Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как быстро оптимизировать сниппет с помощью конкурентов?

Отличие методов GET от POST лежит в способе передачи данных. Запрос GET передает данные в URL, а запрос POST – в теле запроса.
Это различие описывает характеристики способов и особенности запросов для использования того либо другого способа.
Пример из кейса можно рассматривать как демонстрацию возможностей для написания собственных скриптов или использования существующих и получения данных в соответствии с вашими задачами.
Ознакомиться с актуальными APi-методами и синтаксисом можно здесь. serpstat.com/ru/api/
Пример запроса с POST-методом:
{
"id": "1",
"method": "SerpstatDomainProcedure.getDomainsInfo",
"params": {
"domains": ["nike.com", "adidas.com"],
"se": "g_us"
}
}

Так как же все-таки создать и получить оптимальный сниппет, чтобы полюбиться поисковикам?
Кроме того, с помощью этой статьи, вы найдете «аномальные сниппеты», которые отпугивают потенциальных клиентов.
Каково значение снипета в выдаче?

Что же делать?
Для этого нужно смотреть выдачу по множеству фраз, а она может сильно отличаться.
Возьмем, например, фразы «кроссовки adidas» и «кроссовки adidas цены». Только 4 сайта входят в топ-10 по обеим фразам. Значит, при подготовке title и meta-description для сниппета мне нужно учесть сниппеты не 10, а 16 страниц. А если фраз десятки или сотни?
В чем суть метода?
В результате я получаю таблицу с перечнем слов и фраз, которые желательно использовать с перечнем рекомендаций.
Как это работает?
Для этого достаточно ввести какую-то фразу в поиске, например, «кроссовки» и в левом меню перейти на отчет «Страницы-лидеры». Так можно быстро узнать страницы, которые ранжируются по максимуму фраз из вашей ниши.

Возьмем в качестве примера сайт 24k.ua. На нем есть раздел, посвященный часам Casio, который является одним из лидеров этой конкурентной ниши.
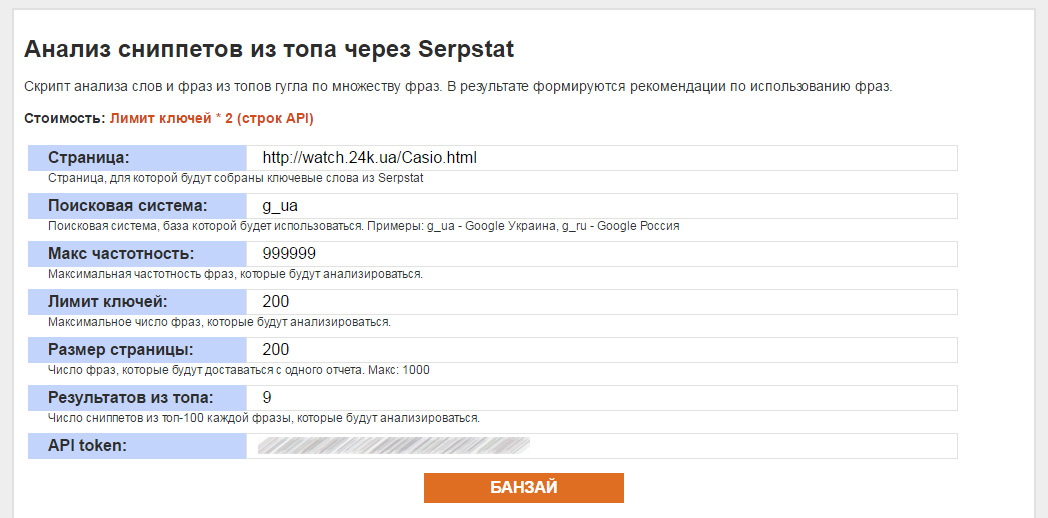
- Страница — url, для которого будут выгружаться ключевые слова из базы Serpstat. В примере я использую страницу про часы Casio.
- Поисковая система — в этом поле нужно указать код нужной поисковой системы из базы сервиса. Например, для Украины этот код — g_ua. Для Германии – g_de.
- Макс частотность — максимальное значение частотности фраз, которые будут анализироваться. Если вам интересны только НЧ фразы, то можно указать 20. Я рекомендую использовать большое число, например, 9913199.
- Лимит ключей — максимальное число фраз, которые скрипт будет выгружать для указанной страницы. Это половина строк API, которые будут использованы.
- Размер страницы — параметр необходимый для пагенации при работе с API Serpstat, т.к. функция url_keywords может выдавать максимум 1000 фраз. Если у вас стоит лимит ключей меньше 1000, то рекомендую использовать размер страницы такой же, как лимит ключей.
- Результатов из топа — число первых сниппетов каждой фразы, которые будут участвовать в анализе. Я чаще всего анализирую топ-5, топ-9 и топ-20, т.е. устанавливаю 5, 9 или 20. Как видно, в примере я указал 9.
- API token — сюда нужно ввести свой ключ для API. Его можно узнать на странице своего профиля в сервисе.
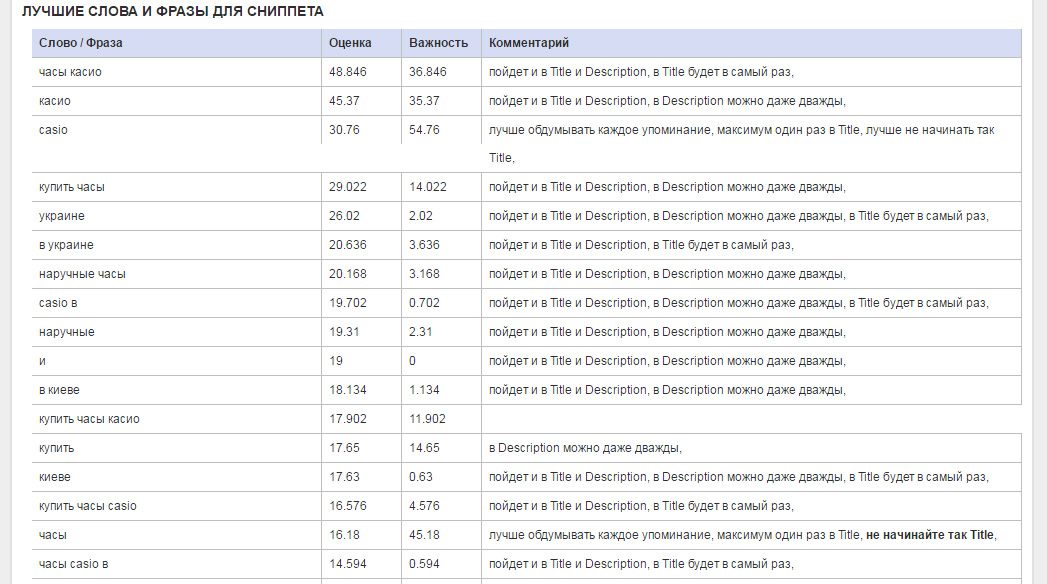
- Оценка — числовое значение характеристик фразы, полученное по сложной формуле в результате учета положения фразы/слова в разных элементах и частоты упоминания.
- Важность — числовая характеристика, определяющая важность использования данной фразы. Максимальное значение – 100.
- Комментарий — перечень советов по использованию фразы/слова в title или description. Например, можно получить рекомендацию не использовать фразу в начале Title, т. к. слишком много сайтов используют эту фразу в начале своего Title. Для указанного примера было найдено две таких фразы.


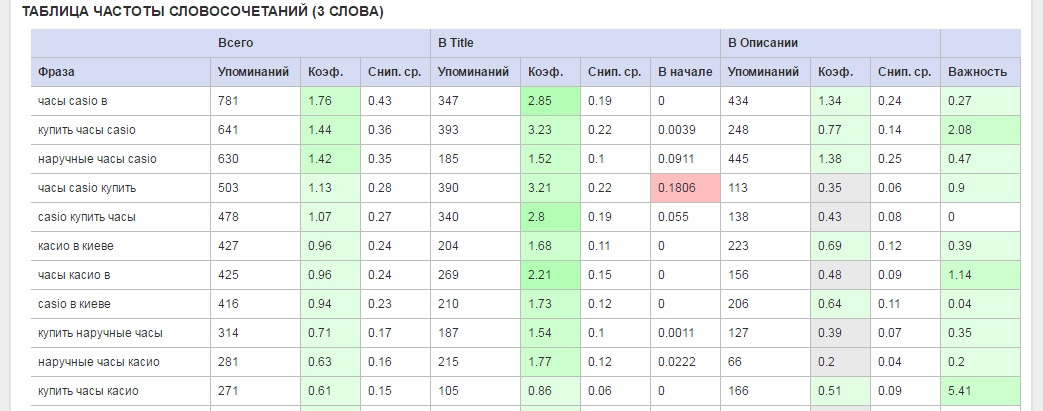
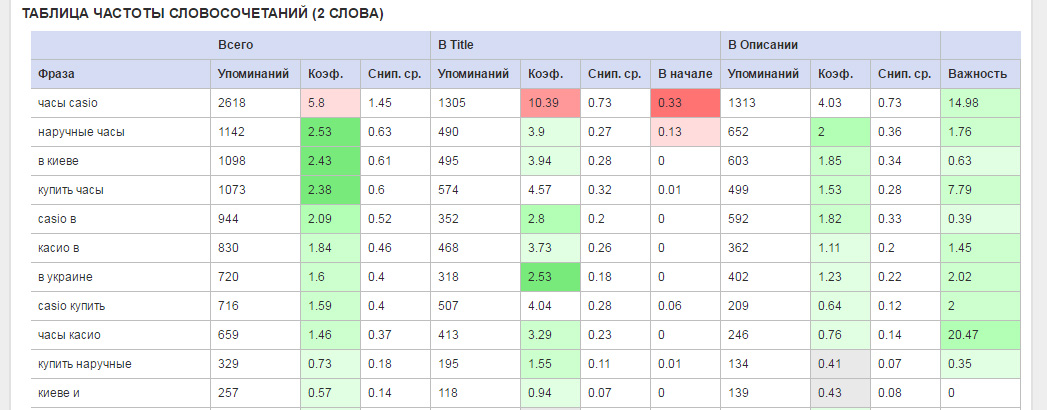
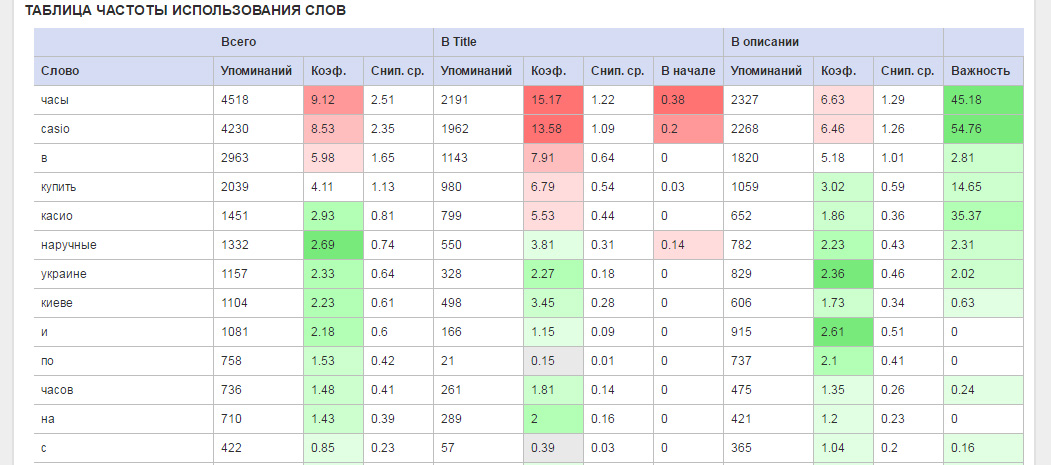
- Упоминания — число упоминаний слова/фразы во всех сниппетах.
- Коэффициент — процент упоминаний фразы относительно всех фраз.
- Снип. Ср. — среднее число упоминаний фразы на каждый сниппет. Например, значение 2 означает, что слово встречается в среднем два раза в каждом сниппете.
- Важность — параметр, о котором уже упоминалось.
Благодаря этим таблицам можно легко подбирать фразы и слова для Title и Meta-Description страницы, чтобы ее сниппет был уникальным и покрывал максимальное число тематичных фраз.
Cкрипт также позволяет находить «аномальные» сниппеты. Это те сниппеты, описание или заглавие, которых отличается от заданных значений в тегах страницы. Зачастую для них берется кусок текста страницы. Найдя такие сниппеты можно легко отредактировать текстовое содержимое, чтобы сниппет выглядел более привлекательно.
Для страницы из примера была получена следующая таблица:

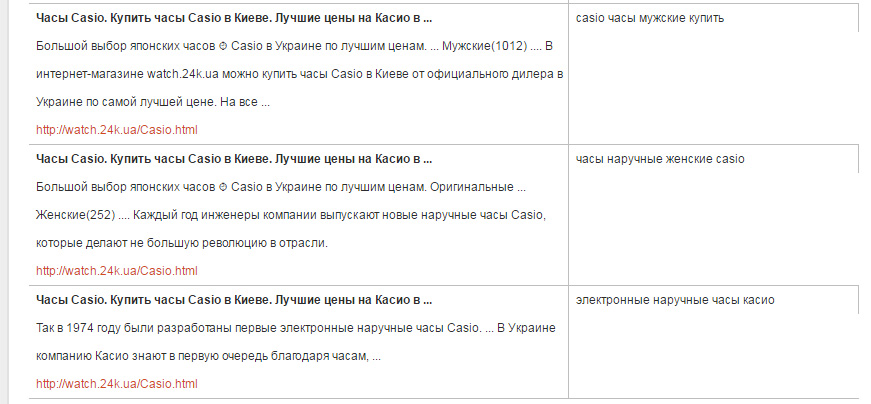
Ну и в конце таблицы выводятся текстом, чтобы их легко обрабатывать в Excel и подобных.

Какая от этого польза?
Скрипт создан для быстрой и идеальной оптимизации ваших сниппетов. Он будет очень полезен, если вы хотите войти в нишу и продумываете Title и Description для основных страниц сайта.
Не лишним он будет, если ваша страница уже в топ-3 или топ-5, ведь можно проанализировать только топ-3 и получить рекомендации по нему. Кроме этого можно подбирать фразы для западных проектов, если вы плохо знаете язык. Я, например, так делал для Германии. Вместо того, чтобы изучать топ и переводить разные фразы и предложения, просто получил перечень фраз с хорошей оценкой и быстро составил оптимальные предложения.
Воспользоваться им вы можете по ссылке или скачать исходник.
http://mz.kiev.ua/tools/serpstat-get-snippets.php
http://mz.kiev.ua/tools/serpstat-get-snippets.rar
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.