Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как собрать семантическое ядро, чтобы полностью охватить тематику


В данной статье я поэтапно расскажу о том, как быстро собрать семантическое ядро для сайта, кластеризовать его и расширить структуру сайта, используя комплекс инструментов. Поехали!
Содержание:
Ядро состоит из ключевых фраз, по которым пользователь находит определенную страницу сайта в зависимости от своего запроса. На основании семантики составляется структура сайта, прописываются метатеги и основные заголовки страниц.
Каким должен быть размер семантического ядра
Размер ядра напрямую зависит от типа сайта, его тематики и не определяется количеством существующих страниц. Структура сайта определяется исключительно после того, как будет завершен сбор семантического ядра.
Но как понять, сколько запросов может быть на вашем сайте, если он был недавно создан? Вам поможет сбор семантики конкурентов. Проанализируйте ключевые фразы конкурентов в топе поисковиков. У вас должно быть не меньше. Но копировать в точности чужую семантику не следует.
Как сформировать первичную
структуру сайта
структуру сайта
Маркерные запросы или маркеры — это ключевые фразы, которые определяют тематику ниши. Они должны четко отвечать тематике страницы (1 маркер — 1 страница). Зачастую маркерными запросами являются категории, разделы и рубрики на сайте. Отталкиваясь от маркерных запросов, можно расширять семантику.
Первичную структуру можно подготовить как для уже существующего сайта, так и для проекта в разработке. Но тут есть пара нюансов.
Для сайта, который еще в разработке:
Для уже существующего сайта:

- москитные сетки;
- спирали от комаров;
- мухобойки;
- липкие ленты;
- ловушки;
- палочки от комаров;
- липкие листы.

Также при разработке первичной структуры, помимо категорий, учитываем типы и значения фильтров. Чем подробнее будет структура, тем проще и быстрее будет ее расширить.
Как определить прямых конкурентов
Как найти конкурентов вручную
Пробейте каждый запрос в поисковой системе и посмотрите, кто находится в выдаче по тем же фразам. Важно помнить, что поисковики часто персонализируют поиск и формируют SERP (страницу выдачи) на основе ваших прошлых запросов. Поэтому для большей точности используйте режим «Инкогнито»: в Google Chrome или Opera — комбинация клавиш Ctrl+Shift+N, в Mozilla — Ctrl+Shift+P.
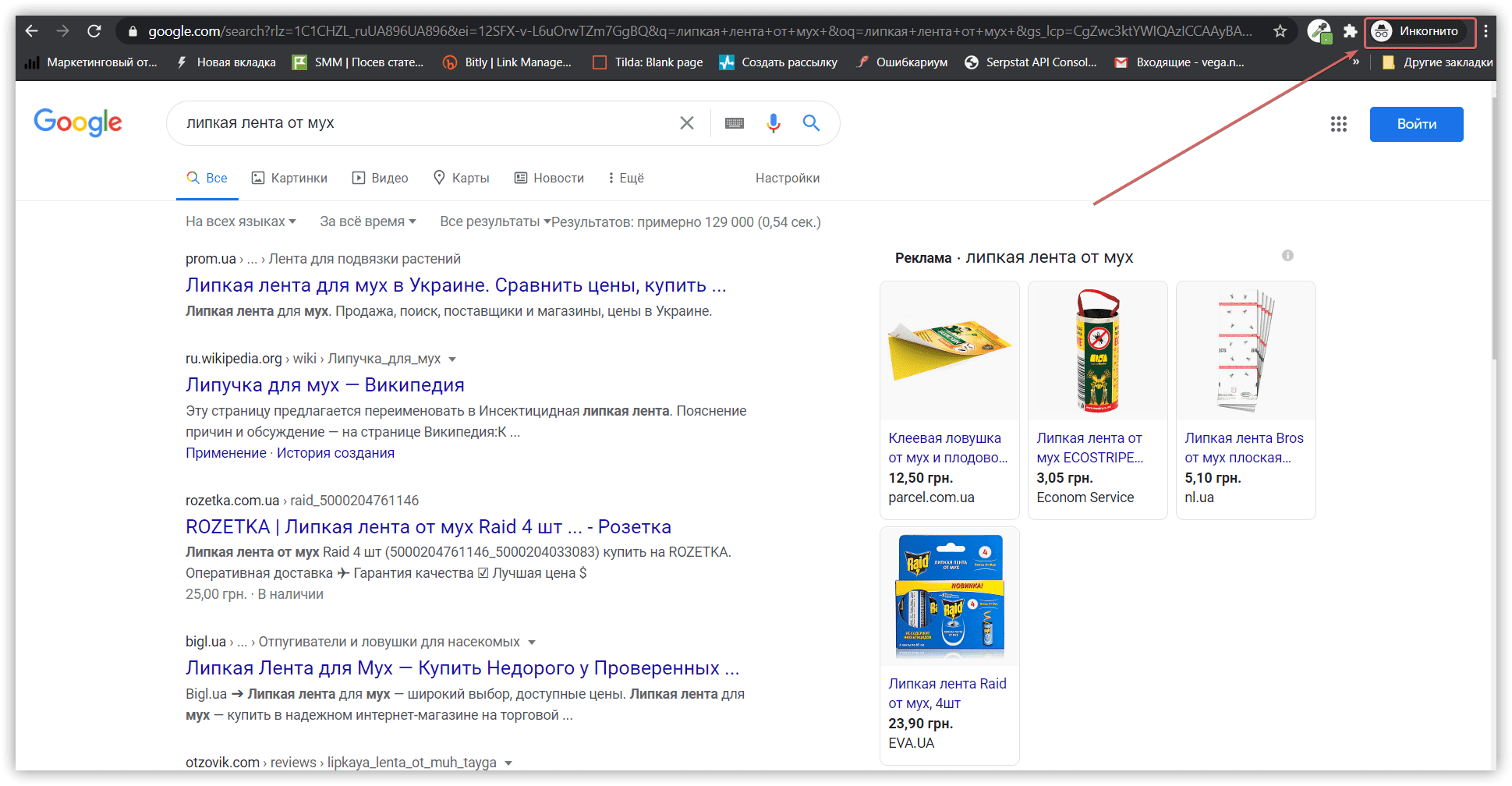
Создайте таблицу и внесите в нее сайты, которые ранжируются по нужным ключевикам. Вы получите общую картину по вашей нише и узнаете ближайших конкурентов. После чего можно начинать анализ.
Просмотрев выдачу по всем ключевым фразам. Так вы соберете базу основных конкурентов и сможете продумать план дальнейших действий.
Однако поиск конкурентов вручную имеет ряд недостатков, которые следует учитывать:
Как определить конкурентов с помощью Serpstat
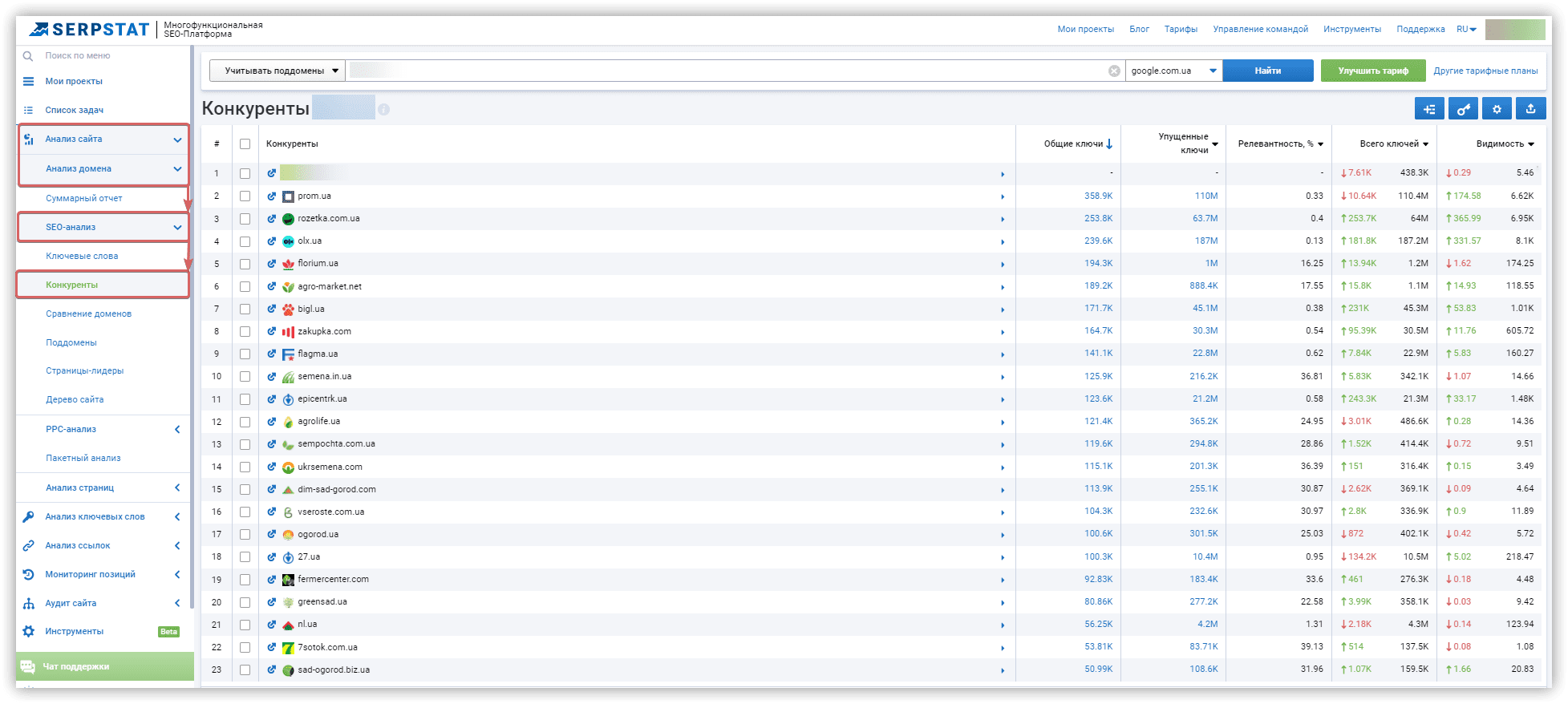
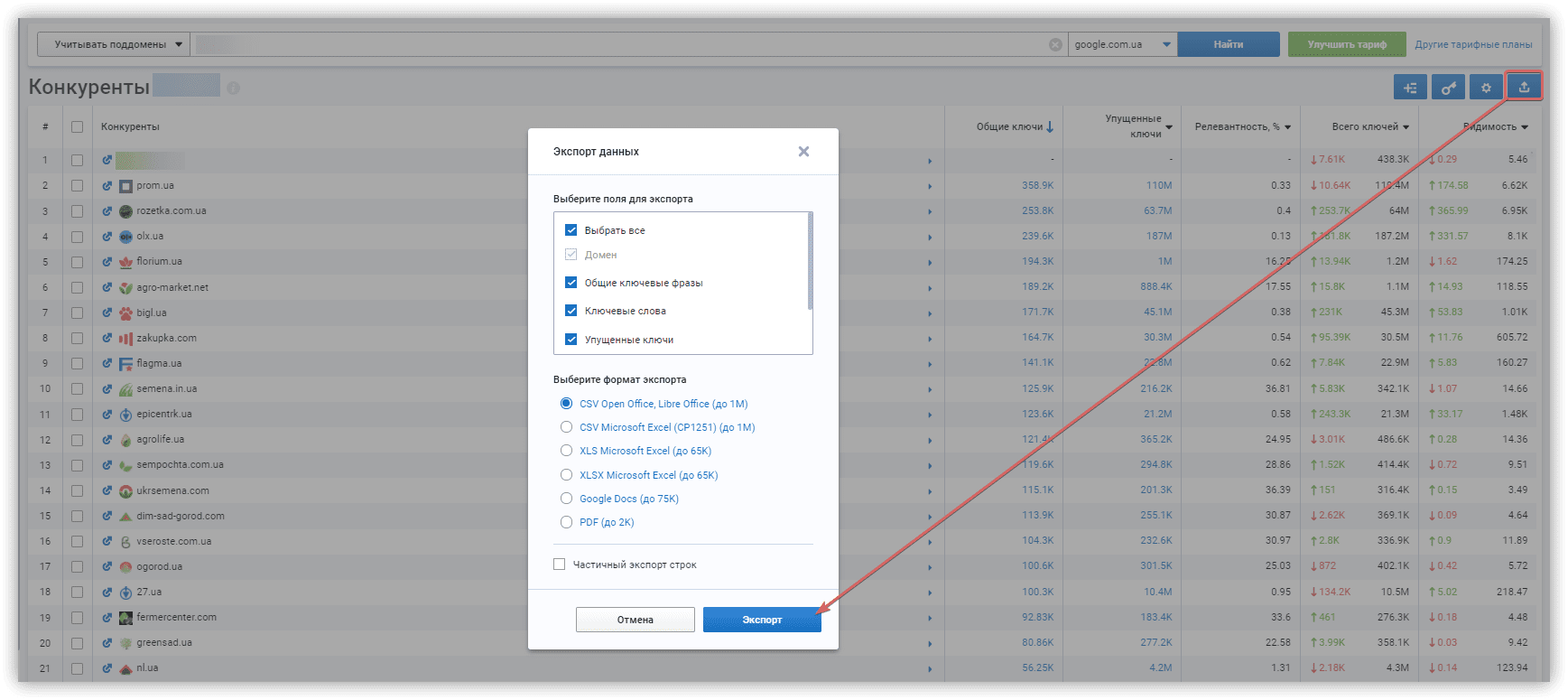
Чтобы получить полный список релевантных конкурентов, перейдите в раздел «Анализ сайта → Анализ доменов → SEO-анализ → Конкуренты».
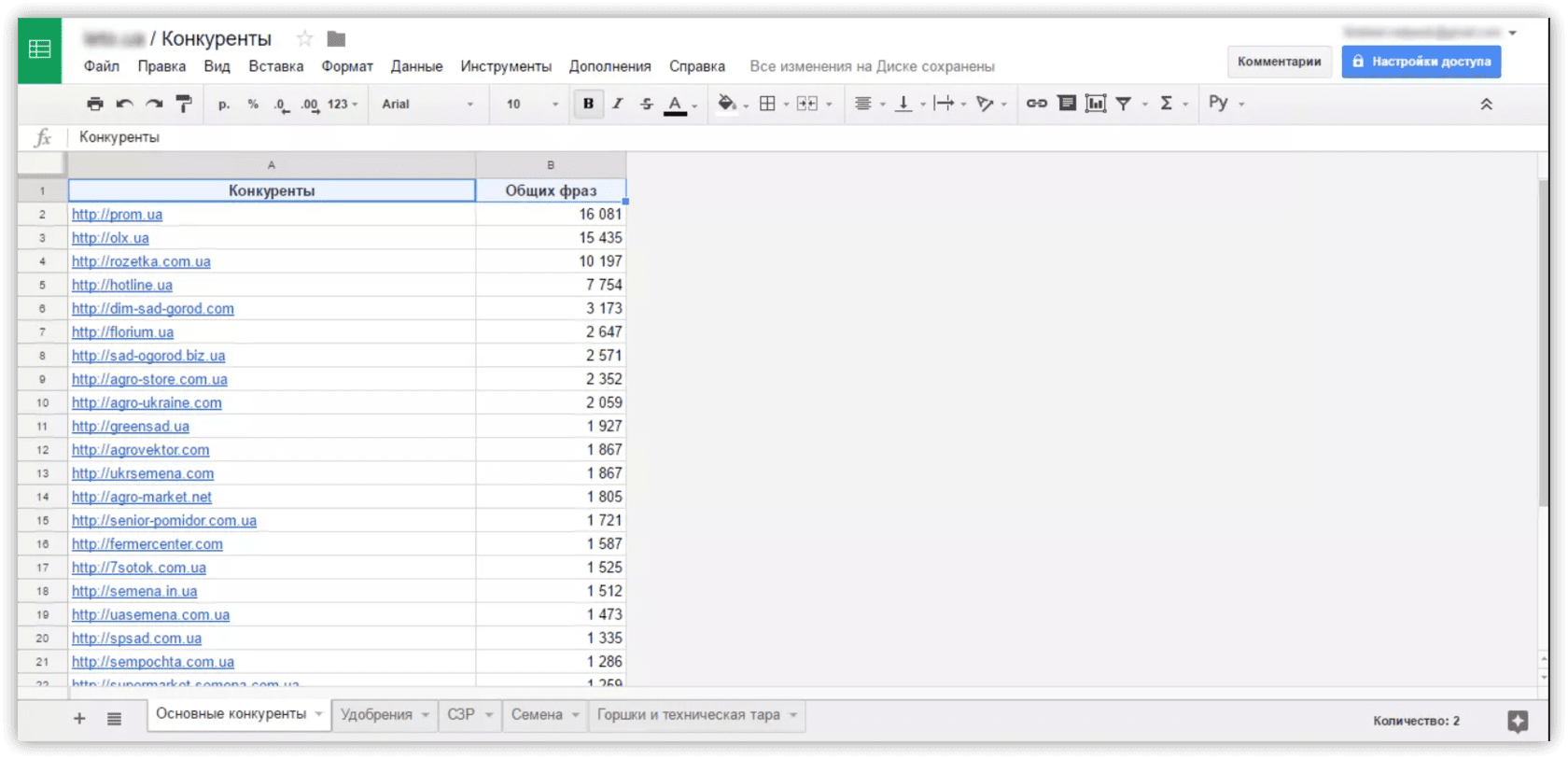
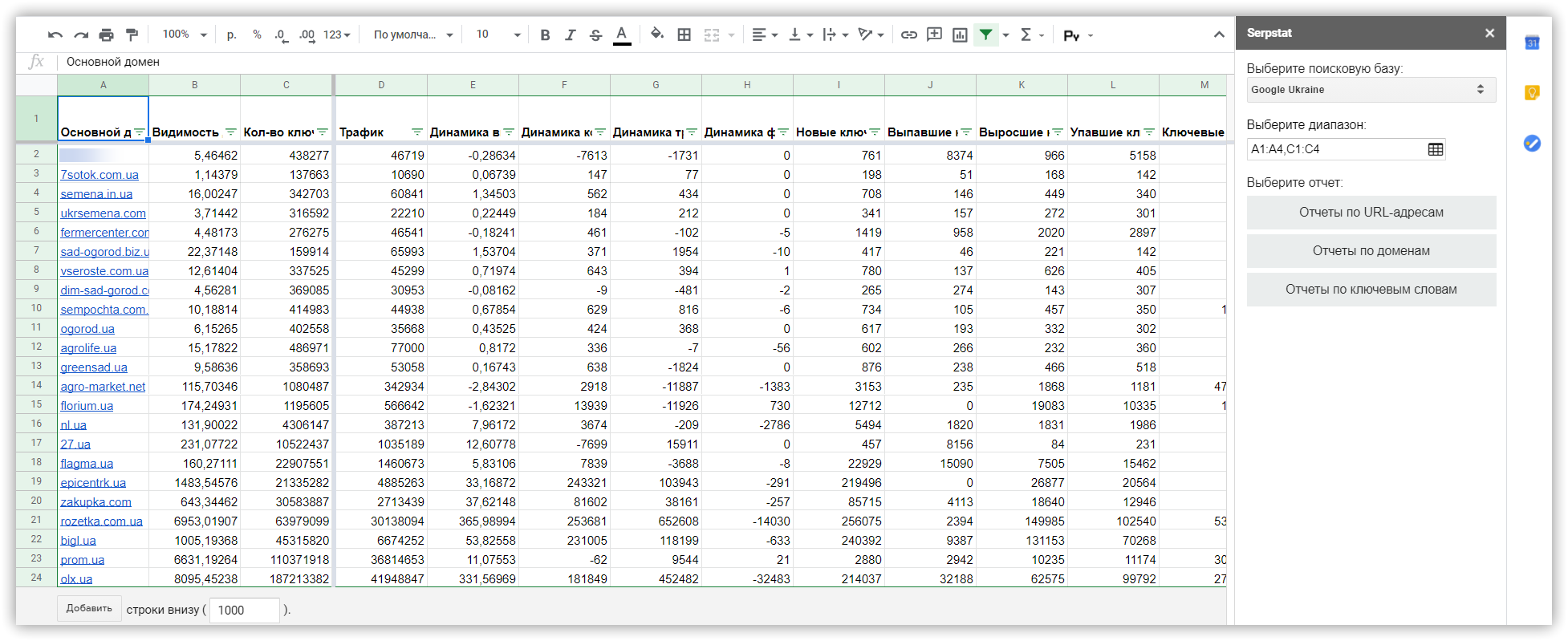
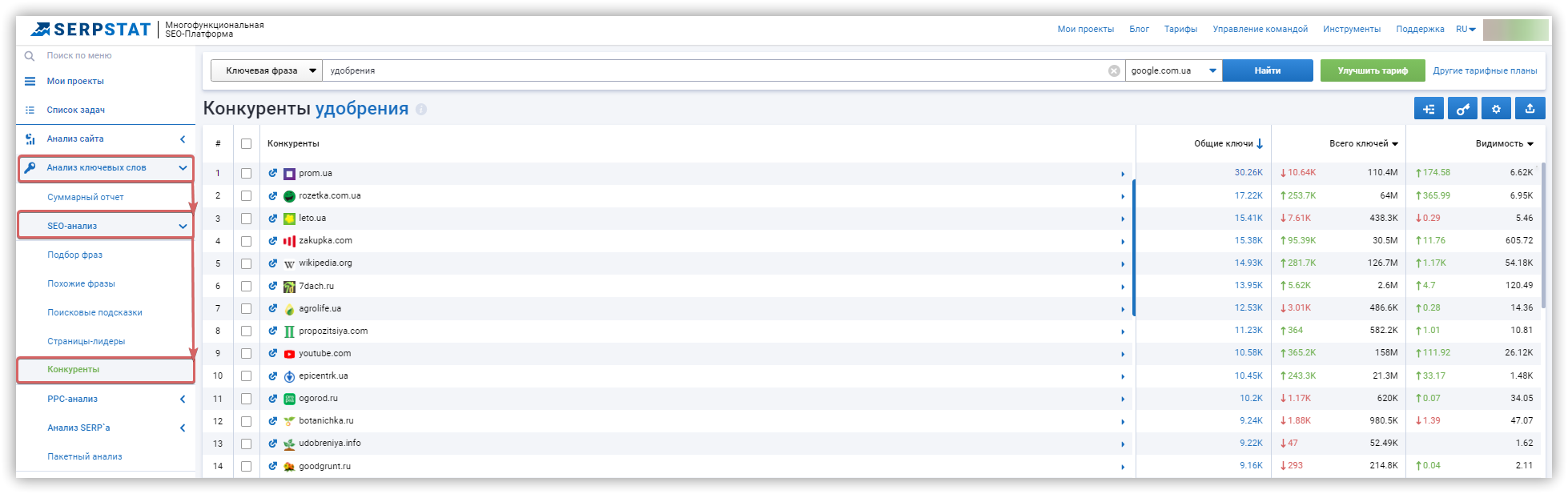
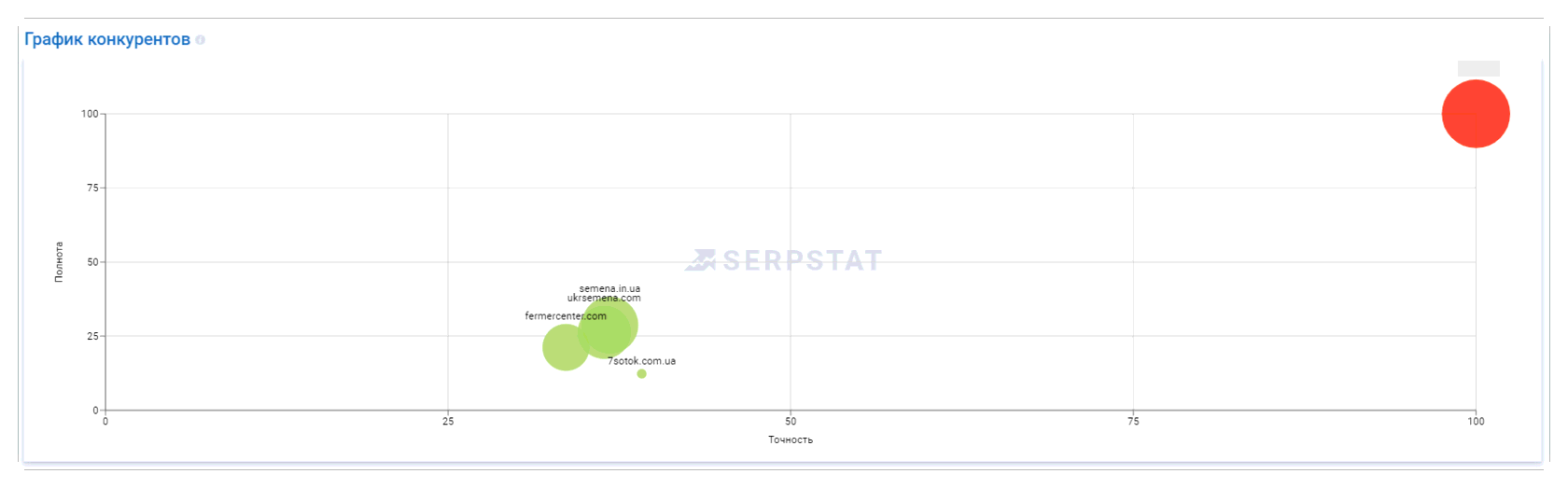
Анализ структуры сайтов-конкурентов
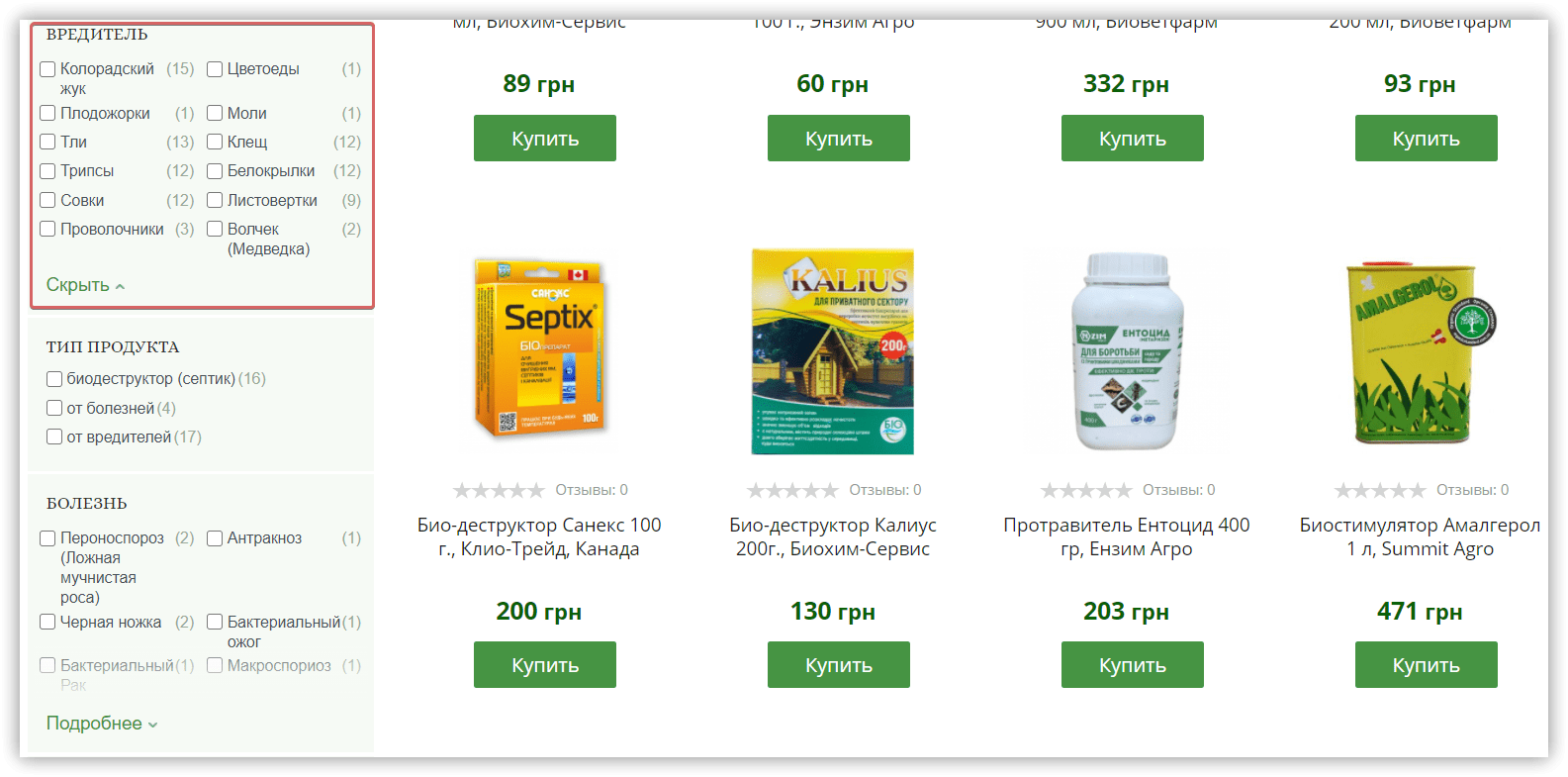
Например, у одного из конкурентов мы нашли интересные фильтры в категории «Инсектициды»:
- вредитель;
- болезнь.
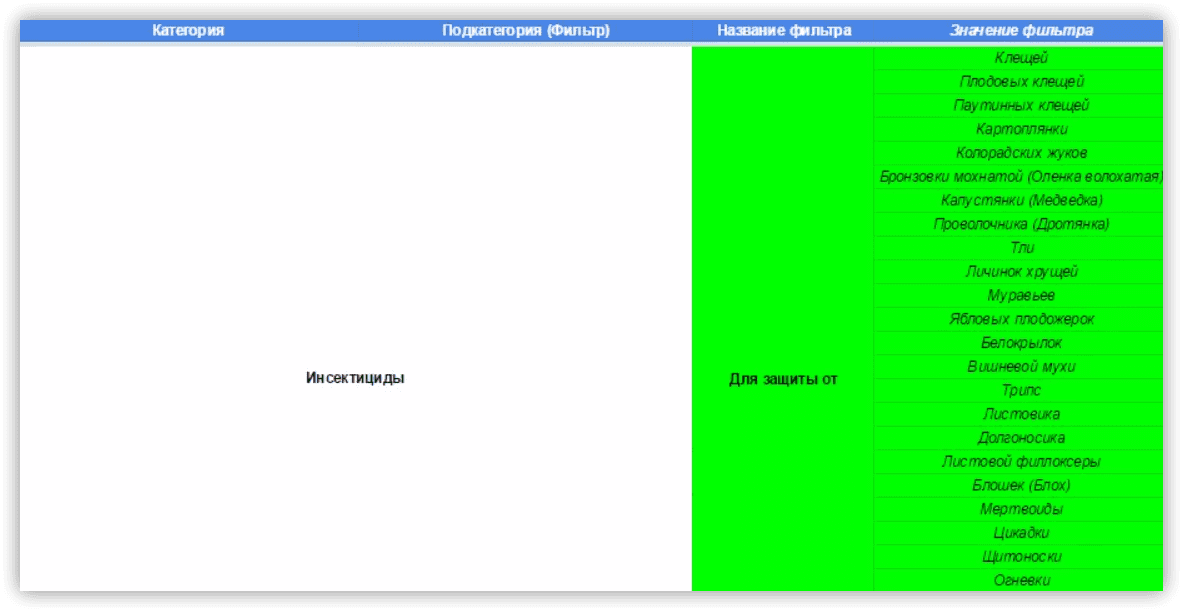
Как собрать семантическое ядро
Под каждую категорию собираем маркерные ключевые фразы в соответствии с названием категории. Отталкивая от этого, расширяем семантику с помощью синонимов.
Чтобы собрать синонимы, используем такие сервисы:
- Serpstat
- API Консоль и дополнение для Google таблиц
- Планировщик ключевых слов Google Рекламы
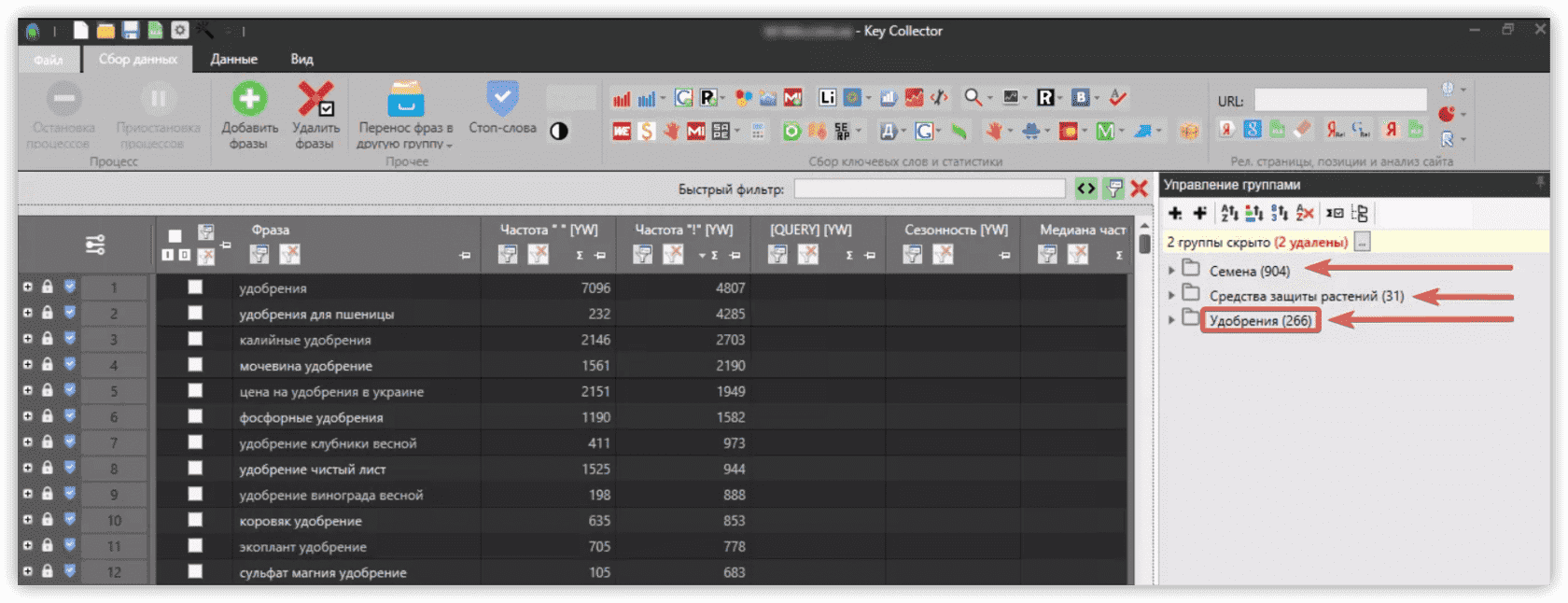
Формирование базовых запросов
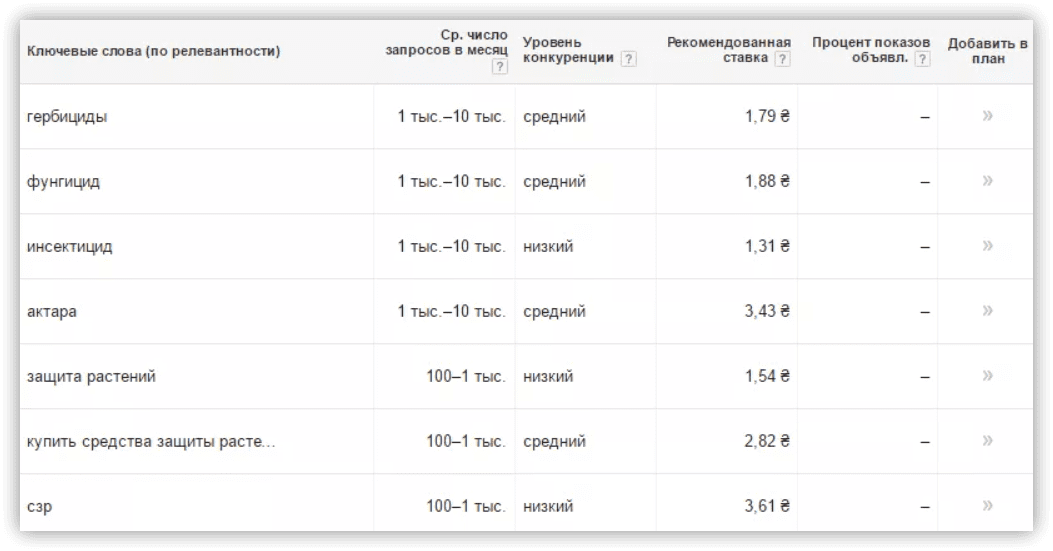
- препараты защиты растений;
- средства для защиты растений.
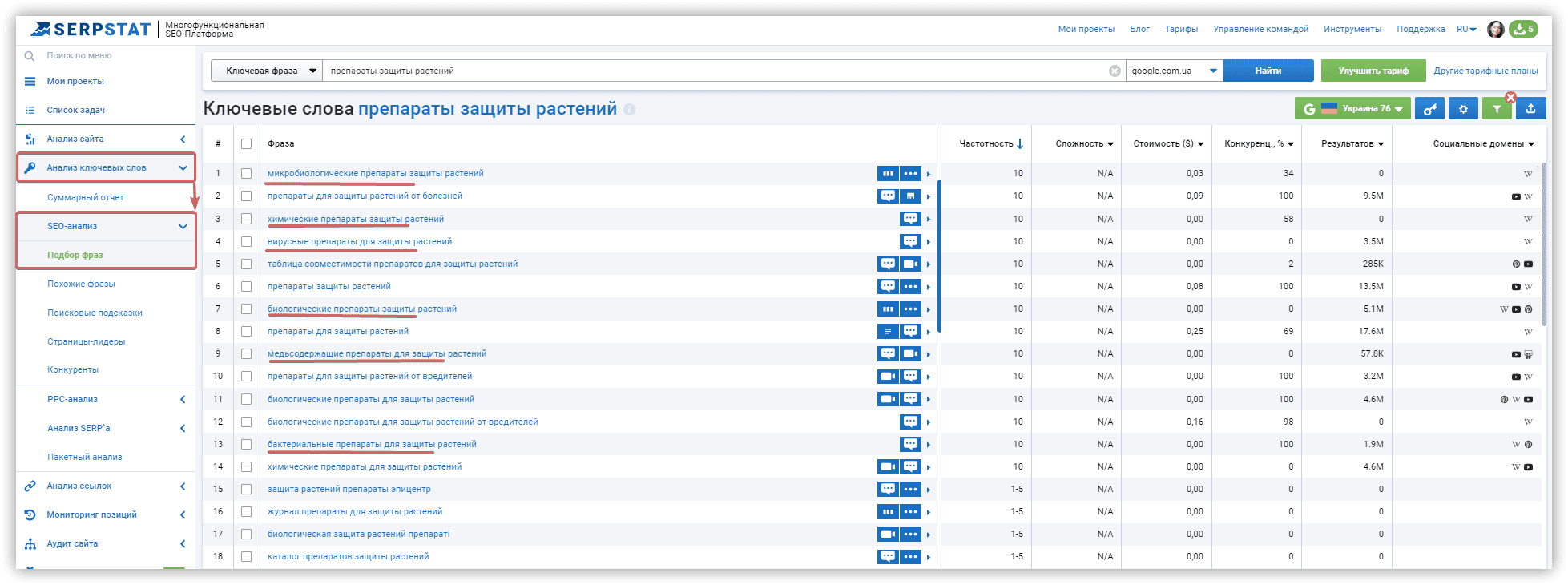
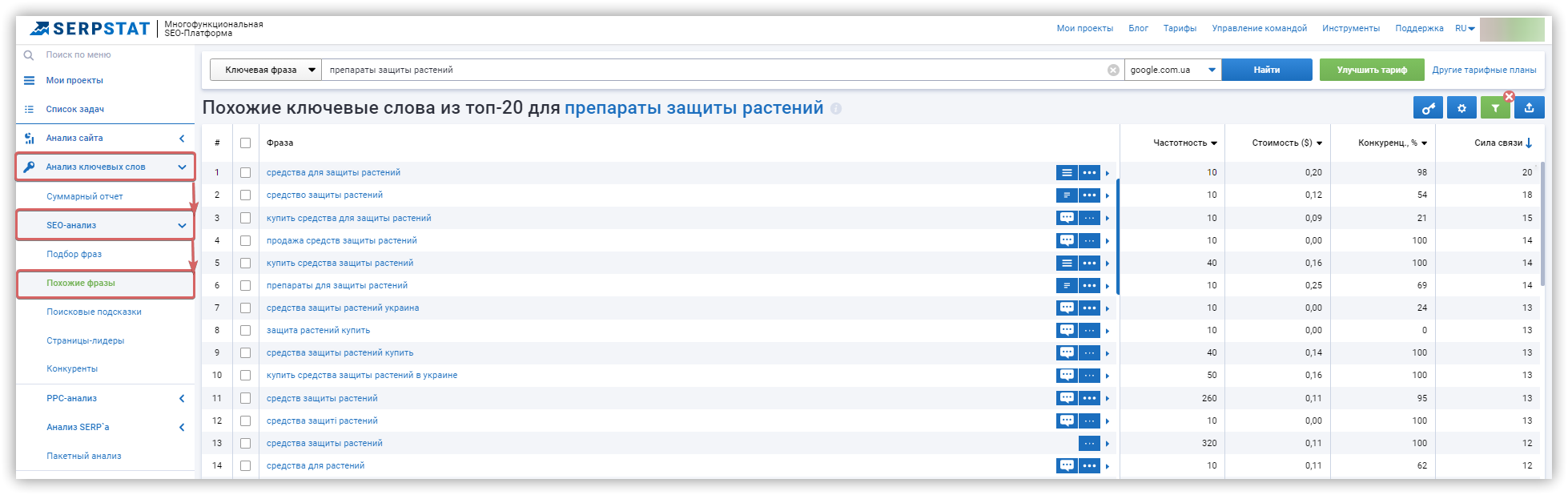
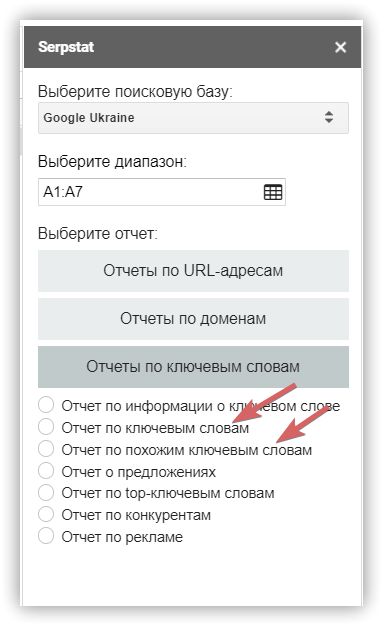
Поиск синонимов через дополнительные сервисы
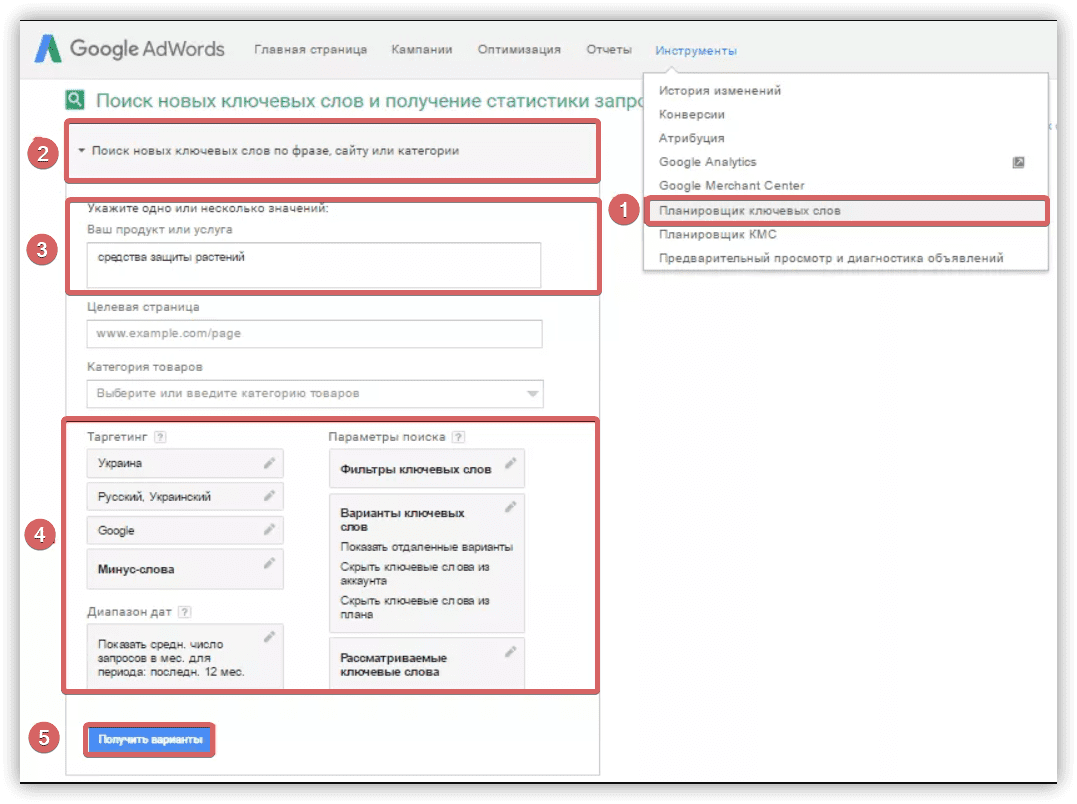
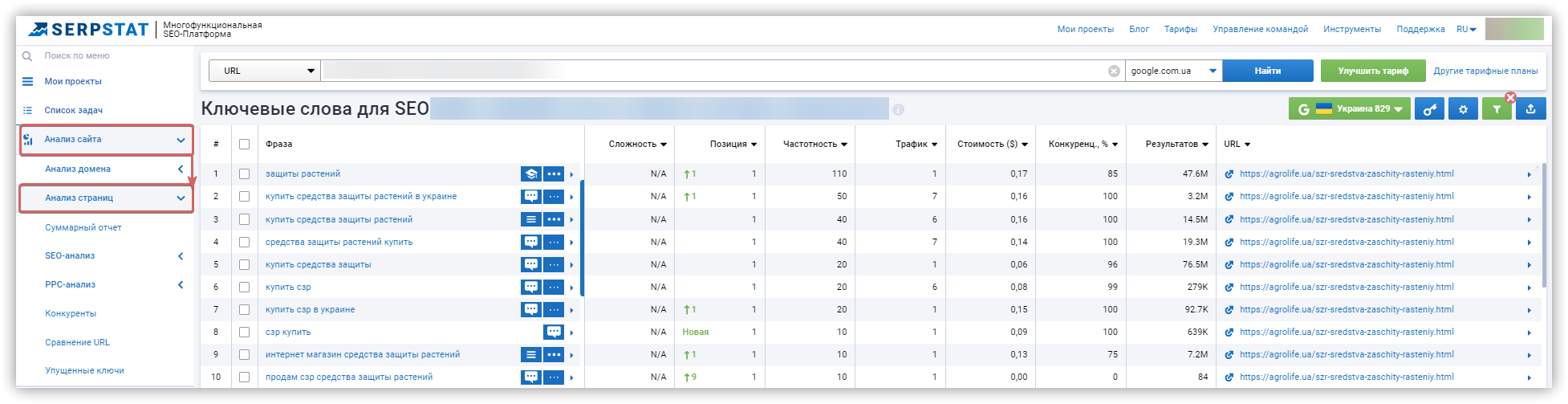
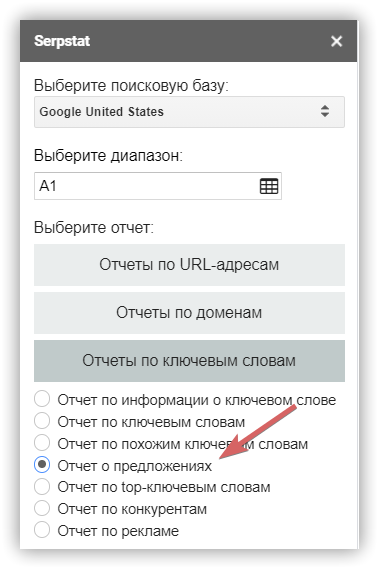
Сбор поисковых запросов через разные источники
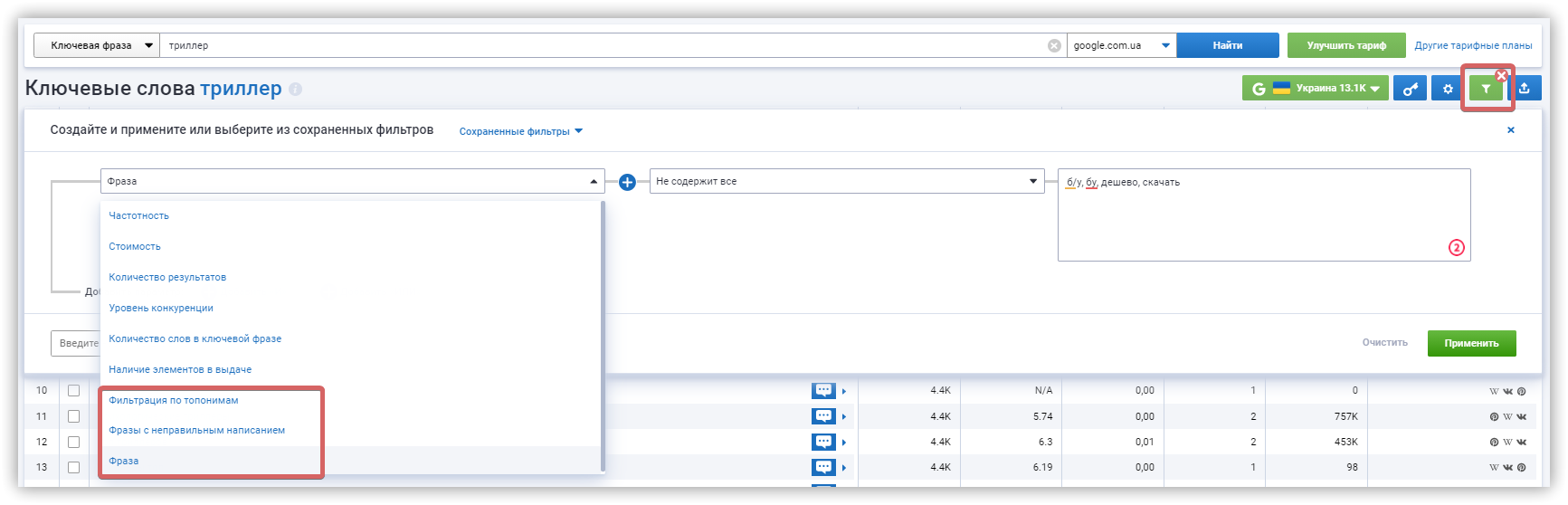
Сбор стоп-слов
В список стоп-слов включаем:
- Приставки, характеризующие информационные запросы: что, это, как, фото, видео, смотреть, своими руками и т.д.
- Топонимы, не соответствующие вашим целям.
- Фразы, предполагающие бесплатное получение: дешево, недорого, бесплатно, скачать и т.д.
- Названия популярных сайтов и брендов: розетка, olx, шафа.
- Субъективные понятия: самый качественный/ лучший и т.д.
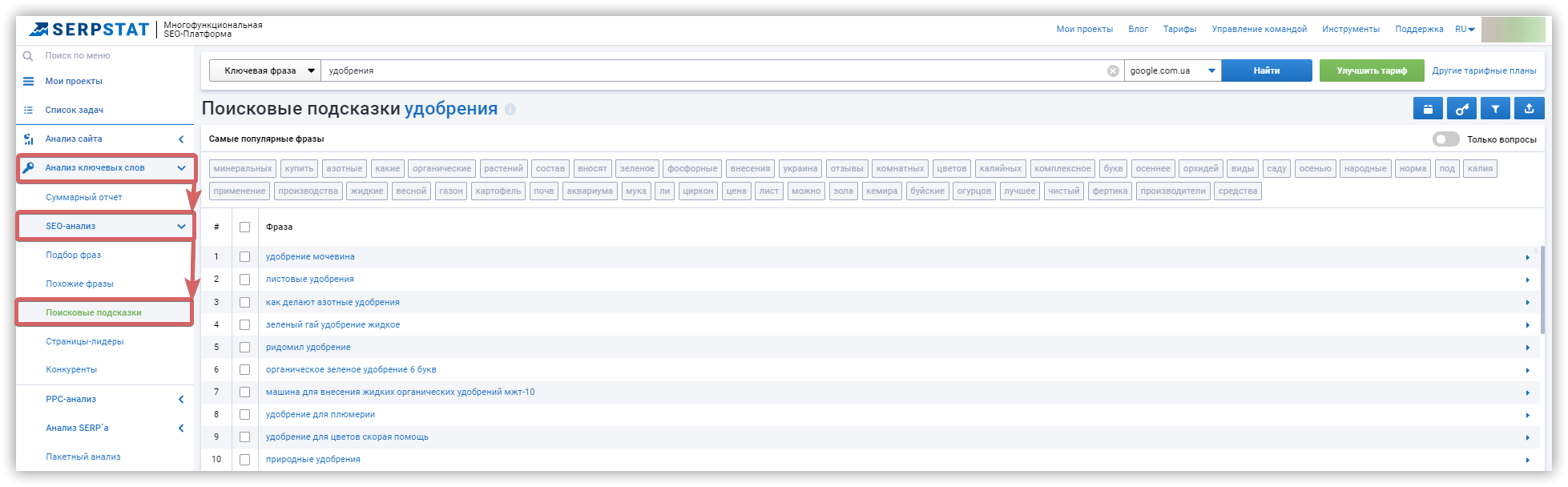
Сбор поисковых подсказок
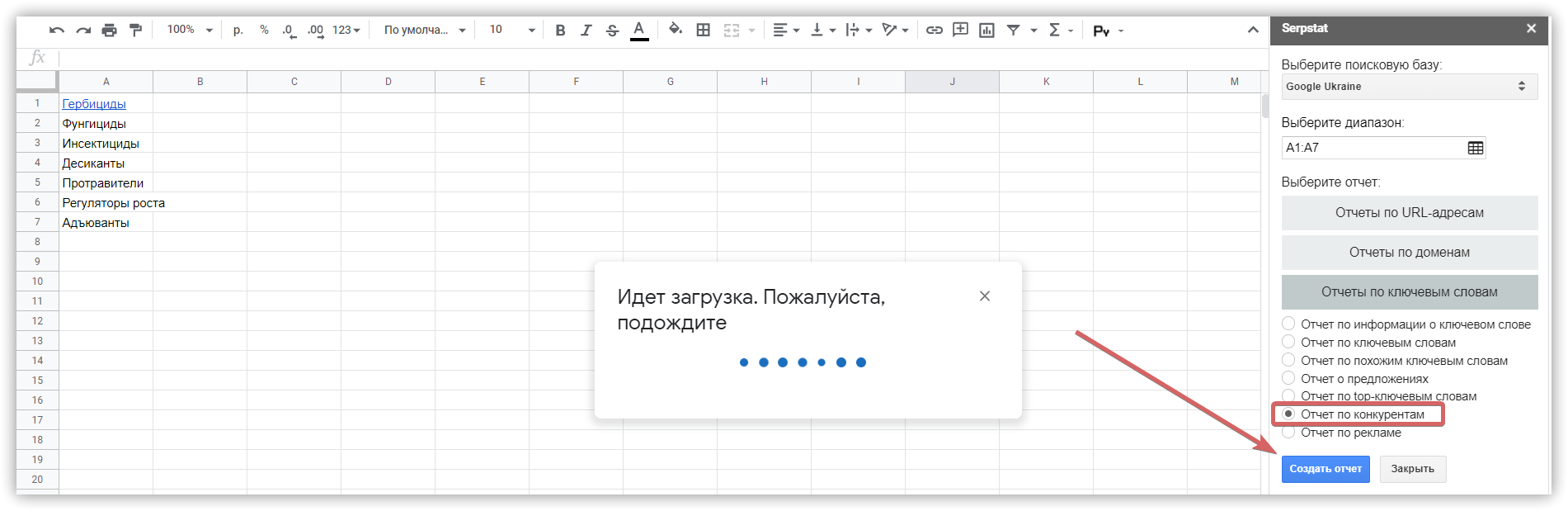
Собрать подсказки в Serpstat можно двумя способами.
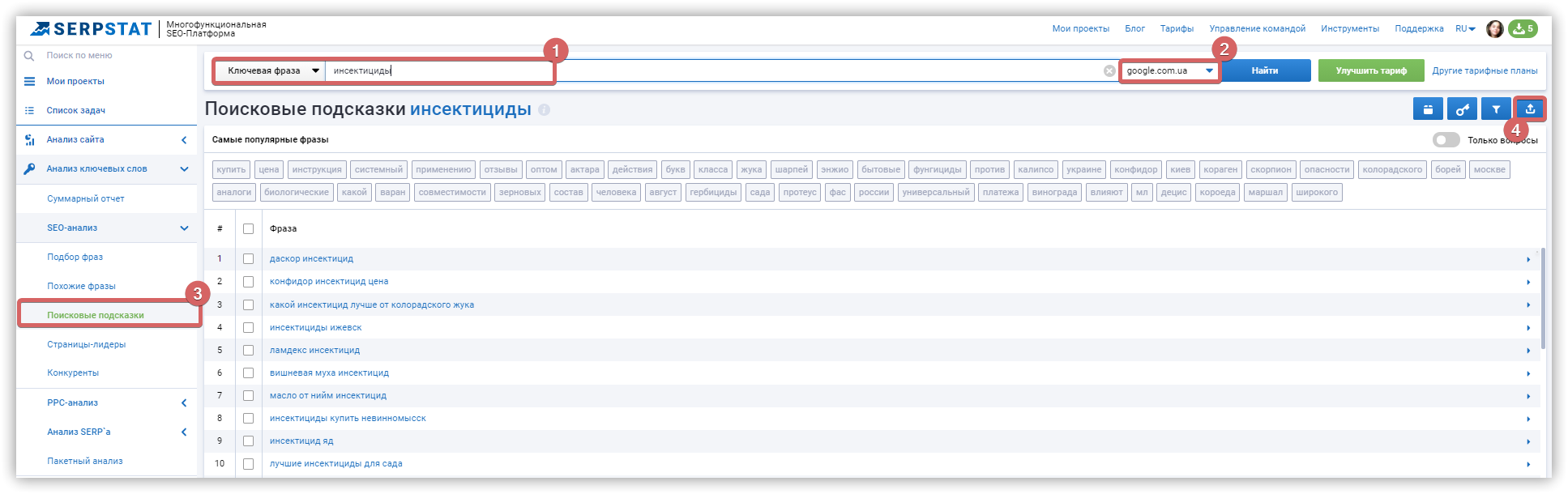
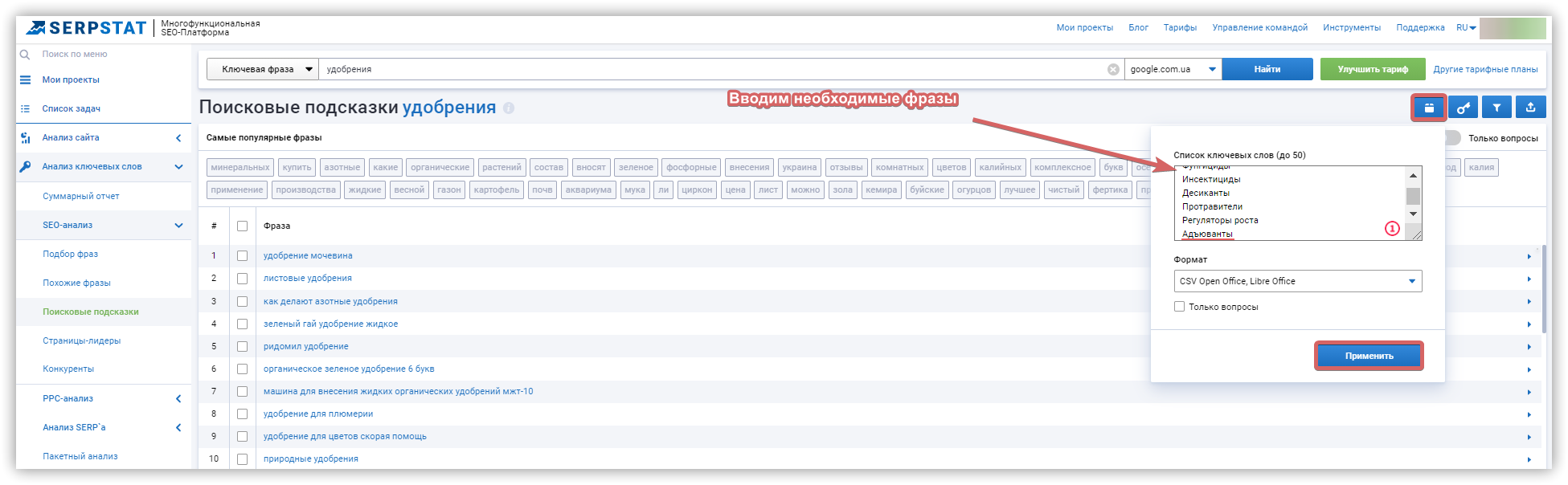
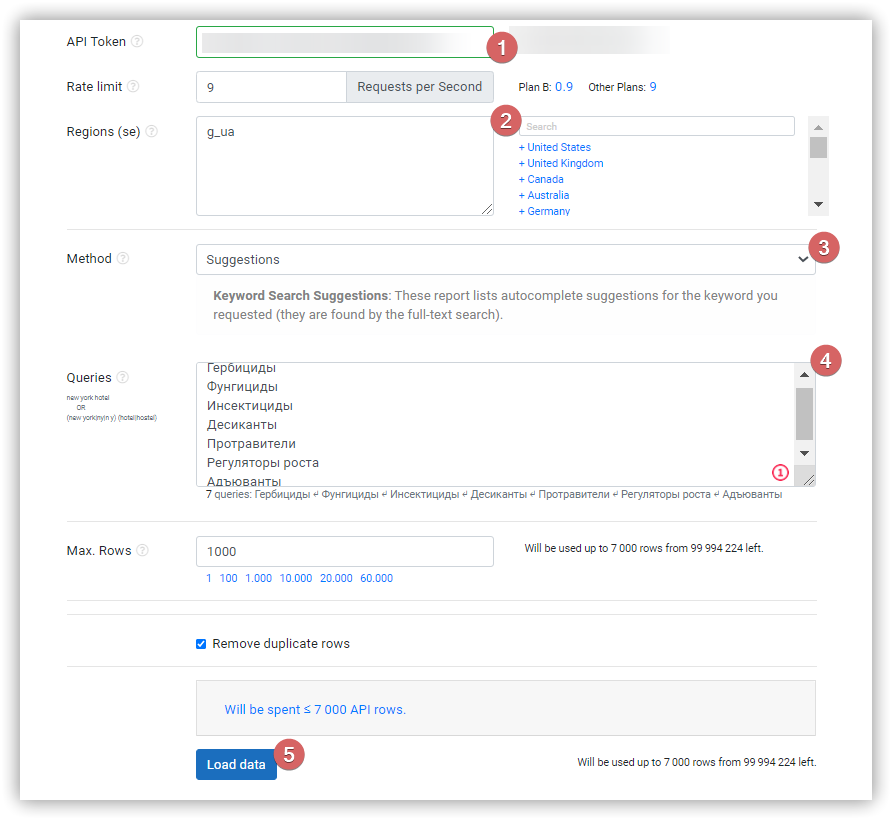
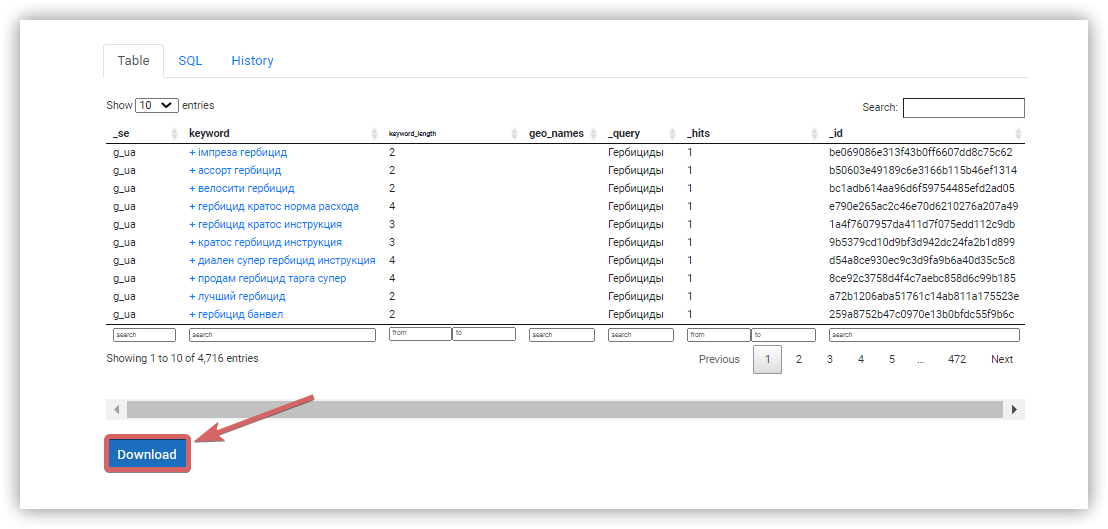
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)

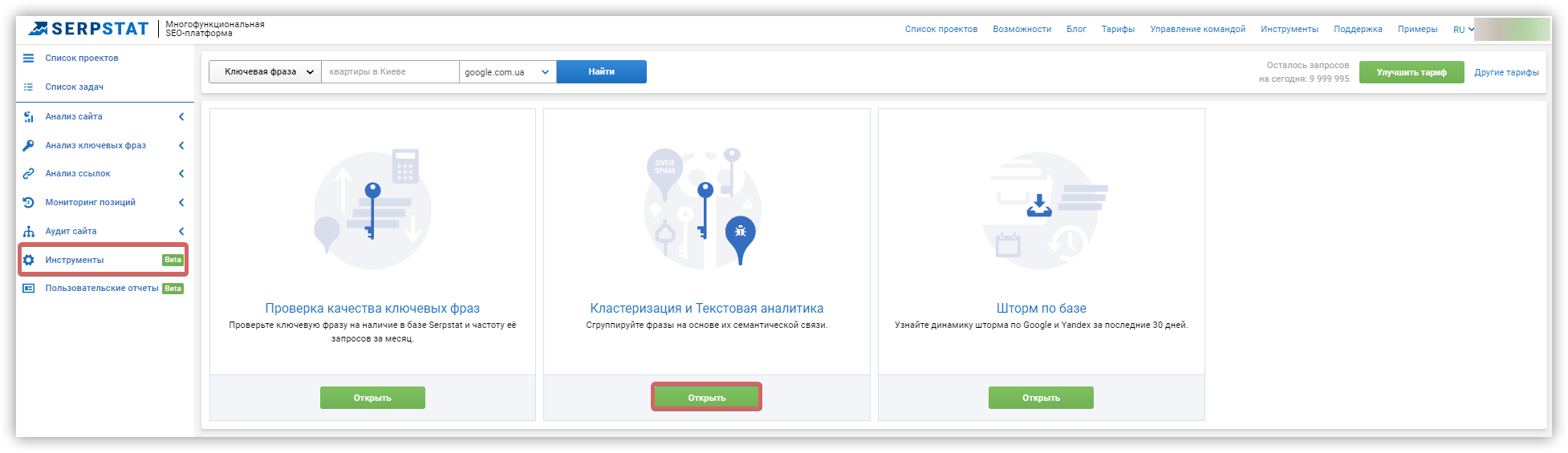
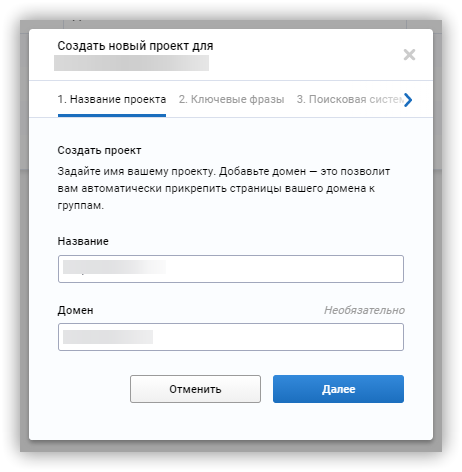
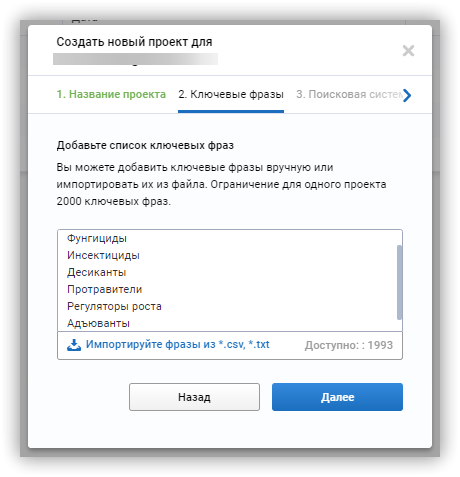
Кластеризация ключевых фраз
Чтобы кластеризовать фразы в Serpstat:
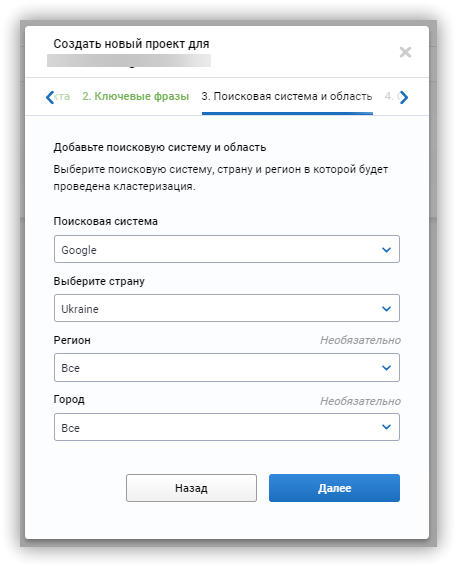
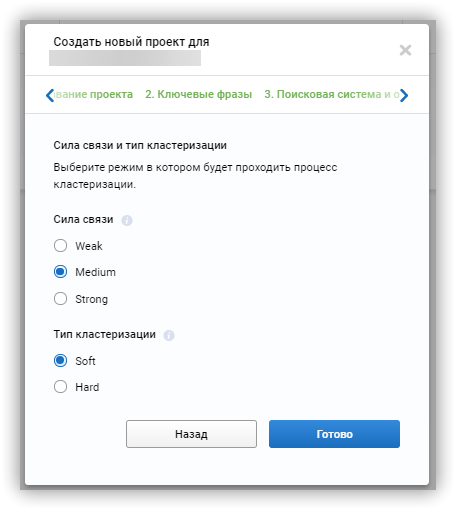
Как сформировать структуру сайта
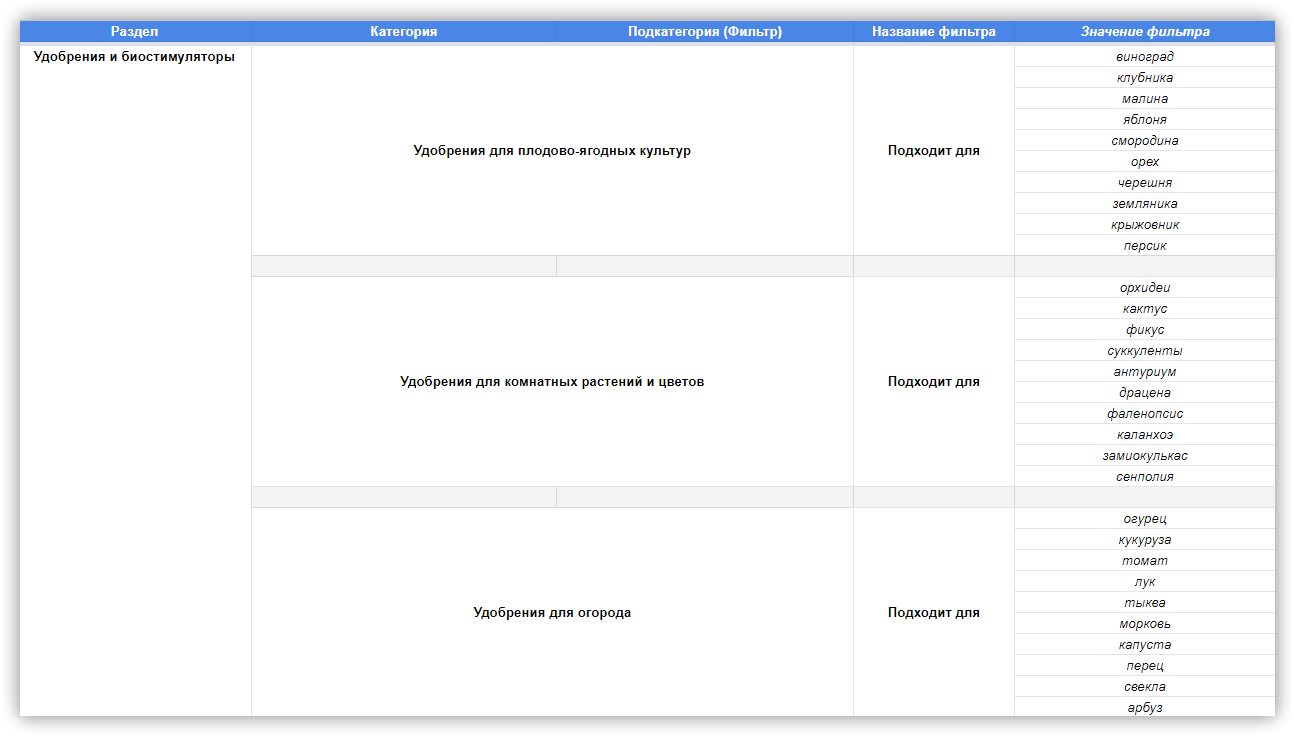
Все данные анализируем и переносим в таблицу. Вот небольшая часть того, что должно получиться:
Бонус: распространенные ошибки при составлении семантического ядра
Заключение
Посмотрите, сколько всего фраз у конкурентов. Проанализируйте их структуру и процент показов. Из имеющихся запросов проведите грамотную кластеризацию по принципу «один запрос = одна страница». Обратите внимание на последовательность слов во фразах, не путайте информационные запросы с коммерческими.
Учтите тот факт, что люди в процессе поиска находятся на разных стадиях. Ваша задача — учесть все возможные запросы на каждой из этих стадий. Не забывайте о низкочастотных запросах, которые помогут вам быстрее выбраться в топ. Размещайте их во вложенных страницах, а в описаниях разделов и категорий применяйте более частотные фразы. Регулярно расширяйте семантику на вашем сайте.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.