Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как проверить индексацию сайта в Google

Если реальное количество страниц на сайте не соответствует количеству проиндексированных страниц, это может сигнализировать о проблемах на сайте. В данной статье вы узнаете все о том, как проверить индексацию в Google.
2. Почему страница не попала в индекс
3. Как проверить индексацию сайта
- Составляем список всех страниц сайта
- Проверяем индексацию этих страниц
- Размечаем страницы — на важные и неважные
- Выясняем дату посещения роботом
- Смотрим есть ли ссылки на эти страницы
- Анализируем и исправляем
- Как проверить индексацию сайта в Google
4. Дополнительно
- Анализируем ошибки индексации в Google Search Console
Проверяем sitemap
- Проверяем в выдаче вручную с помощью оператора «site:»
- Проверяем ограничения в robots.txt
- Как ускорить индексацию сайта в Google
- Анализируем динамику индексации сайта
5. Ссылки на справки Google
FAQ
Когда страница попадает в индекс
То есть, чтобы страница попала в индекс:
- Робот должен зайти на нее.
- Робот должен посчитать ее важной.
Бесполезно звать робота повторно, если он уже посещал страницу и не добавил в индекс — сначала нужно найти и устранить предположительные причины, по которым робот мог посчитать ее неважной.
Почему страница не попала в индекс
- страница недавно появилась и робот просто пока не дошел до нее: возможно все в порядке и страница просто пока не успела проиндексироваться.
- на страницу нет ссылок: нужно проверить наличие в sitemap.xml и перелинковку на сайте.
- Отсутствие уникального контента.Уникальность контента — важный параметр для поисковых систем. Есть два варианта неуникального контента:
- Содержание не уникальное в рамках сайта (то есть это по сути дубль — есть такая же страница по другому адресу на этом же сайте). Если на сайте есть дубликаты страницы — поисковый робот может не индексировать их все, ограничившись одной копией на свое усмотрение.
- Содержание не уникальное в рамках интернета — контент страницы заимствован со стороннего источника, такая страница может не индексироваться.

Что еще хочу добавить, так это то, что в Google наличие большого объема условно низкокачественных страниц оказывает значимое влияние на ранжирование прочих. Иными словами, добавляя в индекс мусор, мы снижаем некую общую оценку всего сайта, то есть отрицательно влияем на него вцелом.
Уже является классикой удаление 70-80% страниц проекта, что приводит к резкому его росту.

- Страница долго загружается.Скорость загрузки страниц можно измерить с помощью разных средств, в том числе посмотреть в сервисах проверки, например:
- Смотрим PageSpeed Insights. Смотрим рекомендации сервисов проверки. Проверяем разные типы страниц.
- Смотрим также в Google Analytics. Отчет «Поведение» → «Скорость загрузки сайта». Удобно, что интегрировано с PageSpeed Insights и можно перейти («Поведение» → «Скорость загрузки сайта» → «Ускорение загрузки») в постраничный анализ (в столбце «Предложения PageSpeed»), а также увидеть тут же по страницам просадки (в столбце «Уровень скорости страниц»).
- Скорость загрузки можно проверить с помощью Аудита сайта Serpstat. В разделе «Скорость загрузки» вы найдете этот параметр для мобильных и десктопных устройств, а также ошибки, замедляющие скорость, и рекомендации по их устранению.
- Проверить скорость страницы прямо в браузере — можно с помощью расширения Serpstat Website SEO Checker.
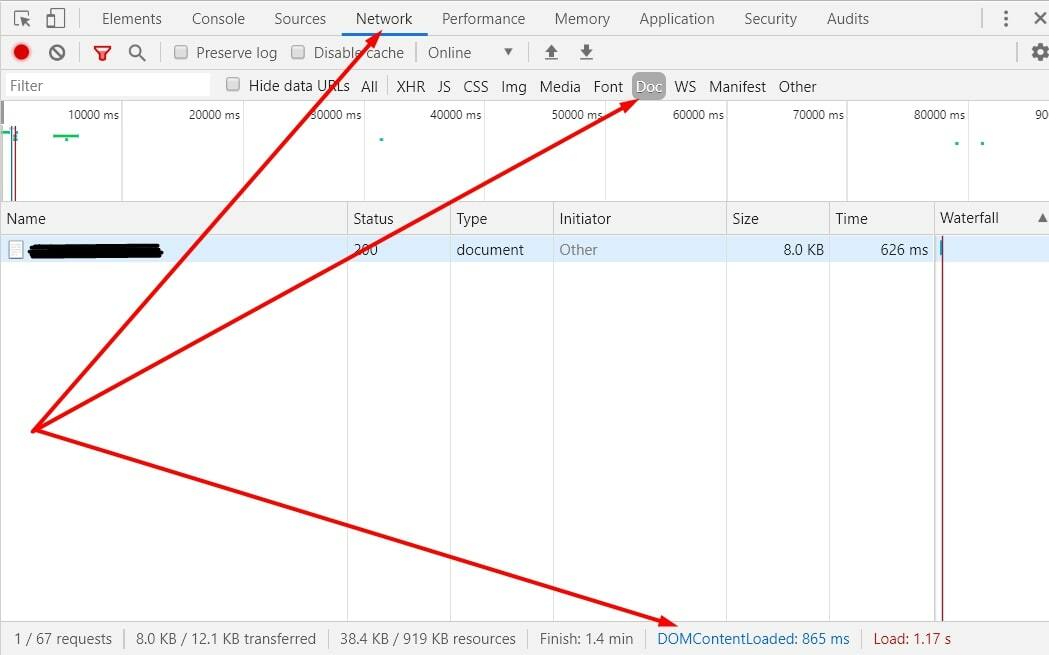
- В Google Chrome скорость можно смотреть прямо на странице, используя F12 (или сочетание клавиш Ctrl+Shift+I или щелкнув правой клавишей мышки и выбрав «Просмотреть код») → переходим во вкладку «Network»→«Doc», обновляем страницу и смотрим данные DOMContentLoaded (в идеале — чтобы было меньше 3-4 секунд):
- Смотрим PageSpeed Insights. Смотрим рекомендации сервисов проверки. Проверяем разные типы страниц.
- Страница с глубокой вложенностью (находится далеко от главной).
- По кликовой вложенности. Можно посмотреть разными инструментами — например, с помощью Аудита Serpstat или Netpeak Spider. Уровень вложенности можем уменьшить, оптимизировав структуру сайта, проработав меню.
- По URL вложенности:
- Высокий процент отказов.Можно посмотреть в Google Analytics.
- Отсутствует или мало контента на странице.Робот может посчитать неинтересными страницы, на которых расположено мало контента и они могут не индексироваться в поисковых системах. Контент — это не только текст, но и товары, картинки, видео — все содержимое страницы.
Также возможна такая ситуация из-за ошибок — например из-за незакрытого <noindex>.
- Контент сгенерирован автоматически.Если контент генерируется автоматически и качество генерации оставляет желать лучшего (например, когда все слова в тексте просто заменили на их синонимы). Страницы с таким контентом могут не индексироваться.
- Ошибки кодировки (например, вместо русского текста непонятные символы).Браузер/робот сам определяет кодировку, исходя из того что он получает от сервера, из контента страницы и пр. Если в кодировке ошибка, браузер/робот может воспринимать текст как хаотичный набор символов. Почему могут быть такие ошибки:
- не прописан тег <meta http-equiv="Content-Type" content="text/html; charset=кодировка" />;
- документ имеет кодировку, отличную от указанной в <meta> (например сайт в UTF-8, а указана кодировка Windows-1251);
- в htaccess не настроена кодировка;
- на сервере прописана неверная кодировка;
- кодировка базы данных отличается от кодировки скриптов сайта (когда например скрипты, заголовки и т.д. все в UTF-8, но база данных хранится в кодировке Windows-1251).
- не прописан тег <meta http-equiv="Content-Type" content="text/html; charset=кодировка" />;
- Указан некорректный код ответа сервера.Код ответа сервера – это информация, которую сервер сообщает посетителю перед тем, как начать передавать документы. Код ответа сервера может быть:
- положительным – 200;
- перенаправить посетителя на другую страницу (например – редирект 301);
- может сообщить о том, что страницы не существует (например – 404).
Как проверить код ответа?
- для всего сайта смотрим с помощью Аудита Serpstat, ScreamingFrog или других инструментов;
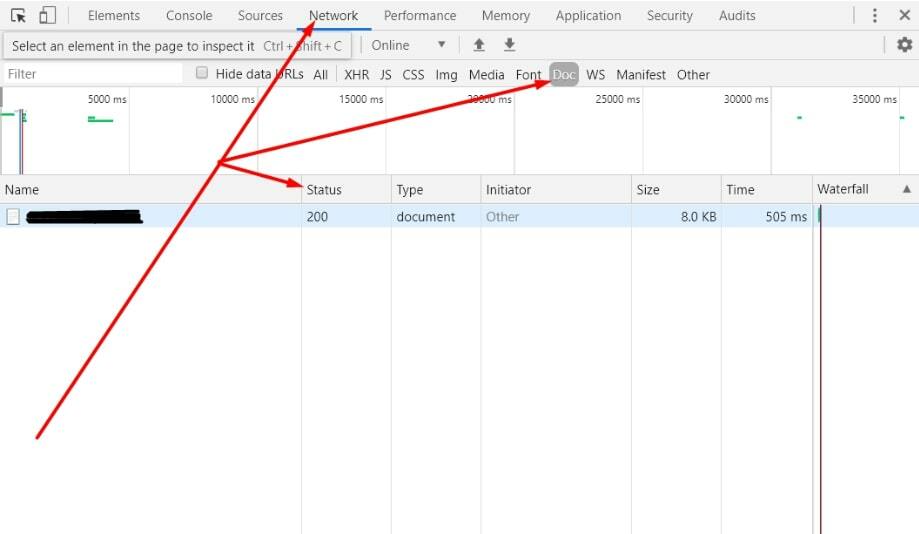
- для конкретной страницы смотрим в GoogleChrome прямо на странице, используя сочетание F12 (или сочетание клавиш Ctrl+Shift+i или щелкнув правой клавишей мышки и выбрав «Просмотреть код») → переходим во вкладку «Network»→«Doc», обновляем страницу и смотрим код ответа сервера в столбце «Status». Так же можно смотреть и в начальной вкладке «Network»→«All» (первой в списке всегда загружается наша конкретная страница), но мне больше нравится «Network»→«Doc», т.к. там ничего «лишнего» ;)
- положительным – 200;
- Важно проверить сайт на запрет индексации — проверяем robots.txt, noindex, meta name="robots". Массово — проверяем запрет в сводке по ошибкам Аудита сайта Serpstat, Screaming Frog или других сервисах;
- ошибка при выборе главного зеркала (с www или без www, http://или https://);
- дубли с «/» на конце с без «/»;
- молодой сайт — фильтр «Песочница»: у робота еще не накопилась статистика по ресурсу, он имеет недостаточный рейтинг, поэтому сайт не индексируется в Гугле. У него низкий краулинговый бюджет и робот ходит по нему довольно плохо;
- на сайт наложены санкции;
- сайт продает ссылки;
- на сайте вирусы;
- на сайте много страниц с 4** или 3** кодами ответов (то есть, много ссылок на такие страницы): нужно актуализировать ссылки внутри сайта (в контенте, в меню).

Как проверить индексацию сайта
- 1Составляем список всех страниц сайта.
- 2Проверяем индексацию этих страниц.
- 3Размечаем страницы — на важные и неважные.
- 4Выясняем дату посещения роботом.
- 5Смотрим есть ли ссылки на эти страницы.
- 6Ловим расхождения.
- 7Анализируем и исправляем.
1. Составляем список всех страниц сайта
- смотрим в админке/ просим программиста сделать выгрузку по всем адресам страниц, которые есть на сайте;
- из карты сайта: этот способ может использоваться лишь как дополнительный — надо учитывать, что туда, например, могут не попасть неважные страницы, которые могут быть в индексе;
- выгрузить из логов сервера все уникальные страницы, посещенные пользователями.
Это наиболее оптимальный способ. Данный источник будет наиболее полный. Не факт что прибегать к нему Вам понадобится, но знать про него лишним не будет.
На крупных сайтах возможно будет полезным для дальнейшего анализа, рассматривать не разом все страницы на одной вкладке таблицы, а разбить на отдельные разделы/категории.
2. Проверяем индексацию этих страниц
- вручную (оператор «site:», Google Search Console, RDS-Bar, букмарклеты);
- с помощью программ-парсеров (например — Comparser, A-Parser);
- сюда же отнесу еще один неочевидный способ съема — в Key Collector по URL через «Сбор позиций сайта»;
- с помощью сервисов (например — Serpstat, СайтРепорт, OverLead).
3. Размечаем страницы — на важные и неважные
- Размечаем вручную: смотрим URL и отмечаем.
- Либо вырабатываем возможные шаблоны для поиска неважных страниц и их разметки, но тут для каждого сайта нужно думать отдельно. Находим закономерности и используем их для автоматизации поиска и разметки (например — с помощью формул в таблицах).
- Составляем матрицу-сводку-списки:
- все проиндексированные важные страницы;
- все проиндексированные неважные страницы (это проблема);
- все непроиндексированные важные страницы (это точка роста).
- наличие в индексе неважных страниц (пустых, дублированных, страниц с ошибками, технических страниц) может замедлить индексирование важных страниц;
- чем больше проиндексированных неважных страниц — тем меньше веса получают важные страницы;
- угроза уменьшения/потери доверия поисковых систем к сайту (вплоть до попадания под фильтры);
- при схожести страниц — важная страница может быть вытеснена неважной.
4. Выясняем дату посещения роботом
- Из Google Search Console.
- Из логов сервераПросим программиста сделать выгрузку-отчет из логов сервера о посещении страниц сайта роботами. В этом отчете смотрим только страницы с кодом ответа 200.
Если логи не пишутся (особенно если у вас крупный ресурс и есть проблемы с индексацией), нужно начать их писать.
В логах нас интересуют: URL страницы, дата посещения, User-Agent (т.е. то как представился посетитель, в данном случае нам нужны записи роботов поисковых систем).
Может быть полезно:
Поисковые роботы Google.
Также с помощью логов сервера можно увидеть, на какую страницу робот зашел и не взял ее в индекс. Нужно понять, почему это произошло.
Что делаем?

- Изучаем список непроиндексированных страниц, которые не посещал робот. Это будет список страниц, на которые необходимо привести робота, чтобы они попали в индекс.
- Изучаем список непроиндексированных страниц, которые посетил робот, это будут страницы на которых есть проблемы (например, с дублями или статическим весом).
5. Смотрим, есть ли ссылки на эти страницы
7. Анализируем и исправляем
- Если важная страница не в индексе, и робот ее не посещал — нужно привести на нее робота.
- Если важная страница не в индексе, и робот ее посещал:
- Находим причину, по которой робот мог счесть страницу неважной и вносим соответствующие корректировки.
- Зовем робота повторно. Чтобы проиндексировать страницу в Google, используем проверку URL в Search Console.
- Если неважная страница в индексе — выявляем и устраняем причину.
Тут смотрим по ситуации — где-то нужно просто убрать/заменить ссылку, где-то закрыть в robots.txt. В случае с Google возможно воспользоваться их инструментом «Параметры URL» (Google Search Console → «Прежние инструменты и отчеты» → «Параметры URL»). - Если страницы неважные и они не в индексе — ничего предпринимать не нужно. Однако, для профилактики, чтобы они вдруг не попали в индекс:
- закрыть их от индексации в robots.txt;
Дополнительно
1. Анализируем ошибки индексации в Google Search Console
- раздел «Ошибка»: контролируем чтобы сюда не попадали важные страницы;
- «Без ошибок, есть предупреждения»: здесь можно отловить закрытые в robots.txt, но при этом проиндексированные, страницы.
- «Страница без ошибок»: здесь можно посмотреть, что залетает в индекс Google и нет ли там лишнего. Также можно увидеть проиндексированные страницы, которые отсутствуют в sitemap.
- «Исключено». Следим чтобы важные страницы не вылетали из индекса.
3. Проверяем sitemap
- проверяем наличие в файле robots.txt;
- проверяем в панели вебмастера;в Google Search Console: проверяем добавление в панель Вебмастера: «Индекс» → «Файлы Sitemap». Если нет — добавляем.
- проверяем добавляются ли новые страницы в sitemap;
- регулярно (раз в неделю-две) скармливаем sitemap в Screaming Frog, делаем обход по нему.

Если у вас, например, крупный онлайн магазин, осознанное разделение по разделам может быть полезным в дальнейшем для анализа этих разделов по отдельности (в частности — для анализа индексации).
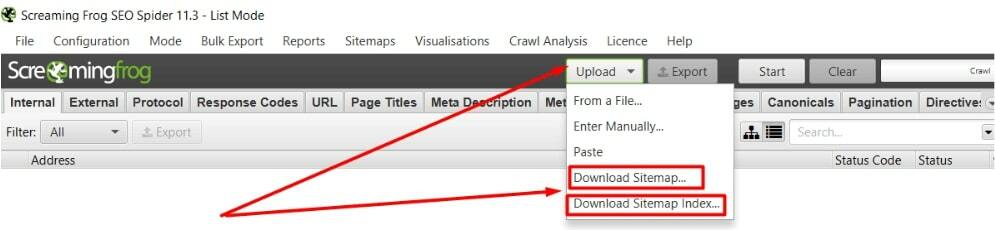
Также это поможет найти огрехи в шаблоне автогенерации sitemap, например:
- дубли страниц;
- замены страниц (пример — /home вместо / , когда это полный дубль);
- неактуальные адреса — адрес страницы с http: когда актуальный с https;
- адрес страницы с www. когда актуальный без www. и т.д.;
- страницы с редиректом;
- 404-страницы.
- страницы пагинации;
- закрытые от индексации страницы.
- страницы закрытые в robots.txt директивами Disallow или Clean-param;
- закрытые в meta name="robots";
- неканонические (с которых стоит rel cannonical).
- незакрытые страницы, которых в сайтмапе быть не должно (пример — шаблонные, технические и пр.).
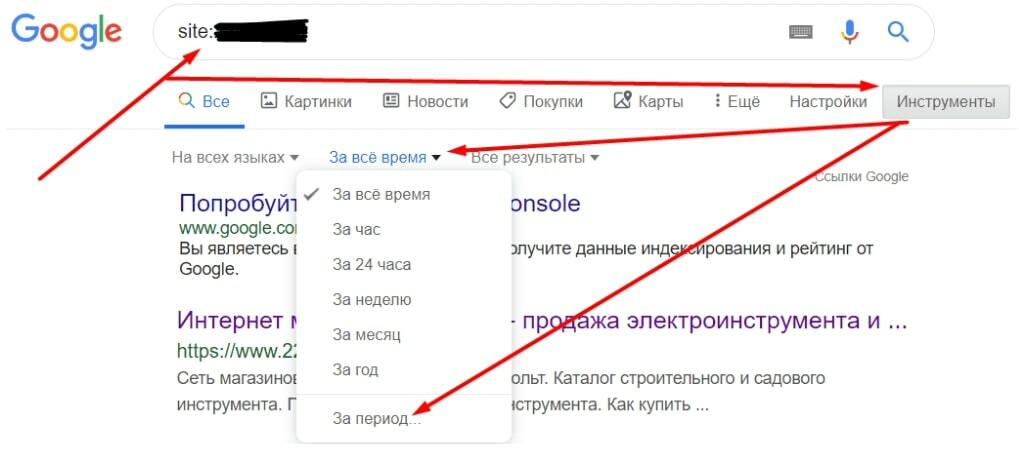
4. Проверяем в выдаче вручную с помощью оператора «site:»

5. Проверяем ограничения в robots.txt
Смотрим в Аудите Serpstat → «Закрытые в Robots.txt».
Для Google следует помнить, что прописанное в robots.txt ограничение — не панацея, поэтому Вам также может пригодиться инструмент «Параметры URL» (Google Search Console → «Прежние инструменты и отчеты» → «Параметры URL»).
6. Как ускорить индексацию сайта в Google
- Добавляем страницу в sitemap.xml.
- Добавляем страницу через панель Вебмастера.
в Google Search Console:
- «Проверка URL»→ Вбиваем адрес→ «Запросить индексирование»;
- «Файлы Sitemap»→ «Добавьте файл Sitemap».
- Делаем перелинковку.Ставим ссылку на часто посещаемой странице и/или связанной по логике и отправляем ее на переобход. Для этого возможно будет полезным использовать mindmap — построить логическое дерево и на нем отобразить связи. Сюда же — создание отдельных блоков, в которые выводятся ссылки на новые страницы.
- Ставим ссылки вне сайта, возможно из социальных сетей.
- Используем HTML-карту сайта.
- Внедряем модуль «Ловец ботов» (когда робот заходит на страницу — ему подставляются нужные ссылки, по которым ему нужно перейти).
7. Анализируем динамику индексации сайта
Если загружаем новый сайт или много новых страниц, нужно следить за динамикой индексации. По мере развития сайта динамика постепенно должна увеличиваться.
Каким образом можем проследить?
Чтобы оценить динамику — нужно знать сколько страниц залетают в индекс каждый день. Для этого:
- используем расширенные настройки поиска;
- смотрим данные в кабинете Вебмастера Google Search Console — «Покрытие».
Да, в этих данных может быть погрешность, но для оценки относительной общей динамики эти данные полезны. Что делаем с этими данными?
Анализируем динамику индексации:
- Пробиваем каждую дату.
- Сводим данные в таблице.
- Анализируем в моменте. Например, если ничего не добавлялось в индекс, а страницы лезут в индекс — значит есть проблемы.
- Можем для наглядности построить график.
- Так, кстати, можно анализировать и конкурентов ;) Следим за ними постоянно — собираем данные и сравниваем по индексации с собой. Возможно что-то подсматриваем у них и внедряем/тестируем у себя.
Справка Google
- Вопрос:Как проиндексировать сайт в Гугл?Ответ:Чтобы проиндексировать сайт в Google, осуществите такие действия:
- Перейдите в Search Console.
- Выберите нужный ресурс.
- Зайдите в раздел Индекс → Sitemap.
- Добавьте URL файла Sitemap в соответствующее поле.
- Нажмите «Отправить» и ожидайте отображения результатов индексации.
- Вопрос:Как быстро проиндексировать сайт?Ответ:Для быстрой индексации сайта в Google можно использовать инструмент «Проверка URL» Search Console. Добавьте на проверку нужный адрес и ожидайте в течение нескольких минут проверки. После этого отправьте запрос на индексацию сайта.
- Вопрос:Как часто Гугл индексирует сайт?Ответ:
- Индексация сайта в Гугле занимает от нескольких дней до нескольких недель.
- Узнать о результатах сканирования можно в Search Console, в разделе Индекс → Покрытие.
- Если запрашивается индексация отдельных страниц, существует ограничение на количество запросов в сутки.
- При повторных запросах сканирования индексация не осуществляется быстрее.
- Вопрос:Где проверить сайт на индексацию?Ответ:Проще всего проверить индексацию сайта с помощью оператора «site:» с добавлением URL-адреса ресурса в поиске Google. Так вы узнаете количество проиндексированных страниц. Для более подробной информации воспользуйтесь Google Search Console. В панели вебмастера можно запросить индексацию всех важных страниц проекта.
- Вопрос:Почему не индексируется сайт?Ответ:Чаще всего сайт не индексируется по таким причинам:
- Фильтры поисковых систем из-за заспамленности, неуникального контента, некачественных ссылок, наличия вредоносного программного обеспечения и пр.
- Некорректные технические настройки, запрещающие доступ ботов на сайт, например, запрет индексации в файле robots.txt.
- Молодой возраст сайта.
- Слишком низкая скорость загрузки страниц.
- Продажа ссылок на сайте.
FAQ
Как проиндексировать сайт в Гугл?
Чтобы проиндексировать сайт в Google, осуществите такие действия: Перейдите в Search Console. Выберите нужный ресурс. Зайдите в раздел Индекс → Sitemap. Добавьте URL файла Sitemap в соответствующее поле. Нажмите «Отправить» и ожидайте отображения результатов индексации.
Как быстро проиндексировать сайт?
Для быстрой индексации сайта в Google можно использовать инструмент «Проверка URL» Search Console. Добавьте на проверку нужный адрес и ожидайте в течение нескольких минут проверки. После этого отправьте запрос на индексацию сайта. Перейдите в инструмент «Переобход страниц», который находится в разделе «Индексирование». Отправьте URL-адрес сайта или конкретной веб-страницы.
Как часто Гугл индексирует сайт?
Индексация сайта в Гугле занимает от нескольких дней до нескольких недель. Узнать о результатах сканирования можно в Search Console, в разделе Индекс → Покрытие. Если запрашивается индексация отдельных страниц, существует ограничение на количество запросов в сутки. При повторных запросах сканирования индексация не осуществляется быстрее/
Где проверить сайт на индексацию?
Проще всего проверить индексацию сайта с помощью оператора «site:» с добавлением URL-адреса ресурса в поиске Google. Так вы узнаете количество проиндексированных страниц. Для более подробной информации по каждой поисковой системе воспользуйтесь Google Search Console. В панелях вебмастеров можно запросить индексацию всех важных страниц проекта.
Почему не индексируется сайт?
Чаще всего сайт не индексируется по таким причинам: Фильтры поисковых систем из-за заспамленности, неуникального контента, некачественных ссылок, наличия вредоносного программного обеспечения и пр. Некорректные технические настройки, запрещающие доступ ботов на сайт, например, запрет индексации в файле robots.txt. Молодой возраст сайта. Слишком низкая скорость загрузки страниц. Продажа ссылок на сайте.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.