Почніть шукати ключові слова
Використовуйте Serpstat, щоб знаходити найкращі ключі
Кластеризація семантичного ядра: алгоритми та підходи популярних SEO-інструментів


Кластеризація ключових фраз у SEO – це поєднання схожих запитів у групи для зручної оптимізації сайту. Ці дії допомагають зібрати семантичне ядро, розподіливши ключові запити для просування на зручні цільові групи, виходячи з певних параметрів.
Кластеризація застосовується у різних галузях: для сегментації ринку, аналізу соціальних мереж, групування результатів пошуку, медичної візуалізації, сегментації зображень та виявлення аномалій. У цій статті ми заглибимося в алгоритми кластеризації не тільки з точки зору SEO, але і з позицій кластерного аналізу як важливого методу машинного навчання.
Кластеризація застосовується у різних галузях: для сегментації ринку, аналізу соціальних мереж, групування результатів пошуку, медичної візуалізації, сегментації зображень та виявлення аномалій. У цій статті ми заглибимося в алгоритми кластеризації не тільки з точки зору SEO, але і з позицій кластерного аналізу як важливого методу машинного навчання.
Що таке кластеризація і для чого вона потрібна в SEO?
У чому переваги автоматичної кластеризації ключових слів?
Алгоритми кластеризації у машинному навчанні
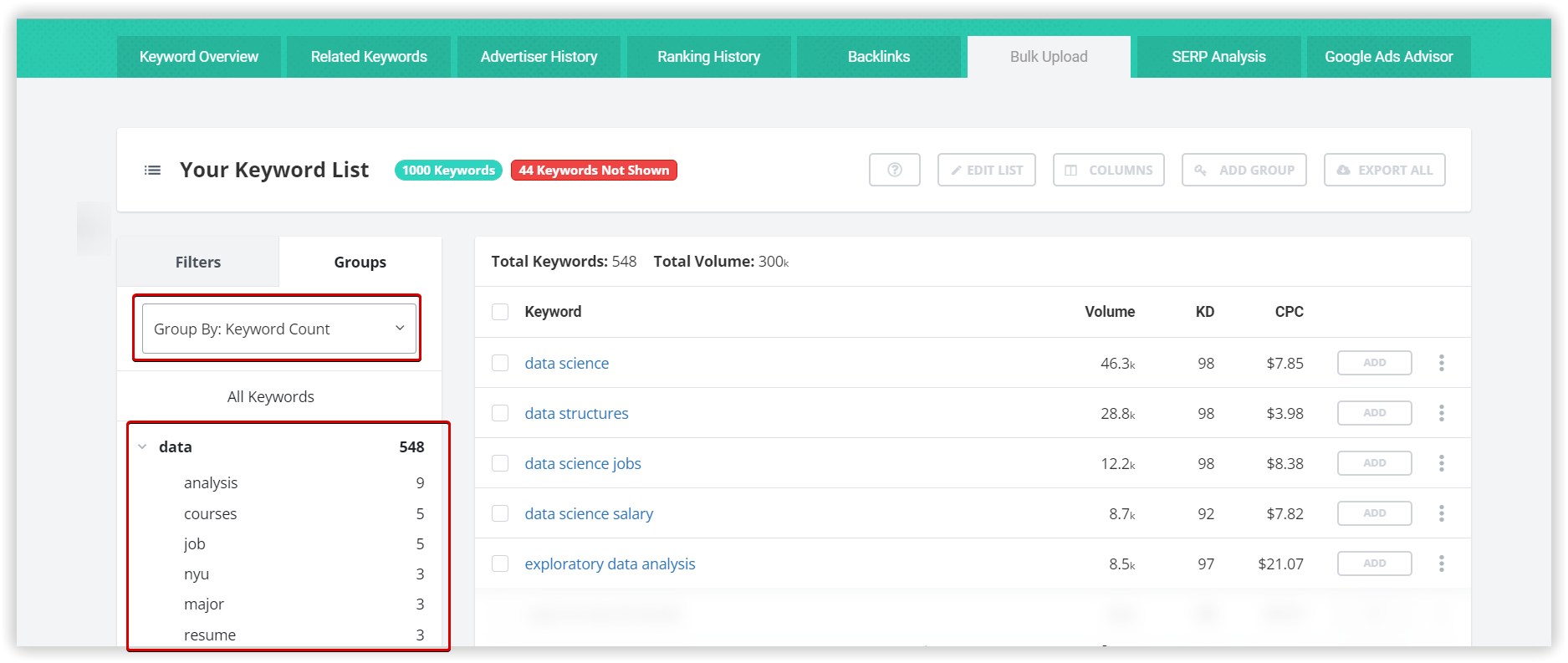
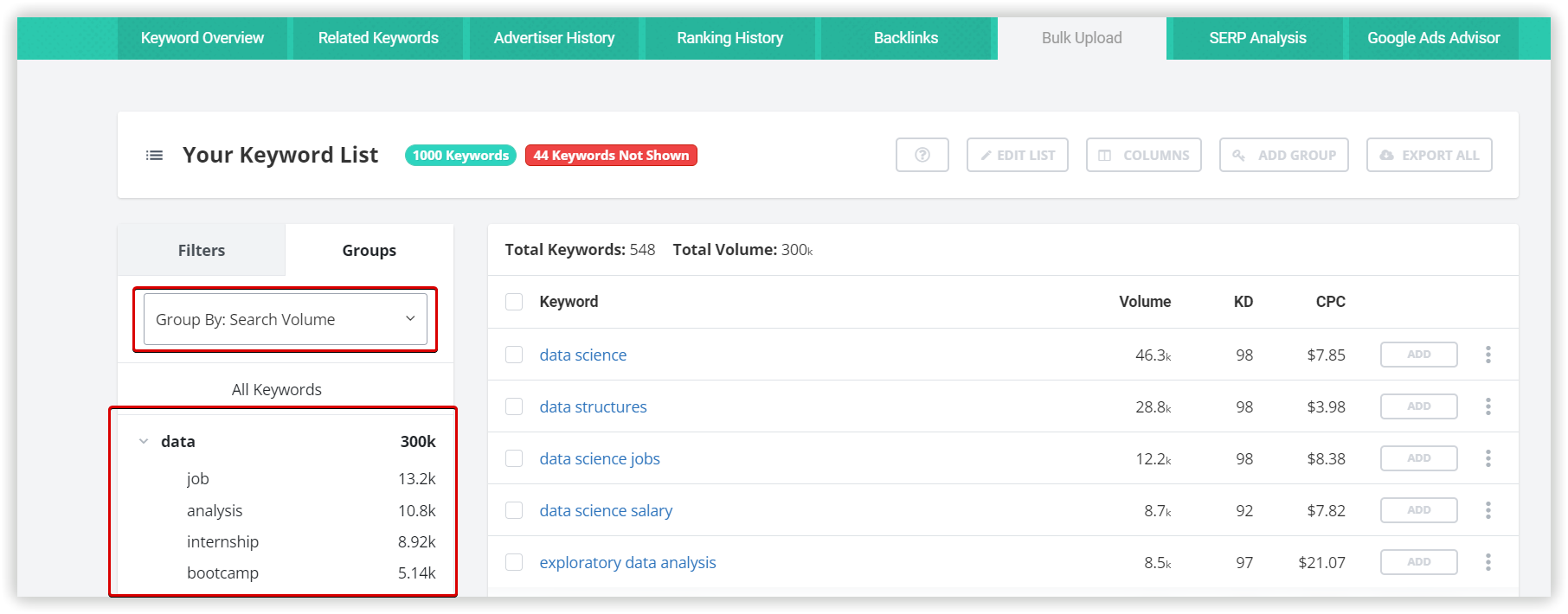
Як зібрати дані для свого проєкту за допомогою кластеризації Serpstat?
У чому переваги автоматичної кластеризації ключових слів?
Алгоритми кластеризації у машинному навчанні
- Загальні математичні підходи
- Підходи на основі систем штучного інтелекту
- Логічний підхід
- Теоретико-графовий підхід
Як зібрати дані для свого проєкту за допомогою кластеризації Serpstat?
- Основні налаштування кластеризації
- Особливості модуля кластеризації Serpstat
- Практичний кейс-дослідження
Що таке кластеризація і для чого вона потрібна в SEO?
Робота з семантичним ядром є основним завданням для підготовки будь-якої SEO-стратегії. Для пошуку найбільш релевантних запитів і формування семантичного ядра, як найбільш трудомісткого етапу, потрібні особливі підходи, які допоможуть заощадити час та гроші.
Підготовка контенту за допомогою кластеризації, крім основних переваг, робить ваш сайт більш зрозумілим для алгоритмів Google.
Кластеризація — це процес поділу набору об'єктів на групи, які називаються кластерами. Однотипні об'єкти повинні потрапляти до однієї групи, водночас об'єкти у різних кластерах мають максимально відрізнятися. Кластеризація в SEO допомагає визначити найбільш релевантні ключові слова та відфільтрувати менш пріоритетні для кращого ранжування.
У 2013 році Google випустив Hummingbird і цей алгоритм почав фокусуватися на фразах, а не на окремих ключових словах, розуміючи їх сенс. У 2015 році з'явився апдейт RankBrain, здатний визначати теми пошукових запитів та знаходити схожі ключові слова.
Створення кластерів ключових запитів, поєднаних тематикою, дає більше можливостей для ефективного розміщення внутрішніх посилань на вашому сайті, що підвищує рівень залучення користувачів. Таке перелінкування допомагає Google зрозуміти, які сторінки є найважливішими.
Якщо ваш бізнес включає мультипродуктові та мультисервісні напрямки — ви можете створити більше кластерів на сайті, перелінкувати їх. У разі просування одного продукту або послуги, кількість створених кластерів буде меншою, але при відповідних налаштуваннях автоматичної кластеризації, ваше семантичне ядро можна розбити на більш дрібні групи. Вивчення основних тематичних напрямків та розширення семантики великою кількістю корисного контенту допоможе покращити вашу конкурентоспроможність.
Одним із ключових принципів ефективного аналізу є розуміння мотивів відвідувачів вашого сайту. Для цього потрібно проаналізувати не тільки ключі, які ваші відвідувачі використовують щоб потрапити на сайт, а і слова, які вони шукають перебуваючи на сайті (пошук по сайту).
Виділяють два основних типи кластеризації ключових слів у SEO:
Підготовка контенту за допомогою кластеризації, крім основних переваг, робить ваш сайт більш зрозумілим для алгоритмів Google.
Кластеризація — це процес поділу набору об'єктів на групи, які називаються кластерами. Однотипні об'єкти повинні потрапляти до однієї групи, водночас об'єкти у різних кластерах мають максимально відрізнятися. Кластеризація в SEO допомагає визначити найбільш релевантні ключові слова та відфільтрувати менш пріоритетні для кращого ранжування.
У 2013 році Google випустив Hummingbird і цей алгоритм почав фокусуватися на фразах, а не на окремих ключових словах, розуміючи їх сенс. У 2015 році з'явився апдейт RankBrain, здатний визначати теми пошукових запитів та знаходити схожі ключові слова.
Створення кластерів ключових запитів, поєднаних тематикою, дає більше можливостей для ефективного розміщення внутрішніх посилань на вашому сайті, що підвищує рівень залучення користувачів. Таке перелінкування допомагає Google зрозуміти, які сторінки є найважливішими.
Якщо ваш бізнес включає мультипродуктові та мультисервісні напрямки — ви можете створити більше кластерів на сайті, перелінкувати їх. У разі просування одного продукту або послуги, кількість створених кластерів буде меншою, але при відповідних налаштуваннях автоматичної кластеризації, ваше семантичне ядро можна розбити на більш дрібні групи. Вивчення основних тематичних напрямків та розширення семантики великою кількістю корисного контенту допоможе покращити вашу конкурентоспроможність.
Одним із ключових принципів ефективного аналізу є розуміння мотивів відвідувачів вашого сайту. Для цього потрібно проаналізувати не тільки ключі, які ваші відвідувачі використовують щоб потрапити на сайт, а і слова, які вони шукають перебуваючи на сайті (пошук по сайту).
Виділяють два основних типи кластеризації ключових слів у SEO:
на основі лем (за схожістю значення ключових слів, їх морфологічними характеристиками);
на основі SERPів (за ТОПами, спільними результатами в видачі пошукової системи)
Ми розглянемо ці підходи та протестуємо кілька платформ. Один і той же набір даних буде розбитий на кластери алгоритмами, що спираються на пошукову видачу та на леми. Наприкінці, готові кластери зі схожими алгоритмами ми перевіримо за допомогою Текстової аналітики, щоб виявити текстову релевантність таких груп.
У чому переваги автоматичної кластеризації ключових слів?
Автоматична кластеризація, базується на машинному навчанні, заощаджує ваш час та виконує завдання з високою точністю. Автоматизовані підходи до кластеризації точніші, ніж мануальні за рахунок низки людських факторів. SEO-фахівцеві знадобиться до трьох днів, щоб скластеризувати тисячу фраз самостійно. При цьому, існує висока ймовірність додавання фрази до помилкового кластера, а також випадкової втрати ключових слів з вашого набору даних. При використанні автоматичної кластеризації, залежно від кількості ключових слів та налаштувань проекту, подібне завдання можна виконати за три години.
- Кластеризація дозволяє об'єднувати фрази за змістом та провести глибший аналіз вашого пулу ключових слів. На основі кластеризації, ви можете створити контент-план та впорядкувати найбільш релевантні набори фраз для просування певних складових вашого контенту.
- Кластеризація допомагає краще зрозуміти інтент користувача. SEO, орієнтоване на тематику, пропонує ретельнішу відповідь на запит користувача, ви орієнтуєтеся на наміри, а не на охоплення одного ключового слова. Отримані кластери допоможуть вам визначити, як мають бути пов'язані окремі сегменти контенту. Це дозволяє оцінити семантичні зв'язки між вашими сторінками в загальній архітектурі сайту.
- Кластеризація ключових слів дозволить вам створювати ефективні цільові сторінки, що позитивно вплине на залучення трафіку.
- За допомогою ієрархічної кластеризації можна організувати структуру веб-сайту з нуля. Кластеризація допомагає полегшити загальну структуру вашого сайту та UX, зробити його зручнішим для відвідувачів.
- Ключові слова з одного кластера можна розміщувати на відповідній сторінці без ризику канібалізації трафіку або появи змішаного контенту. Нескластеризовані ключові слова можна використовувати для інших цілей. Завдяки такому групуванню запитів, ви можете підвищити видимість та авторитет вашого сайту як для користувачів, так і для пошукових систем.
- Автоматична кластеризація ключових слів надає вам всі перераховані переваги швидко і без додаткових зусиль.
Існують різні підходи до автоматичної кластеризації ключових слів. Наприклад, використовуючи «Soft» кластеризацію, деякі інструменти орієнтуються на ключове слово з найбільшою частотністю і порівнюють топ із видачі за цією фразою, з результатами, що відображаються для інших ключових слів. Таким чином, результат кластеризації залежить від кількості URL-адрес, що співпали, у видачі за кожною аналізованою фразою, з видачею за високочастотним ключем — центроїдом цього кластера. Коли кількість спільних URL-адрес досягає рівня заданої точності групування у налаштуваннях, ключові фрази поєднуються у кластер. При застосуванні таких підходів групи ключових фраз пов'язані, але не обов'язково близькі за інтентом.
Існує також метод «Hard» кластеризації, який вимагає зв'язку між усіма елементами всередині кластера. Недоліком цього алгоритму є те, що при його використанні виникає надмірна кількість невеликих кластерів, які можна об'єднати в більші. Високоточна «Hard» кластеризація може ігнорувати схожість між кількома групами. Таким чином, семантично близькі ключові слова, які алгоритм відокремив в поодинокі кластери, можуть бути об'єднані в ще один кластер. Інтелектуальна ієрархічна кластеризація поєднує кластери в суперкластер.
У разі присутності у списку багатозначних ключових слів, виникненні колізії, прив'язка до будь-якої групи відбуватиметься випадковим чином. Теоретично, може бути так, що той самий набір ключових слів потраплятиме у різні кластери щоразу, при новому запуску кластеризації.
При мануальному підході до кластеризації, вам потрібно розбити кожне ключове слово на терміни, визначити їх значення та скласти списки ключових слів на основі необхідних вам параметрів. При цьому, складно буде орієнтуватись у словосполученнях з різним інтентом, це також стосується омонімів та слів з широким значенням.
У цьому контексті варто виділити ключові слова, які змінили своє значення в ході історії. Фрази зі змішаним інтентом, залежно від персоналізованої видачі, а також регіональних факторів, призводять до несподіваних результатів пошуку. Приклади таких ключових слів:
- «Тесла»;
- «Корона» (як вірус, світле пиво чи програмне забезпечення);
- «Кафка» (як письменник і платформа для потокової передачі подій);
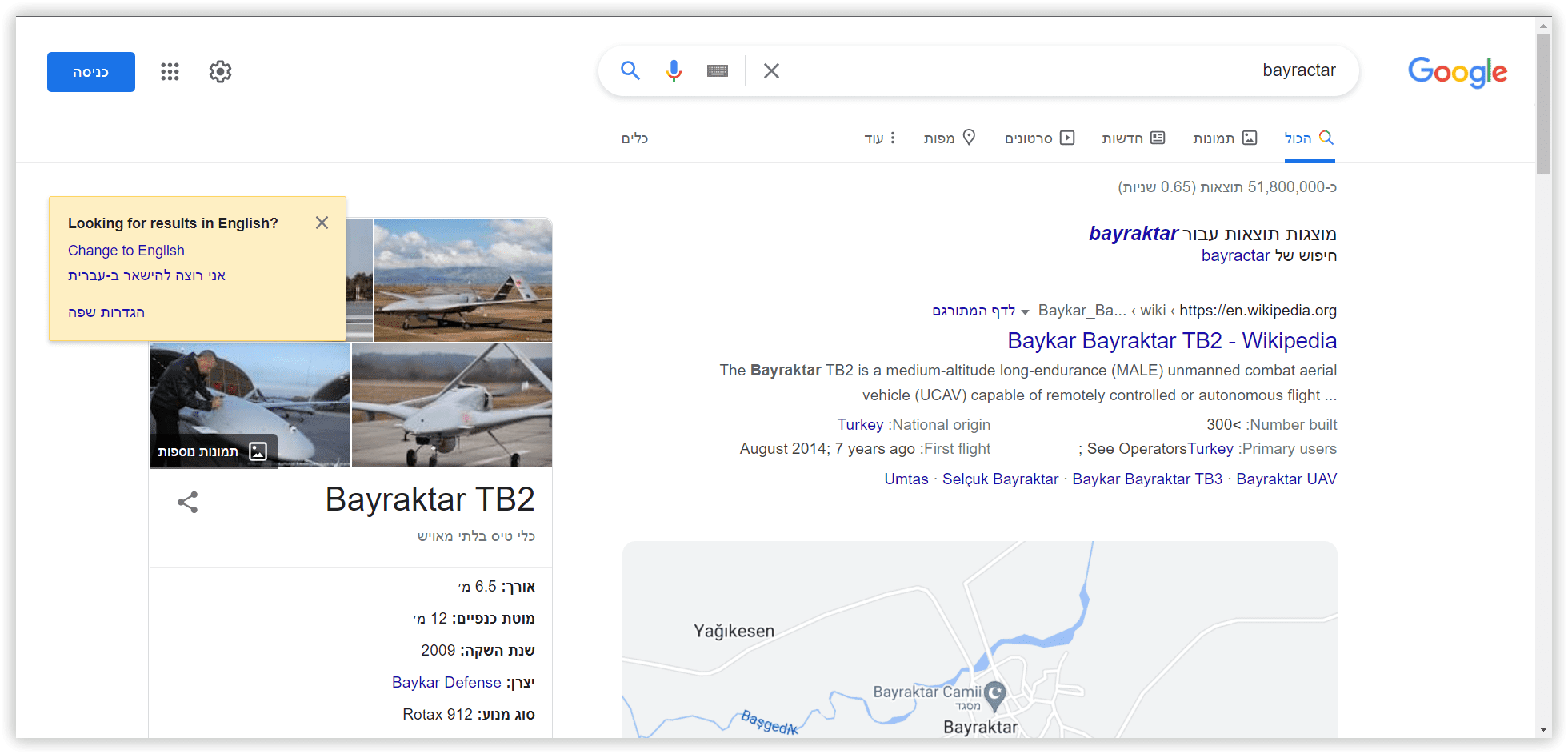
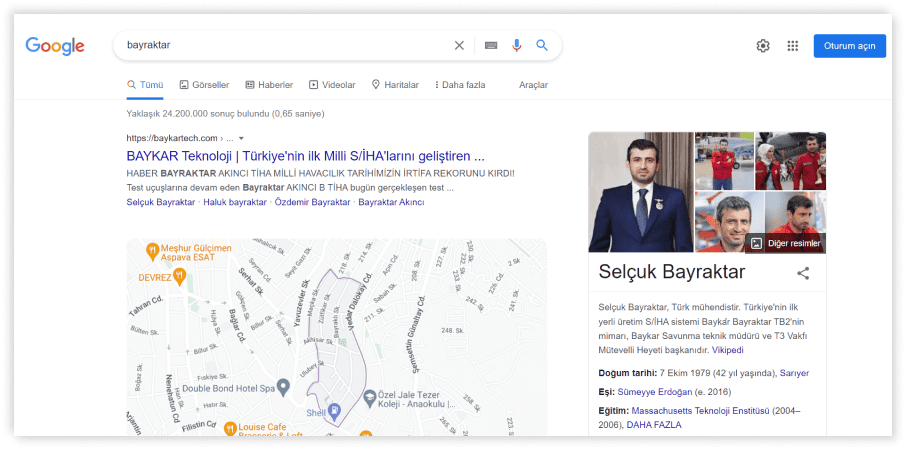
- «Байрактар» (як відомі тактичні безпілотники та турецьке прізвище, з турецького перекладається як «Той, що несе прапор»).
Алгоритми кластеризації у машинному навчанні
Кластеризація має на меті виявлення основних тем та розподілу умов пошуку на різні групи. Цей процес краще спрацює для сценарію, коли теми невідомі. Класифікація, у свою чергу, більше підійде для відомих критеріїв — розмічених даних, за якими ви хочете згрупувати терміни. Класифікація має істотну перевагу перед кластеризацією, оскільки дозволяє нам скористатися власними знаннями про завдання, яке ми намагаємось вирішити. Замість того, щоб просто дозволити алгоритму кластеризації визначити, якими повинні бути групи, ми можемо повідомити класифікатор про те, що ми вже знаємо про ці дані, наприклад їх кількість. Алгоритм класифікації спрямований на пошук найбільш цінних моделей для відбору класів.
Особливості взаємодії між комп'ютерами та людською мовою вивчаються в галузі науки, що називається Natural Language Processing (NLP, обробка природної мови). Щоб надати комп'ютерам можливість розуміти текст і мовлення майже так само, як люди, розвиваються й окремі напрямки всередині сфери AI (штучний інтелект; англ. artificial intelligence). Всі ці заходи допомагають оцінити, як програми та комп'ютери можуть обробляти та аналізувати великі обсяги даних природною мовою. Google здійснив історичне зрушення в розумінні інтенту пошуку користувача, випустивши BERT (Bidirectional Encoder Representations from Transformers), алгоритм-нейромережу з можливістю попереднього навчання.
NLP поєднує обчислювальну лінгвістику зі статистичними моделями, машинним навчанням і моделями глибинного навчання. Найкращий приклад такої моделі – Siri як частина операційної системи iOS. NLP у дії: пристрої Alexa та Google Home, автозаповнення у пошуку Google та Gmail, програмне забезпечення для мовного перекладу, перевірка орфографії та граматики, спам-фільтри, пошук та чат-боти.
Навчання з учителем (Supervised learning) — це підхід до машинного навчання, що ґрунтується на використанні розмічених наборів даних. Такі набори даних більш точно прогнозують результати. З розміченими вхідними та вихідними даними, модель може порівнювати інформацію для поступового навчання. Такий підхід містить у собі два методи: класифікацію та регресію.
При вирішенні завдань класифікації, наприклад для перерозподілу спаму в окрему папку електронної пошти, алгоритми використовуються з метою категоризації тестових даних. Лінійні класифікатори, опорні вектори, дерева рішень і випадковий ліс — це поширені алгоритми класифікації. Моделі регресійного аналізу допомагають прогнозувати, до прикладу, майбутні прибутки від продажу, ґрунтуючись на точкових даних.
У контексті машинного навчання кластеризація належить до навчання без вчителя (Unsupervised learning), система навчається самостійно і без попередньо розмічених даних. Ці алгоритми машинного навчання виявляють закономірності даних без втручання людини. Такі моделі створюються для виявлення аномалій, покращення рекомендацій, прогнозування поведінки клієнтів тощо.
Моделі навчання без вчителя використовуються для виконання трьох основних завдань: кластеризації, асоціації та зменшення розмірності. Кластеризація — це метод інтелектуального аналізу даних для групування нерозмічених даних на основі їх подібності або відмінності. Цей метод підходить як для сегментації ринку та стиснення зображень, так і для автоматизації рутинних SEO завдань. Асоціація — це метод навчання без вчителя, який використовує певні правила визначення взаємозв'язків між змінними і заданим набором даних. Ці методи часто використовуються для аналізу купівельної поведінки, створення рекомендацій та видачі товарів у категорії «Разом із цим товаром купують…». Зменшення розмірності - це метод, який використовується, коли в певному наборі даних занадто багато вимірів, наприклад, на етапі попередньої обробки, щоб видалити шум із візуальних даних та покращити якість зображення.
При вирішенні завдань класифікації, наприклад для перерозподілу спаму в окрему папку електронної пошти, алгоритми використовуються з метою категоризації тестових даних. Лінійні класифікатори, опорні вектори, дерева рішень і випадковий ліс — це поширені алгоритми класифікації. Моделі регресійного аналізу допомагають прогнозувати, до прикладу, майбутні прибутки від продажу, ґрунтуючись на точкових даних.
У контексті машинного навчання кластеризація належить до навчання без вчителя (Unsupervised learning), система навчається самостійно і без попередньо розмічених даних. Ці алгоритми машинного навчання виявляють закономірності даних без втручання людини. Такі моделі створюються для виявлення аномалій, покращення рекомендацій, прогнозування поведінки клієнтів тощо.
Моделі навчання без вчителя використовуються для виконання трьох основних завдань: кластеризації, асоціації та зменшення розмірності. Кластеризація — це метод інтелектуального аналізу даних для групування нерозмічених даних на основі їх подібності або відмінності. Цей метод підходить як для сегментації ринку та стиснення зображень, так і для автоматизації рутинних SEO завдань. Асоціація — це метод навчання без вчителя, який використовує певні правила визначення взаємозв'язків між змінними і заданим набором даних. Ці методи часто використовуються для аналізу купівельної поведінки, створення рекомендацій та видачі товарів у категорії «Разом із цим товаром купують…». Зменшення розмірності - це метод, який використовується, коли в певному наборі даних занадто багато вимірів, наприклад, на етапі попередньої обробки, щоб видалити шум із візуальних даних та покращити якість зображення.
Мета навчання без вчителя – отримати корисну інформацію з величезної кількості нових даних. При навчанні з вчителем алгоритм «навчається», роблячи прогнози на основі навчального набору даних і коригуючи їх доти, доки не отримає правильну відповідь. Хоча моделі навчання з учителем зазвичай точніші, вони вимагають прямого втручання людини і точної розмітки даних. Наприклад, модель контрольованого навчання може розрахувати, скільки часу знадобиться, щоб дістатися роботи, залежно від часу доби, погодних умов тощо.
Навчання без учителя вимагає потужних інструментів для роботи з великими обсягами некласифікованих даних. Ці моделі самостійно вивчають внутрішню структуру інформації. Однак, вони вимагають незначного втручання людини для перевірки. Наприклад, така модель неконтрольованого навчання може припустити, що покупці онлайн-магазину часто купують певні продукти одночасно, але фахівцю з обробки даних необхідно перевірити, чи має сенс групувати ці товари і виводити в рекомендації.
Повертаючись до кластеризації як методу навчання без вчителя, варто згадати, що загальноприйнятої та уніфікованої її класифікації не існує. Можна виділити кілька підходів, але деякі з них можна віднести одразу до кількох умовних груп. Методологічно такі групи мають суттєві відмінності.
Навчання без учителя вимагає потужних інструментів для роботи з великими обсягами некласифікованих даних. Ці моделі самостійно вивчають внутрішню структуру інформації. Однак, вони вимагають незначного втручання людини для перевірки. Наприклад, така модель неконтрольованого навчання може припустити, що покупці онлайн-магазину часто купують певні продукти одночасно, але фахівцю з обробки даних необхідно перевірити, чи має сенс групувати ці товари і виводити в рекомендації.
Повертаючись до кластеризації як методу навчання без вчителя, варто згадати, що загальноприйнятої та уніфікованої її класифікації не існує. Можна виділити кілька підходів, але деякі з них можна віднести одразу до кількох умовних груп. Методологічно такі групи мають суттєві відмінності.
Загальні математичні підходи
К-means
«K» — кількість кластерів, заданих для набору даних. Це означає, що перед кластеризацією ви повинні знати передбачувану кількість майбутніх груп. Цей метод можна використовувати для рекомендацій, пошуку спаму або фейкових новин. Така кластеризація використовується стрімінговим сервісом Netflix: вам надається набір фільмів та список відгуків, які дав кожен оцінювач; ваша мета — створити близько сотні груп пов'язаних фільмів. Кожна початкова точка «K» служить центральною точкою для одного з таких «K-наборів».
При використанні даного алгоритму завжди необхідно вказати приблизну кількість необхідних кластерів. Ви можете спробувати перетворити дані ключових слів на вектори, щоб дізнатися,
як цей підхід працює з ранжуванням Google для застосування в SEO.
Результат застосування K-means кластеризації на наборі даних із Serpstat, з урахуванням однорідності (10 кластерів):
«K» — кількість кластерів, заданих для набору даних. Це означає, що перед кластеризацією ви повинні знати передбачувану кількість майбутніх груп. Цей метод можна використовувати для рекомендацій, пошуку спаму або фейкових новин. Така кластеризація використовується стрімінговим сервісом Netflix: вам надається набір фільмів та список відгуків, які дав кожен оцінювач; ваша мета — створити близько сотні груп пов'язаних фільмів. Кожна початкова точка «K» служить центральною точкою для одного з таких «K-наборів».
При використанні даного алгоритму завжди необхідно вказати приблизну кількість необхідних кластерів. Ви можете спробувати перетворити дані ключових слів на вектори, щоб дізнатися,
як цей підхід працює з ранжуванням Google для застосування в SEO.
Результат застосування K-means кластеризації на наборі даних із Serpstat, з урахуванням однорідності (10 кластерів):
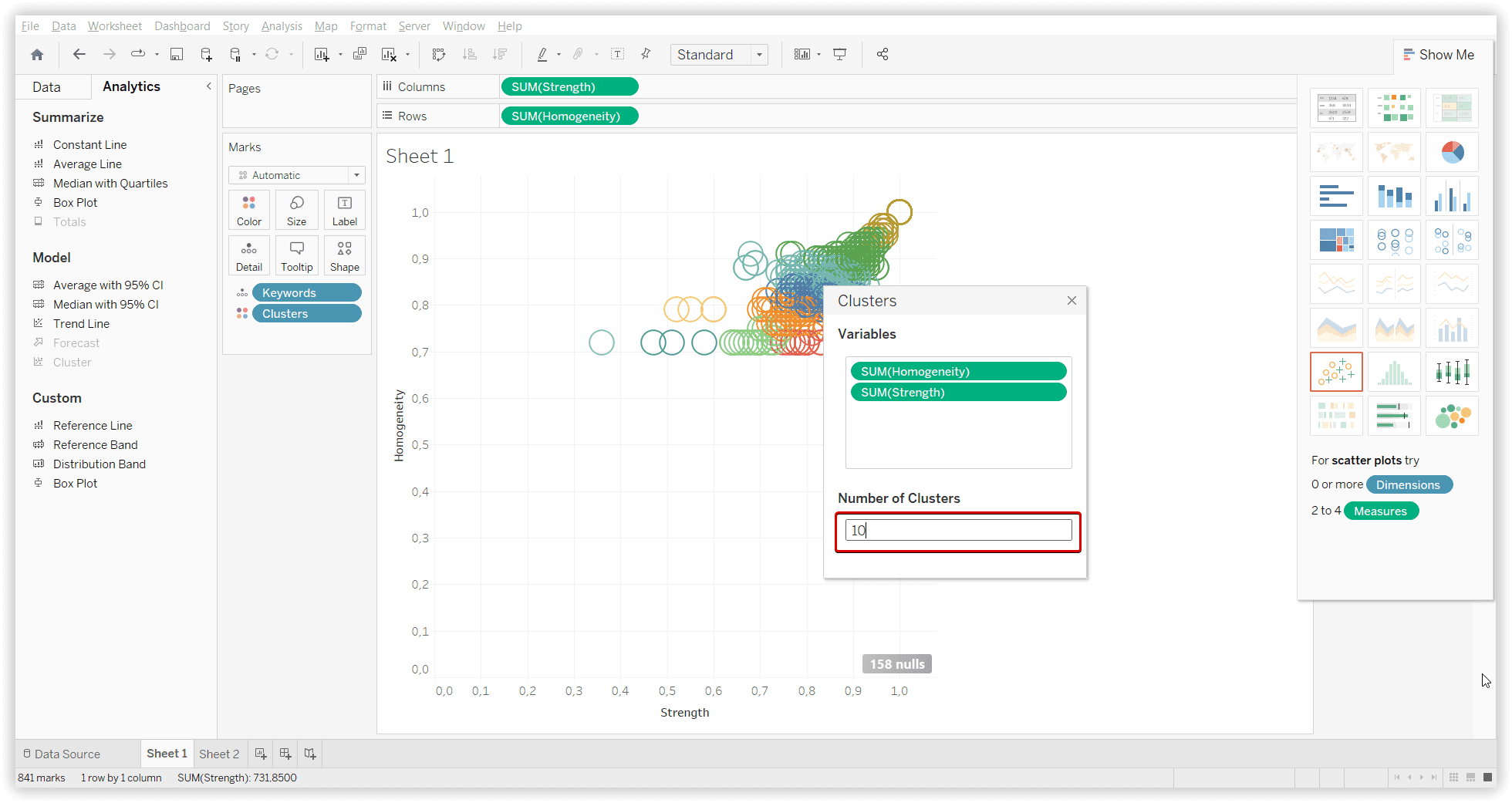
Необхідні параметри, Легенда
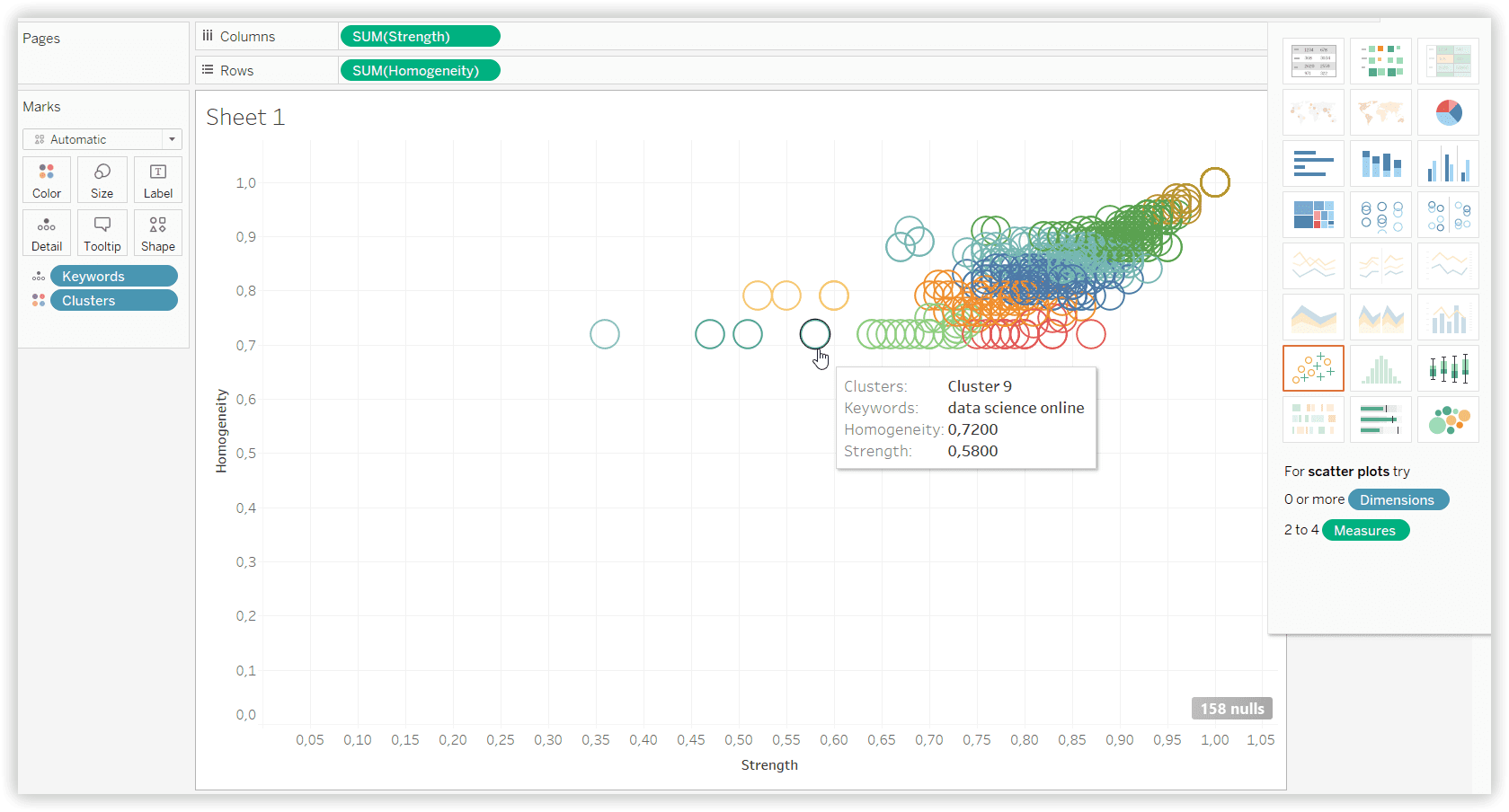
Результат застосування K-means
Підходи на основі систем штучного інтелекту
Метод нечіткої кластеризації (C-середні). За такого підходу створюють k кластерів, а потім призначають дані кожному кластеру за існуючим фактором, що визначає, наскільки сильно дані належать цьому кластеру.
Мережі Кохонена. Це приклад простих самоорганізованих нейронних мереж, які відкривають нові можливості — адаптацію до раніше невідомих вхідних даних. Такі системи характерні для нашого мозку, як спосіб навчання, коли немає певних шаблонів.
Генетичний алгоритм (GA кластеризація)— це метод, що базується на принципах генетики та природного відбору. Він часто використовується для пошуку оптимального вирішення складних проблем.
Мережі Кохонена. Це приклад простих самоорганізованих нейронних мереж, які відкривають нові можливості — адаптацію до раніше невідомих вхідних даних. Такі системи характерні для нашого мозку, як спосіб навчання, коли немає певних шаблонів.
Генетичний алгоритм (GA кластеризація)— це метод, що базується на принципах генетики та природного відбору. Він часто використовується для пошуку оптимального вирішення складних проблем.
Логічний підхід
Головний підхід такого виду – побудова дендрограми, що здійснюється за допомогою дерева рішень.
У цьому випадку дендрограма показує ключові слова за їхніми власними кластерами, починаючи з двох загальних груп, які розбиваються на дрібніші кластери з найбільш схожими ключовими словами.
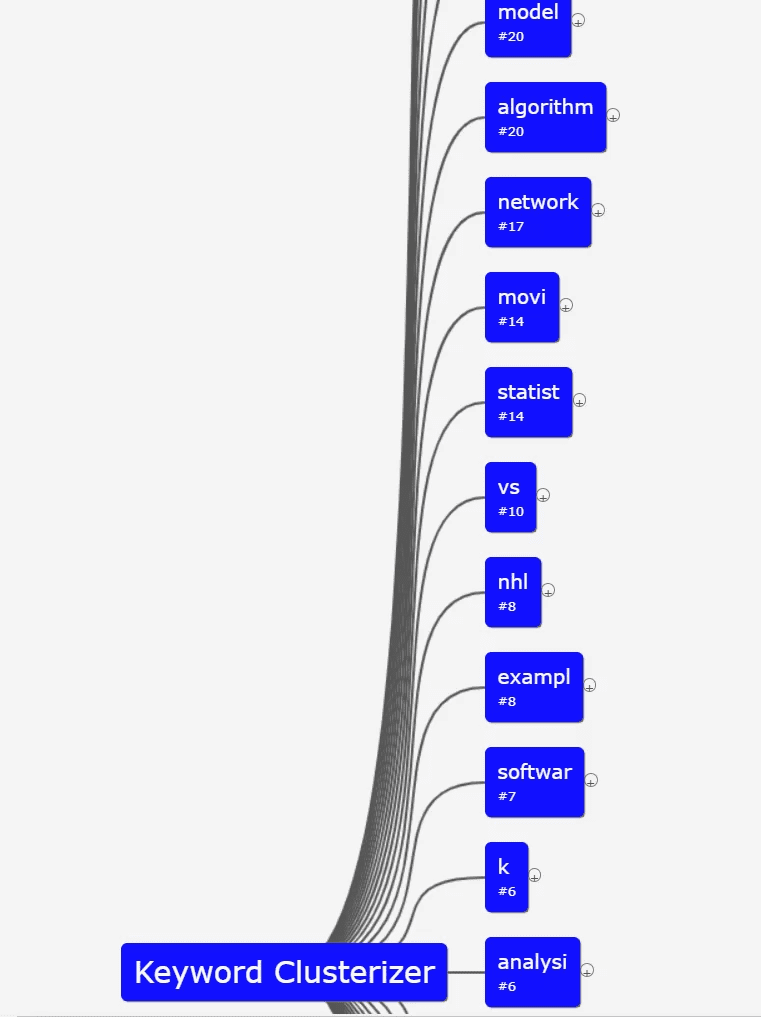
Візуалізацію такого підходу можна знайти у сервісі Keyword Cupid.
У цьому випадку дендрограма показує ключові слова за їхніми власними кластерами, починаючи з двох загальних груп, які розбиваються на дрібніші кластери з найбільш схожими ключовими словами.
Візуалізацію такого підходу можна знайти у сервісі Keyword Cupid.
Теоретико-графовий підхід
У теорії графів, розділі математики, кластер утворюється з вершин графів, де розташовані об'єкти, а ребра відповідають відстаням між цими об'єктами. За рахунок подібних характеристик і зв'язків, різні точки можуть створювати групи.
Ієрархічна кластеризація (також графові алгоритми кластеризації та ієрархічний кластерний аналіз) є набором алгоритмів для створення ієрархії вкладених кластерів. Ієрархічний підхід передбачає наявність груп з підгрупами (кластерів різного порядку). Евристичний метод включає поділ даних на групи на підставі деякої міри подібності, з можливістю подальшого звуження. Інший метод, навпаки, йде від унікальних об'єктів і послідовно поєднує ці складові у групи.
Ієрархічна кластеризація (також графові алгоритми кластеризації та ієрархічний кластерний аналіз) є набором алгоритмів для створення ієрархії вкладених кластерів. Ієрархічний підхід передбачає наявність груп з підгрупами (кластерів різного порядку). Евристичний метод включає поділ даних на групи на підставі деякої міри подібності, з можливістю подальшого звуження. Інший метод, навпаки, йде від унікальних об'єктів і послідовно поєднує ці складові у групи.
Між теперішнім на майбутнім: як штучний інтелект змінює SEO
Алгоритми кластеризації популярних SEO-інструментів
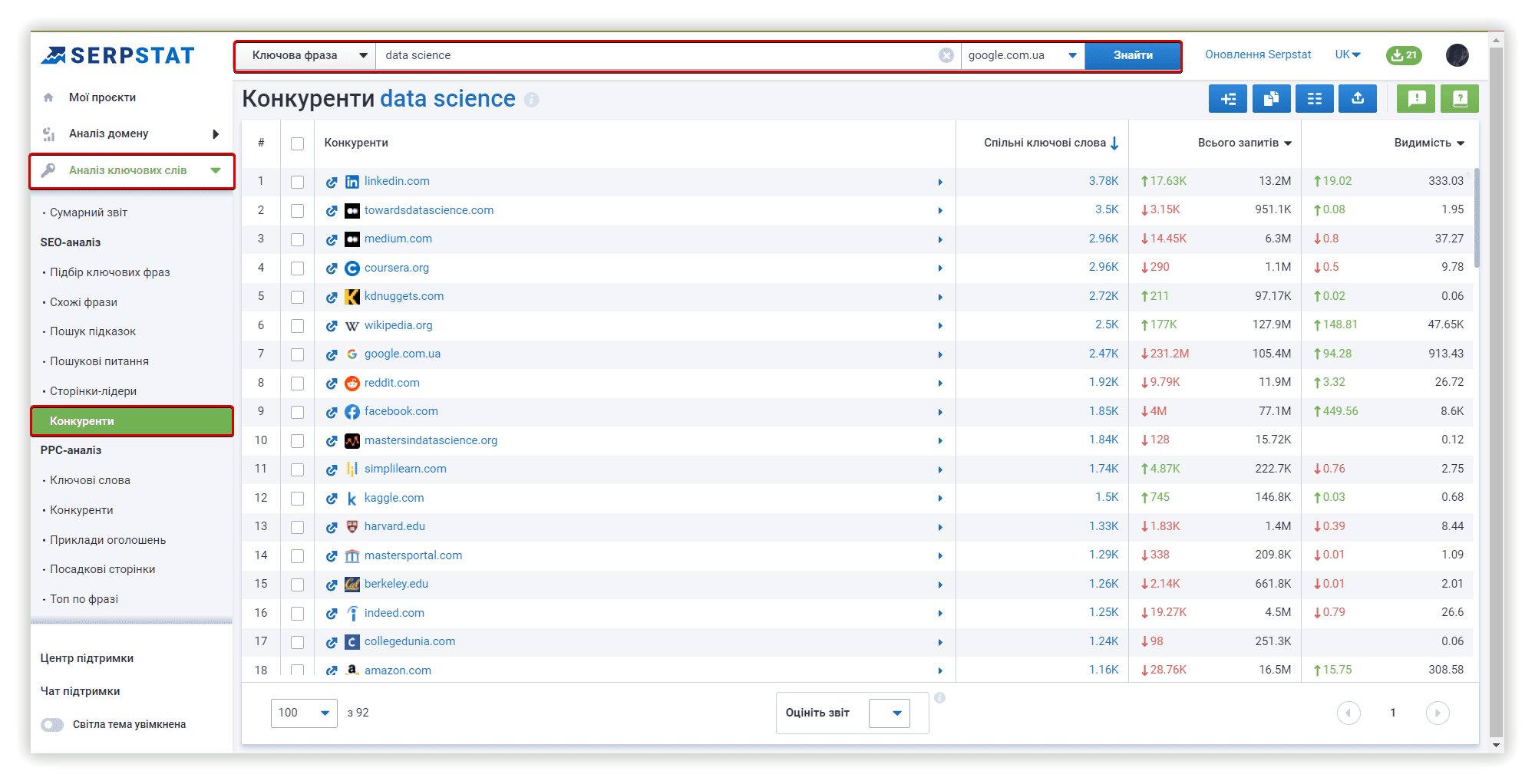
Serpstat
Більшість SEO-сервісів використовує ключові слова з найбільшою частотністю як своєрідні центроїди для кластерів, покладаючись на схожі сторінки у видачі пошукової системи. Проте Serpstat вважає такий евристичний метод неточним, оскільки, за цією логікою, для створення проєкту кластеризації буде достатньо кількох високочастотних ключових фраз. Ми використовуємо комбінацію алгоритмів, що базується на теоретико-графовому підході ієрархічної кластеризації.
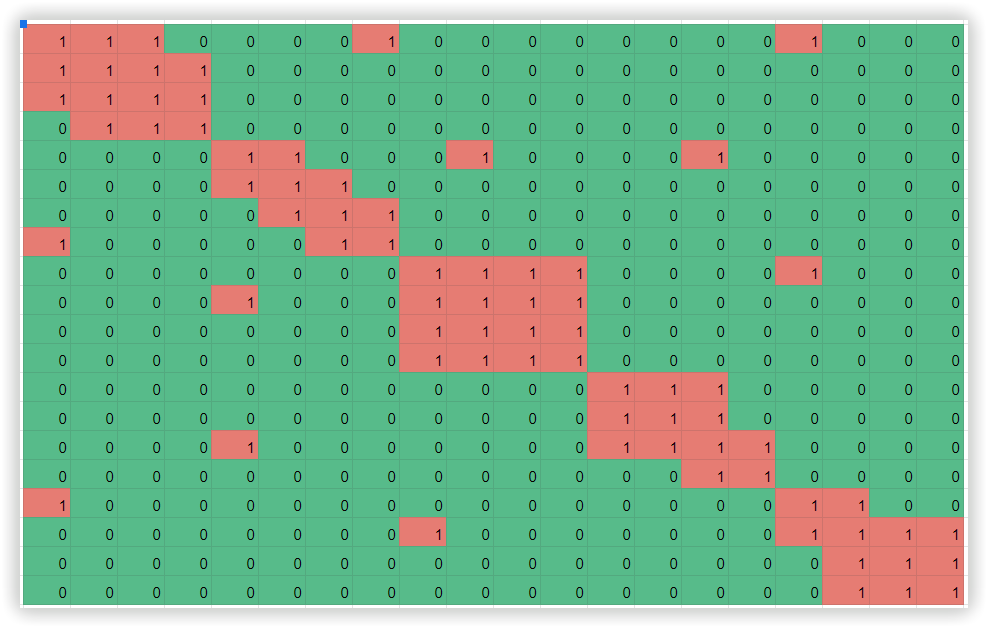
Для підрахунку ми будуємо матрицю суміжності, відповідно до кількості спільних URL-адрес для групи фраз. Припустімо, що ключове слово «неттоп» матиме ту саму кількість спільних URL у видачі, що й фраза «неттоп ігровий», таких спільних сторінок у видачі може бути 12. А ключові слова «неттоп» і «Mac Mini» матимуть лише 5 спільних URL-адрес в рамках аналізованого ТОП-30 пошукової видачі. Тепер, ми створимо матрицю так, щоб відносні числові значення були розташовані ближче один до одного. Якщо надати кожному числовому значенню колір, ми отримаємо класичну діаграму Чекановського. Приклад такої матриці:
Для підрахунку ми будуємо матрицю суміжності, відповідно до кількості спільних URL-адрес для групи фраз. Припустімо, що ключове слово «неттоп» матиме ту саму кількість спільних URL у видачі, що й фраза «неттоп ігровий», таких спільних сторінок у видачі може бути 12. А ключові слова «неттоп» і «Mac Mini» матимуть лише 5 спільних URL-адрес в рамках аналізованого ТОП-30 пошукової видачі. Тепер, ми створимо матрицю так, щоб відносні числові значення були розташовані ближче один до одного. Якщо надати кожному числовому значенню колір, ми отримаємо класичну діаграму Чекановського. Приклад такої матриці:
Список перевірених в процесі кластеризації сторінок видачі пошукової системи, можна побачити в блоку «Метатоп». Існує пряма залежність, між позицією окремих URL у метатопі на та їх релевантністю, якщо певнах сторінка знаходиться вище в метатопі, вона є більш релевантною тематиці кластера.
При використанні методу Чекановського, більш ймовірно, що досліджуваний метатоп, тобто набір URL-адрес, як демонстрація кластеру, виступатиме в ролі центроїду. Близькість ключового слова до тематики кластера розраховується з урахуванням схожості результатів пошукової видачі за ключовим словом та аналізованого метатопу. Serpstat розробив унікальний ітераційний алгоритм, що дозволяє знаходити та виправляти неточності кластеризації.
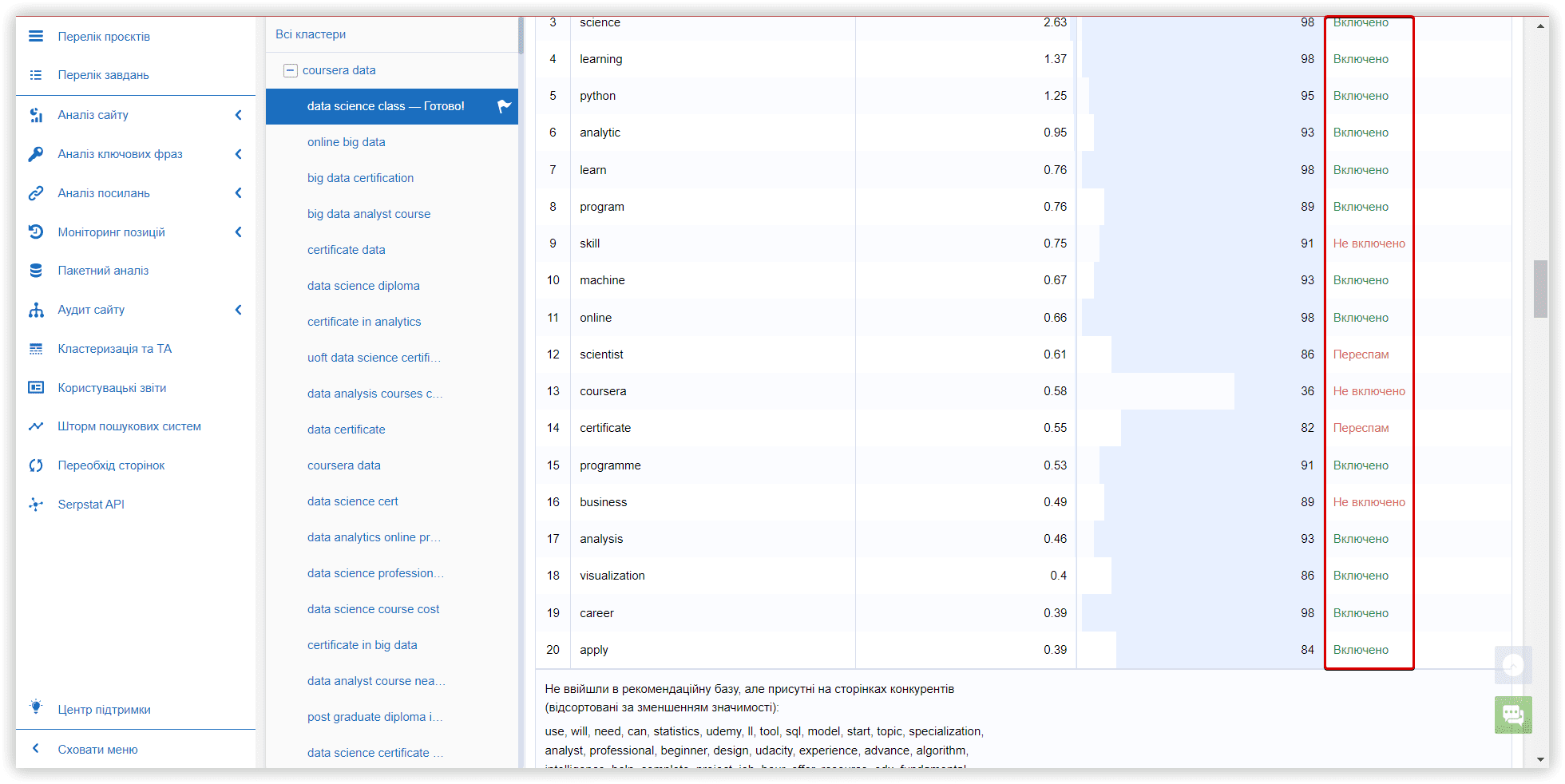
SEO-платформа використовує спеціальні метрики для опису підсумкових кластерів:
Однорідність (%) показує, як ключові слова у кластері пов'язані одне з одним. Цей показник оцінює SERP кожного ключового слова.
Сила зв'язку, за шкалою від 0 до 100, відображає схожість між метатопом та пошуковою видачею певного ключового слова (наскільки ключове слово із кластера близьке до основної тематики цого кластера).
При використанні методу Чекановського, більш ймовірно, що досліджуваний метатоп, тобто набір URL-адрес, як демонстрація кластеру, виступатиме в ролі центроїду. Близькість ключового слова до тематики кластера розраховується з урахуванням схожості результатів пошукової видачі за ключовим словом та аналізованого метатопу. Serpstat розробив унікальний ітераційний алгоритм, що дозволяє знаходити та виправляти неточності кластеризації.
SEO-платформа використовує спеціальні метрики для опису підсумкових кластерів:
Однорідність (%) показує, як ключові слова у кластері пов'язані одне з одним. Цей показник оцінює SERP кожного ключового слова.
Сила зв'язку, за шкалою від 0 до 100, відображає схожість між метатопом та пошуковою видачею певного ключового слова (наскільки ключове слово із кластера близьке до основної тематики цого кластера).
Щоб перевірити, як працюють різні підходи до кластеризації, ми проведемо Текстову аналітику в Serpstat на кластерах, які вдалося отримати за допомогою SEO-платформ, що базуються на кластеризації з SERP аналізом.
Текстова аналітика в Serpstat (ТА) - це інструмент, який допомагає підвищити релевантність контенту на основі парсингу та аналізу текстового наповнення сайтів-конкурентів із ТОП-15 видачі. Цей інструмент також фіксує входження певних ключових слів у ваш контент і дозволить зрозуміти, чи не перенасичений текст окремими фразами. Якщо ж ви не включили деякі релевантні ключові слова у свій контент, ви побачите їх в якості рекомендацій. Крім того, якщо ви прикріпили цільову сторінку до проекту ТА, у результатах можна побачити можливі технічні проблеми, які впливають на вашу оптимізацію та провести подальший аудит сторінки.
Для аналізу тексту, а також для покращеного розуміння інтенту, Serpstat використовує алгоритм TF-IDF-CDF (TF – частота слова, IDF – зворотна частота документа та наш власний показник, CDF – частота документа для кластера). Цей підхід допомагає визначити статистичні показники для ключових слів, що визначають тему для кластера:
TF — враховує кількість входжень ключового слова в текст;
IDF – контролює неінформативні ключові слова, які присутні в певному відсотку тексту, стоп-слова;
СDF — знаходить найпотужніші ключові слова для кластеру.
Завдяки Текстовій аналітиці, можна отримати найцінніші ключові слова, наприклад, для майбутньої структури сайту. Згодом, ви можете використовувати ці фрази у проєкті Моніторингу позицій та спостерігати за ефективністю просування вашого веб-ресурсу.
Щоб відстежити якість кластерів, виконаних різними інструментами, ми також порівняємо метрики з Текстової аналітики. Для чистоти експерименту один і той же набір даних, з подібними налаштуваннями кластеризації, використовується для всіх аналізованих SEO-платформ.
Текстова аналітика в Serpstat (ТА) - це інструмент, який допомагає підвищити релевантність контенту на основі парсингу та аналізу текстового наповнення сайтів-конкурентів із ТОП-15 видачі. Цей інструмент також фіксує входження певних ключових слів у ваш контент і дозволить зрозуміти, чи не перенасичений текст окремими фразами. Якщо ж ви не включили деякі релевантні ключові слова у свій контент, ви побачите їх в якості рекомендацій. Крім того, якщо ви прикріпили цільову сторінку до проекту ТА, у результатах можна побачити можливі технічні проблеми, які впливають на вашу оптимізацію та провести подальший аудит сторінки.
Для аналізу тексту, а також для покращеного розуміння інтенту, Serpstat використовує алгоритм TF-IDF-CDF (TF – частота слова, IDF – зворотна частота документа та наш власний показник, CDF – частота документа для кластера). Цей підхід допомагає визначити статистичні показники для ключових слів, що визначають тему для кластера:
TF — враховує кількість входжень ключового слова в текст;
IDF – контролює неінформативні ключові слова, які присутні в певному відсотку тексту, стоп-слова;
СDF — знаходить найпотужніші ключові слова для кластеру.
Завдяки Текстовій аналітиці, можна отримати найцінніші ключові слова, наприклад, для майбутньої структури сайту. Згодом, ви можете використовувати ці фрази у проєкті Моніторингу позицій та спостерігати за ефективністю просування вашого веб-ресурсу.
Щоб відстежити якість кластерів, виконаних різними інструментами, ми також порівняємо метрики з Текстової аналітики. Для чистоти експерименту один і той же набір даних, з подібними налаштуваннями кластеризації, використовується для всіх аналізованих SEO-платформ.
Cluster army
Cluster Army — це безкоштовний інструмент для створення кластерів на основі схожості лем ключових слів. Алгоритм намагається знайти частину слова, що відповідає за його лексичне значення. Cluster Army потрібно зробити кілька кроків для успішної кластеризації:
- Вивчити імпортований перелік;
- Знайти частотність по лемі, видалити стоп-слова;
- Знайти етимологію для кожного окремого запиту;
- Знайти відповідність для всіх пар ключів;
- Знайти відповідність для трьох запитів;
- Створити таблицю з початковим ключовим словом, повʼязаним з ним високочастотним, а згодом, і групами по 2-3 фрази;
- Зрештою, інструмент створить кластери, які ви можете використовувати у своєму проєкті.

Spy fu
Ще один приклад кластеризації, що базується на лематичній подібності. Цей підхід буде корисним для створення тематичних кластерів, підбору статей для перелінкування, сторінок, пов'язаних з основною темою. Інструмент кластеризації SpyFu працює наступним чином:
- Ви можете імпортувати свої брендові запити, а також ключі «з довгим хвостом». Spy Fu додасть у них дані, щоб отримати повну картину за тематикою.
- Потім потрібно відсортувати ключові слова, щоб побачити, як нові дані впливають на отримані результати, або фільтрувати, формуючи автоматичні групи.
- Зрештою, створюється новий список ключових слів для подальшого аналізу в інших платформах або ж у внутрішніх інструментах Spy fu.
Contadu
Це базовий інструмент групування ключових фраз, що ґрунтується на алгоритмах обробки тексту найпростішими методами.
Процес кластеризації в Contadu складається з кількох кроків:
Процес кластеризації в Contadu складається з кількох кроків:
- Збір варіантів ключових слів, базуючись на імпортованих даних.
- Перевірка частотності, трендів, CPC та значень показника конкуренції.
- Пошук результатів всіх варіантів ключових слів.
- Побудова матриці подібності між ключовими словами.
- Кластеризація на основі подібності.

Umbrellum
Цей сервіс є прикладом адаптивної ієрархічної кластеризації. Алгоритм базується на спектральній кластеризації, яка ідентифікує структуру набору даних та групує їх відповідно до ступеню подібності.
Для цього Umbrellum використовує кластеризацію з відстанню Левенштейна. Цю відстань можна розрахувати як мінімальну необхідну кількість правок, необхідну для заміни одного слова іншим. Технічно, це число відображає, наскільки відрізняються два ключових слова. Чим вище цей показник, тим більше відмінностей існує між двома запитами.
Для цього Umbrellum використовує кластеризацію з відстанню Левенштейна. Цю відстань можна розрахувати як мінімальну необхідну кількість правок, необхідну для заміни одного слова іншим. Технічно, це число відображає, наскільки відрізняються два ключових слова. Чим вище цей показник, тим більше відмінностей існує між двома запитами.
Simple SEO tool
Цей сервіс лема-кластеризації дозволяє групувати до 10 000 фраз за короткий проміжок часу. Simple SEO працює у два етапи: спочатку створюється пріоритетна група слів, потім подальша вибірка групується за семантичною подібністю.

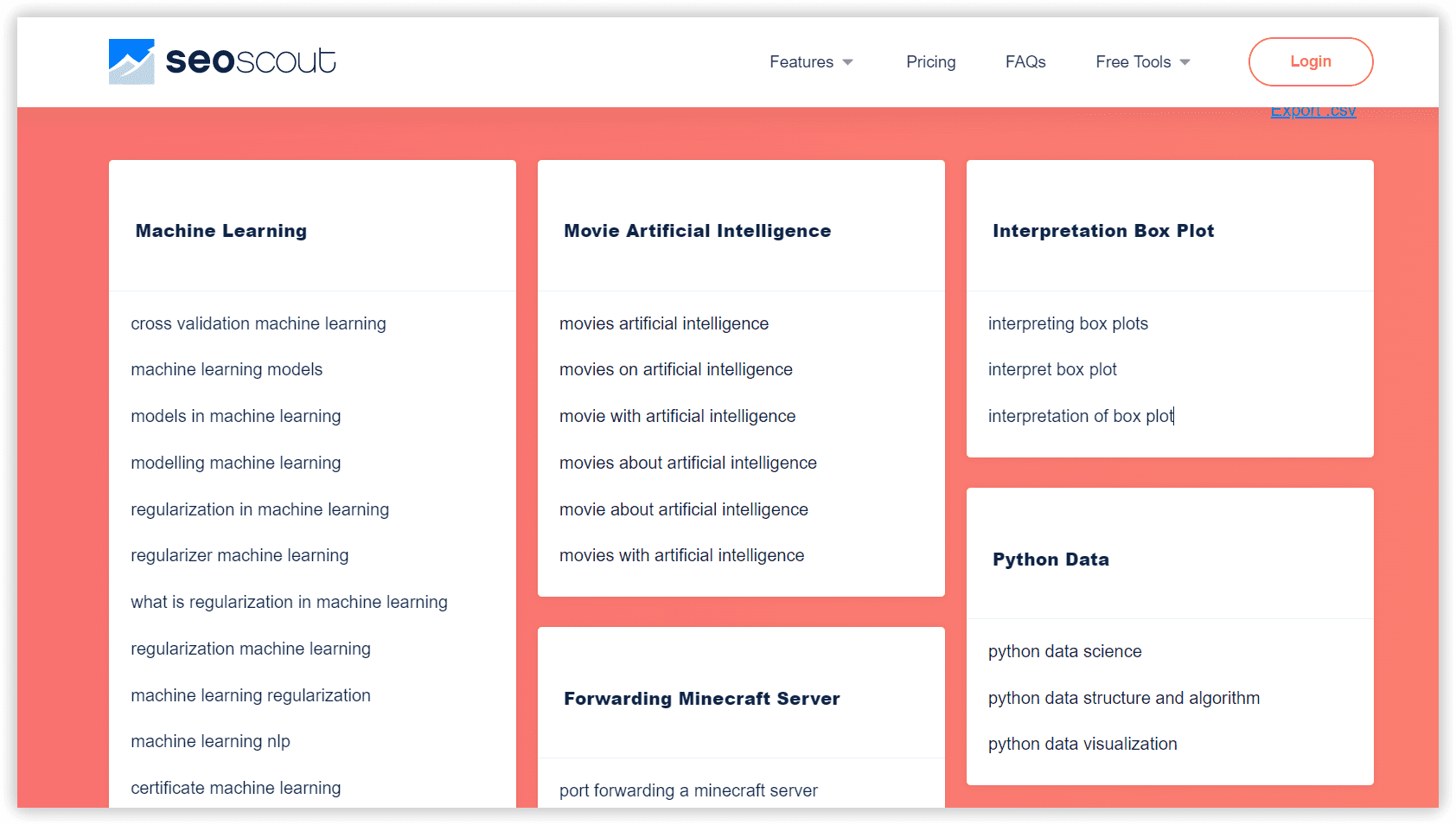
SEO Scout
Інструмент автоматично збирає запити, ключові слова та їх варіації з вашого списку та групує їх за тематичною подібністю.
В SEO Scout ви можете задавати діапазон ключових слів з довгим хвостом, що представляютимуть певну групу, а також їх мінімальну частотність. Готові групи можна переглянути та відправити копірайтеру, разом із ТЗ та варінтами запланованих публікацій.
В SEO Scout ви можете задавати діапазон ключових слів з довгим хвостом, що представляютимуть певну групу, а також їх мінімальну частотність. Готові групи можна переглянути та відправити копірайтеру, разом із ТЗ та варінтами запланованих публікацій.
Працюючи з сервісами кластеризації на основі такої семантичної подібності, потрібно враховувати важливість попередньої підготовки даних для відповідності цілям та очікуваної релевантності груп. Важливо збирати ключові слова, які приведуть на сайт користувачів, зацікавлених у ваших продуктах або послугах, запити, які позитивно вплинуть на показник конверсії.
Критерії, які ви потрібно враховувати:
- Семантична релевантність. Ключові слова у кластерах повинні мати схожий пошуковий інтент.
- Частотність та ціна за клік. Основні ключові слова в групах повинні мати високу частотність та хороший потенціал конверсії (з урахуванням CPC).
- Складність просування в органічному пошуку. Підбирайте тільки ключові слова, за якими ваш сайт має реальні шанси ранжуватися.
Наше основне дослідження буде зосереджено на алгоритмах Serpstat, Keyword Cupid та Spy SERP, які спираються на видачу пошукових систем.

Бажаєте спробувати кластеризацію Serpstat?
Зареєструйтесь та отримайте тестовий доступ до сервісу на 7 днів! Ми повідомимо про закінчення тріалу завчасно та запропонуємо можливі умови продовження роботи з сервісом:)
Зареєструйтесь та отримайте тестовий доступ до сервісу на 7 днів! Ми повідомимо про закінчення тріалу завчасно та запропонуємо можливі умови продовження роботи з сервісом:)
Персональна демонстрація
Залиште заявку, і ми проведемо для вас персональну демонстрацію сервісу, надамо пробний період і запропонуємо комфортні умови для старту використання інструменту
Як зібрати дані для свого проекту за допомогою кластеризації Serpstat?
Щоб провести кластеризацію ключових слів за тематичними групами, вам необхідно зібрати найповніший список запитів. Це перше фундаментальне завдання в процесі створення нового сайту, а також у розширенні семантики для покращення ранжування вже існуючого. Цей процес допоможе зрозуміти, що користувачі шукають у вашій ніші і як конкуренти працюють зі схожою семантикою.
Існує безліч як безкоштовних, так і платних інструментів у складі Serpstat, які допоможуть вам знайти ключові слова для вашого сайту. Використовуйте звіт Трендові запити, щоб відслідковувати актуальні тенденції та високочастотні ключі по містах або країнах.
Зверніть увагу, що існують різні типи пошукових запитів: ви можете розрізняти їх за специфічними характеристиками (наприклад, довжина, наприклад ключові слова з довгим хвостом) та за інтентом користувача (навігаційні, інформаційні, транзакційні). Комерційні та інформаційні ключі не бажано поєднувати на одній сторінці. Враховуючи інтенсивність конкуренції за певними запитами, ви зможете створити ефективне семантичне ядро.
Звіти, які ви можете використовувати для розширення та збору семантики:
Збір семантики для проекту в кластеризації ми розпочали з модуля «Пошукова аналітика» в Serpstat, подальші дії описані в покроковій інструкції.
Додаткові налаштування Кластеризації — у наступному розділі статті.
Існує безліч як безкоштовних, так і платних інструментів у складі Serpstat, які допоможуть вам знайти ключові слова для вашого сайту. Використовуйте звіт Трендові запити, щоб відслідковувати актуальні тенденції та високочастотні ключі по містах або країнах.
Зверніть увагу, що існують різні типи пошукових запитів: ви можете розрізняти їх за специфічними характеристиками (наприклад, довжина, наприклад ключові слова з довгим хвостом) та за інтентом користувача (навігаційні, інформаційні, транзакційні). Комерційні та інформаційні ключі не бажано поєднувати на одній сторінці. Враховуючи інтенсивність конкуренції за певними запитами, ви зможете створити ефективне семантичне ядро.
Звіти, які ви можете використовувати для розширення та збору семантики:
- Підбір ключових фраз ( ключові слова в органічній видачі, пов'язані з шуканою фразою),
- Схожі фрази (всі пошукові запити, семантично пов'язані з шуканим ключовим словом);
- Пошукові підказки та Пошукові питання (запити, пропоновані пошуковими системами під час пошуку, що доповнюють формулювання запиту; питання, на яке користувачі шукають відповідь з урахуванням аналізованого слова).
Збір семантики для проекту в кластеризації ми розпочали з модуля «Пошукова аналітика» в Serpstat, подальші дії описані в покроковій інструкції.
Додаткові налаштування Кластеризації — у наступному розділі статті.
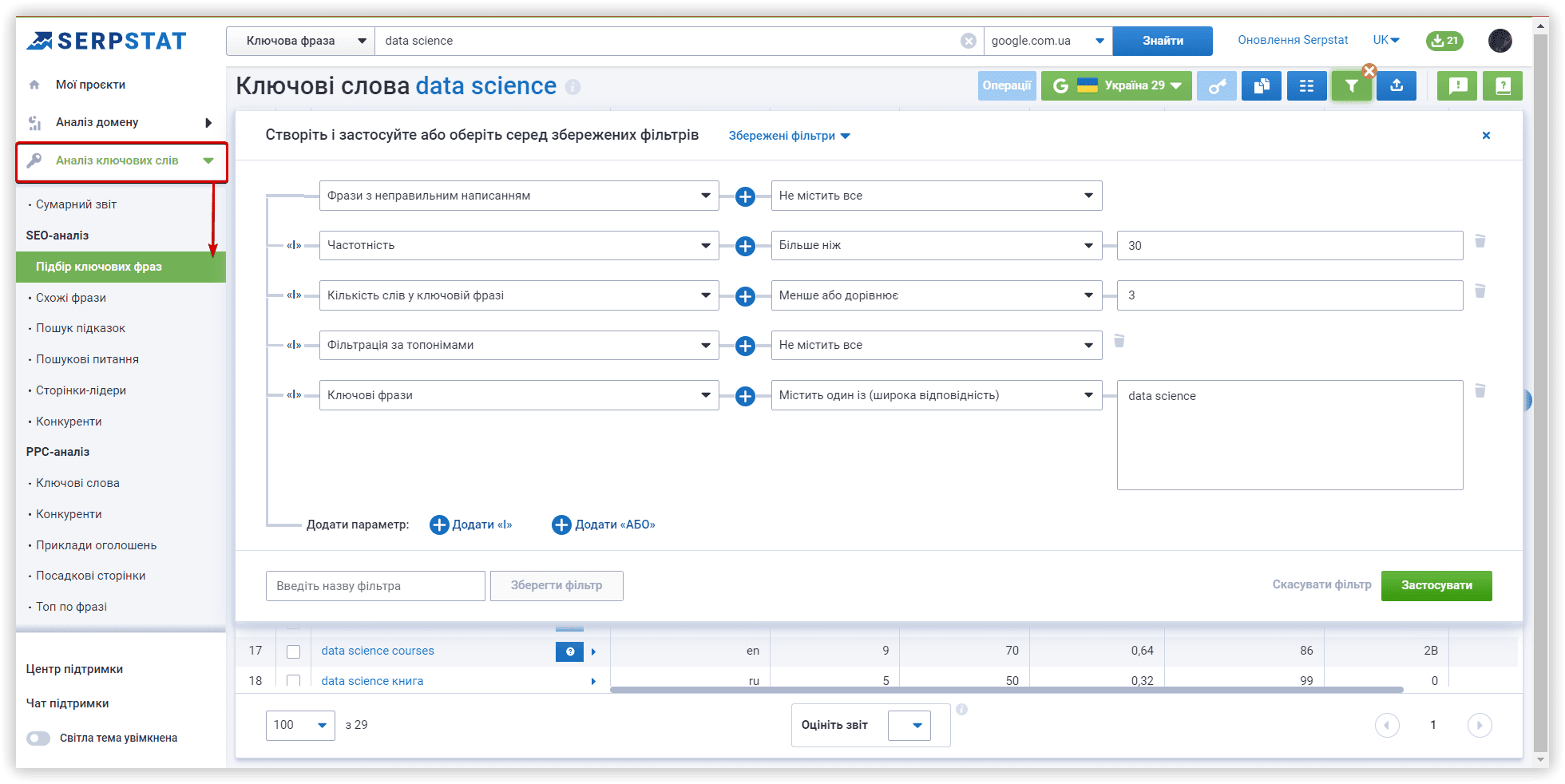
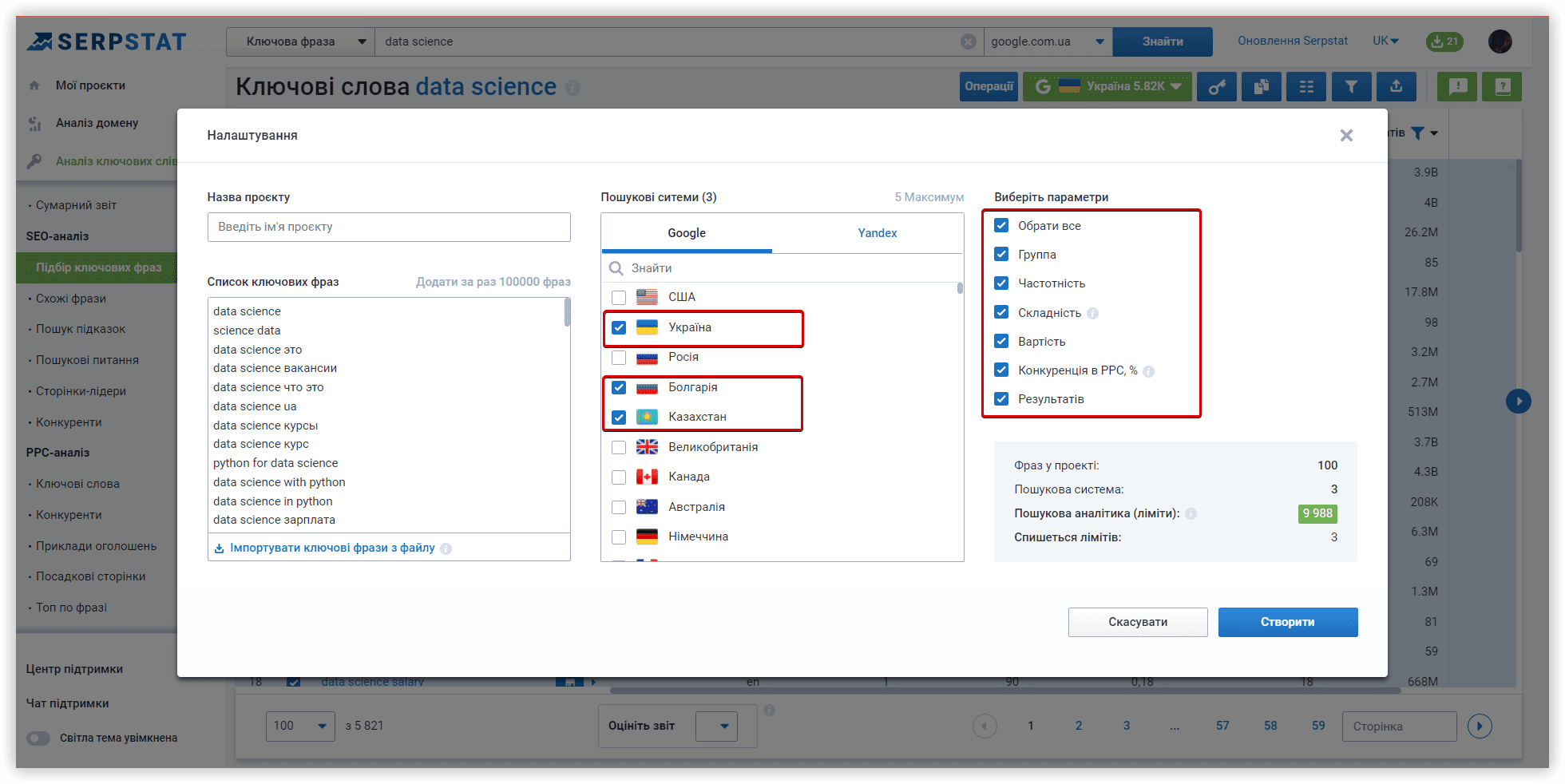
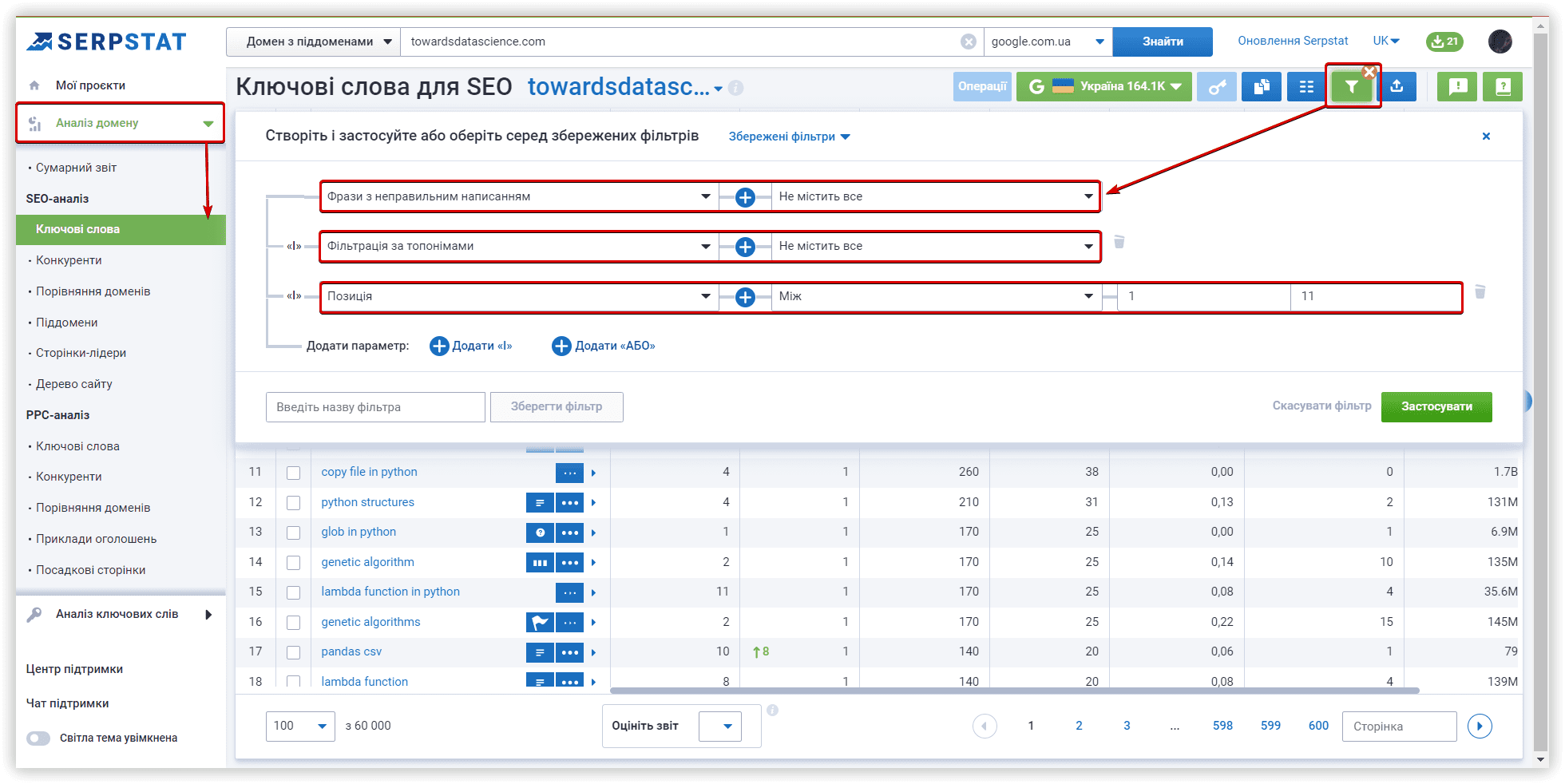
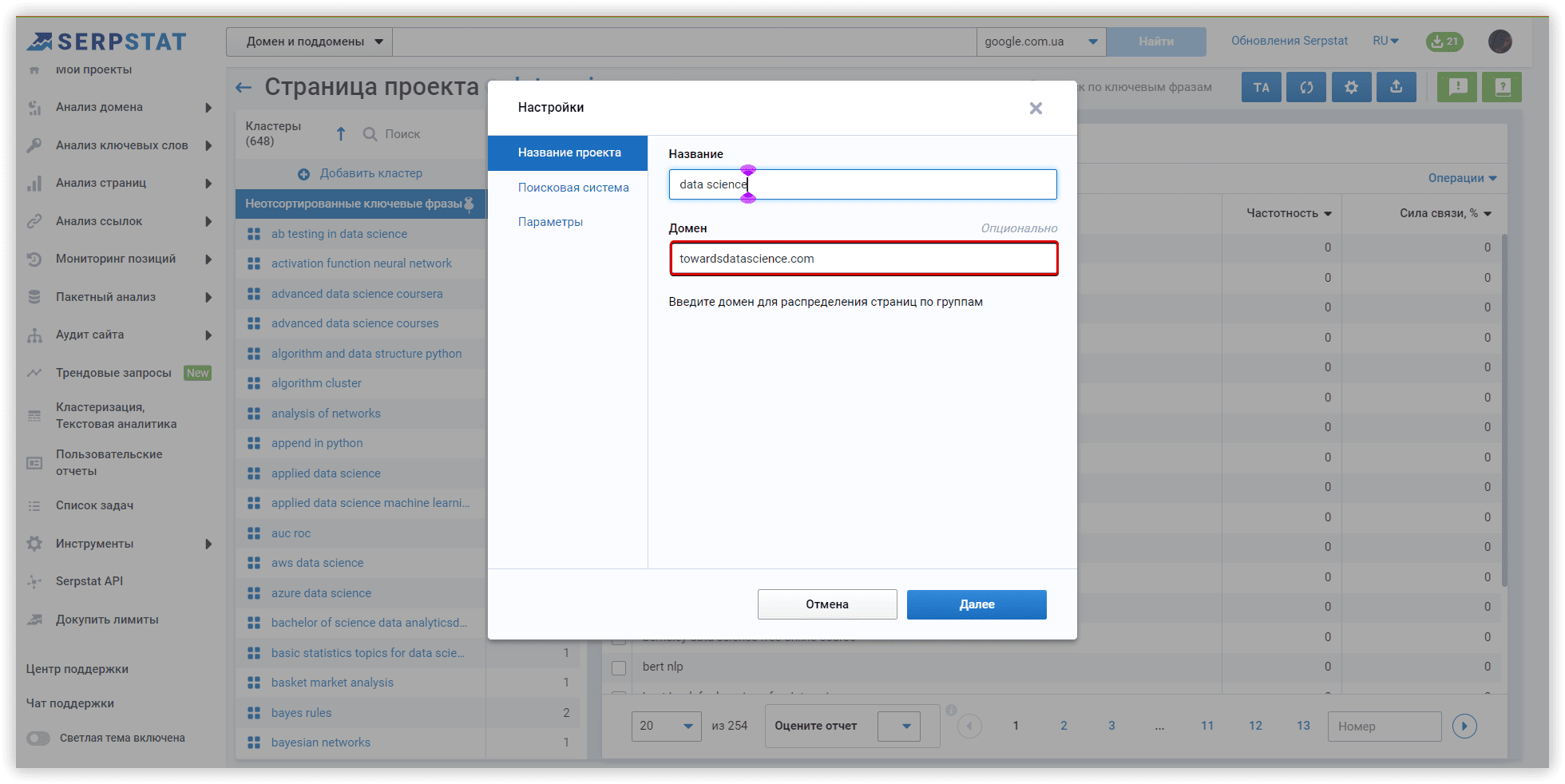
Основні налаштування кластеризації
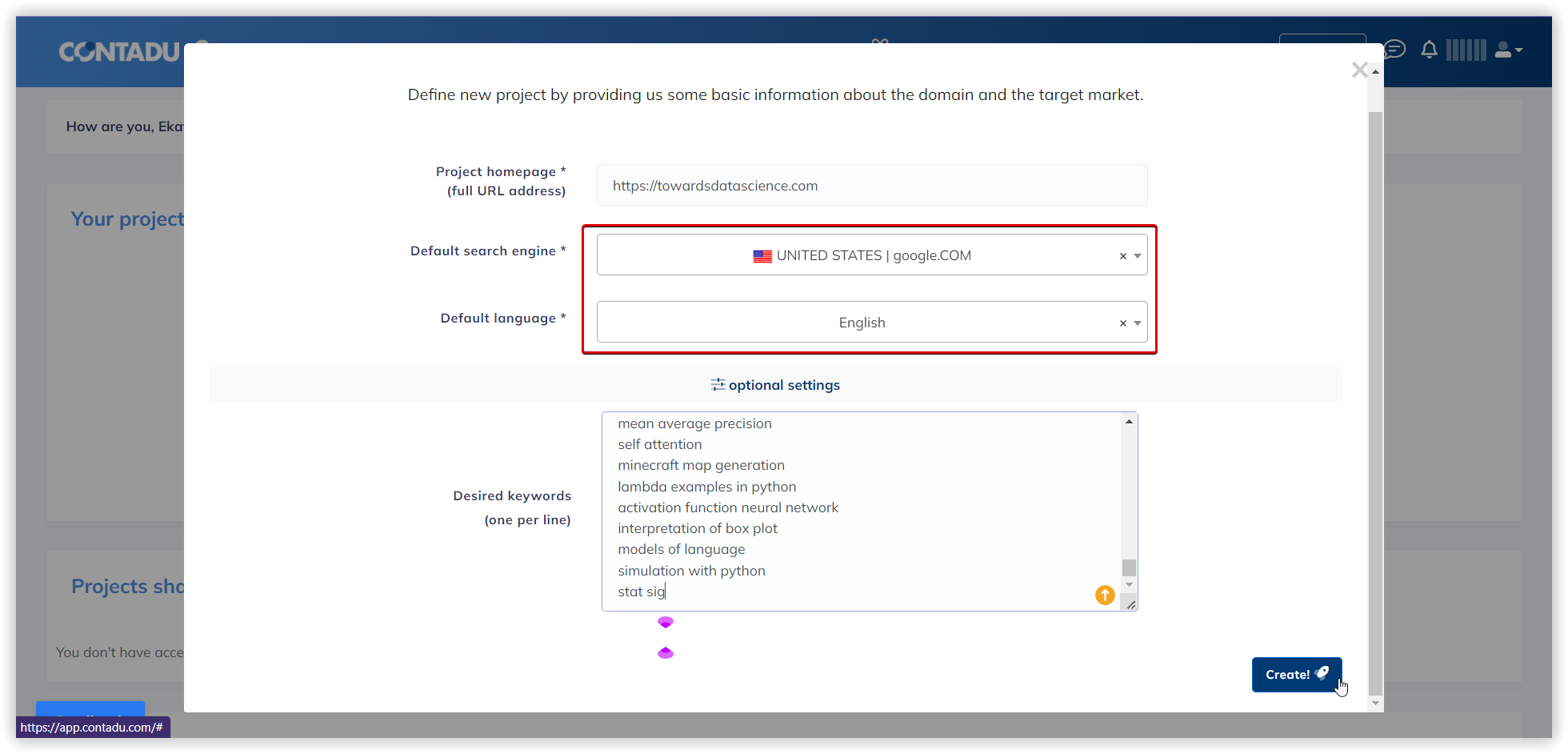
Ми будемо використовувати домен towardsdatascience.com, як цільовий, всередині основного проєкту кластеризації. Це перший етап налаштуваннь, який допоможе нам перерозподілити кластери на сторінках сайту, якщо наша мета — розширити семантику.
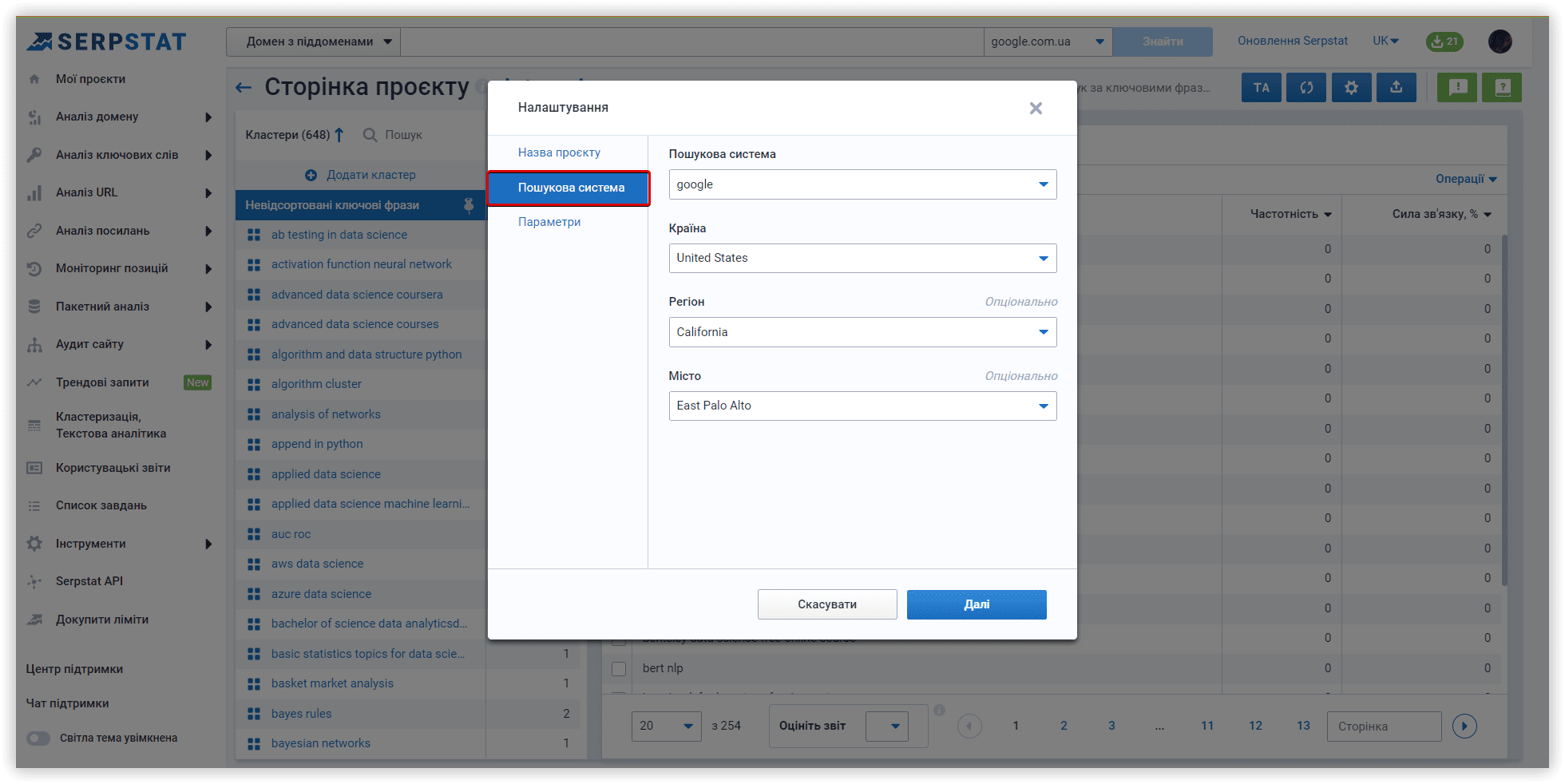
Далі, вказуємо регіон та пошукову систему для аналізу (Google/US/California/East Palo Alto):
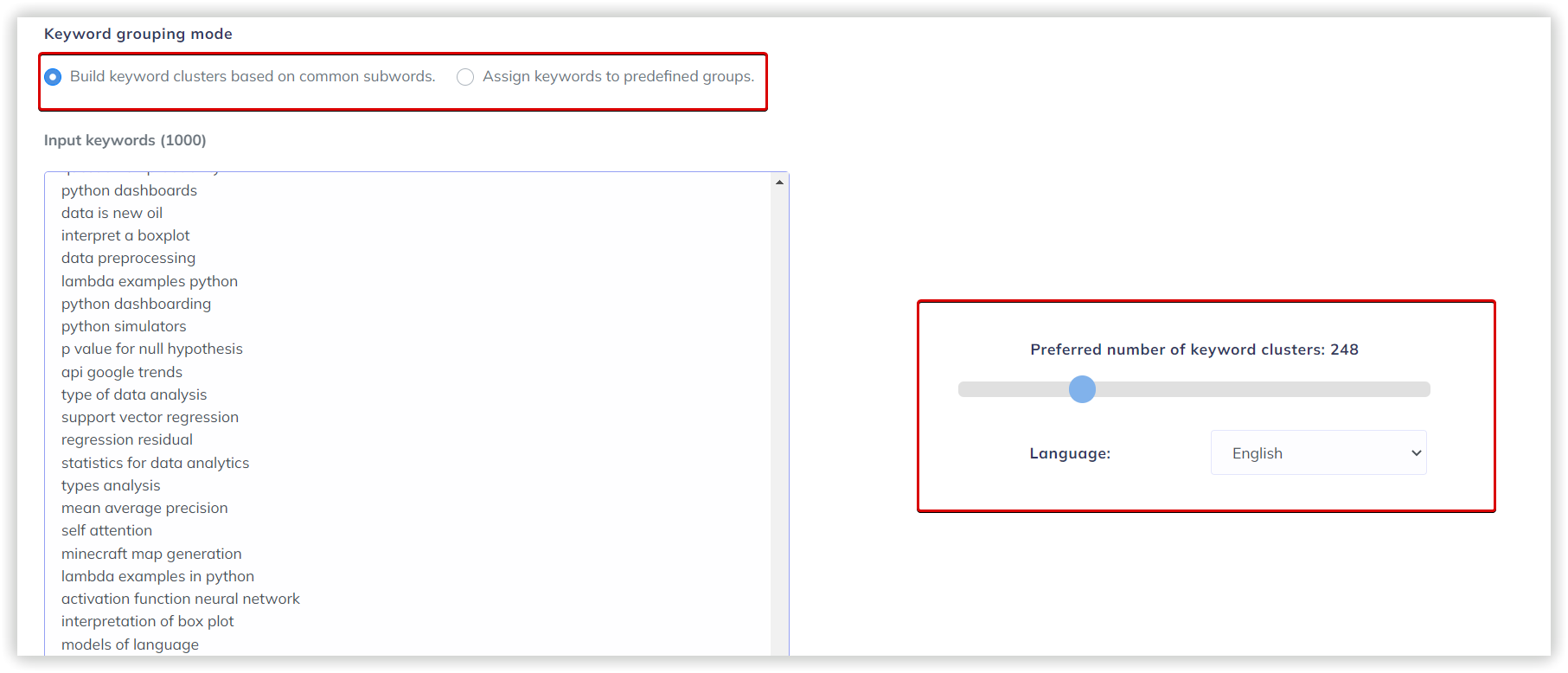
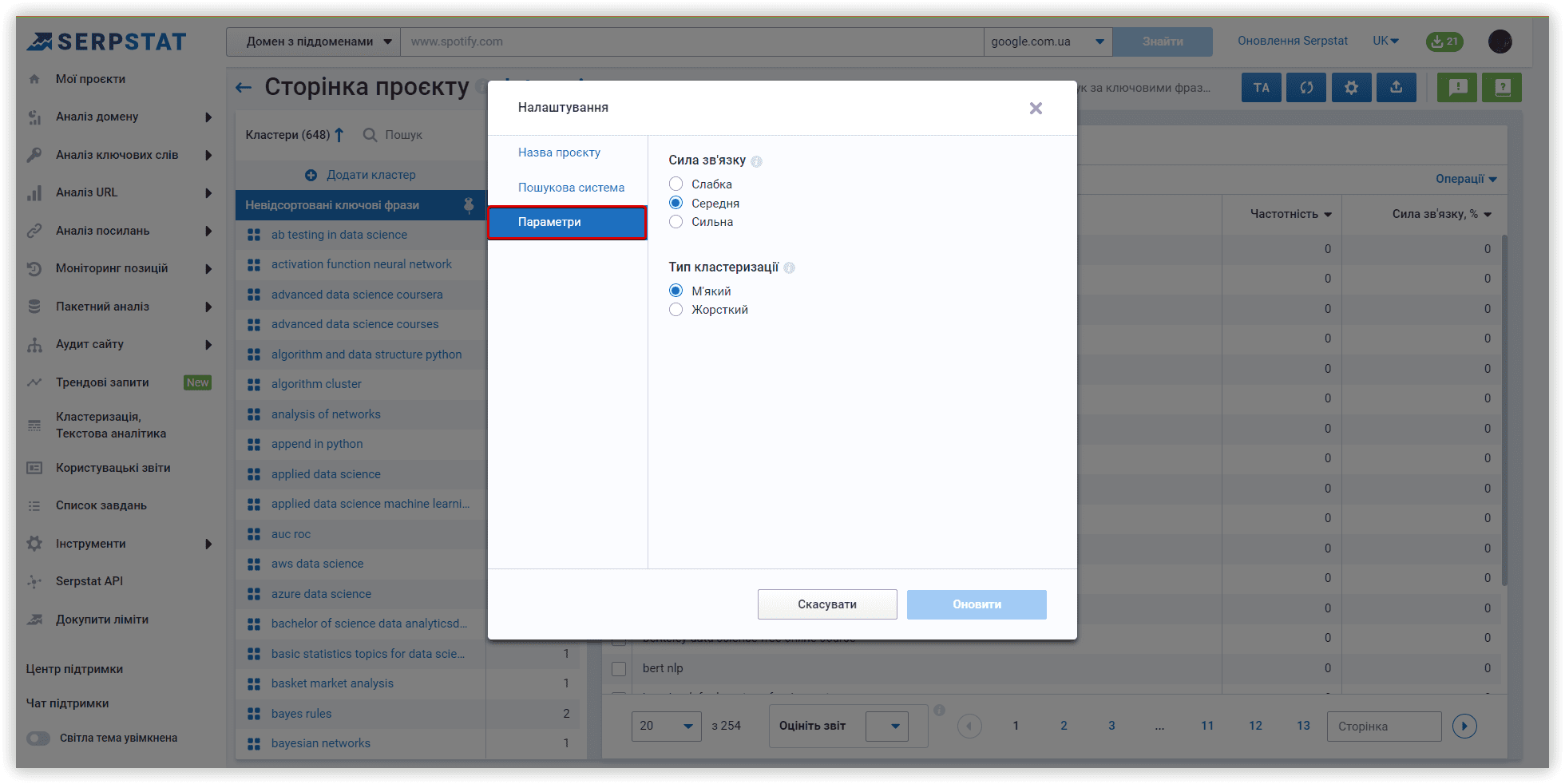
Розглянемо параметри кластеризації детальніше. Під «Силою звʼязку» мається на увазі кількість спільних URL у ТОП-30 результатів за ключовими словами. Вимоги при «Слабкій силі зв'язку» — 3 спільних URL у видачі для того, щоб фрази потрапили в один кластер, варіант для «Середньої сили зв'язку» — не менше 8 спільних URL-адрес, для «Сильної сили зв'язку» потрібно мінімум 12 спільних сторінок у видачі, щоб згрупувати ключі в одному кластері. Варто пам'ятати, що при такому налаштуванні, критерії для перебування фраз в одній групі посилюються, отже кластерів буде менше, а велика кількість ключів потрапить у невідсортовані групи.
Тип кластеризації визначає те, як ключі збиратимуться в кластер. «М'який тип» — для створення кластера нам не потрібні спільні URL-адреси для ВСІХ ключових слів у групі. Візуалізацію цього типу кластеризації можна представити так:

Якщо вам потрібні щільніші, хоч і не такі великі групи, вибирайте «Жорсткий тип». Частина запитів залишиться невідсортованою через відсутність спільних URL-адрес для об'єднання в кластер, який відповідає цим параметрам. Цей тип кластеризації можна зобразити так:

В рамках нашого огляду алгоритмів, перевіримо кластеризацію із середньою силою зв'язку та м'яким типом кластеризації. Проєкти у двох інших сервісах також запущені з аналогічними параметрами.
Якщо у вас накопичилися нові ключі для кластеризації, ви можете додати їх до запуску кластеризації, або ж зробити це пізніше і перезапустити проєкт з новими ключовими словами.
Якщо у вашому списку запитів, можуть знаходитись невалідні, рекомендуємо задіяти відровідний чекбокс:
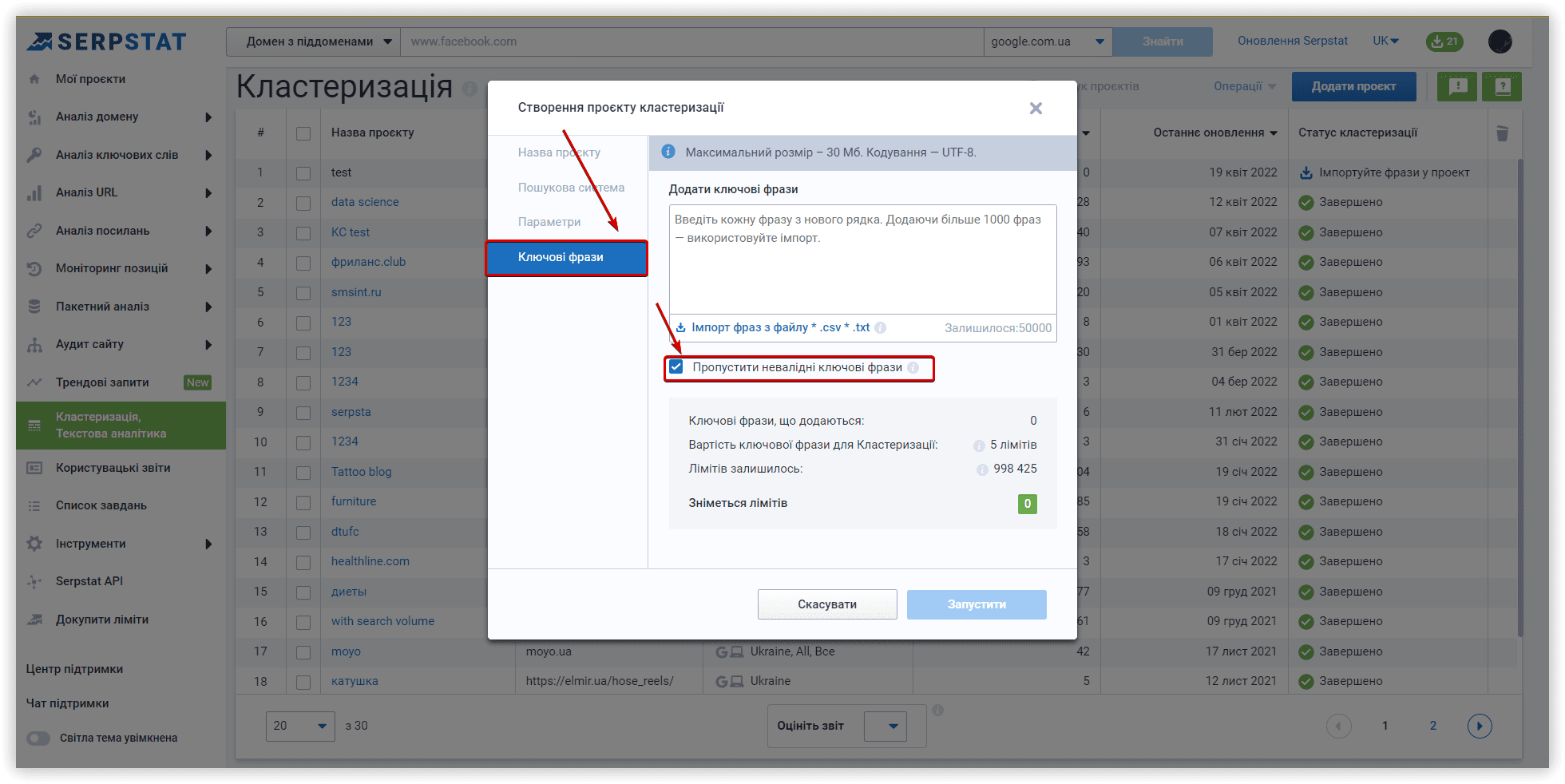
Serpstat може скластеризувати до 50 тисяч ключових слів в одному проєкті. Наявність великих окремих груп, що становлять ваше семантичне ядро, може максимізувати кількість фраз, якими ранжується ваш контент. Ви можете додати більше ключів, коли визначите кластери, які відповідають певному розділу вашого сайту чи сторінці. Вивчення вже згрупованої семантики дозволить знайти нові підходи для більшого охоплення. Таким чином, ви побудуєте свій контент, спираючись на очікування користувачів.
Тривалість кластеризації в Serpstat – від кількох хвилин до кількох годин, залежно від кількості ключових фраз у проєкті.
Візуалізацію кластеризації, яку ми отримали за допомогою Serpstat за однорідністю та розміром груп, можна зобразити так:
Тривалість кластеризації в Serpstat – від кількох хвилин до кількох годин, залежно від кількості ключових фраз у проєкті.
Візуалізацію кластеризації, яку ми отримали за допомогою Serpstat за однорідністю та розміром груп, можна зобразити так:
Наступною досліджуваною платформою кластеризації на основі SERP-ів є Spy SERP. Кластеризація у сервісі виконується у кілька етапів:
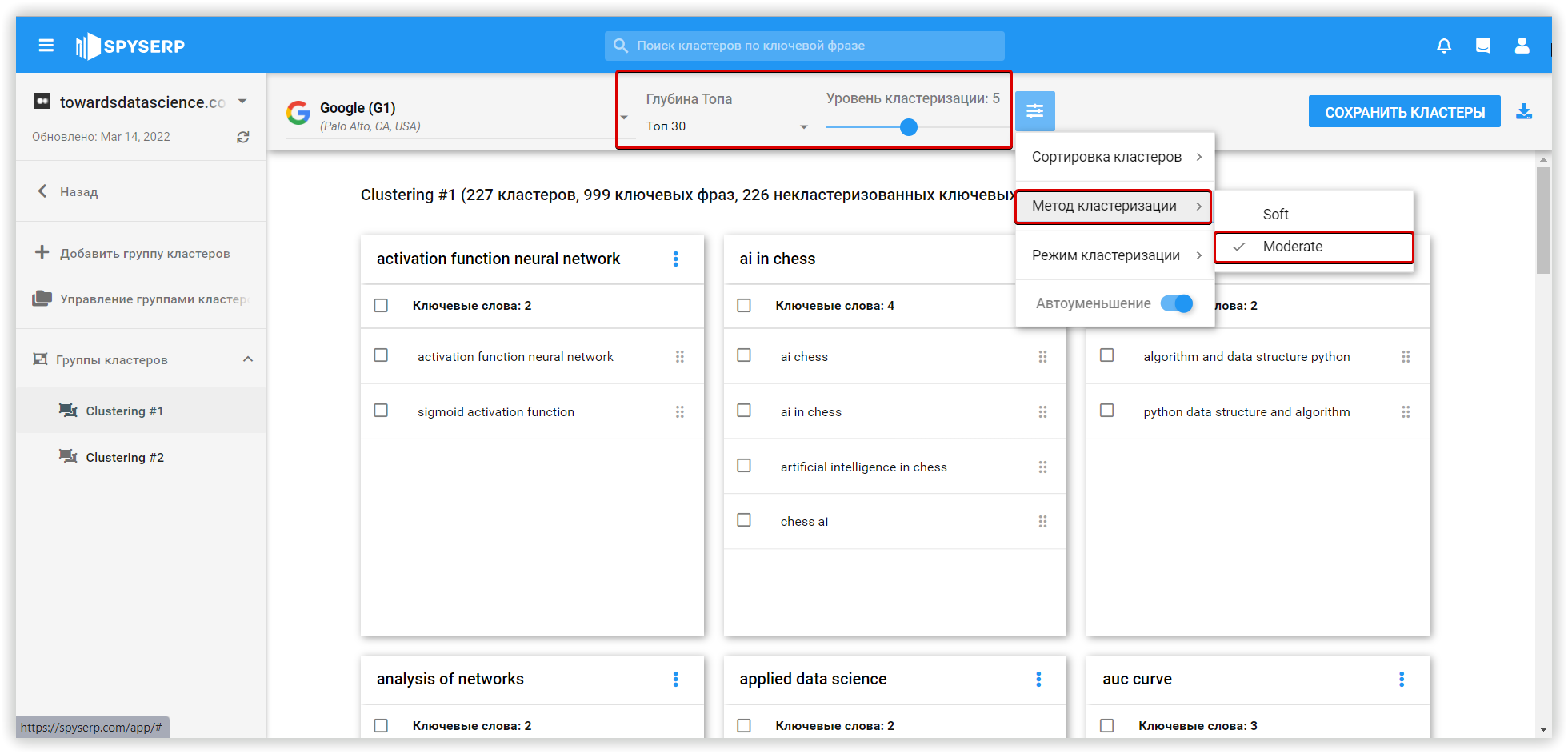
«Soft» кластеризація в Spy SERP — це тип групування ключових слів навколо кількох кластерів з урахуванням популярності ключових слів. Інший, «Moderate» варіант — результати пошуку порівнюються один з одним, моделюючи тісніші зв'язки. Цей тип ґрунтується на релевантності ключових слів.
- Запуск проекту в моніторингу позицій, щоб отримати дані безпосередньо з SERPів. Відповідно до ваших налаштуваннь, інструмент збирає дані та зіставляє сторінки з пошукової видачі за кожним ключовим словом (від ТОП-3 до ТОП-100).
- Якщо певним сторінкам присвоєно різні ключові слова, за кількома збігами — бот групує запити за цією ознакою. Є можливість встановити потужність кластеризації (мінімальна кількість збігів). Чим нижчий цей показник, тим більше кластерів буде створено.
- Якщо для ключових слів у пошуковій видачі немає збігів, вони групуються окремо.
«Soft» кластеризація в Spy SERP — це тип групування ключових слів навколо кількох кластерів з урахуванням популярності ключових слів. Інший, «Moderate» варіант — результати пошуку порівнюються один з одним, моделюючи тісніші зв'язки. Цей тип ґрунтується на релевантності ключових слів.
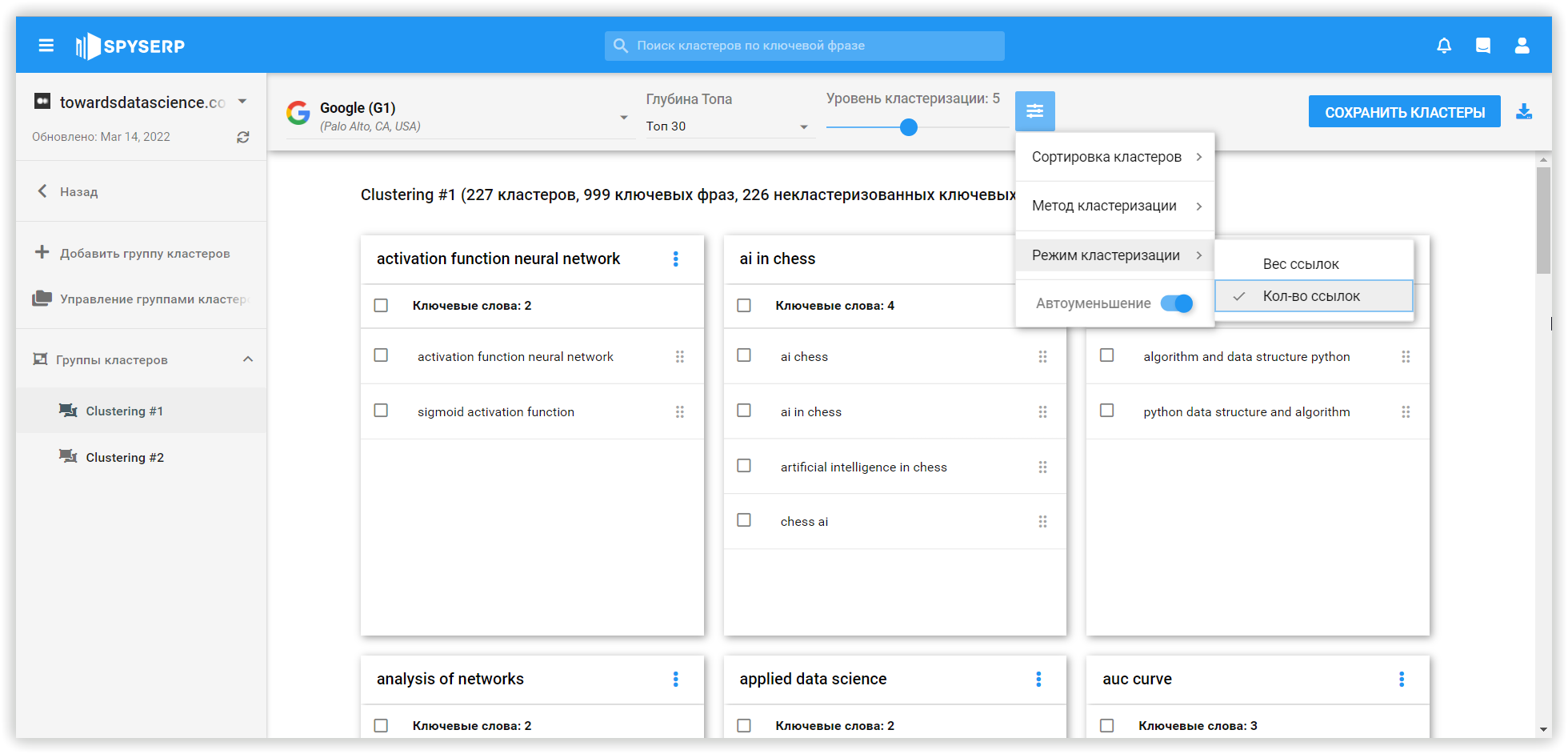
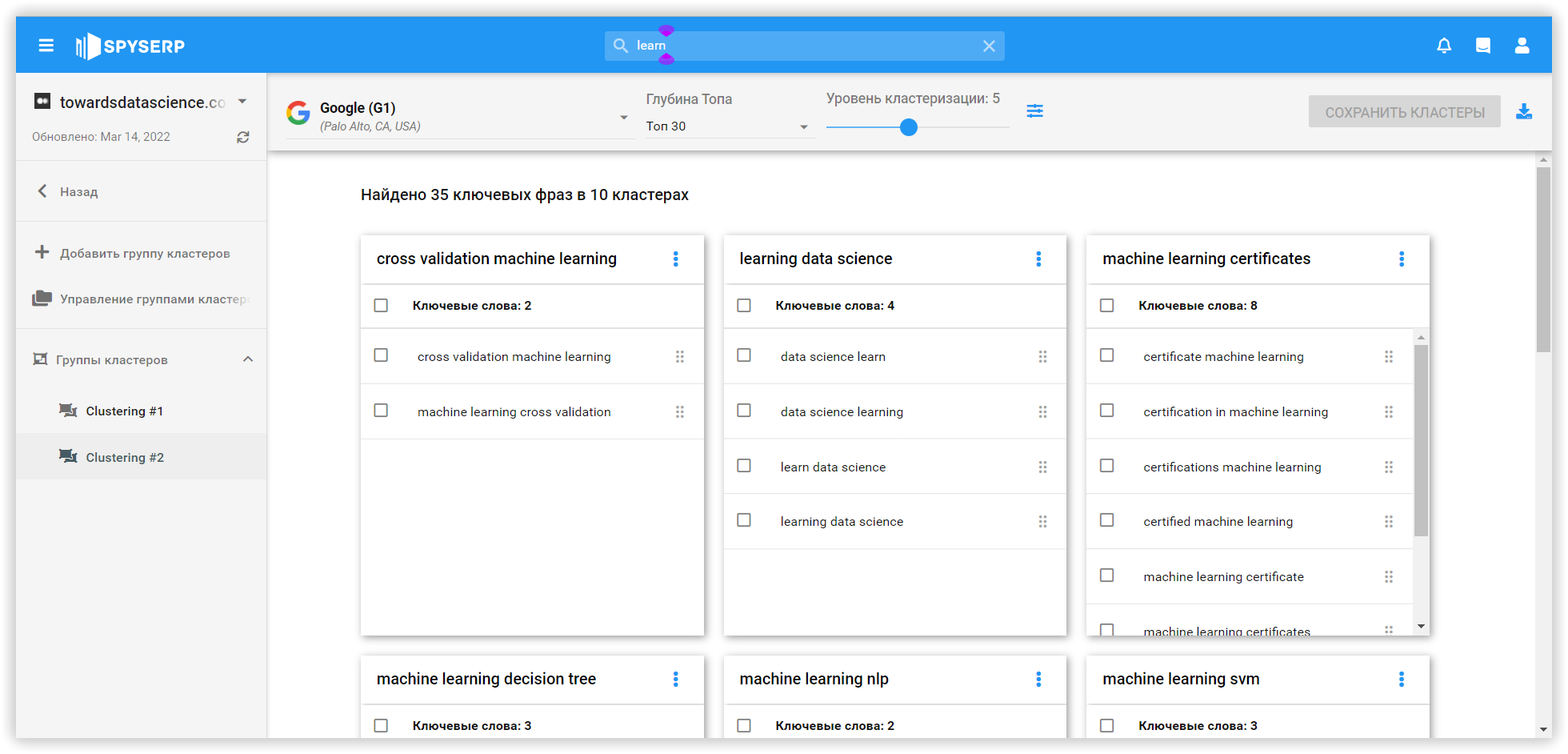
Остання платформа, яку ми порівнювали з позицій алгоритмів — Keyword Cupid. Цей SEO-сервіс аналізує перші 5-10 сторінок Google (налаштування залежить від ніші та кількості очікуваних результатів у видачі). Так, алгоритм Keyword Cupid створює своєрідну площину, щоб зрозуміти, наскільки тісно пов'язані аналізовані ключові слова. Логічно припустити, що надавати більше значення варто збігам на 1 сторінці, а не на 5-й.
Підхід сервісу унікальний через використання двох видів програмованих нейронних мереж. Перша мережа фокусується на угрупованні імпортованих ключових слів у дуже тісні тематичні кластери, щоб гарантувати, що подальше угруповання буде коректним у разі виникнення колізій.
Друга нейронна мережа фокусується на угрупованні створених кластерів і використовує набір певних правил, щоб забезпечити «гнучкіші» зв'язки.
Keyword Cupid не використовує алгоритм NLP, TF-IDF або показники релевантності кластеризації. Крім того, сервіс не рахує посилання, що відповідають за «тісність зв'язків» у кластері. Якщо Google випустить апдейт, що покращує попадання в інтент у видачі, результати кластеризації також покращуються. Назва кластеру служить розміткою для групи результатів, що використовується як центр всередині вузла (блоку або теми).
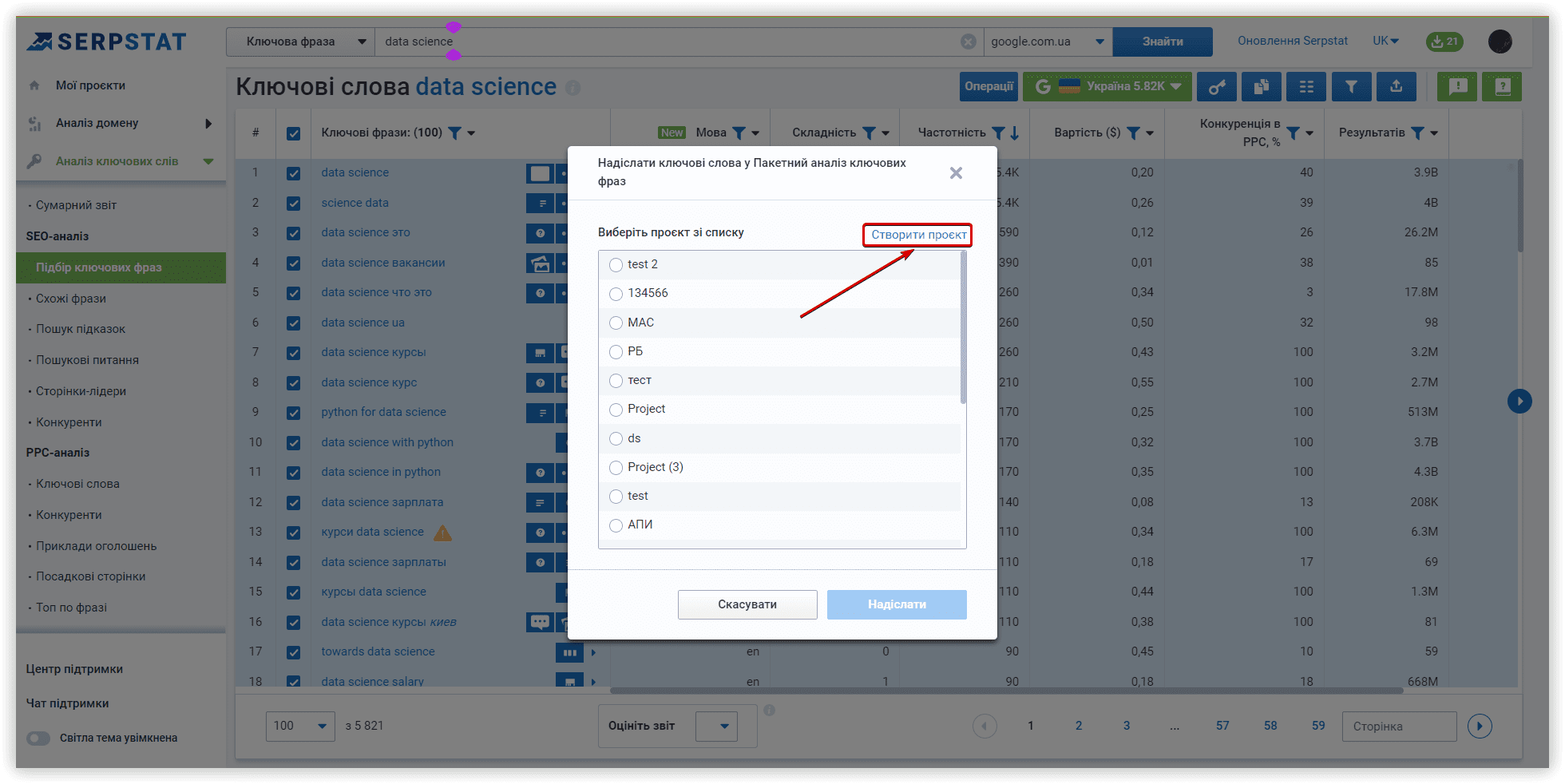
Щоб розпочати кластеризацію даних у Keyword Cupid, потрібно підготувати файл з основними показниками за ключами: складністю (KD), вартістю за клік (CPC) та частотністю. У цьому вам знову допоможе Пакетний аналіз ключових фраз.
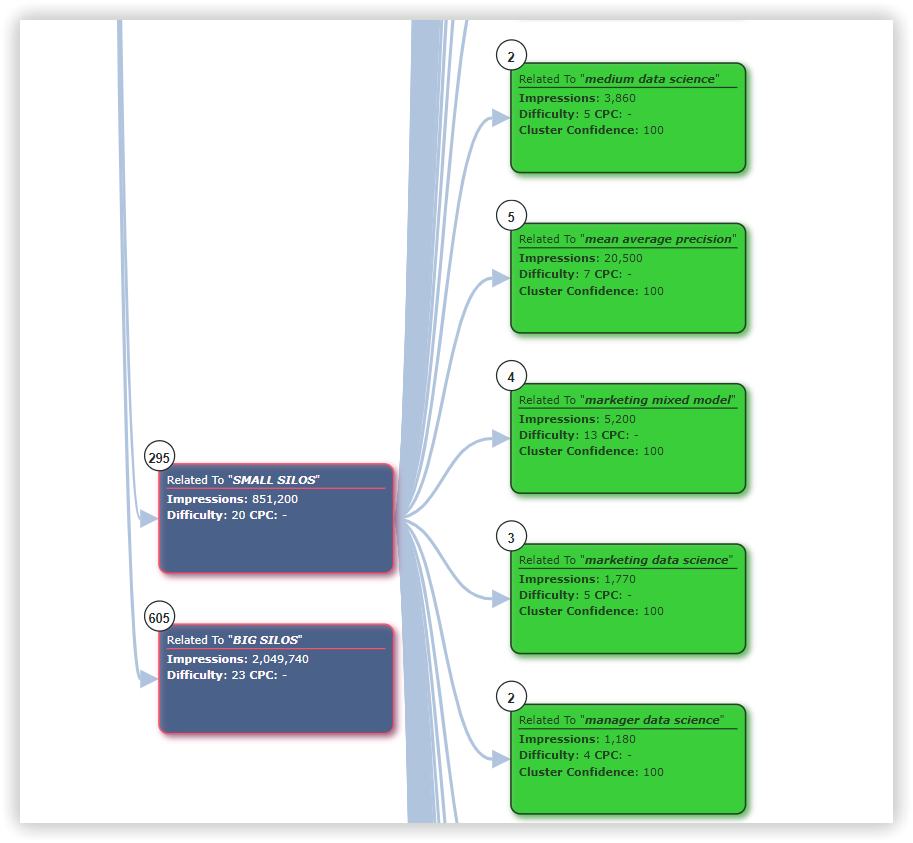
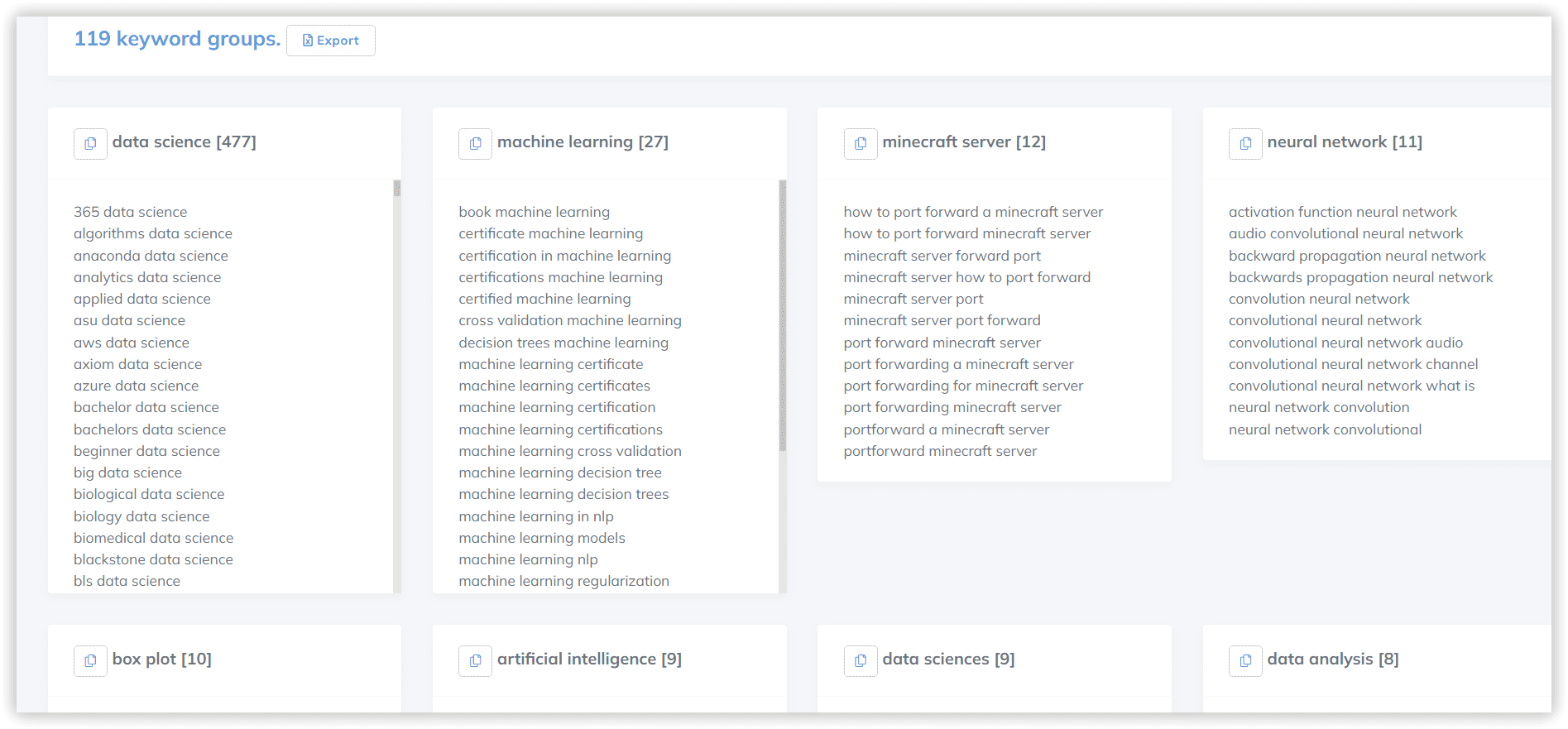
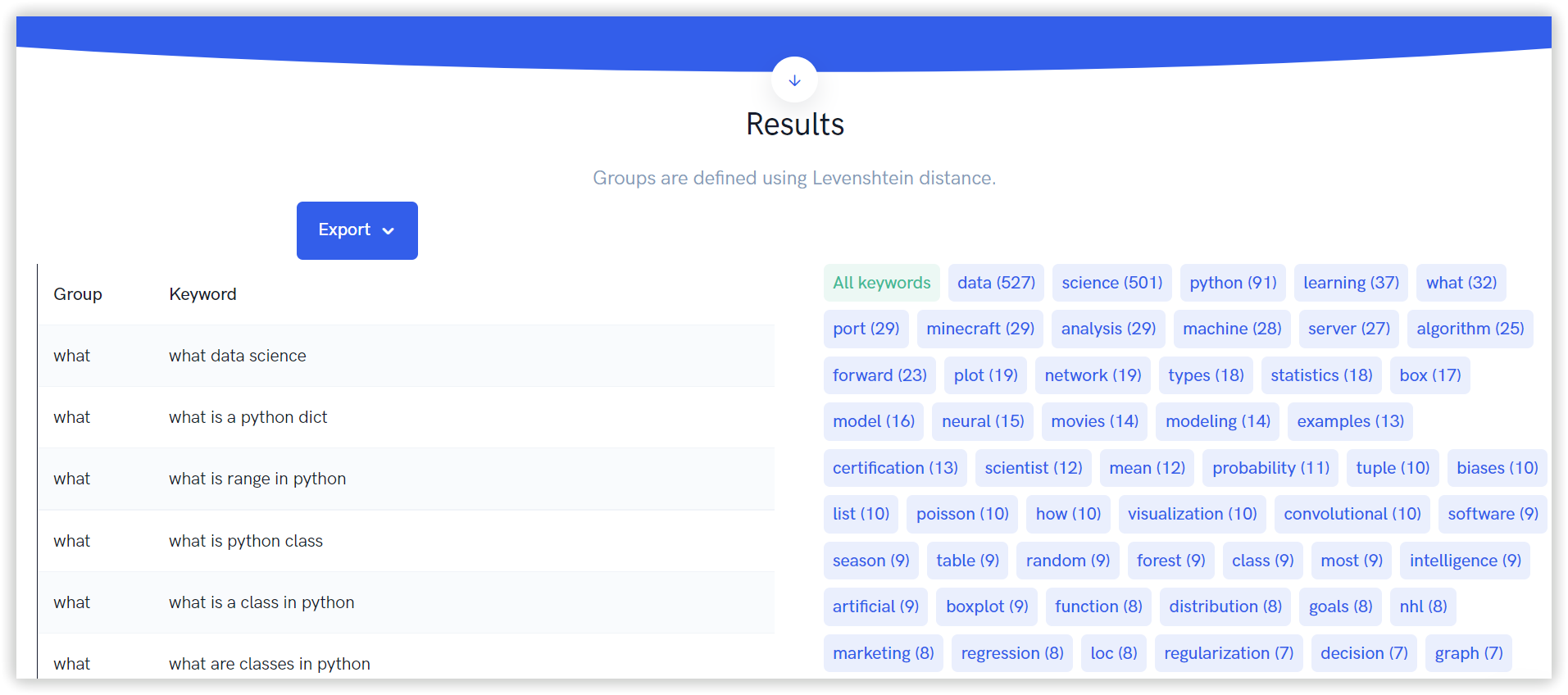
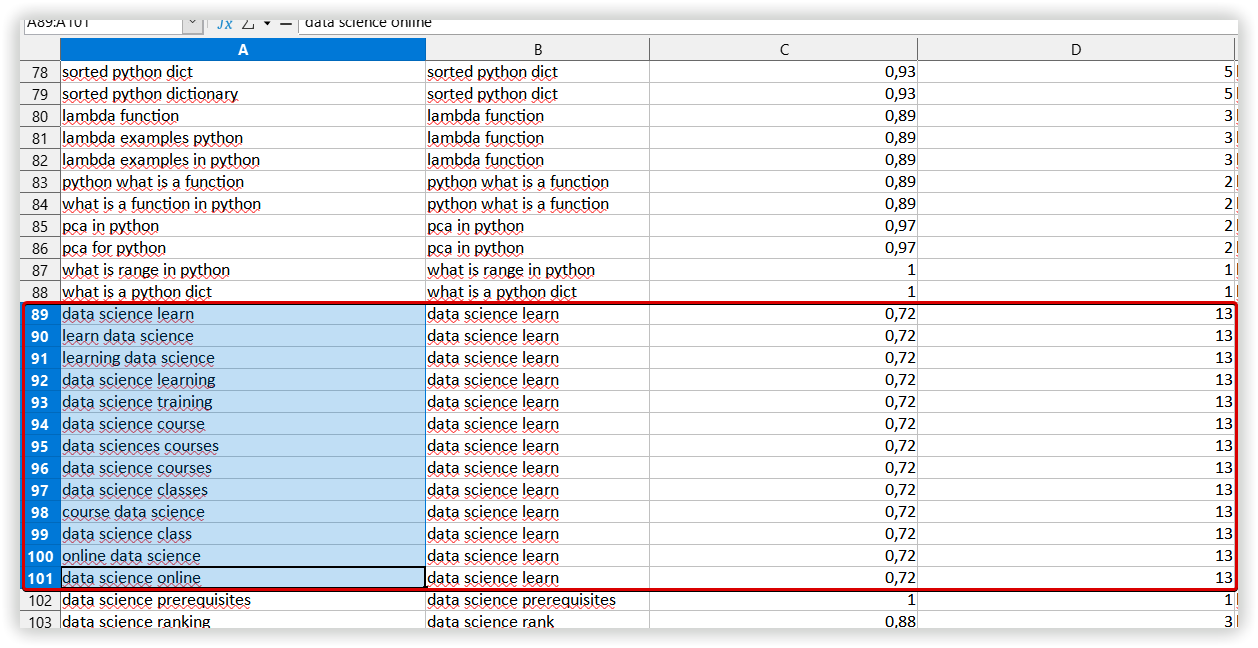
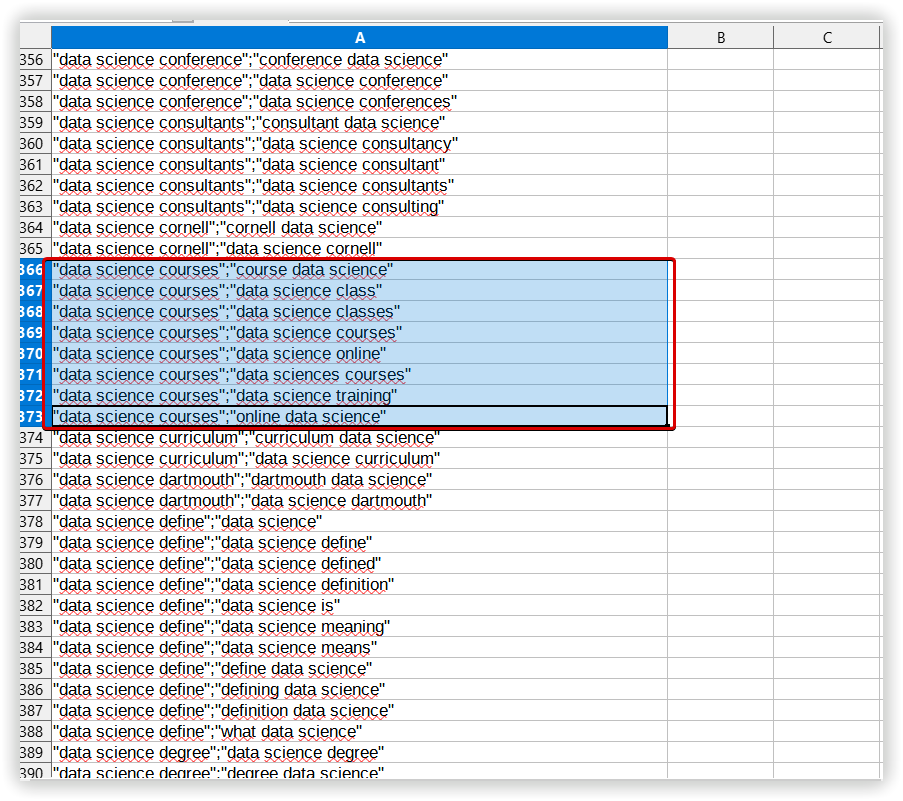
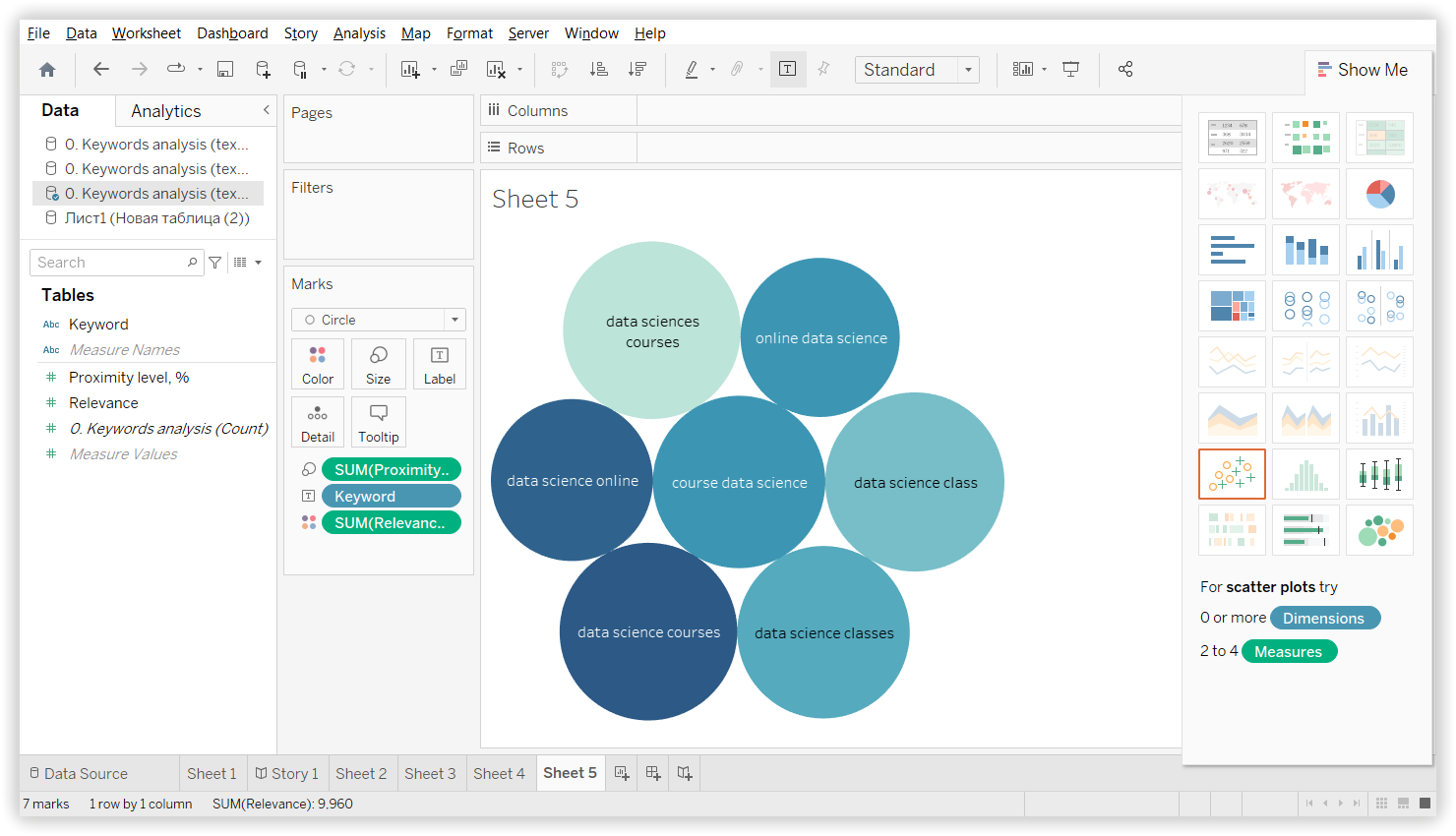
Для перевірки якості створених кластерів ми вибрали один випадковий кластер, загальний для всіх інструментів. Для Serpstat це «Data science learning» — 13 ключових слів:
Підхід сервісу унікальний через використання двох видів програмованих нейронних мереж. Перша мережа фокусується на угрупованні імпортованих ключових слів у дуже тісні тематичні кластери, щоб гарантувати, що подальше угруповання буде коректним у разі виникнення колізій.
Друга нейронна мережа фокусується на угрупованні створених кластерів і використовує набір певних правил, щоб забезпечити «гнучкіші» зв'язки.
Keyword Cupid не використовує алгоритм NLP, TF-IDF або показники релевантності кластеризації. Крім того, сервіс не рахує посилання, що відповідають за «тісність зв'язків» у кластері. Якщо Google випустить апдейт, що покращує попадання в інтент у видачі, результати кластеризації також покращуються. Назва кластеру служить розміткою для групи результатів, що використовується як центр всередині вузла (блоку або теми).
Щоб розпочати кластеризацію даних у Keyword Cupid, потрібно підготувати файл з основними показниками за ключами: складністю (KD), вартістю за клік (CPC) та частотністю. У цьому вам знову допоможе Пакетний аналіз ключових фраз.
Для перевірки якості створених кластерів ми вибрали один випадковий кластер, загальний для всіх інструментів. Для Serpstat це «Data science learning» — 13 ключових слів:
1
data science learn
2
learn data science
3
learning data science
4
data science learning
5
data science training
6
data science course
7
data sciences courses
8
data science courses
9
data science classes
10
course data science
11
data science class
12
online data science
13
data science online
Однорідність: 72%
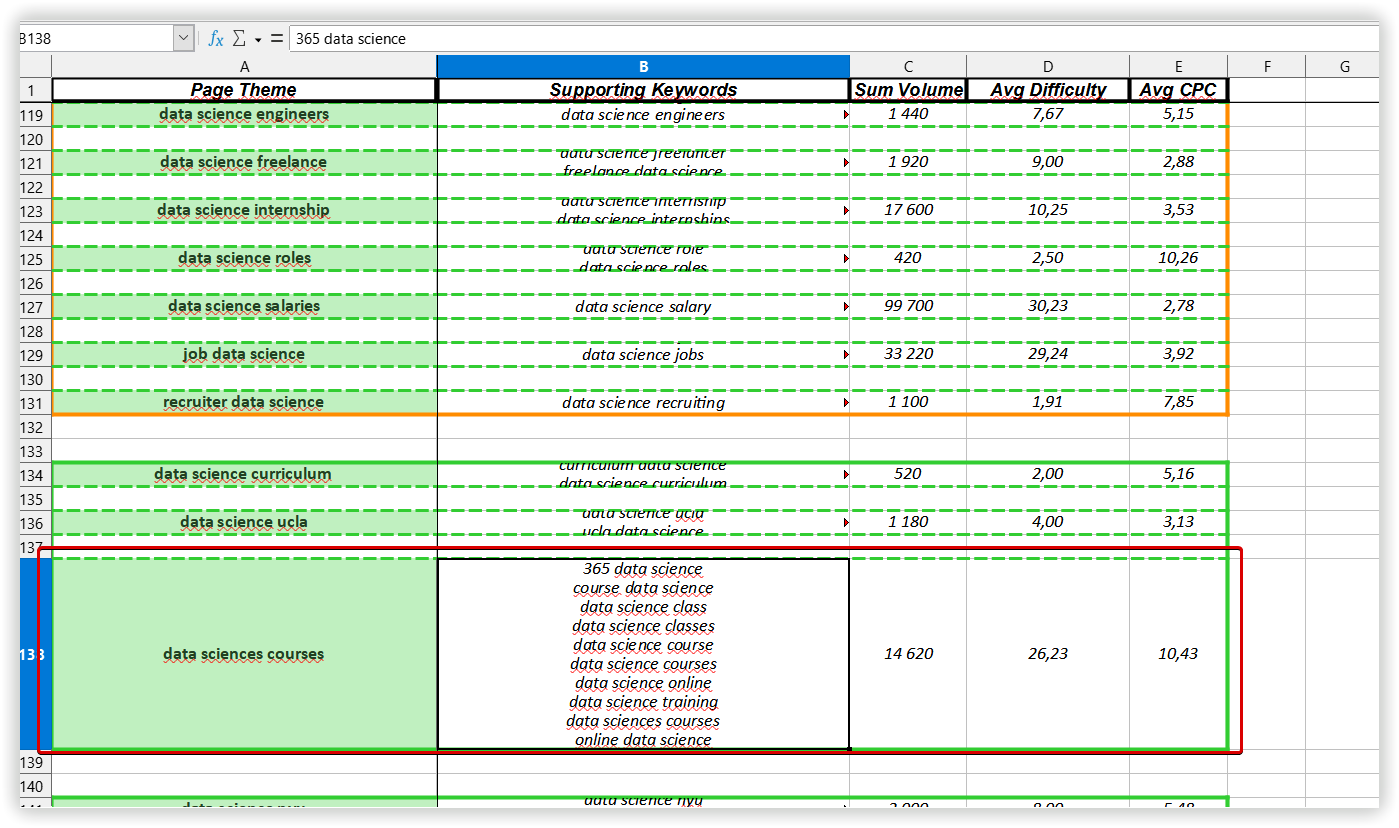
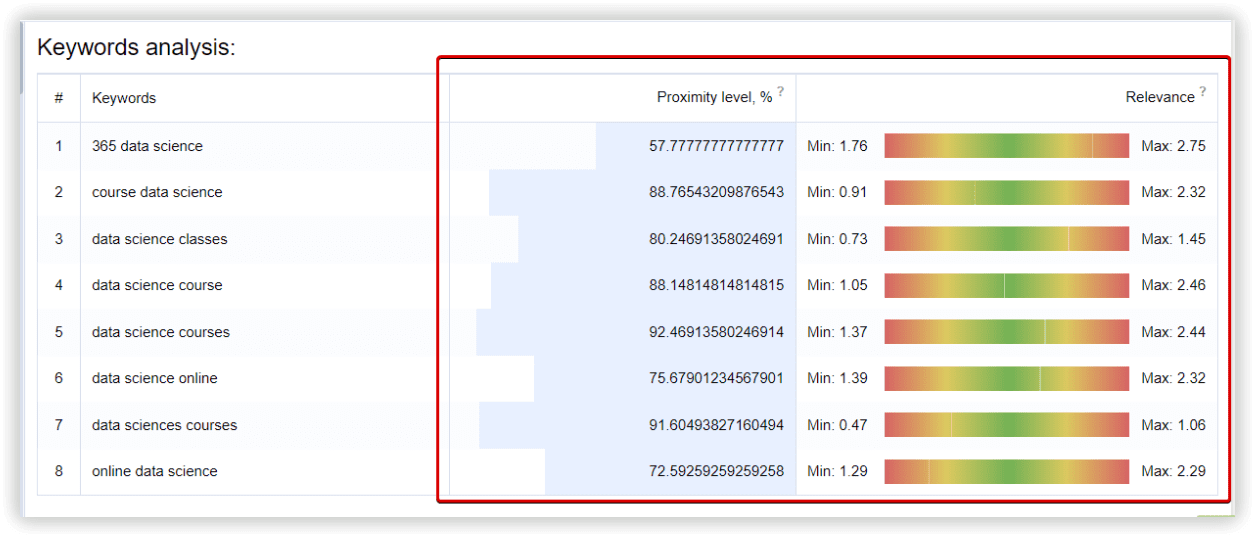
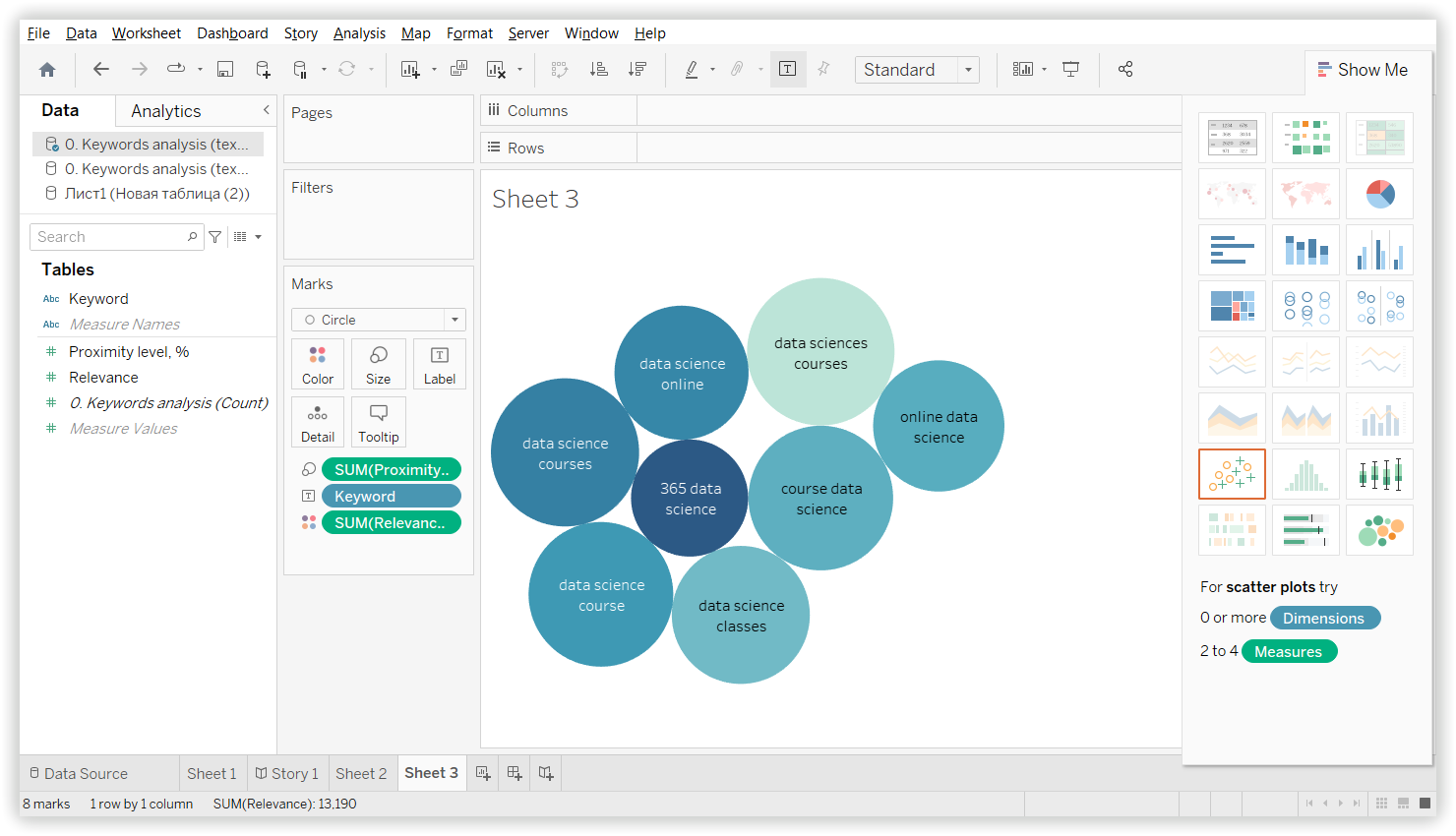
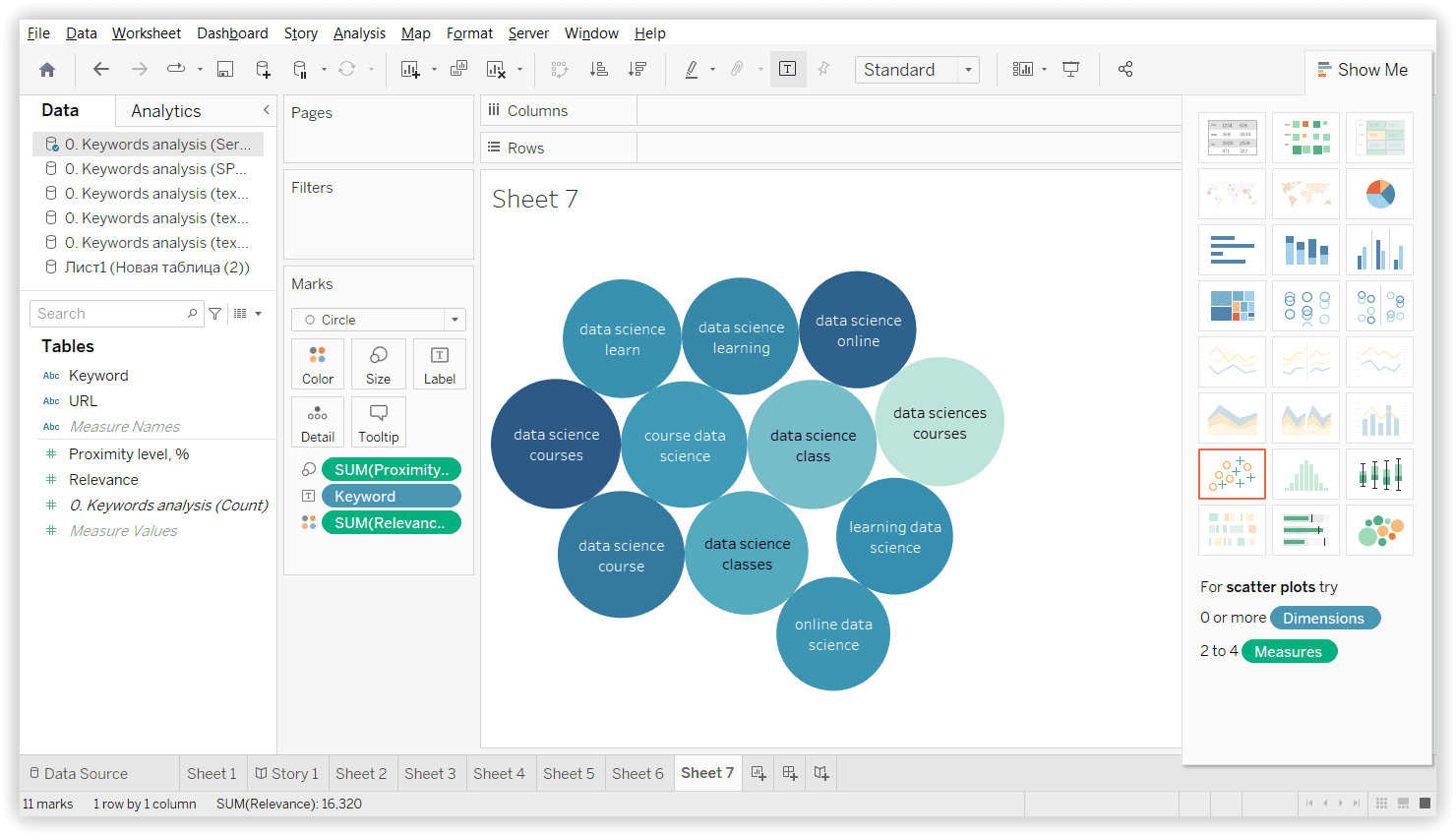
В Keyword Cupid — «Data sciences courses» на 10 ключів:
1
365 data science
2
course data science
3
data science class
4
data science classes
5
data science course
6
data science courses
7
data science online
8
data science training
9
data sciences courses
10
online data science
В Spy SERP — «Data science courses»
1
course data science
2
data science class
3
data science classes
4
data science courses
5
data science online
6
data sciences courses
7
data science training
8
online data science
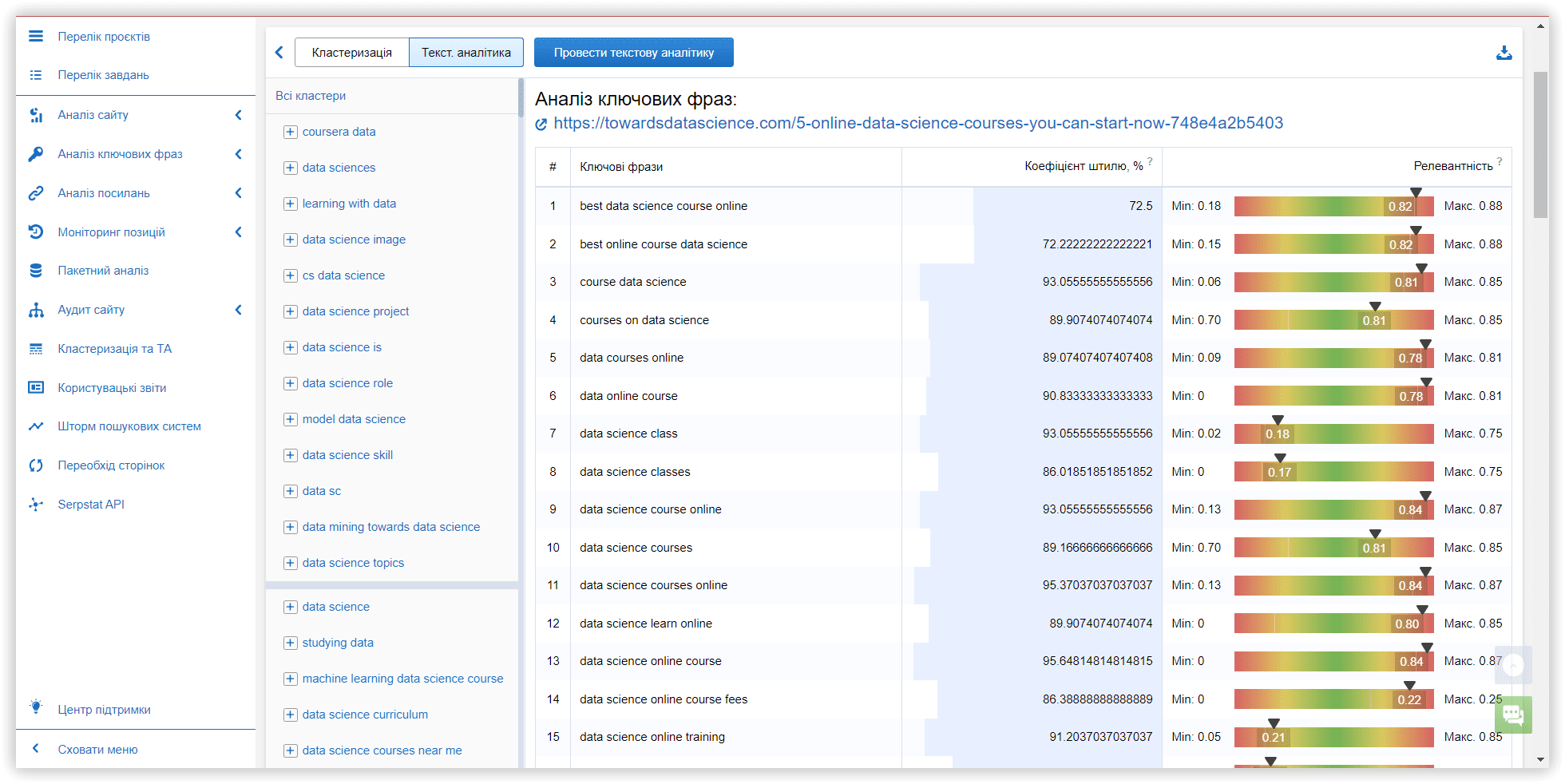
Наступний крок — провести Текстову аналітику і зробити більш докладний аналіз результатів.
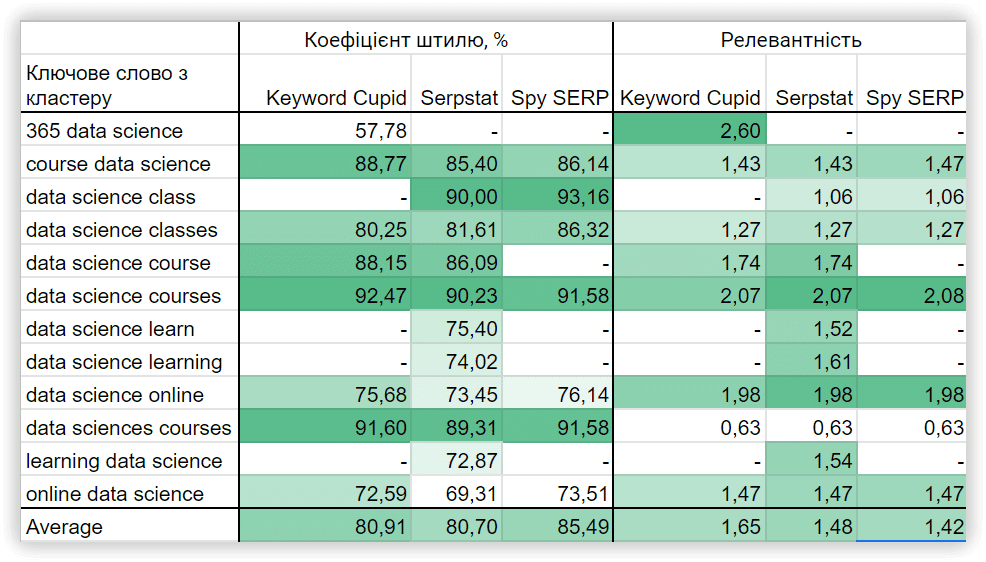
Аналіз контенту з ТОП-15 пошукової видачі та підрахунок результатів може тривати декілька годин, залежно від кількості ключових слів у кластері. Далі, ми порівняємо характеристики кластерів в ТА та перевіримо релевантність тексту по кожному аналізованому кластеру, який ми отримали в результаті роботи з вищезгаданими інструментами.
Коефіцієнт штилю, % — вказує на силу зв'язку ключового слова з іншими ключовими словами групи, спираючись на тематику.
Релевантність — це відповідність ключового слова темі цільової сторінки. За формулою TF-IDF розраховується важливість кожного ключового слова у заголовках конкурентів у метатопі. Після цього виводиться середнє значення по кожному ключовому слову.
Значимість % — важливість ключового слова для Title/H1/Body у контексті аналізованої тематики. Ця метрика розраховується як відношення ключового слова до набору ключових слів, у контенті конкурентів.
Популярність % показує, як часто конкуренти використовують це ключове слово. Показник відображає важливість ключового слова для кластеру.
Статус — показує, як часто використовується ключове слово в точному входженні, чи є ймовірність того, що у вашому тексті запит використовується занадто часто, або, що ви поки що не додали певні релевантні слова, які є в контенті конкурентів.
Приклад даних у текстовій аналітиці для кластера з Serpstat:
Коефіцієнт штилю, % — вказує на силу зв'язку ключового слова з іншими ключовими словами групи, спираючись на тематику.
Релевантність — це відповідність ключового слова темі цільової сторінки. За формулою TF-IDF розраховується важливість кожного ключового слова у заголовках конкурентів у метатопі. Після цього виводиться середнє значення по кожному ключовому слову.
Значимість % — важливість ключового слова для Title/H1/Body у контексті аналізованої тематики. Ця метрика розраховується як відношення ключового слова до набору ключових слів, у контенті конкурентів.
Популярність % показує, як часто конкуренти використовують це ключове слово. Показник відображає важливість ключового слова для кластеру.
Статус — показує, як часто використовується ключове слово в точному входженні, чи є ймовірність того, що у вашому тексті запит використовується занадто часто, або, що ви поки що не додали певні релевантні слова, які є в контенті конкурентів.
Приклад даних у текстовій аналітиці для кластера з Serpstat:
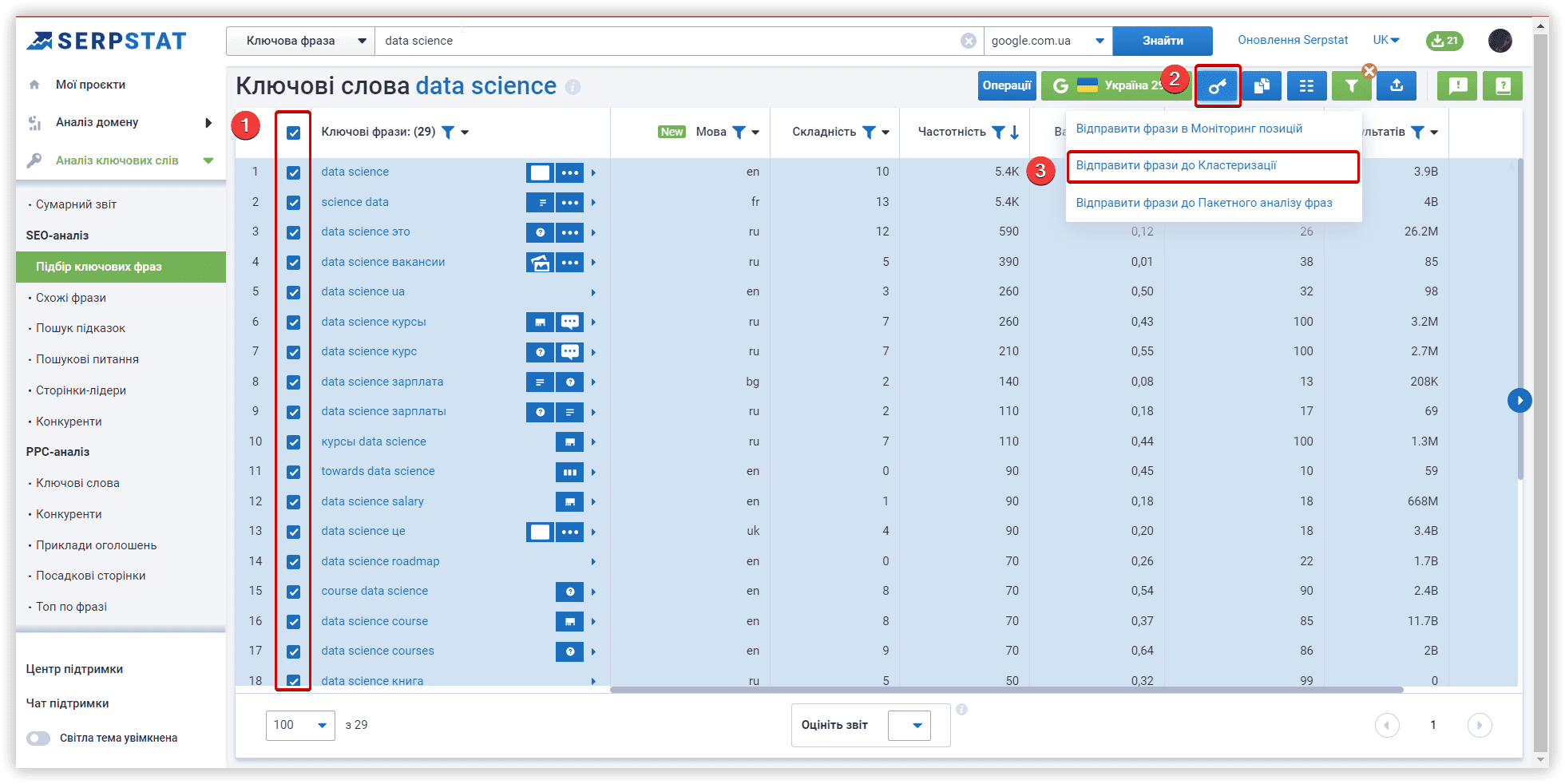
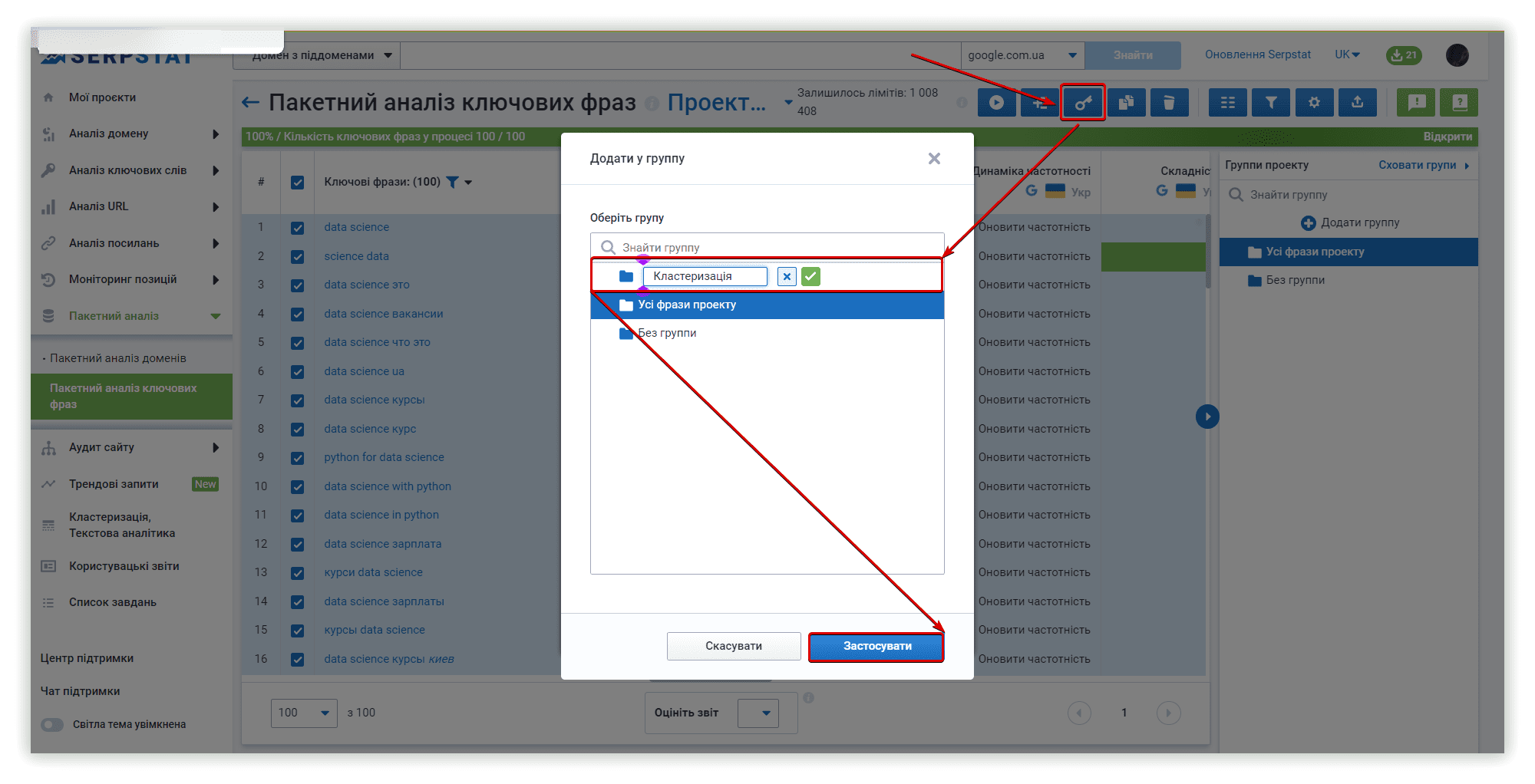
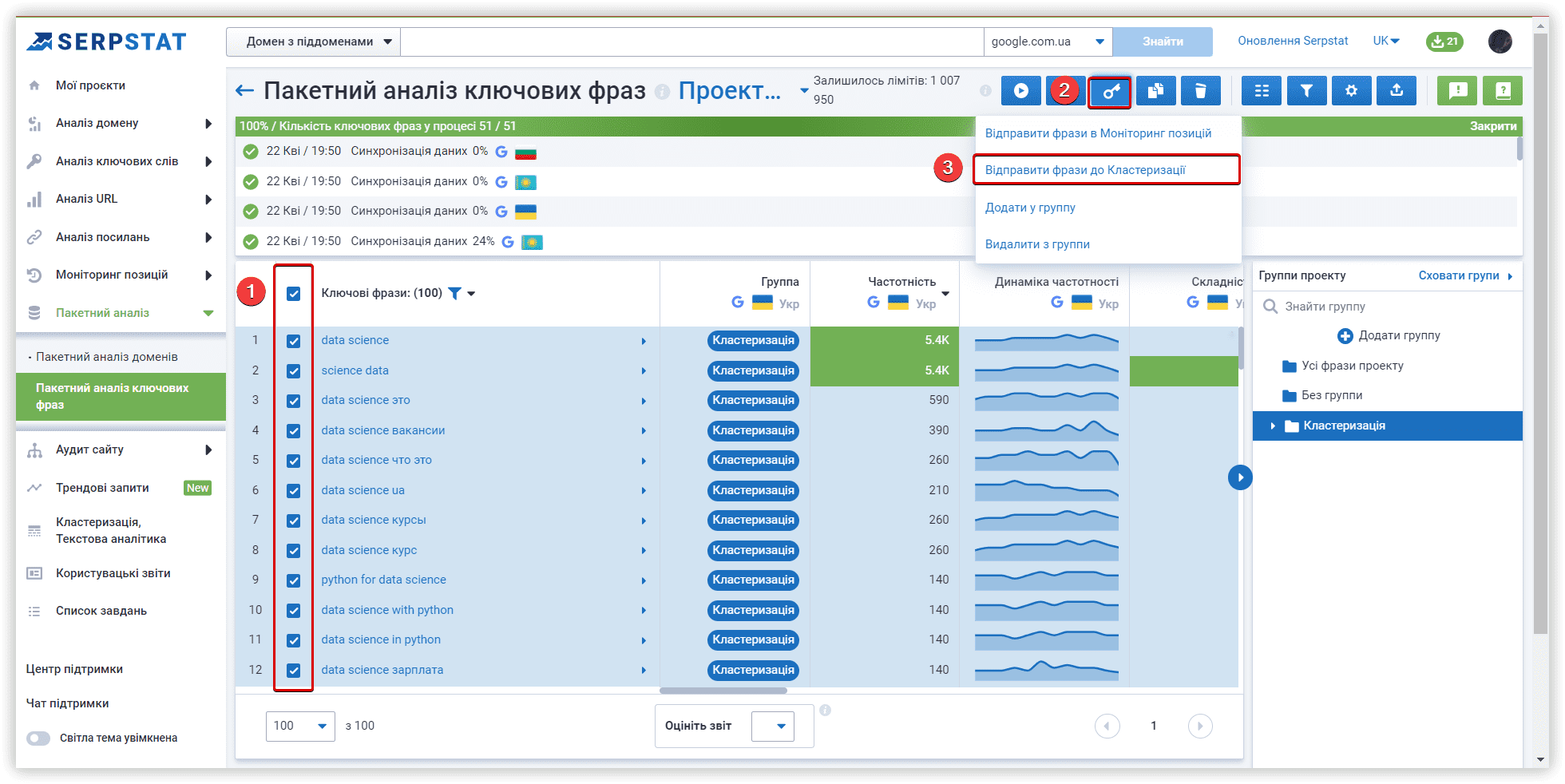
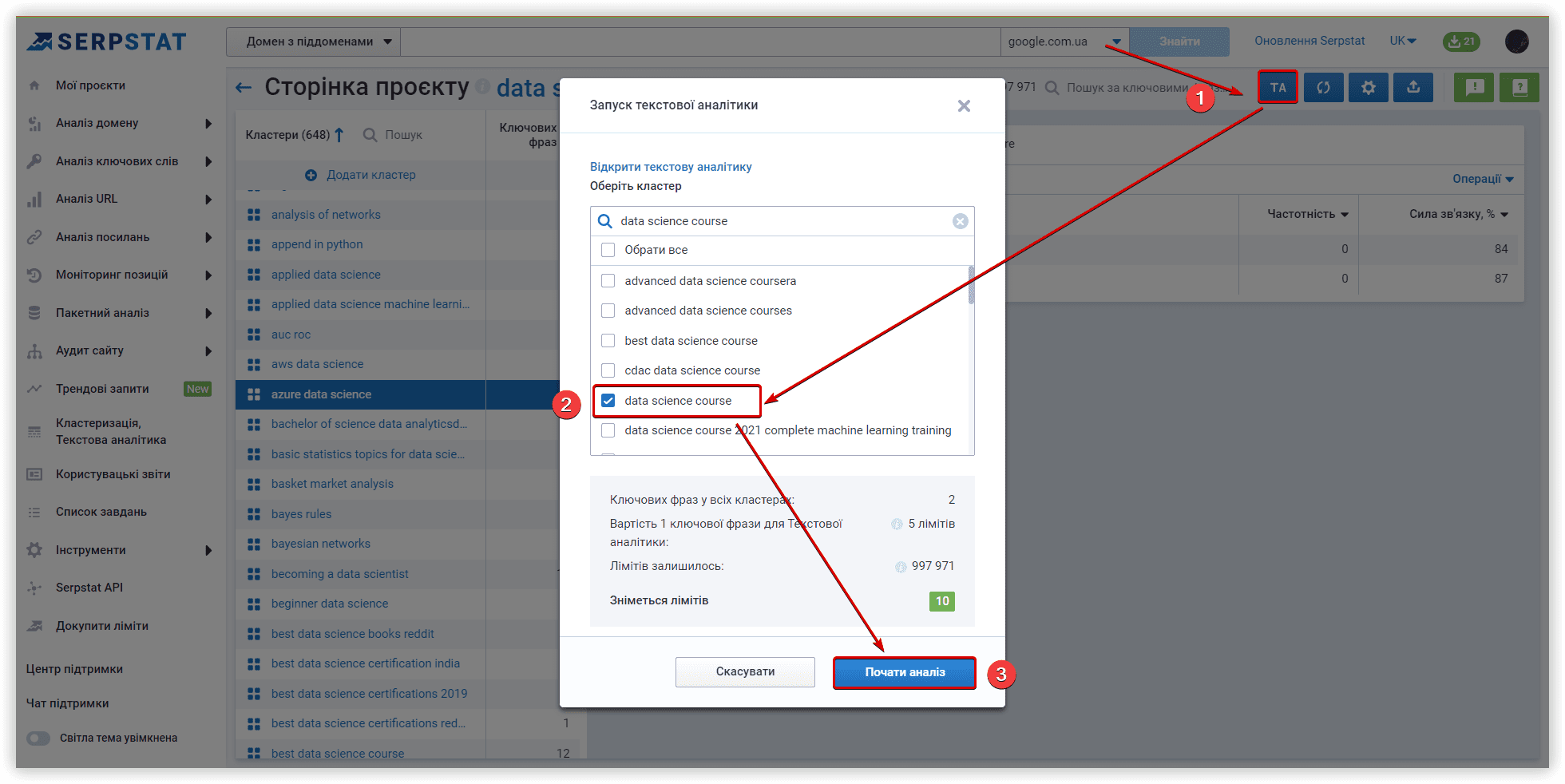
Serpstat додав можливість створення кастомних кластерів в одному з оновлень, це дає нам можливість повторити всередині інструменту кластери інших платформ.
Щоб додати новий кластер, використовуйте відповідну кнопку:
Щоб додати новий кластер, використовуйте відповідну кнопку:
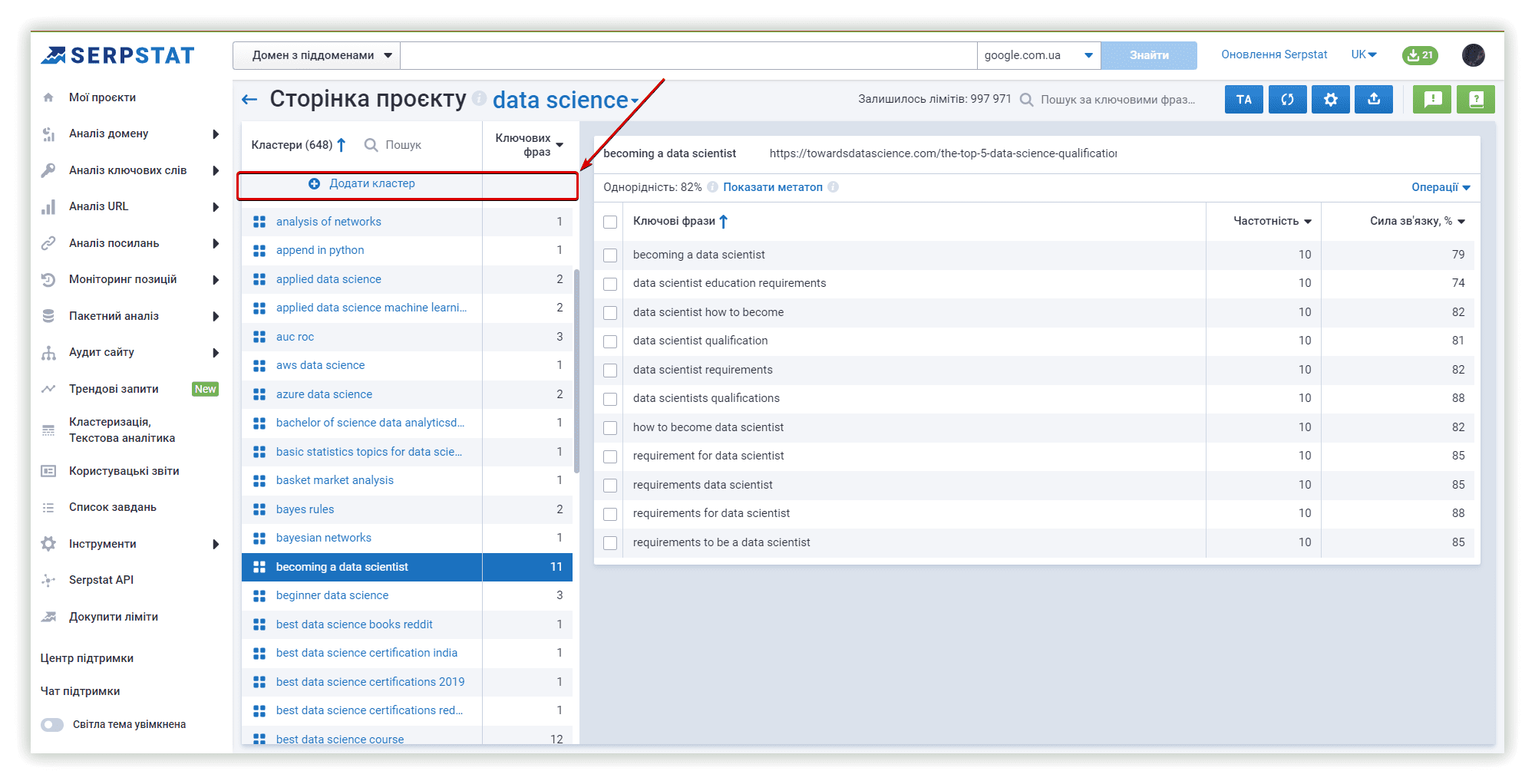
Після завершення першого текстового аналізу можна перенести необхідні ключові слова в нові кластери для Keyword Cupid і Spy SERP, щоб почати текстовий аналіз з новим набором даних.
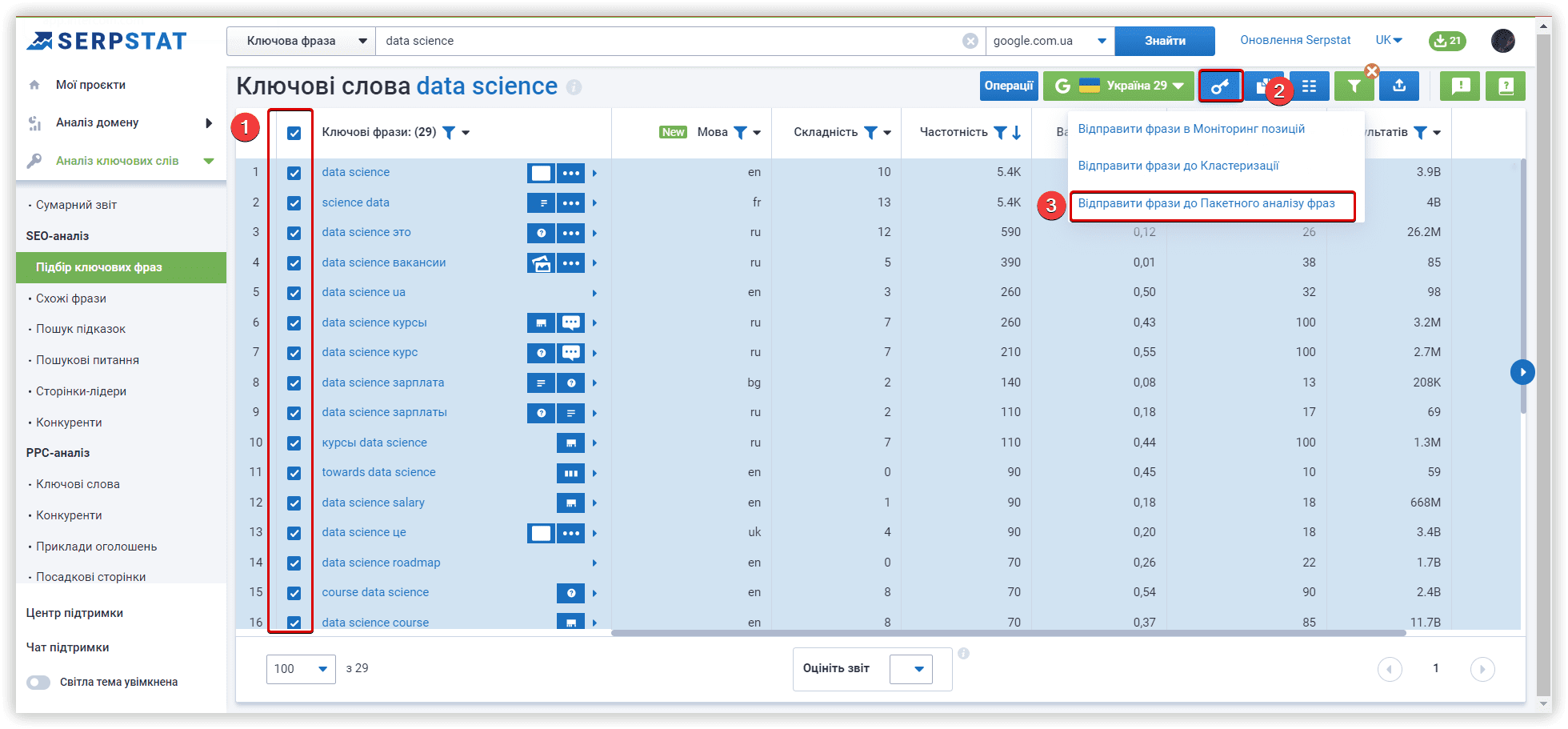
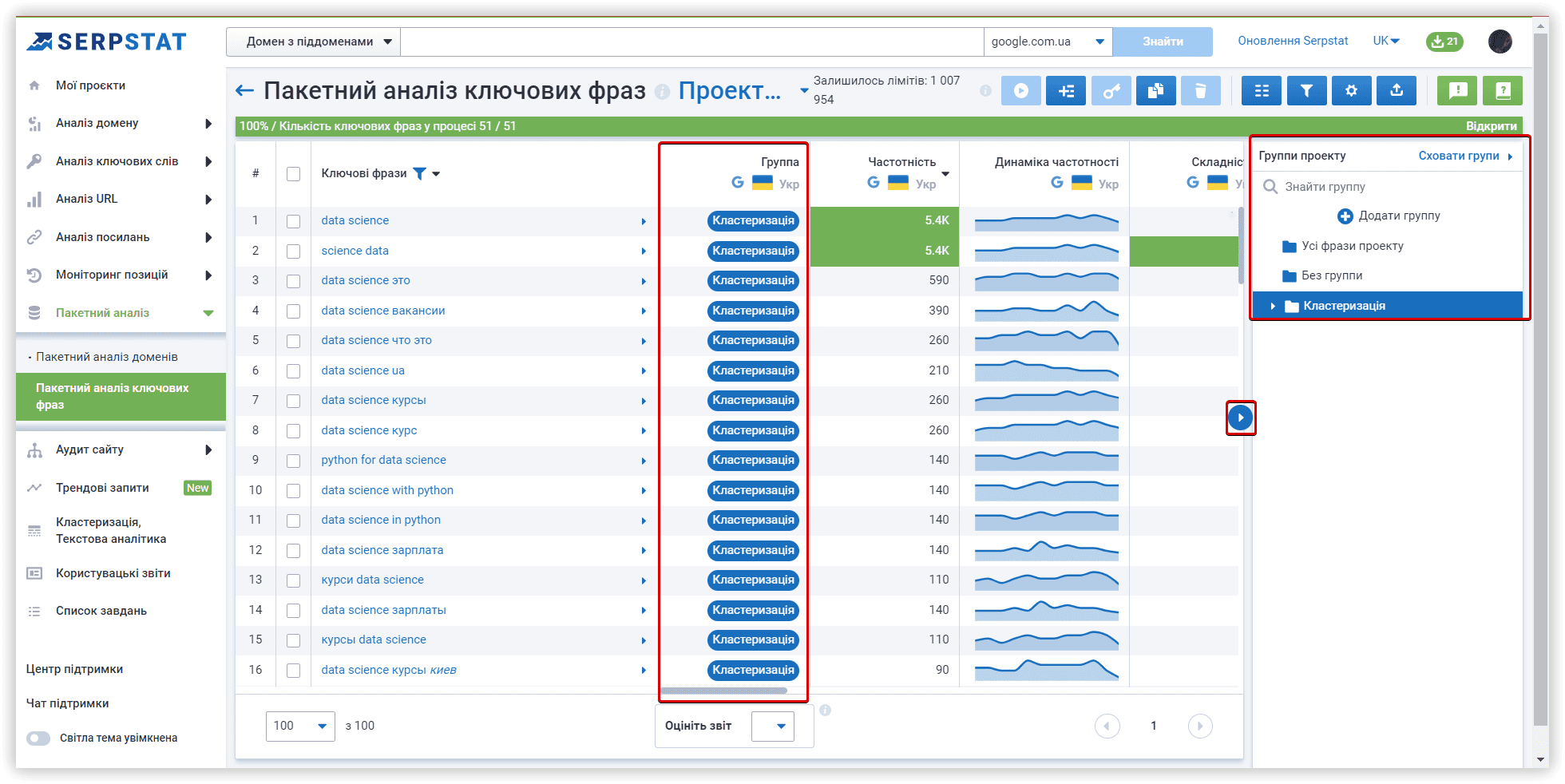
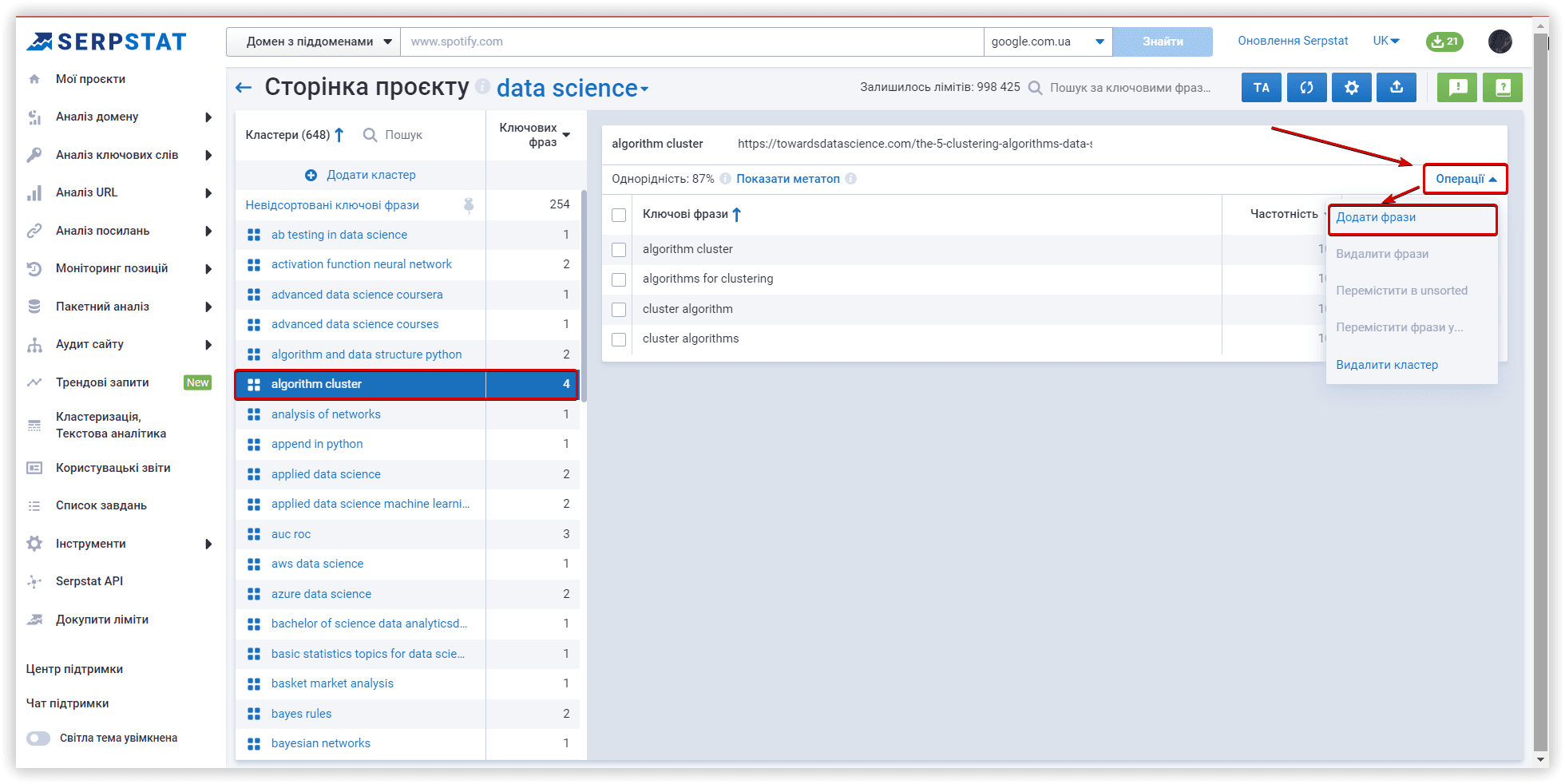
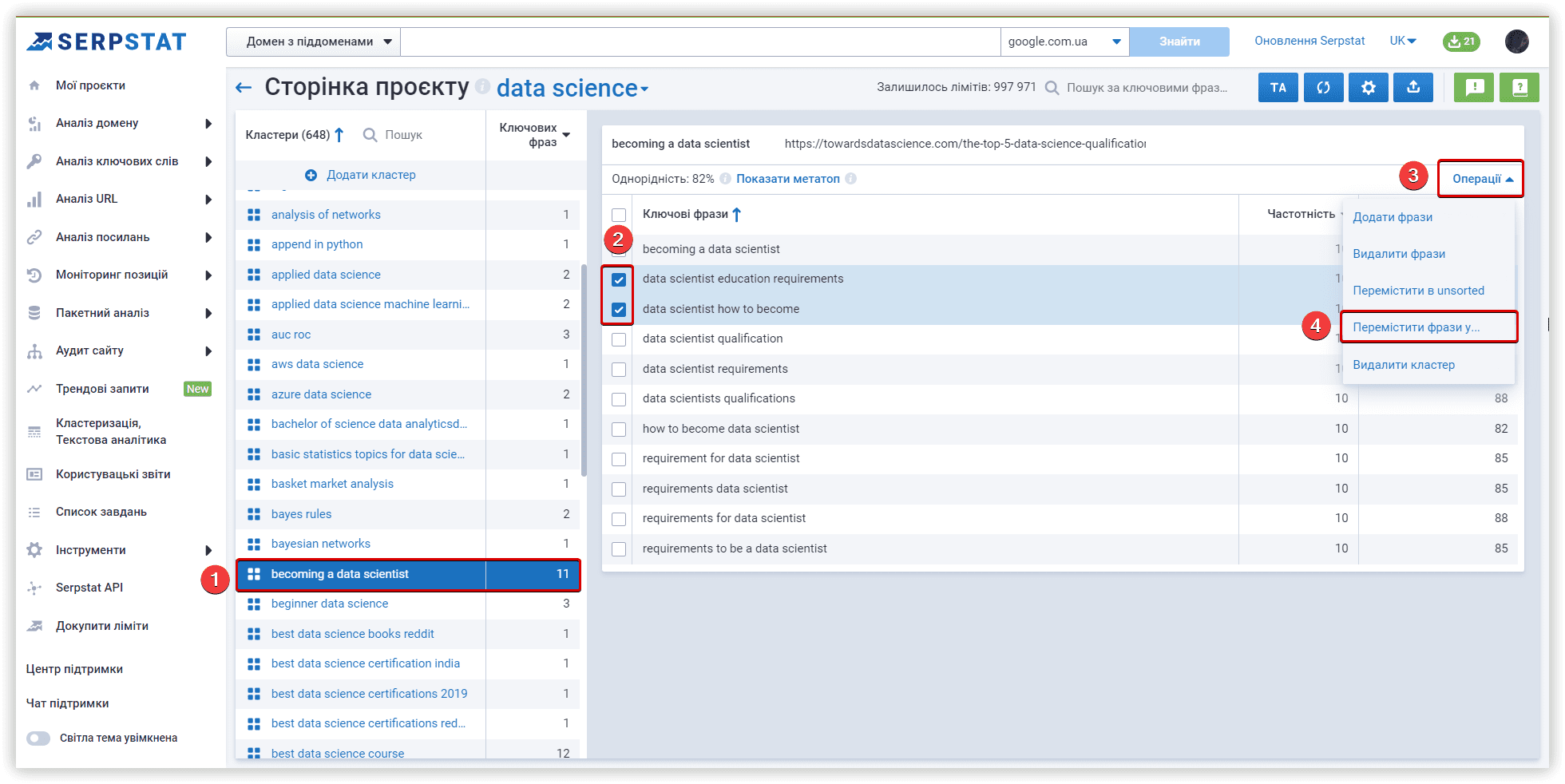
Щоб перемістити ключові слова в новий кластер із кластерів Serpstat, можна використовувати меню «Операції»:
Щоб перемістити ключові слова в новий кластер із кластерів Serpstat, можна використовувати меню «Операції»:
Ключове слово «365 data science» було в кластері «Невідсортовані ключові фрази» в Serpstat, Keyword Cupid використовував цей ключ в основному аналізованому кластері.
З 10 ключових слів від Keyword Cupid, 8 ключів Serpstat виявив у ТОП-15 видачі.
З 10 ключових слів від Keyword Cupid, 8 ключів Serpstat виявив у ТОП-15 видачі.
Згідно з результатом Текстової аналітики, «365 data science» — не найрелевантніший запит для цього кластера, його не варто використовувати в контенті.
Далі, повторюємо кластер Spy SERP та запускаємо аналітику. Цей сервіс не враховував ключі «365 data science» та «data science course». Останній ключ потрапив до кластеру не відсортованих ключів у звіті SpySERP.
Далі, повторюємо кластер Spy SERP та запускаємо аналітику. Цей сервіс не враховував ключі «365 data science» та «data science course». Останній ключ потрапив до кластеру не відсортованих ключів у звіті SpySERP.
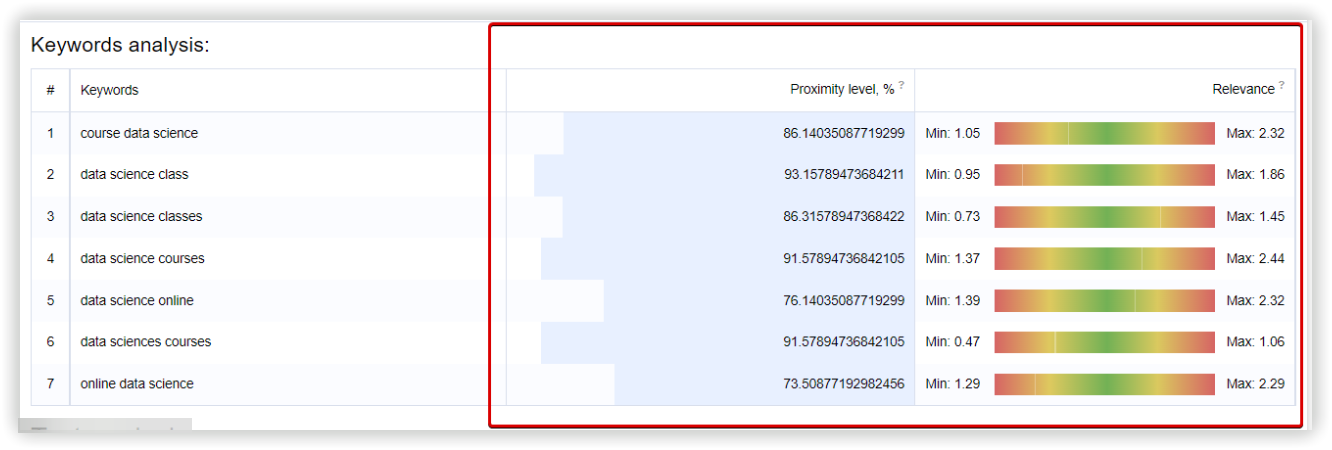
Можна побачити, що ключ з високою релевантністю «data science course» не потрапив у кластер, у той час як менш релевантний «online data science» присутній у звіті.
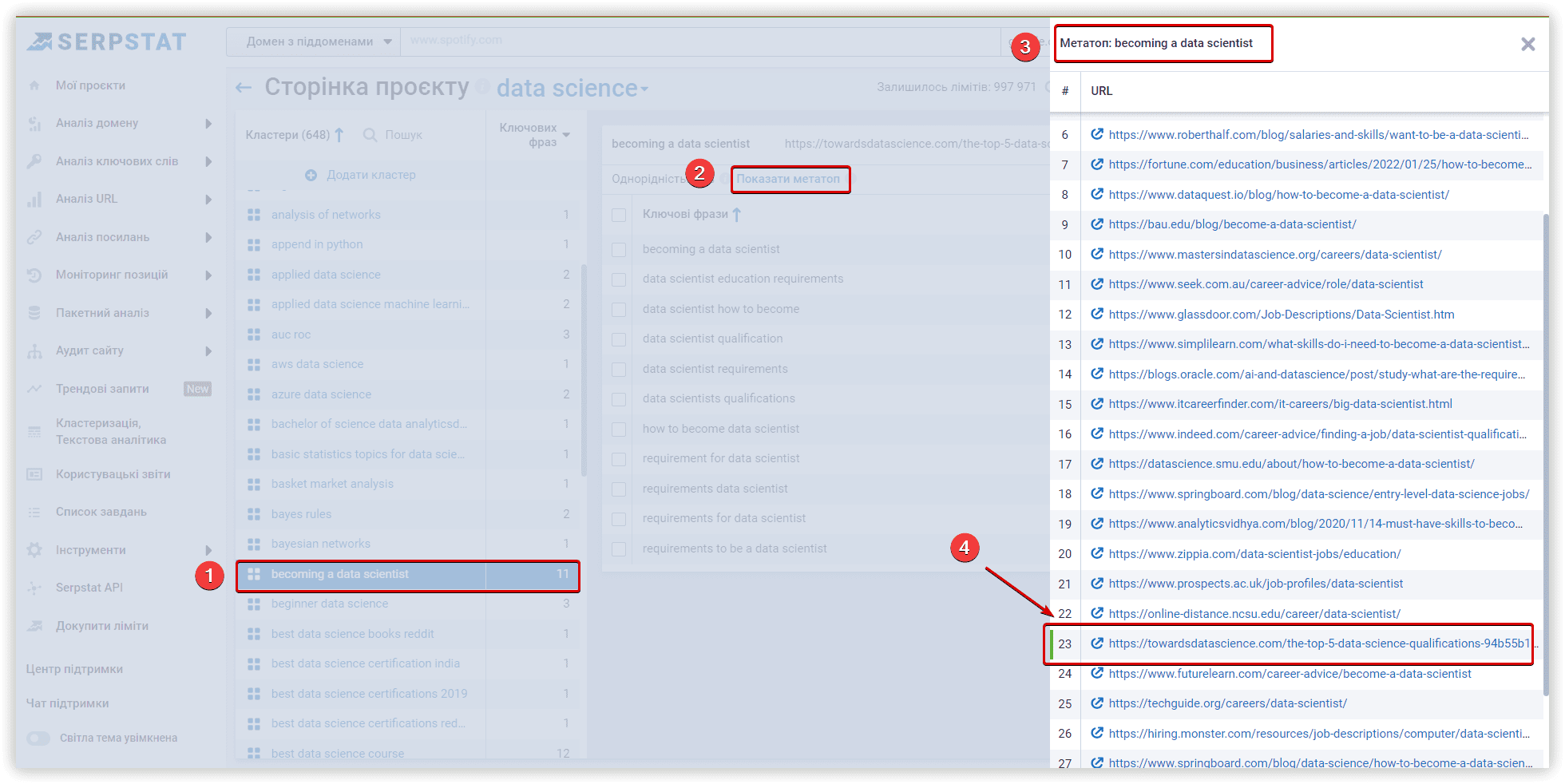
Особливості модуля кластеризації Serpstat
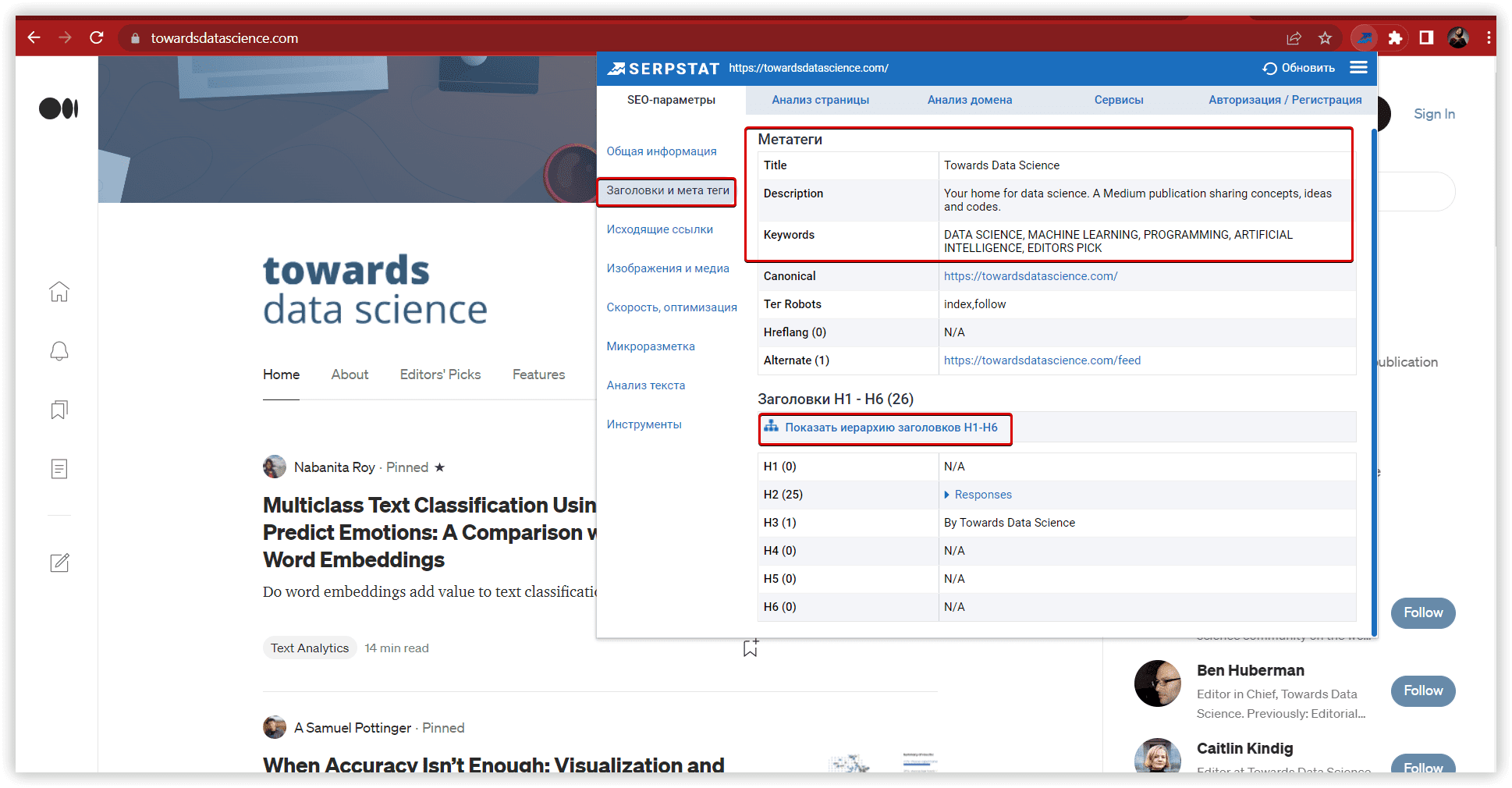
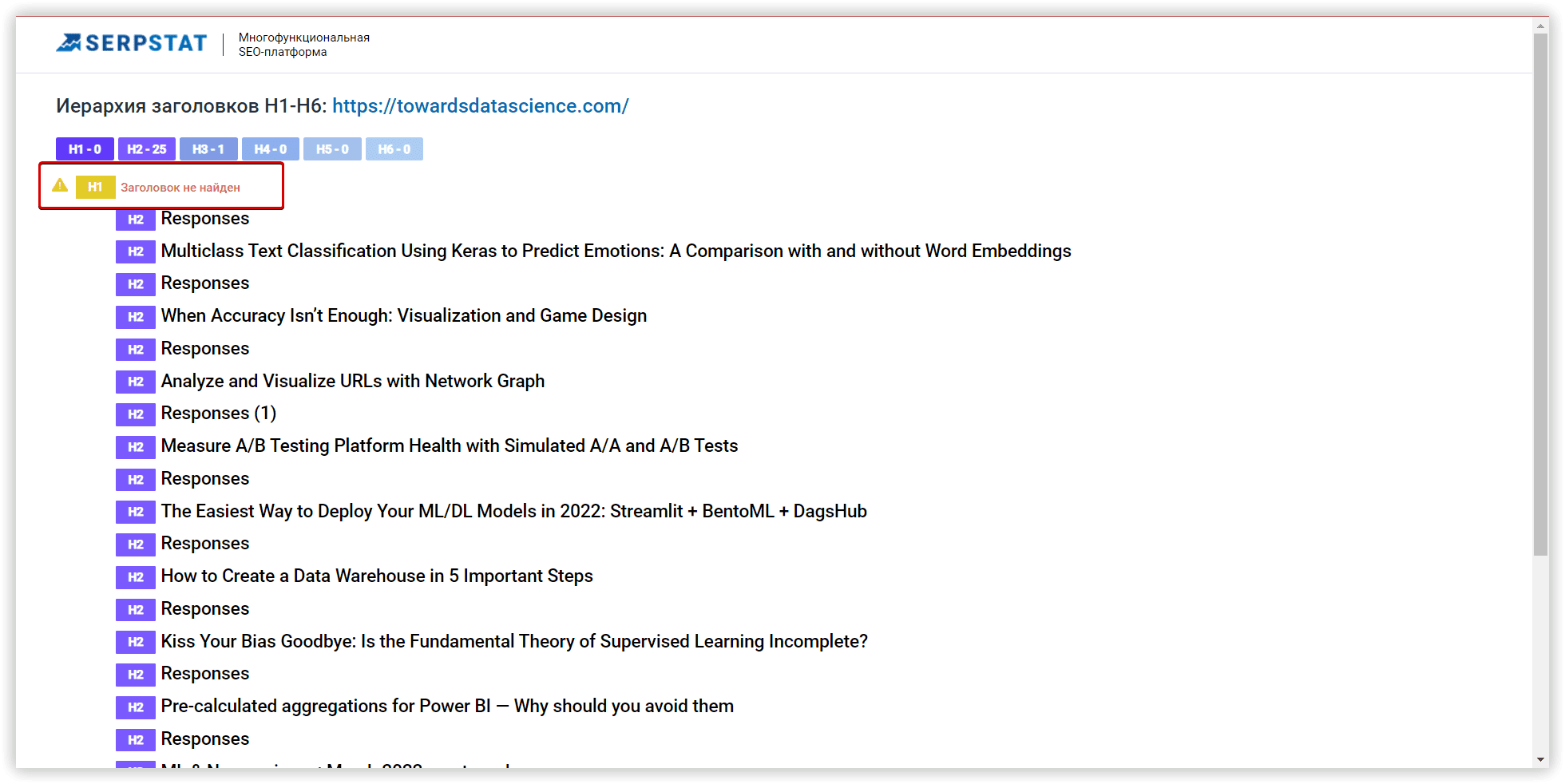
Алгоритми на основі пошукової видачі надають вам більше можливостей кластеризації. З використанням загальних URL-адрес як параметрів, цей процес стає більш прозорим і зрозумілим. Serpstat швидко об'єднує ключові слова у групи, аналізує вже опублікований контент та створює групи ключових слів, найбільш релевантні сторінкам сайту. Ви можете перевірити метатоп, який використовується під час кластеризації та підрахувати основні характеристики кластера, натиснувши на відповідну кнопку.
Цільові сторінки у метатопі виділені зеленим кольором.
Цільові сторінки у метатопі виділені зеленим кольором.
Таким чином, ви також можете відстежувати позицію сторінки, що аналізується в регіоні. На відміну від багатьох інших інструментів, Serpstat збирає дані для групування всередині кластеризації, ці параметри подібні до результатів Парсингу топу. Весь процес відбувається у фоновому режимі.
За допомогою іншого корисного інструменту, текстової аналітики, ви можете перевіряти помилки на цільовій сторінці. Якщо помилка виділена сірим кольором, це означає, що вона виявлена на цільовій сторінці. Далі, дізнатися про додаткові деталі, можна за допомогою плагіну — Serpstat SEO Checker, а також Аудиту однієї сторінки.
Побачити надмірні або «втрачені» ключові слова можна на сторінці результатів ТА:
Практичний кейс-дослідження
Наочний приклад використання Serpstat для запуску нового сайту — наш додатковий експеримент із кластеризацією. Під час проходження SEO-курсів від спеціалістів агентства Netpeak, ми створювали свій MVP — інтернет-магазин. Працюючи з кластеризацією Serpstat, щоб створити структуру для майбутнього сайту, мені вдалося продумати проект магазину тату-обладнання з нуля та прописати технічне завдання, відповідно до цільових сторінок.
Які задачі треба було виконати?
- Складаючи семантичне ядро, створити найбільш підходящу структуру для інтернет-магазину тату-обладнання.
- Наслідувати цю структуру, підбираючи найбільш релевантні та високочастотні запити для кращого ранжування в Google US.
Як Serpstat допоміг у вирішенні цих завдань?
1
Збір семантичного ядра почався з дослідження ключових фраз за тематикою сайту в Serpstat, аналізу доменів-конкурентів та збору основних даних за ключами. Потрібно було знайти бенчмарк-приклади у тату-бізнесі та запозичити семантику таких сайтів.
2
Далі, вказавши як регіон Google US/Каліфорнія, я обрала бажану силу зв'язку та тип кластеризації Сильна/Жорсткий.
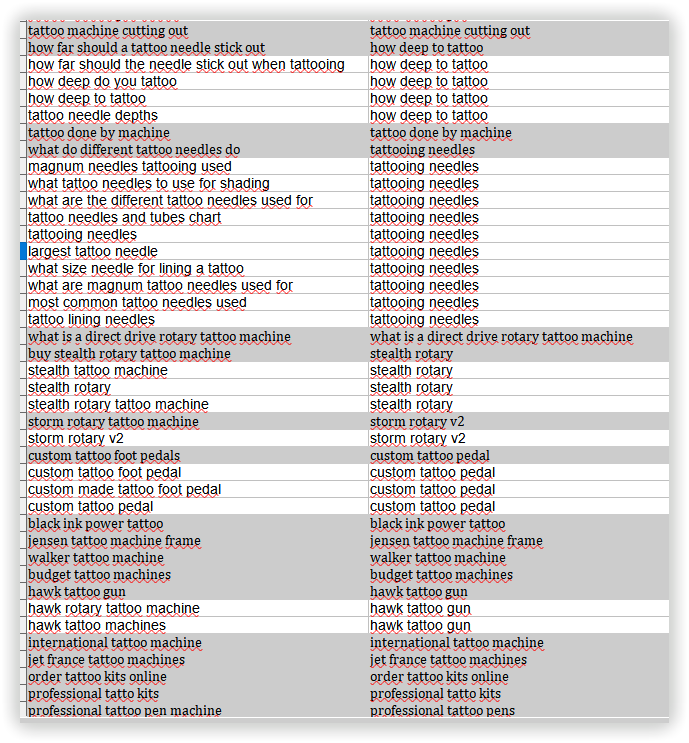
3
Після експорту результатів кластеризації, роботи з фільтрацією та сортуванням, вдалося отримати прототип структури майбутнього сайту:
4
Далі — створення схематичної карти сайту, Mind Map.
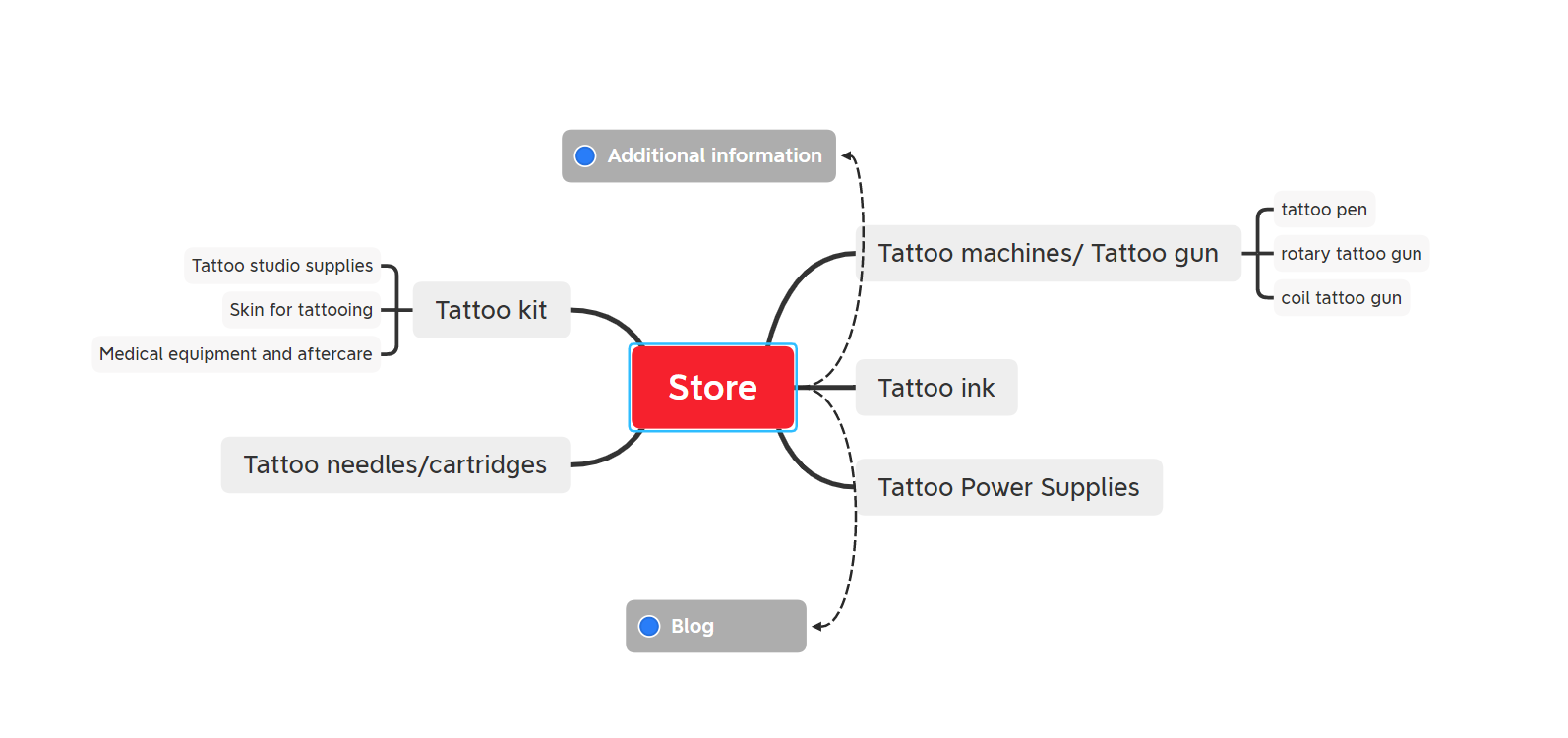
5
Після цього етапу потрібно було приступити до написання технічного завдання.

6
Категорії та контент були створені, а сайт відкритий для індексації, щоб допомогти Serpstat розподілити ключі для кластерів на існуючих сторінках, перевірити релевантність у Текстовій аналітиці, а також попрацювати з Google Analytics та Tag Manager.

Результати
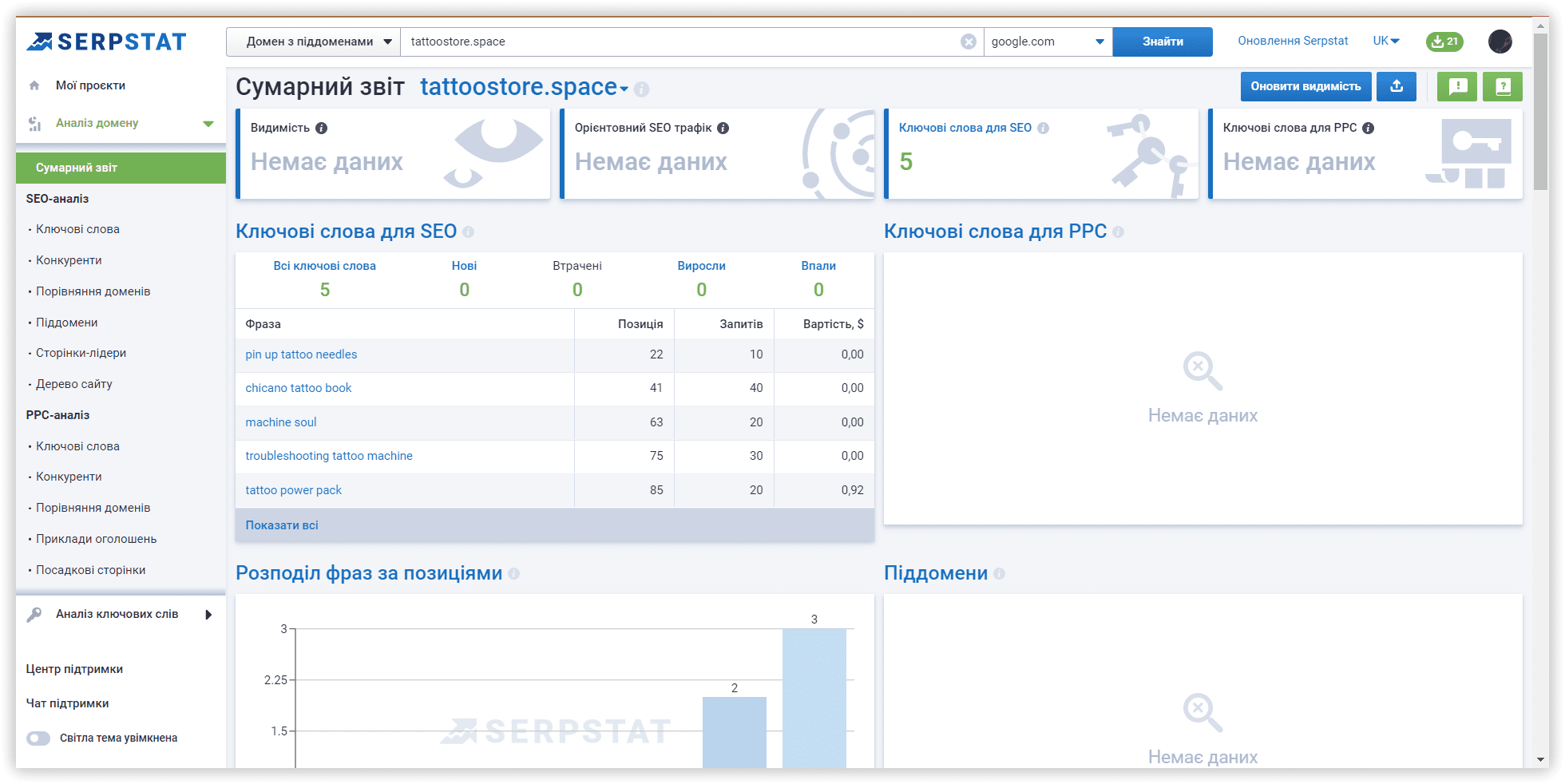
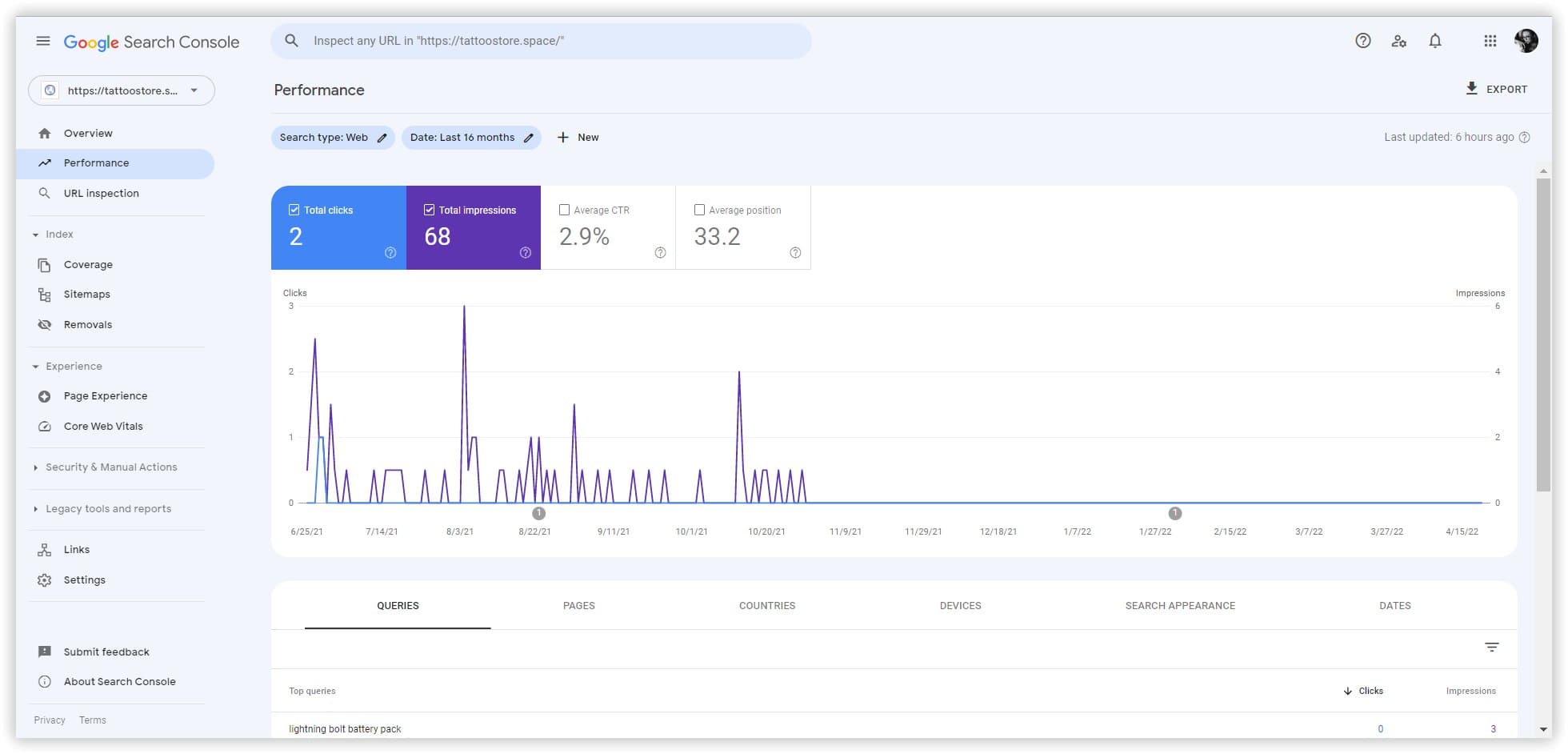
Через тиждень мій сайт відображався в Аналізі домену Serpstat за 5 ключовими словами з 22-ї по 85-ту позицію в Google США. Я отримала очікуваний результат за рахунок такого прототипування, широкої семантики баз Serpstat та швидкої автоматичної кластеризації.
Висновки
З кластеризацією ключових слів для своїх цільових сторінок, ви демонструєте Google, що ваш сайт досить змістовний для певної ніші і відображаєте широту і глибину змісту. Ви даєте пошуковим системам сигнали про групи контенту, а це допомагає ідентифікувати та просувати певні сторінки в результатах пошуку, задіявши логіку алгоритмів пошукових систем.
Кластеризація допомагає зробити сайт зручнішим для користувачів, краще ранжуватися за ключовими запитами різного типу, примножувати органічний трафік за рахунок корисного та структурованого контенту, організовувати внутрішнє перелінкування ефективніше, простіше розширювати семантику у певній ніші.
Кластеризація ключових фраз – це найпростіший спосіб оптимізувати одну сторінку під кілька запитів, об'єднаних пошуковим інтентом. За допомогою Serpstat ви можете згрупувати до 50 тисяч ключових слів, швидко та просто розробити детальне семантичне ядро сайту. Вдавшись до кластеризації можна оптимізувати контент, орієнтований на десятки схожих та пов'язаних ключових слів, що допоможе ранжуватися за цілою групою запитів, а структуру сайту організувати відповідно до алгоритмів Google. Групування запитів з огляду на пошукову видачу, базується на перетині цілей пошуку та працює завдяки алгоритмам машинного навчання.
Текстова аналітика Serpstat допоможе підвищити релевантність контенту, сформованого за кластерами, та врахувати ТОП-15 видачі пошукової системи у певному регіоні.
У цій статті ми розглянули значення кластеризації в контексті машинного навчання та порівняли результати роботи різних алгоритмів та підходів до розбивки семантичного ядра, щоб перевірити релевантність кожного створеного кластера. Висновки свідчать про те, що автоматизована кластеризація, що базується на пошуковій видачі, відпрацьовує ефективніше, ніж лематизовані алгоритми, для стандартних задач кластеризації. Окремі SEO інструменти застосовують різні підходи до групування методом перевірки видачі пошукової системи.
Кластеризація допомагає думати масштабніше про зміст сайту та адаптуватися до умов пошукової оптимізації майбутнього.
Кластеризація допомагає зробити сайт зручнішим для користувачів, краще ранжуватися за ключовими запитами різного типу, примножувати органічний трафік за рахунок корисного та структурованого контенту, організовувати внутрішнє перелінкування ефективніше, простіше розширювати семантику у певній ніші.
Кластеризація ключових фраз – це найпростіший спосіб оптимізувати одну сторінку під кілька запитів, об'єднаних пошуковим інтентом. За допомогою Serpstat ви можете згрупувати до 50 тисяч ключових слів, швидко та просто розробити детальне семантичне ядро сайту. Вдавшись до кластеризації можна оптимізувати контент, орієнтований на десятки схожих та пов'язаних ключових слів, що допоможе ранжуватися за цілою групою запитів, а структуру сайту організувати відповідно до алгоритмів Google. Групування запитів з огляду на пошукову видачу, базується на перетині цілей пошуку та працює завдяки алгоритмам машинного навчання.
Текстова аналітика Serpstat допоможе підвищити релевантність контенту, сформованого за кластерами, та врахувати ТОП-15 видачі пошукової системи у певному регіоні.
У цій статті ми розглянули значення кластеризації в контексті машинного навчання та порівняли результати роботи різних алгоритмів та підходів до розбивки семантичного ядра, щоб перевірити релевантність кожного створеного кластера. Висновки свідчать про те, що автоматизована кластеризація, що базується на пошуковій видачі, відпрацьовує ефективніше, ніж лематизовані алгоритми, для стандартних задач кластеризації. Окремі SEO інструменти застосовують різні підходи до групування методом перевірки видачі пошукової системи.
Кластеризація допомагає думати масштабніше про зміст сайту та адаптуватися до умов пошукової оптимізації майбутнього.
Думка авторів гостьових дописів може не збігатися з думкою редакції та спеціалістів Serpstat.
Знайшли помилку? Виділіть її та натисніть Ctrl + Enter, щоб повідомити нам.
Використовуйте кращі SEO інструменти
Перевірка зворотніх посилань
Швидка перевірка зворотніх посилань вашого сайту та конкурентів
API для SEO
Отримайте швидко великі обсяги даних за допомогою функціонального SЕО API
Аналіз конкурентів
Зробіть повний аналіз сайтів конкурентів для SEO та PPC
Моніторинг позицій
Відстежуйте зміну ранжування цільових запитів використовуючи моніторинг позицій ключів
Рекомендовані статті
Кейси, лайфхаки, дослідження та корисні статті
У вас немає часу стежити за новинами? Не турбуйтеся! Наш редактор підбере статті, які неодмінно допоможуть вам у роботі. Приєднуйтесь до нашої затишної спільноти :)
Натискаючи кнопку, ви погоджуєтеся з нашою Політикою конфіденційності