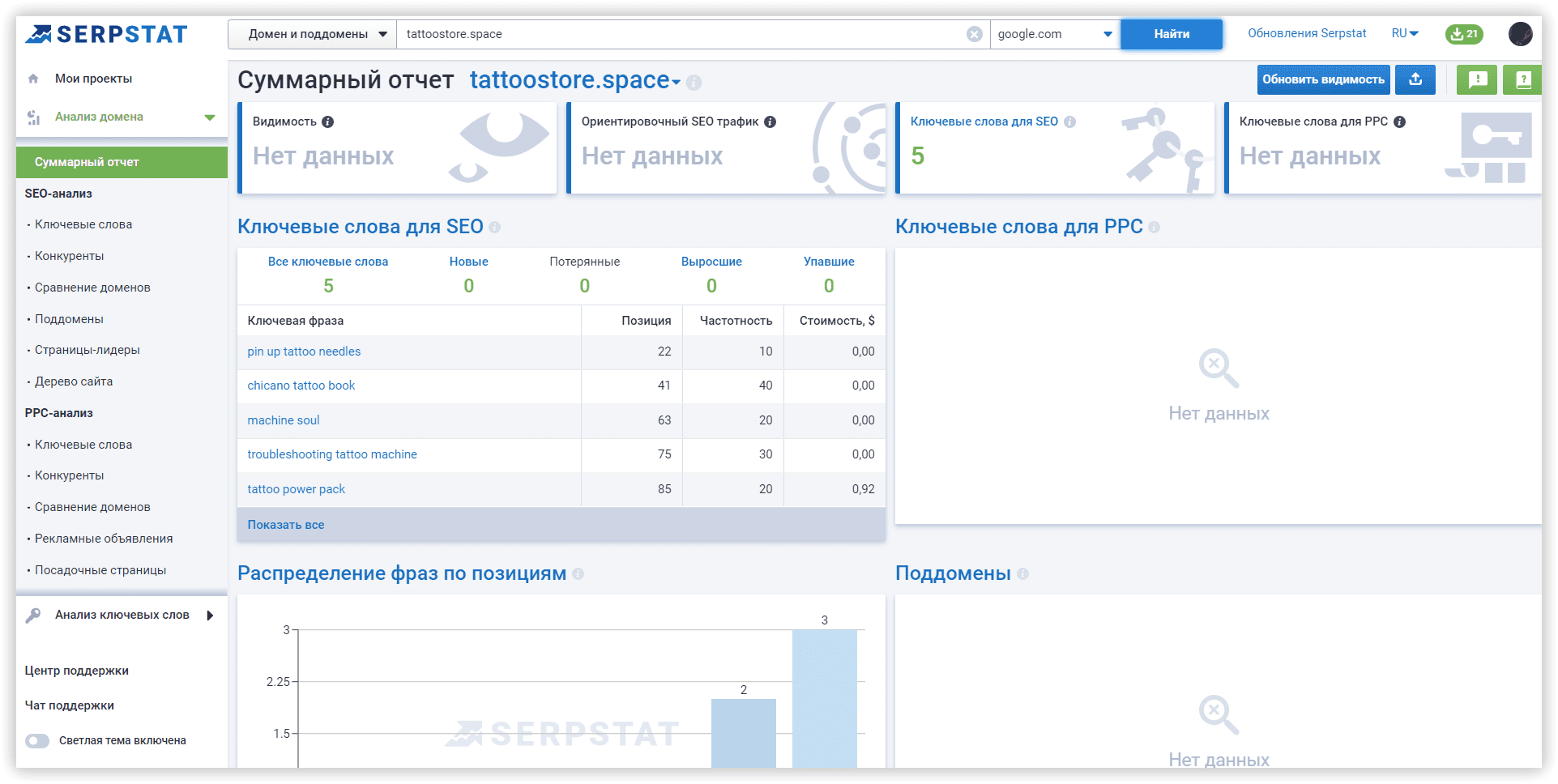
Полученные результаты
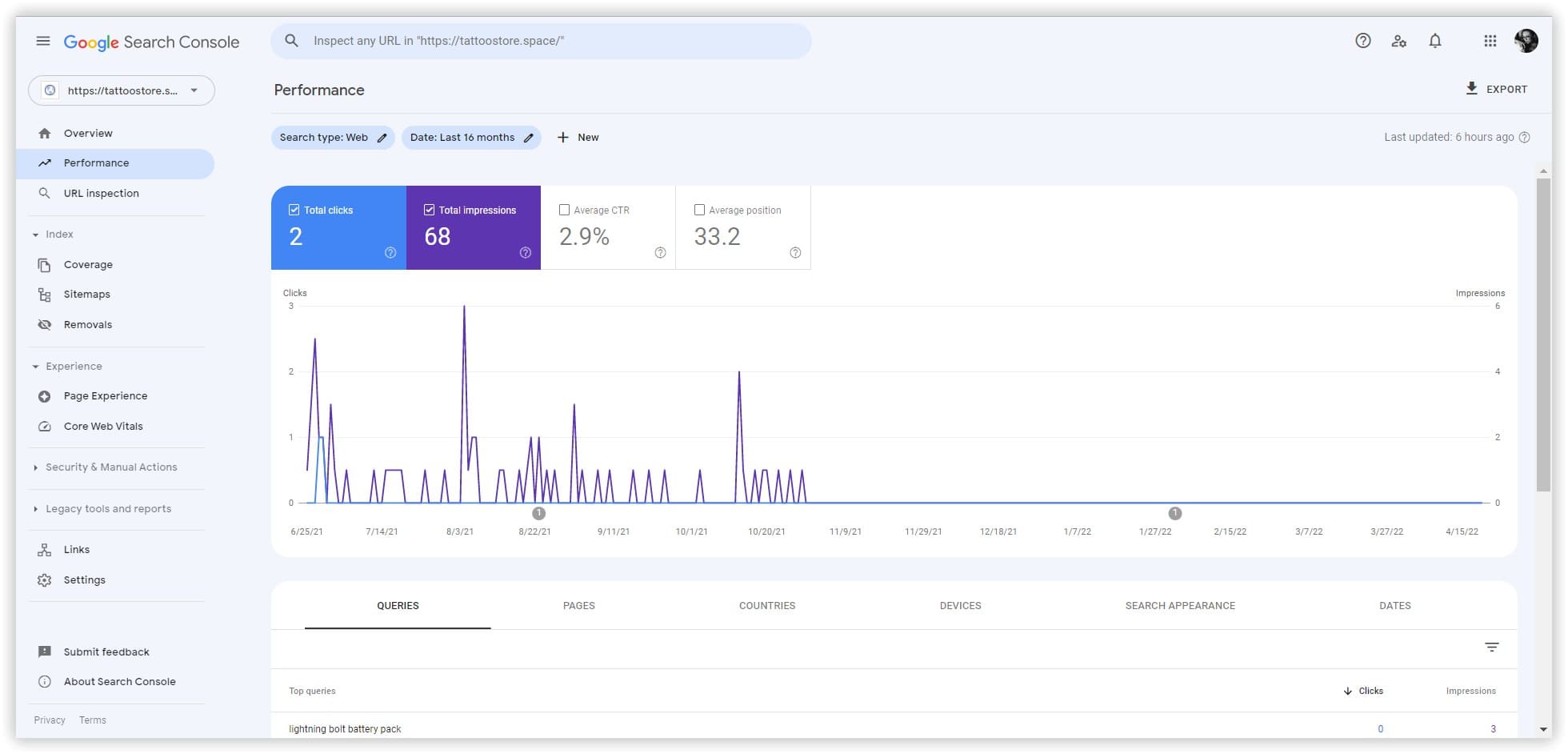
Через неделю мой сайт отображался в Анализе домена Serpstat по 5 ключевым словам с 22 до 85 позиций Google US. Я получила ожидаемый результат за счет такого прототипирования и быстрой автоматической кластеризации.
Выводы
Когда вы проводите кластеризацию для своих целевых страниц, вы показываете Google, что ваш веб-сайт достаточно содержателен для определенной ниши, демонстрируете широту и глубину содержания. Вы даете поисковым системам сигналы о группах контента, что помогает идентифицировать и продвигать эти страницы в результатах поиска, задействовав логику алгоритмов поисковых систем.
Кластеризация помогает сделать сайт более удобным для пользователей, лучше ранжироваться по ключевым запросам разного типа, приумножать органический трафик за счет полезного и структурированного контента, организовывать внутреннюю перелинковку эффективней, и проще расширять семантику в определенной нише.
Кластеризация ключевых фраз — это самый простой способ оптимизировать одну страницу под нескольких ключевых запросов, объединенных поисковым интентом. С помощью Serpstat вы можете сгруппировать до 50 тысяч ключевых слов, быстро и просто разработать точное семантическое ядро сайта.
С помощью кластеризации, можно оптимизировать контент, ориентированный на десятки похожих и связанных ключевых слов, что поможет ранжироваться по целой группе запросов и организовать структуру сайта в соответствии с алгоритмами Google. Группировка ключей по поисковой выдаче, основана на совпадении целей поиска и работает благодаря алгоритмам машинного обучения.
Текстовая аналитика Serpstat поможет повысить релевантность контента, сгенерированного по кластерам, и учесть ТОП-15 выдачи поисковой системы в определенном регионе.
В этой статье мы рассмотрели значение кластеризации в контексте машинного обучения и сравнили результаты работы различных алгоритмов и подходов к разбивке семантического ядра, чтобы проверить релевантность каждого созданного кластера. Результаты свидетельствуют о том, что автоматизированная кластеризация на основе поисковой выдачи является более эффективной и простой в использовании, а также полагается на алгоритмы Google и способна улучшаться в связи с постоянными апдейтами поисковиков.
Кластеризация помогает думать масштабней о содержании сайта и адаптироваться к будущим условиям поисковой оптимизации.
Кластеризация помогает сделать сайт более удобным для пользователей, лучше ранжироваться по ключевым запросам разного типа, приумножать органический трафик за счет полезного и структурированного контента, организовывать внутреннюю перелинковку эффективней, и проще расширять семантику в определенной нише.
Кластеризация ключевых фраз — это самый простой способ оптимизировать одну страницу под нескольких ключевых запросов, объединенных поисковым интентом. С помощью Serpstat вы можете сгруппировать до 50 тысяч ключевых слов, быстро и просто разработать точное семантическое ядро сайта.
С помощью кластеризации, можно оптимизировать контент, ориентированный на десятки похожих и связанных ключевых слов, что поможет ранжироваться по целой группе запросов и организовать структуру сайта в соответствии с алгоритмами Google. Группировка ключей по поисковой выдаче, основана на совпадении целей поиска и работает благодаря алгоритмам машинного обучения.
Текстовая аналитика Serpstat поможет повысить релевантность контента, сгенерированного по кластерам, и учесть ТОП-15 выдачи поисковой системы в определенном регионе.
В этой статье мы рассмотрели значение кластеризации в контексте машинного обучения и сравнили результаты работы различных алгоритмов и подходов к разбивке семантического ядра, чтобы проверить релевантность каждого созданного кластера. Результаты свидетельствуют о том, что автоматизированная кластеризация на основе поисковой выдачи является более эффективной и простой в использовании, а также полагается на алгоритмы Google и способна улучшаться в связи с постоянными апдейтами поисковиков.
Кластеризация помогает думать масштабней о содержании сайта и адаптироваться к будущим условиям поисковой оптимизации.
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.