SEO-аналіз конкурентів з API та без
Підходи та кейси SEO агенцій


Зміст
Особливості роботи SEO-агентств із клієнтами
Аналіз конкурентів за допомогою Serpstat (аналітика VS моніторинг)
- Підбір унікальних ключів з перетину семантик
- Підбір унікальних ключів для конкурента
- Підбір конкурентів за допомогою «Аналізу ключових слів»
- Підбір конкурентів за допомогою «Моніторингу позицій»
- Аналіз конкурентів у пошуковій видачі
- Аналіз конкурентів за допомогою API Serpstat
Підходи до порівняння доменів та вибору фраз для просування
Використання «Дерева сайту» з семантикою свого та конкурентних сайтів
Serpstat та диджитал-агенція Inweb спільно розглянули оптимізацію для бізнесу з API інтеграціями та без них, в інтерфейсі SEO-платформи. У цій статті ми покажемо, як аналізувати конкурентів, знаходити ключові слова, використовувати кластеризацію та інші інструменти швидко та ефективно.
Особливості роботи SEO-агентств із клієнтами
Бувають ситуації, коли власники бізнесу посилено намагаються навчитися SEO, але приходять до того, що просто не мають ресурсу часу. Тоді вони й звертаються до агенцій. Проте розбиратися в основах все одно потрібно. Важливо розуміти, що робить команда та навіщо.
Бувають навіть випадки, коли потенційним партнерам доводиться відмовляти через причини, не пов'язані з грошима. Часто клієнти приходять із запитами, які просто неможливо здійснити. Наприклад, коли необхідно отримувати трафік з дуже конкурентної тематики, а стан сайту не відповідає критеріям якості. Або через асортимент. Наприклад, монобренд суконь, 20 штук, конкурувати з Kasta не може, тому що на платформі 20 тисяч суконь. Тоді здійснюється лише перший етап — оптимізація, налаштування аналітики. Далі по SEO краще нічого не робити, в цьому просто немає сенсу. Скільки посилань не купуй, що не роби — результату не буде. SEO не окупиться.
Або дуже вузька ніша. Часто звертаються стартапи, які працюють у нішах, де не сформовано попиту. У цьому випадку просування в органіці теж не має особливого сенсу. SEO працює з попитом, якщо його немає, його неможливо створити із нічого. У таких випадках просування теж нерентабельне.
Або, наприклад, аутсорсингові компанії, яким потрібні замовлення на розробку ПЗ з-за кордону. Конкуренція дуже велика, і SEO — це не той канал, який може вирішити таке завдання.
Агентства не можуть брати все поспіль, — результату не буде досягнуто, а марна робота нікому не потрібна.
Тому розглянемо кілька універсальних підходів, які можна використовувати будь-якому бізнесу вже зараз, без додаткових зусиль.
Аналіз конкурентів за допомогою Serpstat (аналітика VS моніторинг)
Як зробити аналіз конкурентів? Розглянемо два глобальні підходи:
Ми можемо звернутись до аналітики Serpstat, з бази даних сервісу, але є нюанси:
- По-перше, відомості можуть бути застарілими. Існує певний цикл оновлення даних, 7.4 млрд ключів просто не можуть оновлюватись щоденно.
- По-друге, тоді ми робитимемо оцінку конкуренції порівняно з певним сайтом, на основі всіх ключів. А треба розуміти, що далеко не всі ці запити є цільовими для нас, тому у вибірку можуть потрапляти не зовсім реальні конкуренти.
Альтернативний спосіб працює практично в режимі реального часу, аналіз проходить через інструменти моніторингу. Так ми можемо відстежити не тільки позиції власного домену, а й позиції будь-якого домену, який потрапляє до топ-100. Це допоможе дати оцінку конкуренції на цільовому ринку загалом.
Розгляньмо перший спосіб на прикладі сайту кліматичного обладнання.
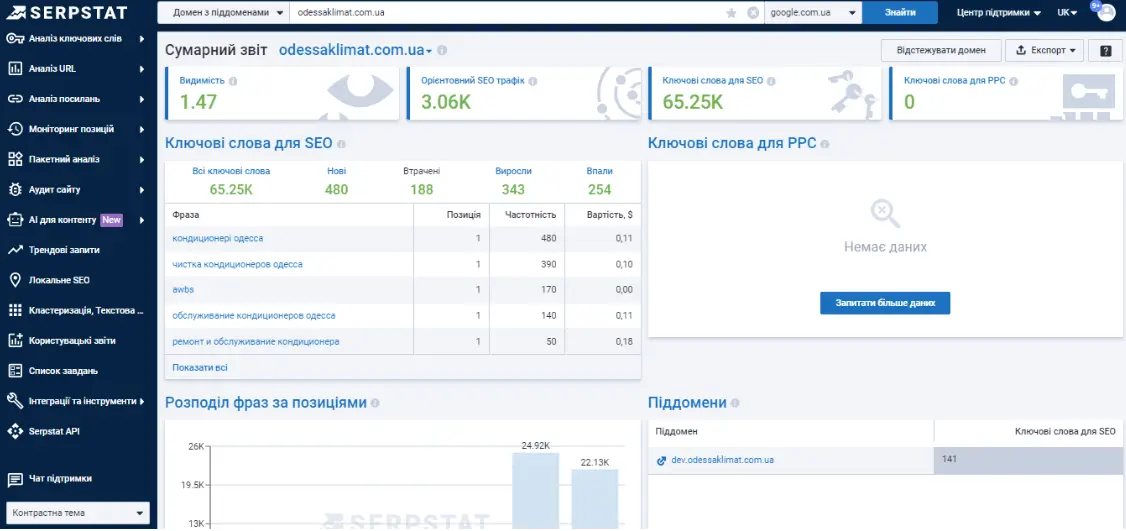
По-перше, існують сайти, які займаються тим самим, що й великі гравці на ринку. Але багато проєктів працюють як на конкретному локальному ринку, так і на території всієї країни.
Що ми робимо при аналізі: орієнтуємося на ті ключі, за якими ранжується сайт і намагаємося виявити, які конкурентні сайти тієї ж тематики ранжуються за ними ж.
В Serpstat є можливість вибору між різними регіонами Google і це також може стати в пригоді.
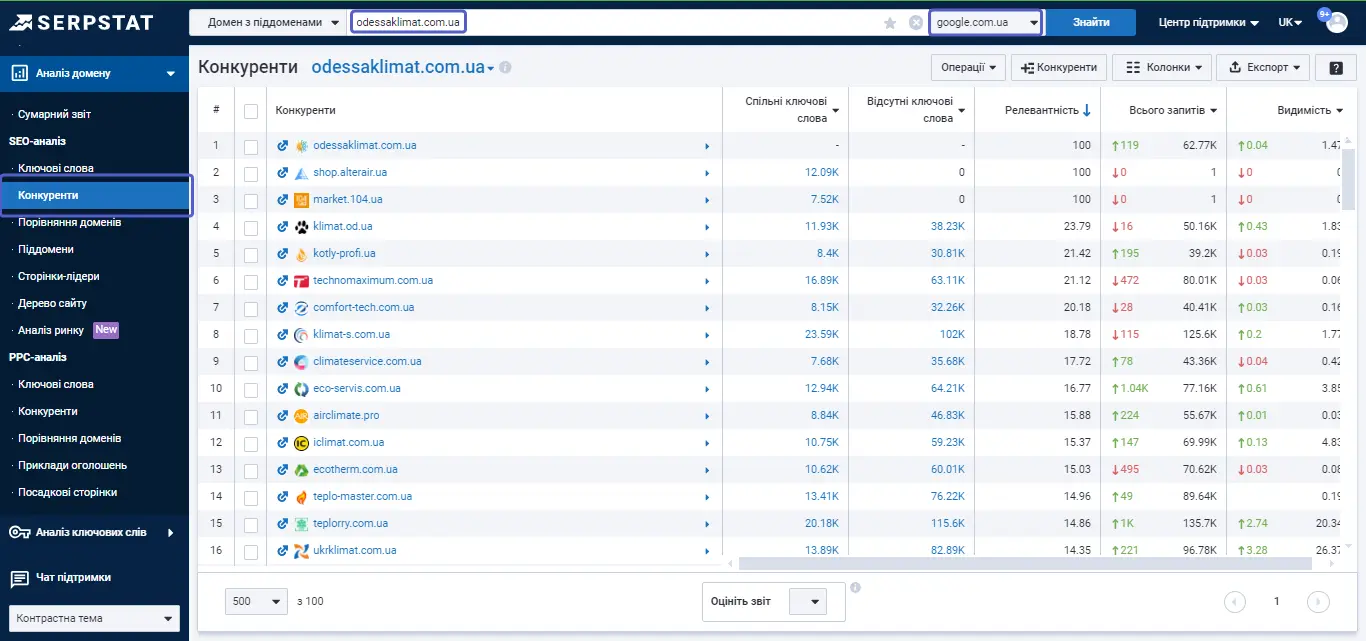
Тепер про нюанси. По-перше, деякі сайти, особливо сайти-гіганти, агрегатори, з'являтимуться на початку списку. З цим можна боротися просто орієнтуючись на релевантність. Чим вище відсоток релевантності, тим ближче за тематикою, та за обсягом семантики той чи інший конкурент до сайту, що досліджується.
Найпростіший варіант — відфільтрувати великі сайти, адже некоректно порівнювати себе з Amazon або Ebay. Тоді ми отримуємо ресурси, які плюс-мінус відповідають нам за кількістю ключів. Відсоток релевантності говорить про те, що ми працюємо за тією самою семантикою.
Також у Сумарному звіті відображається видимість конкурентів, яка є важливим показником. Якщо наша видимість знаходиться на рівні 0.2, то буде недоцільно брати в порівняння той сайт, який має видимість 0.04, — наша «помітність» у видачі більша, ніж у конкурента. Ми ж маємо орієнтуватися на тих, хто або на нашому рівні, або краще нас. Саме тому слід використовувати показник релевантності, щоб зробити добірку більш відповідною.
Ми вже розуміємо, що відповідає нам з семантики ціла низка сайтів. Але знову-таки згадуємо, що ми говоримо про всю семантику. Зверніть увагу на кількість спільних та «втрачених» ключів. Існує великий ризик того, що серед таких запитів будуть зустрічатися зовсім нецільові. Можна виділити окремі підходи, щоб з цим впоратися, використовуючи інструмент «Порівняння доменів».
Підбір ключових слів на основі перетину семантик конкурентів
Ми можемо зробити добірку з семантики та спробувати відфільтрувати те, що нам не знадобиться. І тут ми беремо тих конкурентів, які нас цікавлять найбільше.
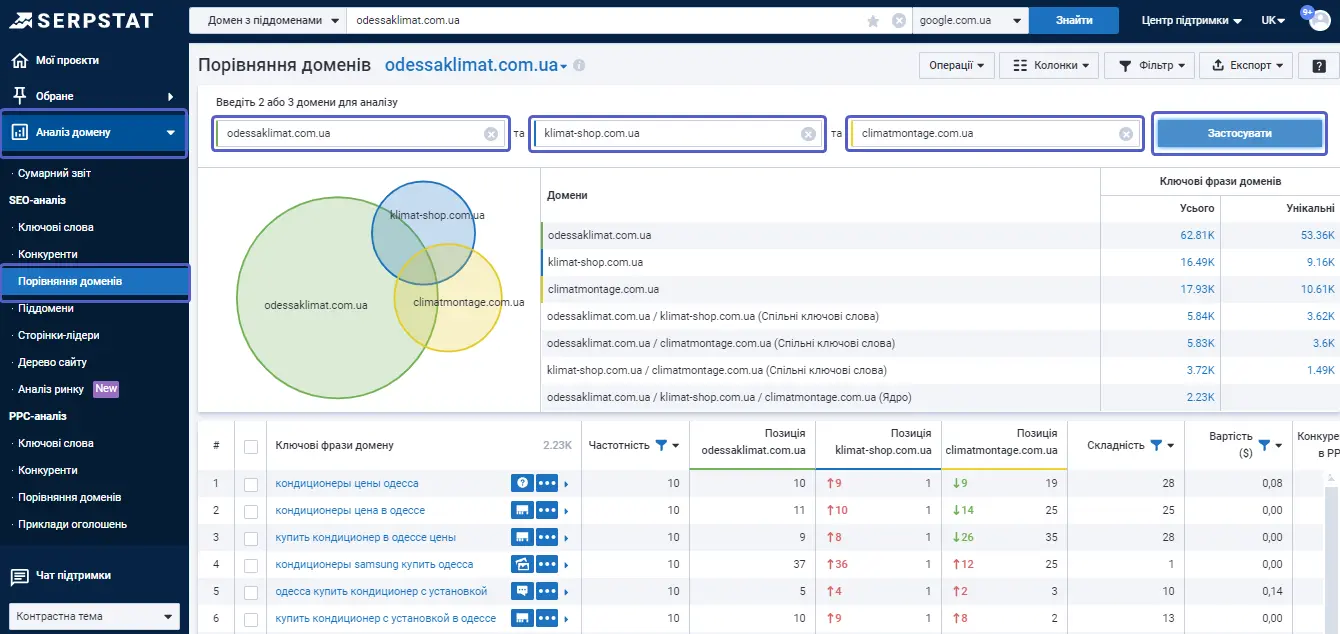
Принцип простий – намагаємось визначити ту семантику, яка відповідає тематиці.
Треба розуміти, що нам, швидше за все, буде цікава семантика, що знаходиться десь на перетині наших конкурентів. Вона є унікальною для обох наших конкурентів одночасно.
Але потрібно підходити до цього дуже творчо і розуміти, що якщо ваші конкуренти працюють за цими ключами, можливо, ви зіткнетеся з тим, що ці ключі мають високий рівень конкуренції. Тобто, за ними може працювати ще багато сайтів.
У місці, де ми маємо спільну семантику для всіх, рівень конкуренції буде найвищий:
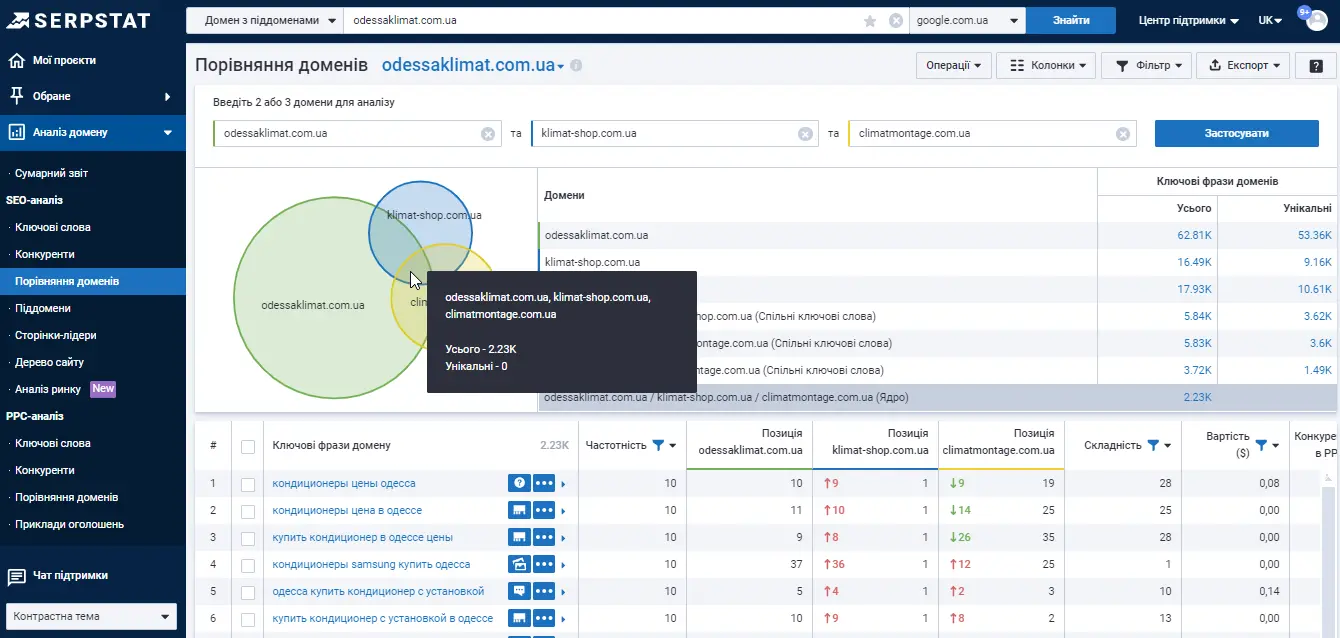
Але якщо ми говоримо про аналіз сайтів із дуже вузькою тематикою, є сенс сюди заглядати. Особливо, коли ви намагаєтеся сформувати семантичне ядро, тобто на початку робіт із сайтом, коли вам потрібно від чогось відштовхуватися.
Коли ви намагаєтеся сформувати ядро, перетин всіх сайтів і буде, найцікавішим для вас. Це класичний підхід при порівнянні та аналізі конкурентів.
Підбір унікальних ключів для конкурента
Ще одним із підходів у роботі SEO-фахівця є аналіз унікальних ключів. Тобто ми порівнюємо три сайти, але беремо до уваги тільки унікальні ключі, лише для одного проєкту:
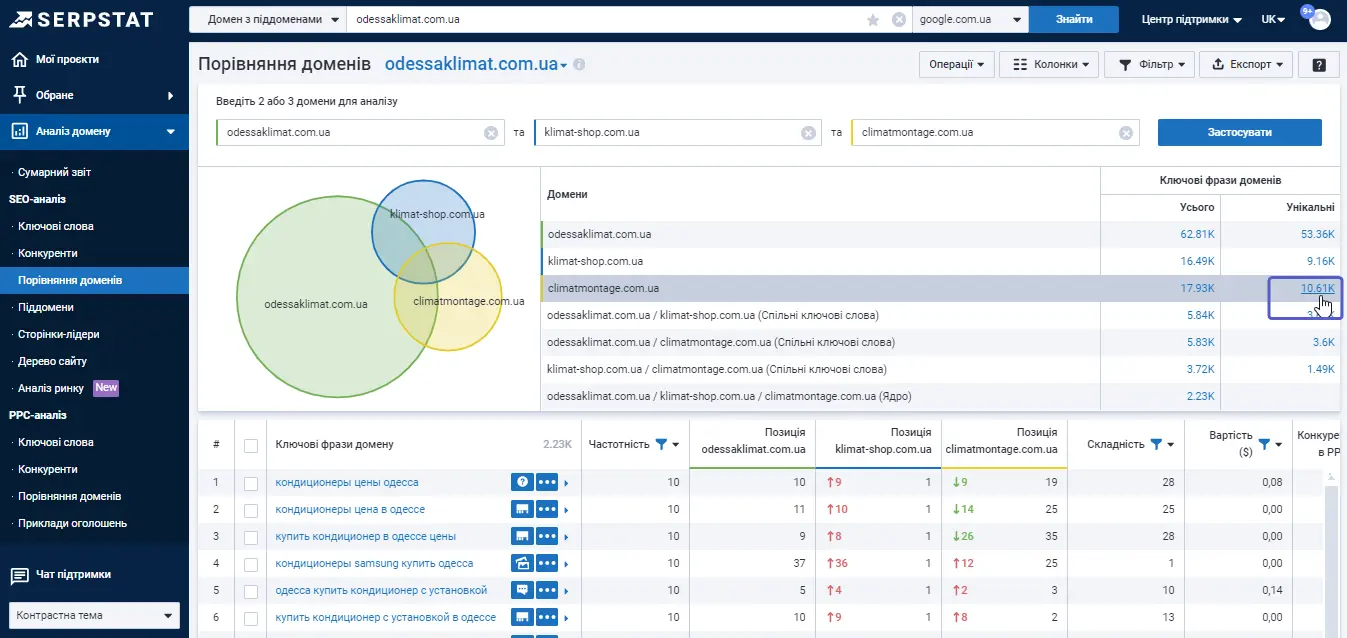
Вже саме ці ключі, унікальні, будуть не настільки конкурентними. Часто бувають ситуації, коли сайту ще немає, і ви не можете орієнтуватися на свою семантику. Тоді можна зробити таке ж порівняння щодо свого цільового конкурента.
Підбір конкурентів за допомогою «Аналізу ключових слів»
У Serpstat підбір конкурентів можливий і за допомогою «Аналізу ключових слів». Тобто, ви можете задати тематику через аналізатор ключових слів. Наприклад, якщо ми вже розбираємо тему «кондиціонери», платформа може аналізувати цей ключ і зробити добірку конкурентів на його основі.
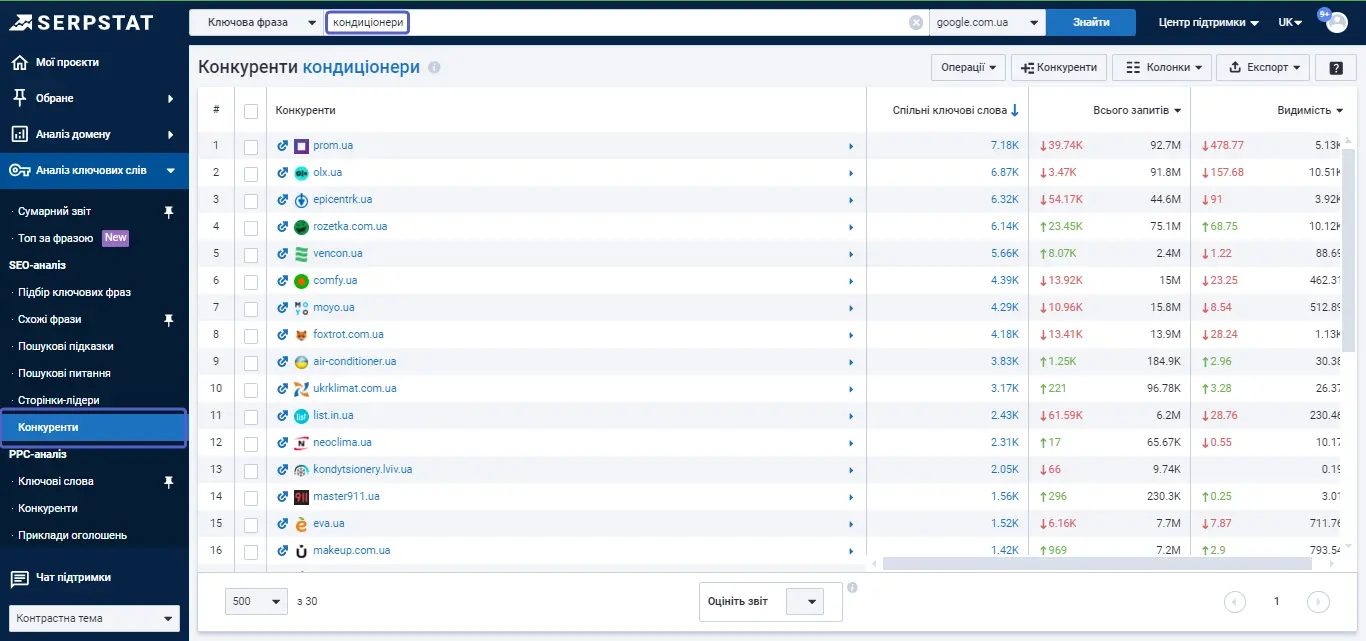
Тут важливо відзначити, що серед результатів буде багато великих сайтів, які важко порівняти з власним. Але ви побачите загальну кількість ключів сайту у видачі і зрозумієте, який сайт буде найближчим.
У базі є багато запитів, що побудовані на основі головного ключа «кондиціонери», вони точно входять в тематику. Є й приклади з непоганим рівнем видимості, gree.com.ua та cooper-hunter.com.ua, які можна брати для розбору. Далі потрібно зрозуміти, як вони формують семантику та як працюють із контентом. Це все класичні підходи.
Підбір конкурентів за допомогою «Моніторингу позицій»
Тепер — некласичний підхід, конкуренція на основі тих ключів, які ми відстежуємо для власного сайту. Традиційно до моніторингу ми завжди додаємо ті ключі, які нам максимально цікаві. Саме тому вибір конкурентів тут буде більш релевантним.
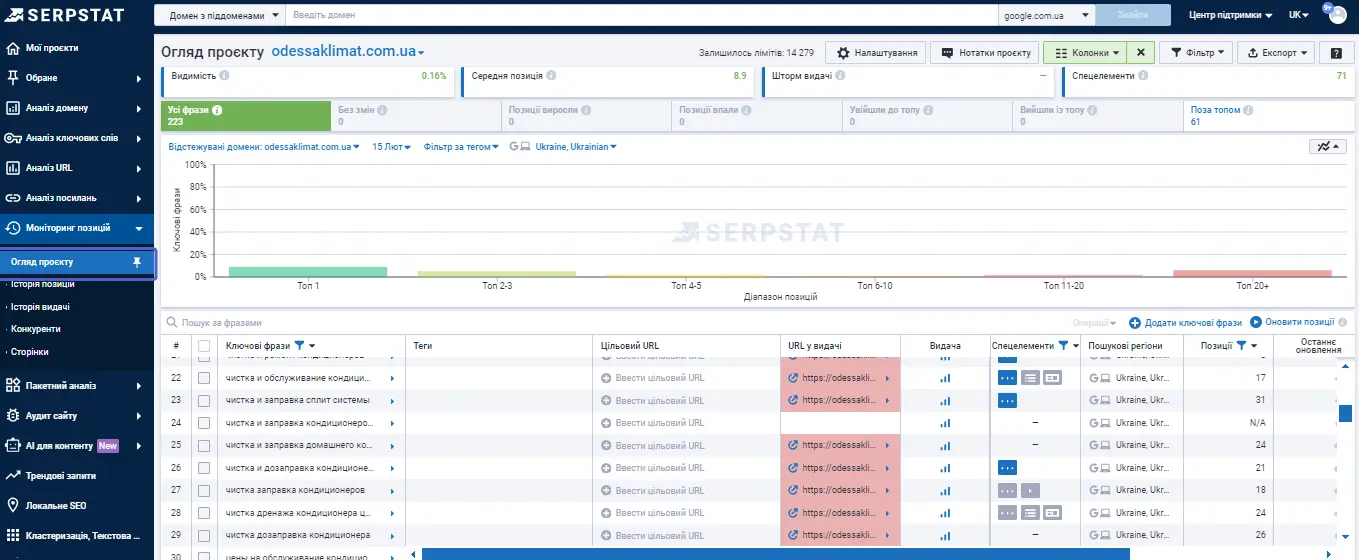
Ми визначаємо ключ та його позицію, але насправді робимо це не тільки для свого сайту, а для всього зрізу ресурсів, які потрапляють у топ-100. Це виглядає так:
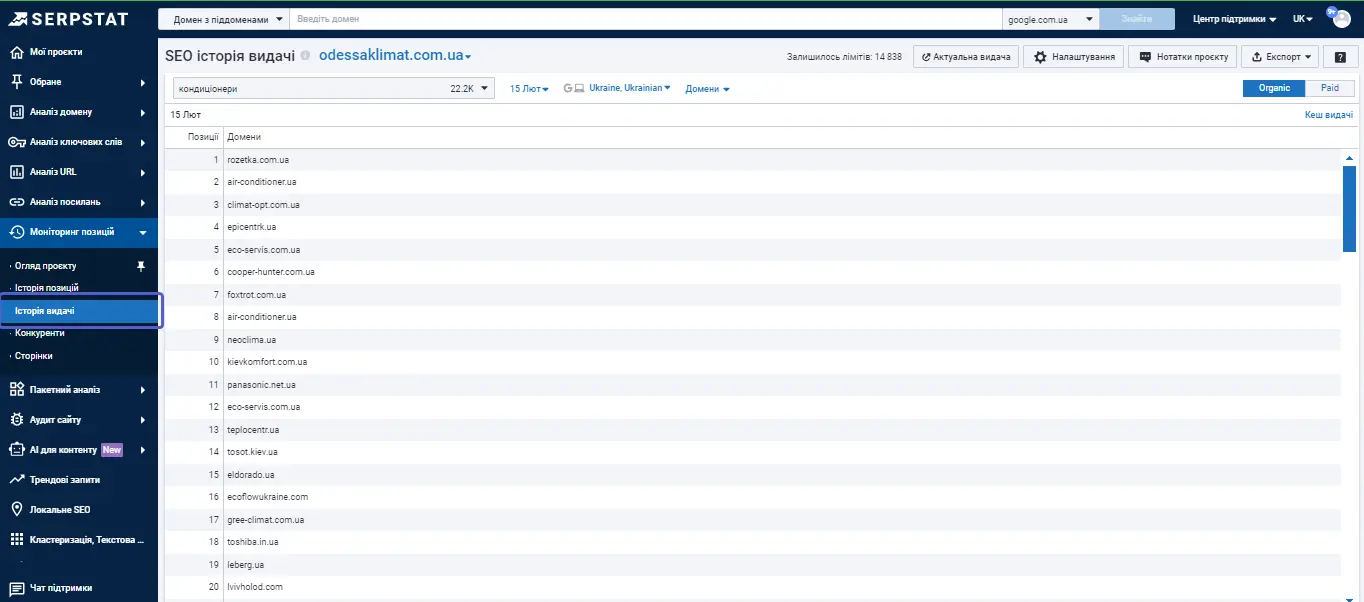
Тобто, ми вже розуміємо хто знаходиться в топ-100 зараз і отримуємо додаткові дані щодо конкуренції. Ми можемо зробити певний зріз ринку на цей час за всіма цільовими ключами.
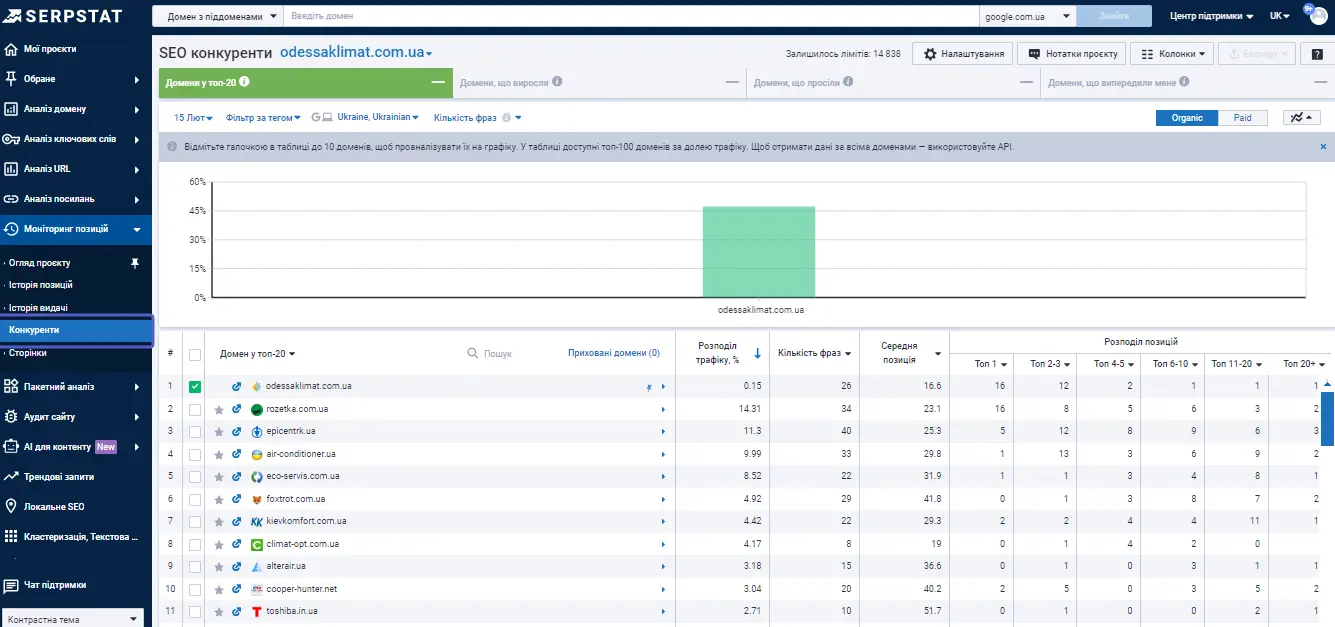
Тут знову бачимо сайти, з якими не плануємо конкурувати, є можливість їх приховати.
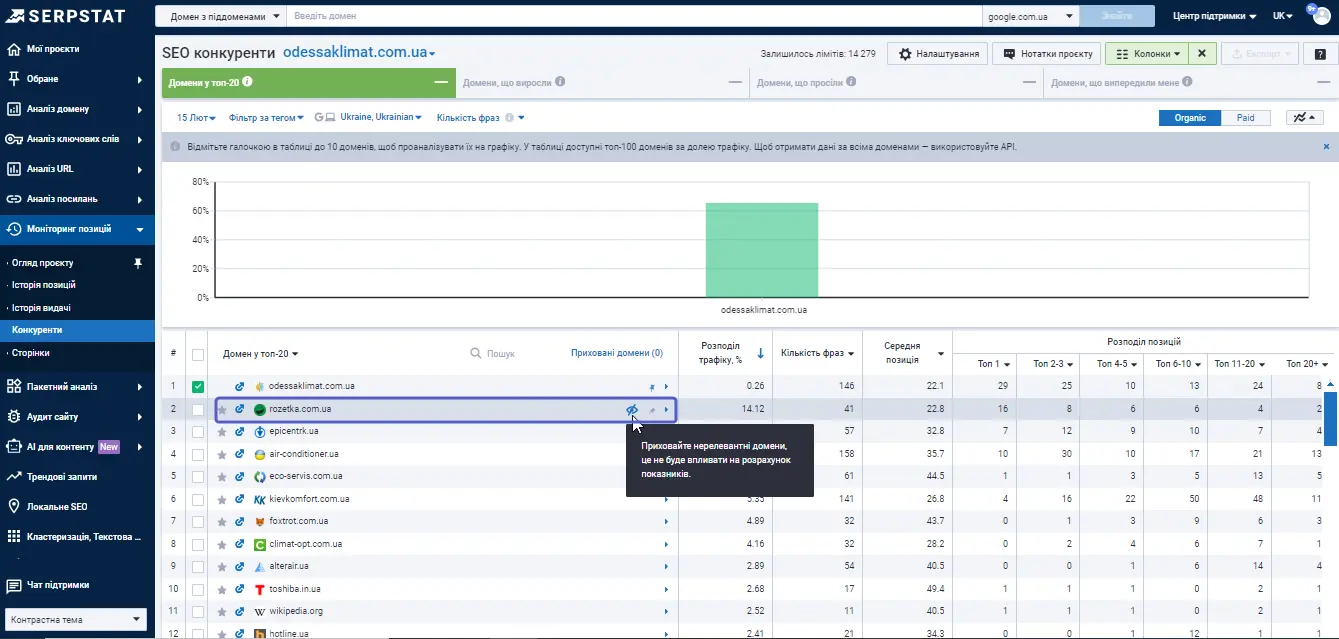
Таким чином, отримуємо потрібний список конкурентів на ринку, сформуємо те конкурентне середовище, в якому нам комфортно працювати.
Підхід дозволяє визначити, у кого яка частка і хто як працює на ринку. Наприклад, виникла ситуація, що у нас цільових запитів у проєкті близько 250, а фактично робочих – 146 (за ними ми ранжуємось в межах топ-100).
Це дуже хороший приклад того, як починати роботу для нового сайту: визначаєте цільові ключі, вони можуть бути зовсім не опрацьовані на сайті, але ви ставите їх на відстеження. Після цього можна зрозуміти, що за деякими цільовими запитами ви взагалі не потрапляєте до топ-100.
Варто орієнтуватися на серйозніших конкурентів. Ми бачимо досить багато сайтів, де кількість фраз більша, середня позиція вища, їх і треба аналізувати, розбирати найважливіші сторінки.
Аналіз конкурентів у пошуковій видачі
Бувають ситуації, коли попри всі наші зусилля сайт залишається на слабких позиціях за ключами. Або взагалі не виходить у топ-100.
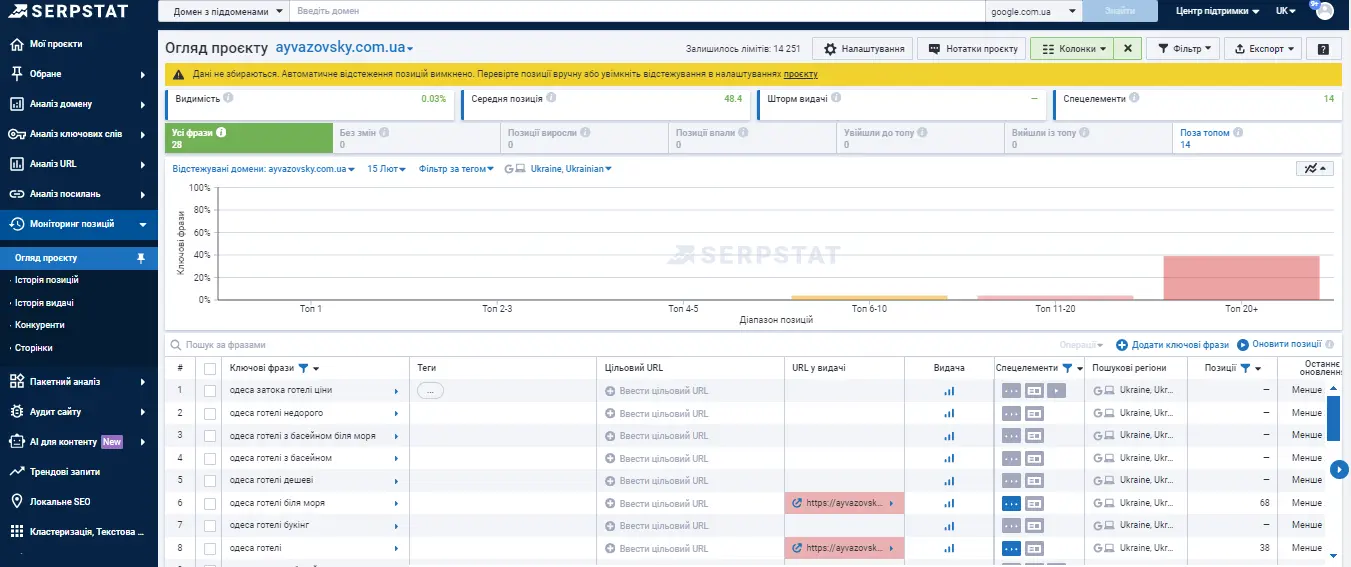
Тоді слід перейти у видачу та подивитися, що відбувається. Власне, видача — це також один зі способів аналізу конкуренції. За великим рахунком, головне — аналіз не тільки сайтів у топ-10. Вони там закріпились, їх складно вибити. Цікаві нам ті, хто намагається протягом кількох місяців пробитися у топ і робить це успішно. Це і будуть круті зразки для наслідування.
Бажано звернути увагу саме на такі пробивні проєкти, а потім провести базовий розбір їхніх сторінок — перевірити метатеги, заголовки, наявність часто задаваних питань (FAQ), кількість входжень ключових слів, використання синонімів тощо.
Іноді після базового аналізу не виходить знайти жодних об'єктивних причин, чому сайт знаходиться в топ-10. Найчастіше причиною є авторитеті і сильний посилальний профіль. Варто зробити додатковий аналіз домену та цієї сторінки через «Аналіз посилань».
Тоді зрозуміло, що треба працювати не над структурою чи контентом, а шукати шляхи збільшення своєї посилальної маси. Найчастіше це єдиний спосіб пробитися в топ.
Отже, ми розглянули два основні підходи в аналізі конкурентів — на основі пошукової аналітики з бази Serpstat та на основі даних Моніторингу. У першому випадку є ризик отримати дані не 100% актуальними (повне оновлення бази запитів може займати до трьох місяців). У другому — актуальність даних становить 100%. Тепер розглянемо, як із таким самим завданням справляється агентство.
Аналіз конкурентів за допомогою API Serpstat
В Inweb ті ж дані беруться з Serpstat, але при цьому використовується API та вибудовуються метрики та дашборди на стороні агентства. Ви можете інтегрувати API Serpstat у свої внутрішні інструменти й оперативно отримувати необхідні дані.
Ось приклад такого інструменту:
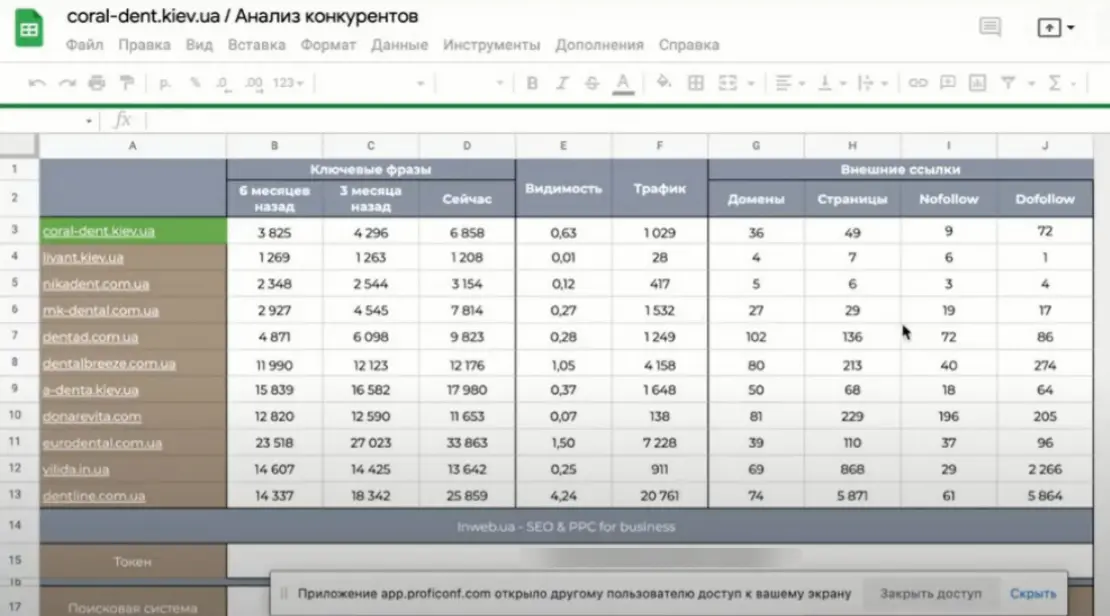
Звіт використовується для оцінки конкуренції сайту і створюється на етапі пресейлу, щоб розуміти показники аналізованого сайту та надати цю інформацію клієнту. В таблиці є налаштування пошукової системи, — Google практично в будь-якому регіоні. Для старту потрібно ввести свій домен та натиснути на «Отримати дані»:
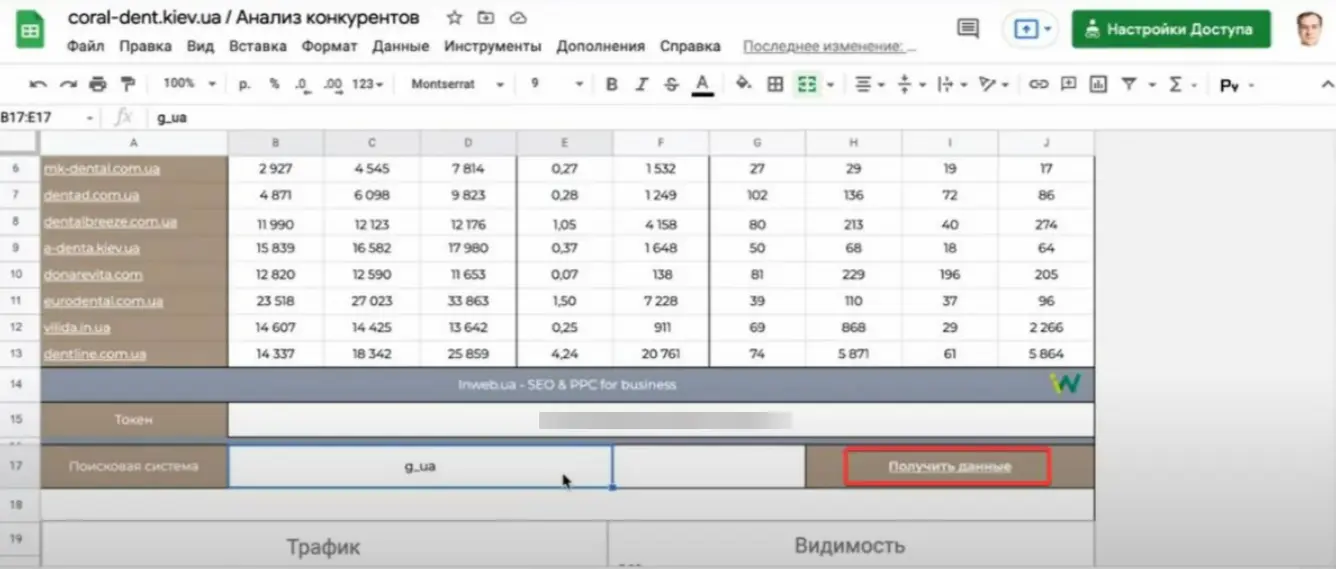
При натисканні запускається скрипт, який починає отримувати дані з Serpstat. Основні конкуренти визначаються із спільних ключових фраз. В результаті отримуємо 10 конкурентів. Далі, після виконання цього методу API здійснюється звернення по кожному домену різними методами для отримання відомостей за ключовими фразами. Відображаються дані за 6 місяців, 3 місяці і на зараз, щоб бачити динаміку за власним та конкурентним доменом.
Доцільніше орієнтуватися на ключові фрази, оскільки видимість не завжди об'єктивно відображає ситуацію, а трафік складно порахувати точно.
Алгоритм розрахунку трафіку у всіх платформ приблизно однаковий, і він часто не демонструє об'єктивну ситуацію, тому що його неможливо точно дізнатися не власникам сайту (із доступом до Google Analytics). Ще слід врахувати, що частотність запитів також рахується орієнтовно.
Аналогічно, до кожного домену йде запит на отримання даних за зовнішніми посиланнями. В API є окремий метод для отримання цієї інформації. Тут вказується кількість доменів та сторінок, що посилаються. Також відображається кількість nofollow і dofollow посилань.
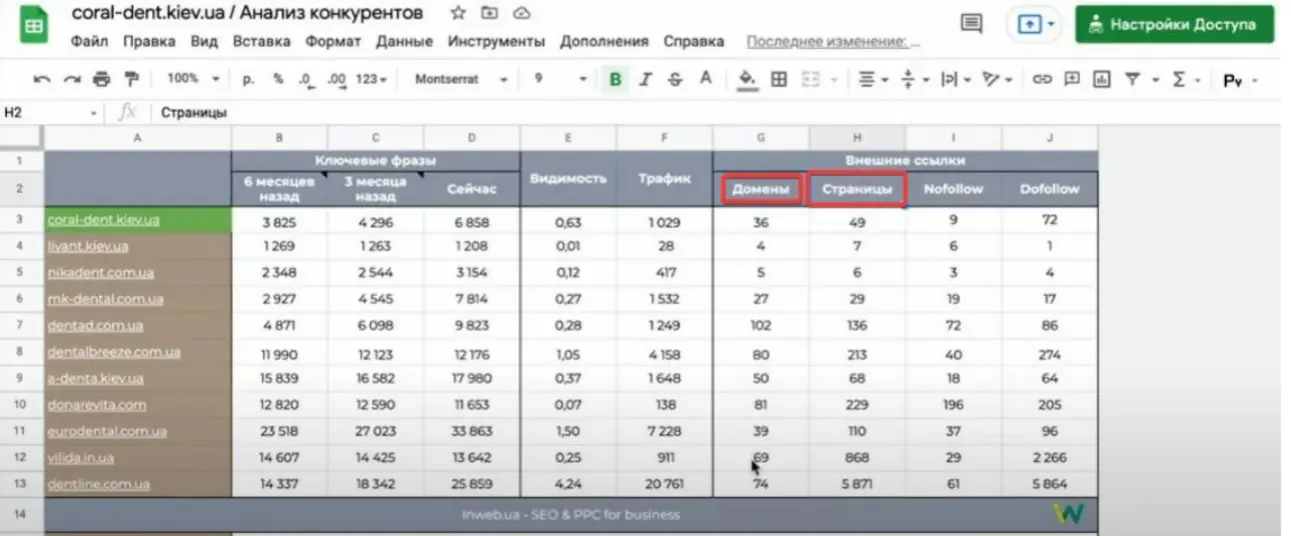
Далі, виходячи з цих даних, будуються графіки.
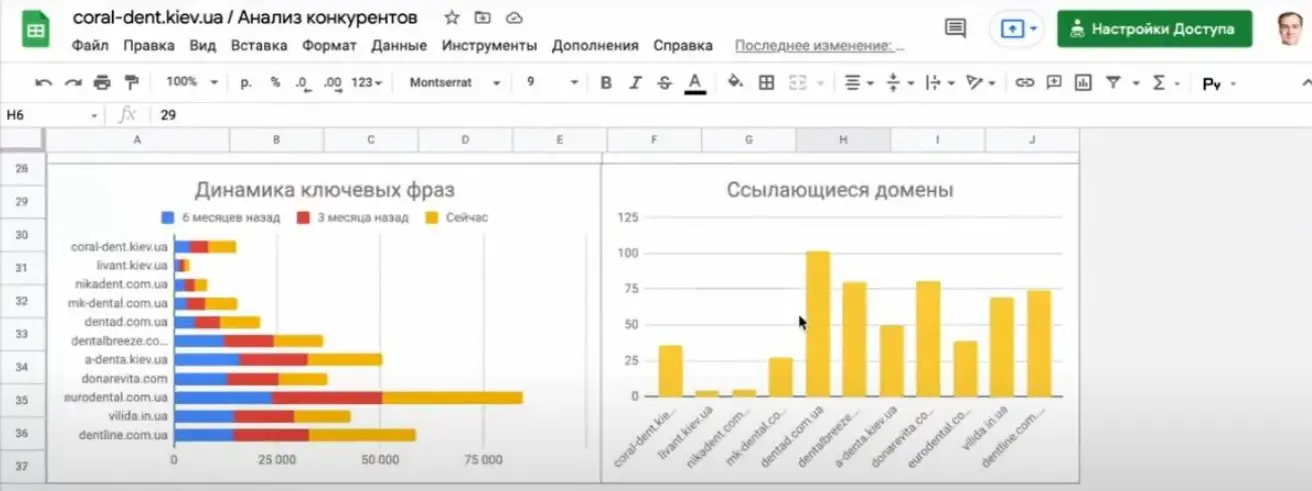
Збирається інформація досить швидко, вранці та ввечері. Потрібно натиснути кнопку та скрипт автоматично перезаписує всі дані. Тобто всі ті дані, які можна отримати в інтерфейсі Serpstat, ми можемо віддати по API, зекономивши час та підлаштувавши дашборди під свої потреби.
Аналогічні функціональності є в особистому кабінеті:
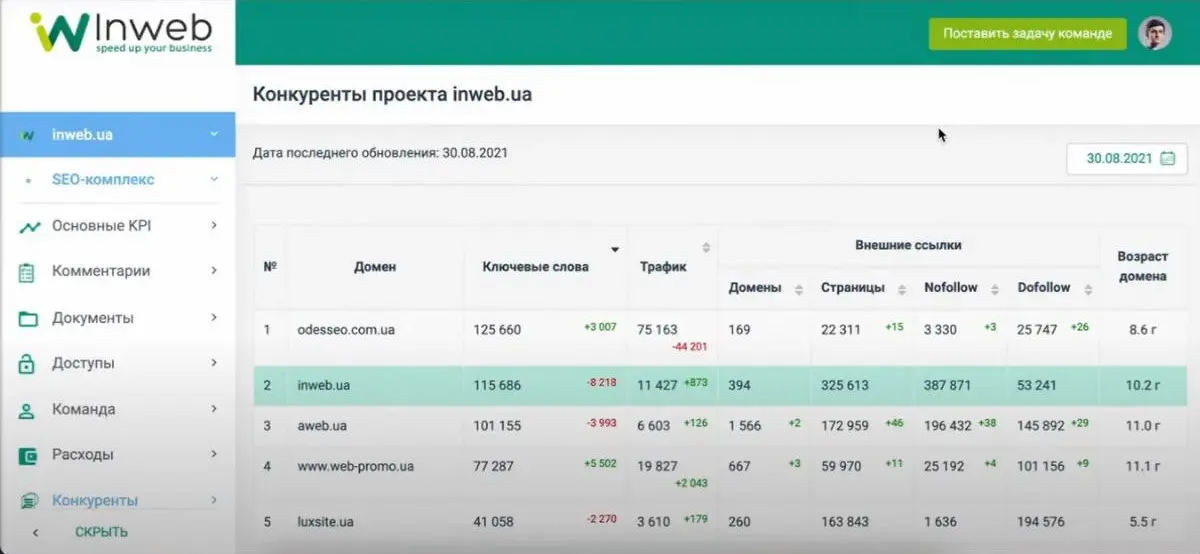
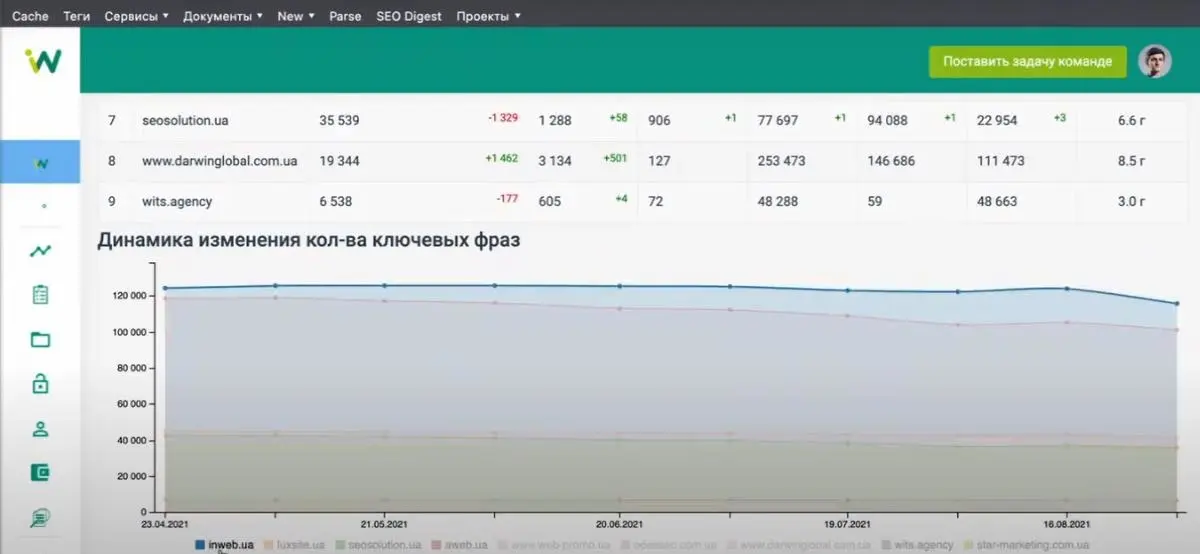
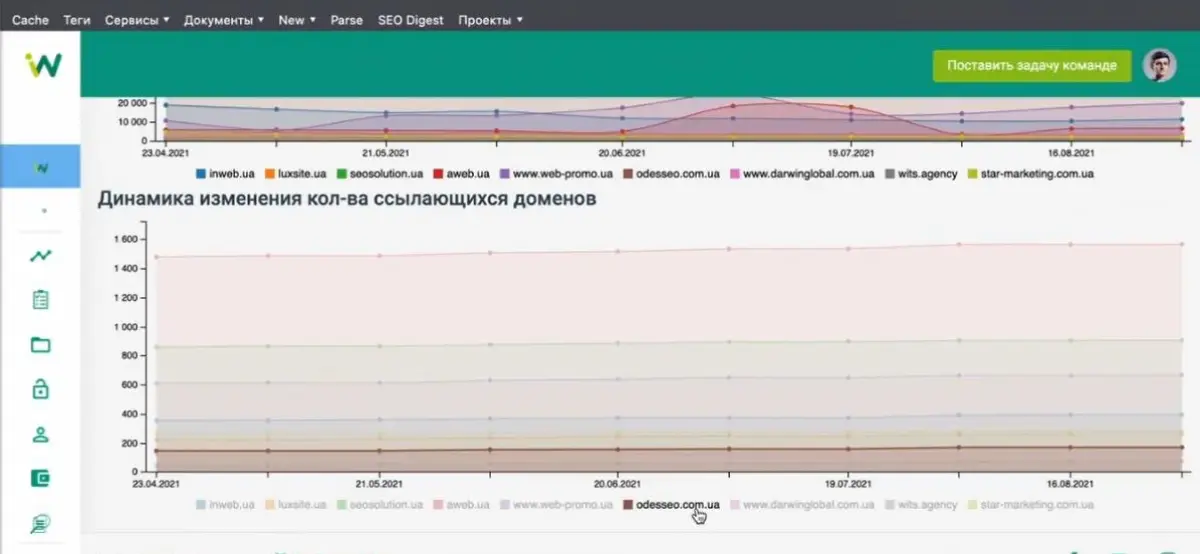
Інформація оновлюється приблизно раз на 2 тижні, всі дані підтягуються незалежно. Повністю дашборд оновлюється раз на два тижні і робити це частіше немає сенсу. Ця інформація доступна для клієнта, а за потреби можна вручну додати конкурентів на запит замовника.
Деякі із API-методів Serpstat можна застосувати одразу в Spread Sheets, з відповідним розширенням для пакетного аналізу доменів, фраз, або навіть сторінок в Google таблицях.
Підходи до порівняння доменів та вибору фраз для просування
Є деякі аспекти й у виборі запитів для просування. Часто багато компаній ставлять супер-амбітні цілі за дуже крутим ключем, наприклад, просунутися в топ за словом «кондиціонери».
Успішність просування при цьому залежить від ключа та сайту, який потрібно просувати.
Немає сенсу працювати лише за конкретними ключами. Кінцева мета — це не певні ключові слова. Наприклад, якщо ставити мету бути в топ-1 за запитом «купити кондиціонер», то упускаються інші, менш конкурентні та частотні ключі.
Варто враховувати, що за деякими ключами ще й підсумкова конверсія може бути дуже висока. Наприклад, якщо проаналізувати в «Аналізі ключових слів» ключ «кондиціонер», то ми отримаємо круту частотність, але дуже високий рівень конкуренції, навіть у контексті.
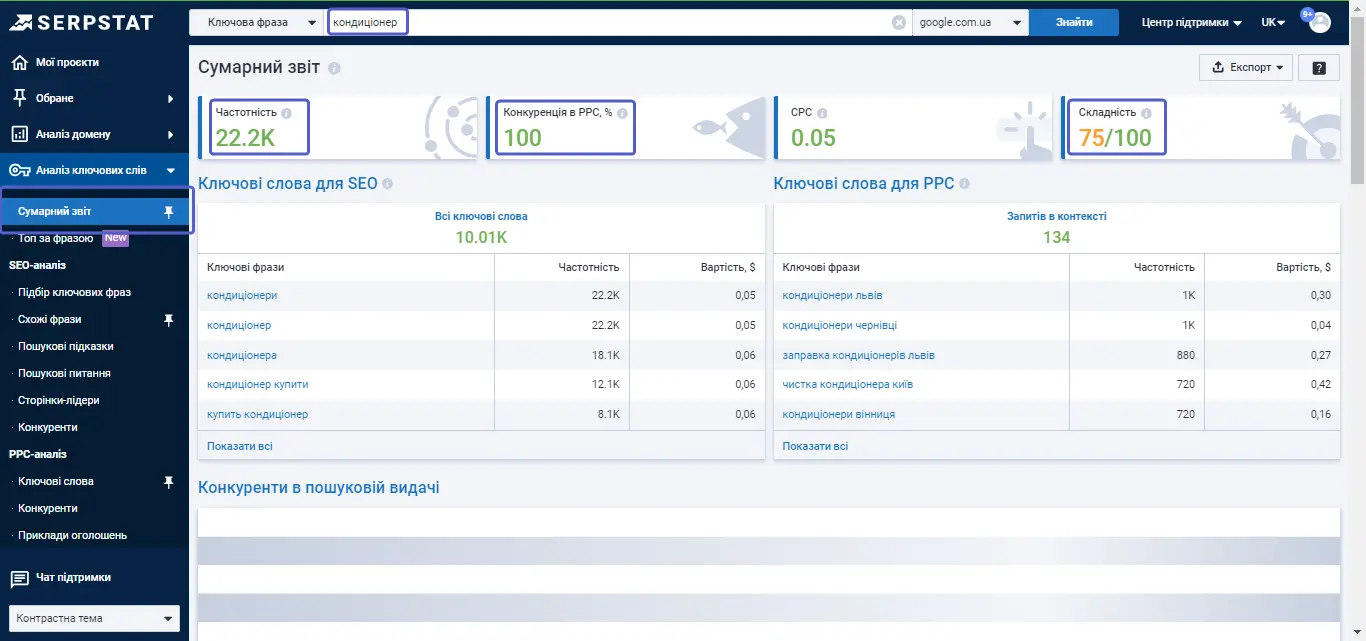
Плюс, за запитом висока складність просування. Дуже проблематично просуватися за такими глобальними темами, тому що топ вже зайнятий. В цьому випадку на допомогу приходять інші інструменти. Наприклад — «Підбір ключових фраз».
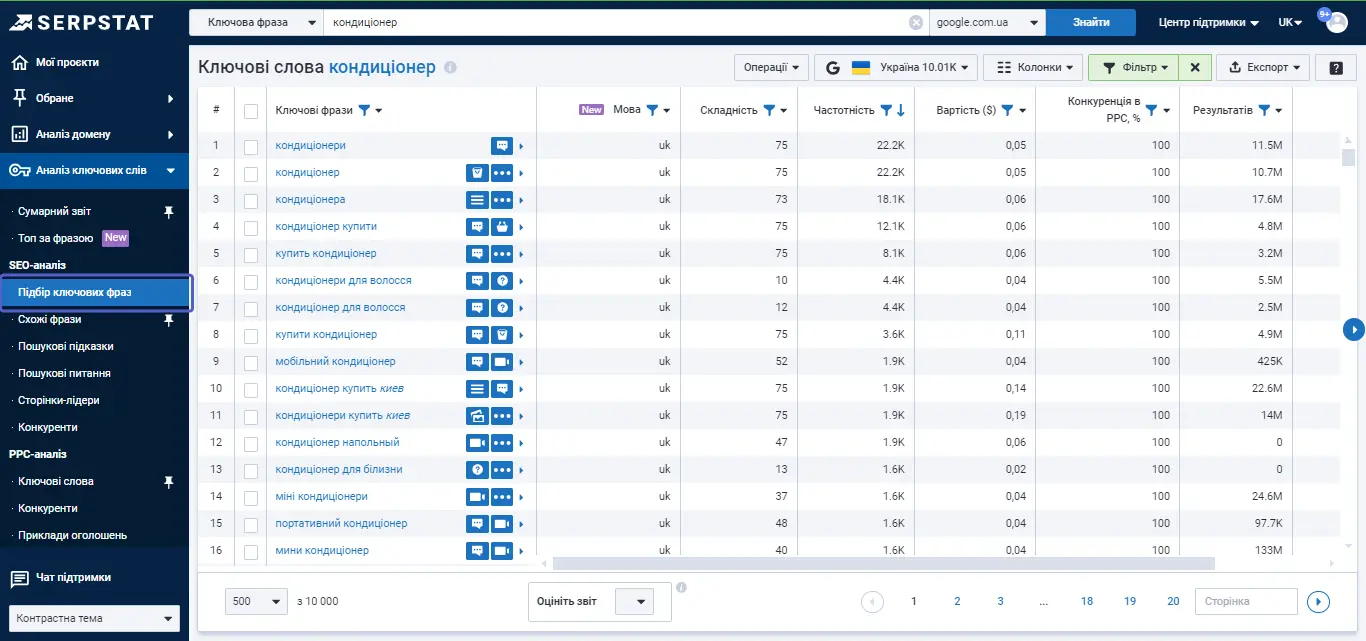
Цей інструмент дозволяє знайти фрази, які є максимально близькими до бажаного ключового запиту. Тут варто звернути увагу на параметр «Складність»: якщо складність на рівні 75, то буде проблематично просунутися за цим запитом. Є й ті ключі, які генеруватимуть певний трафік на сайт, але рівень їхньої конкуренції буде значно нижчим.
Безумовно, якщо ви не займаєтесь заправкою кондиціонерів, то й просуватися за таким запитом немає сенсу. Але можна зробити вибір на користь тих ключів, які допоможуть це зробити максимально легко. Для зручності у Serpstat є сортування за спаданням складності.
Ще одна корисна фішка — «Пошукові підказки».
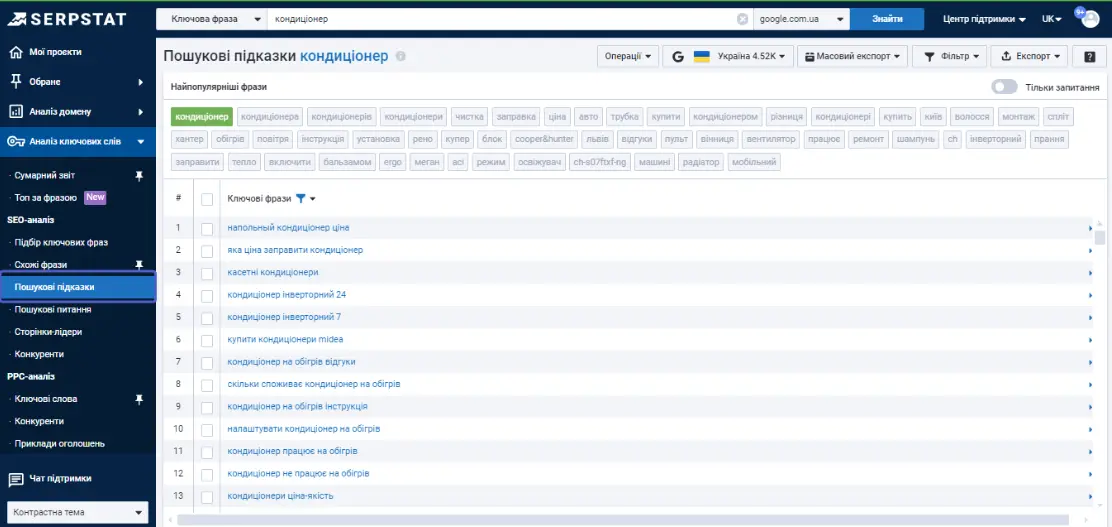
Їх доцільно використовувати, коли потрібно набрати «long tail» запити, які є легшими для просування порівняно з короткими фразами. Тому long tail ключі часто використовуються як цільові запити на перших етапах просування сайту — за ними ми можемо найшвидше отримати результат. Наприклад, на запит «кондиціонери для вантажних автомобілів» буде набагато легше отримати результат, ніж за ключем «кондиціонери».
Також варто звернути увагу на «Схожі фрази». Цей інструмент корисний для розуміння того, який контент писати, які ключі використовувати.
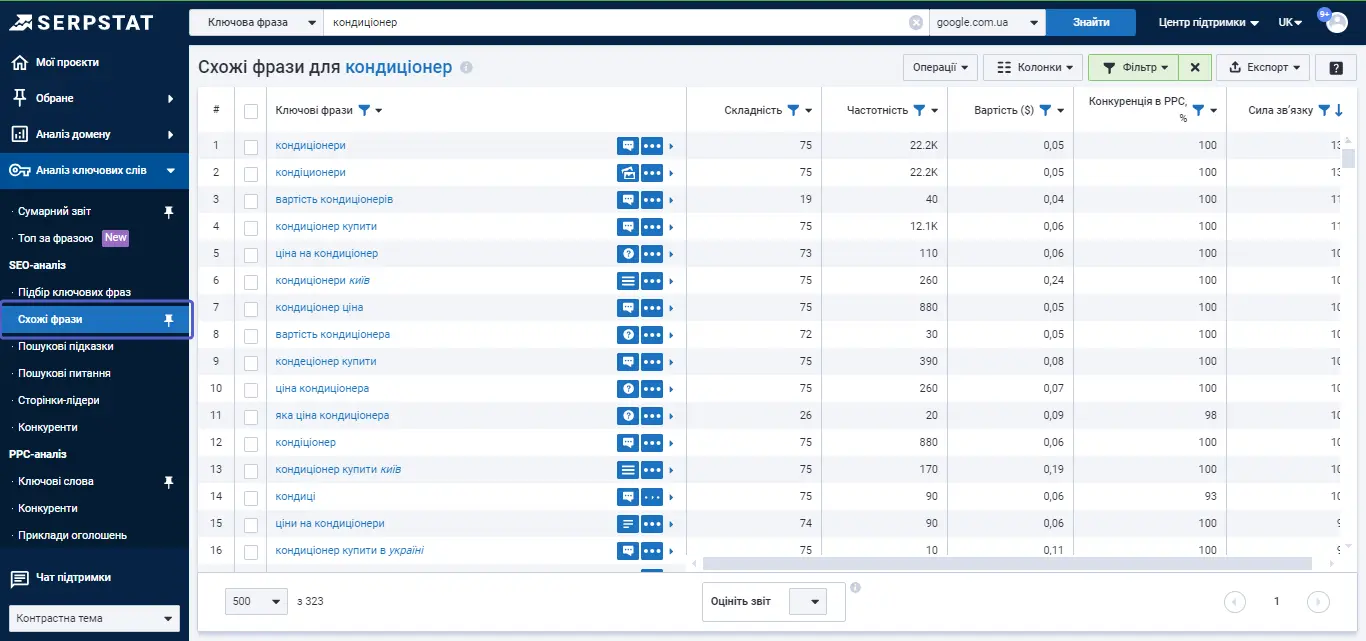
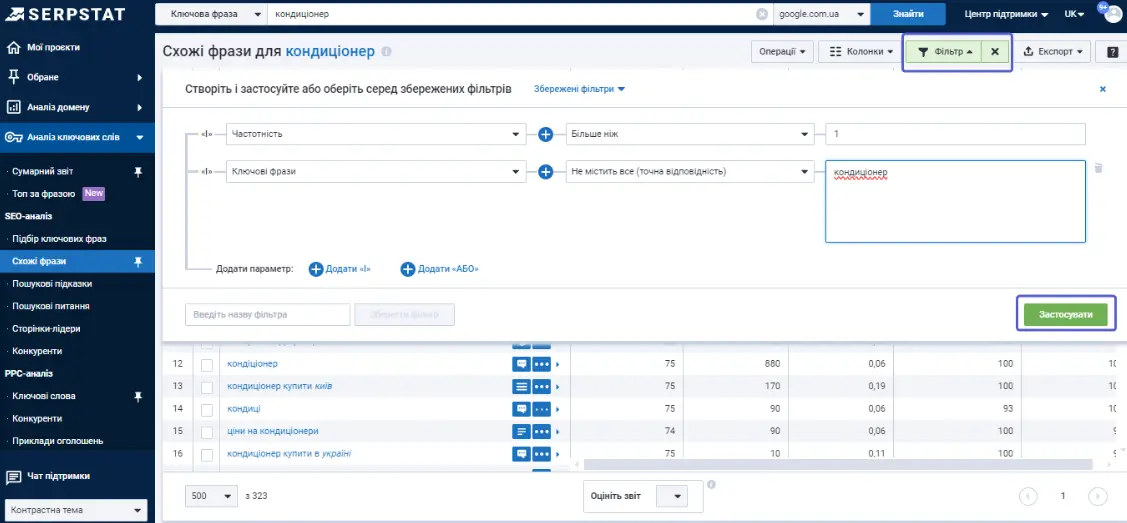
Можна відфільтрувати всі ключові фрази зі словом кондиціонер, за потреби.
Так можна знайти додаткові запити, наприклад «скільки електроенергії споживає обігрівач».
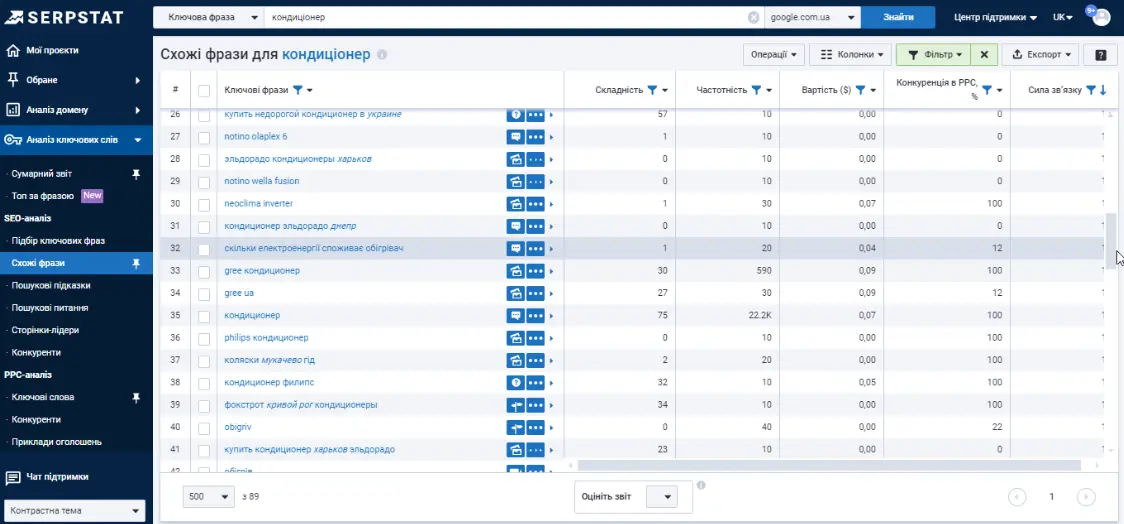
Можна знаходити варіативні ключі, які «битимуть» за тією ж тематикою і при цьому допомагатимуть уникнути переспаму. Якщо цікавить тематика формування контенту, буде корисно подивитися «Пошукові питання».
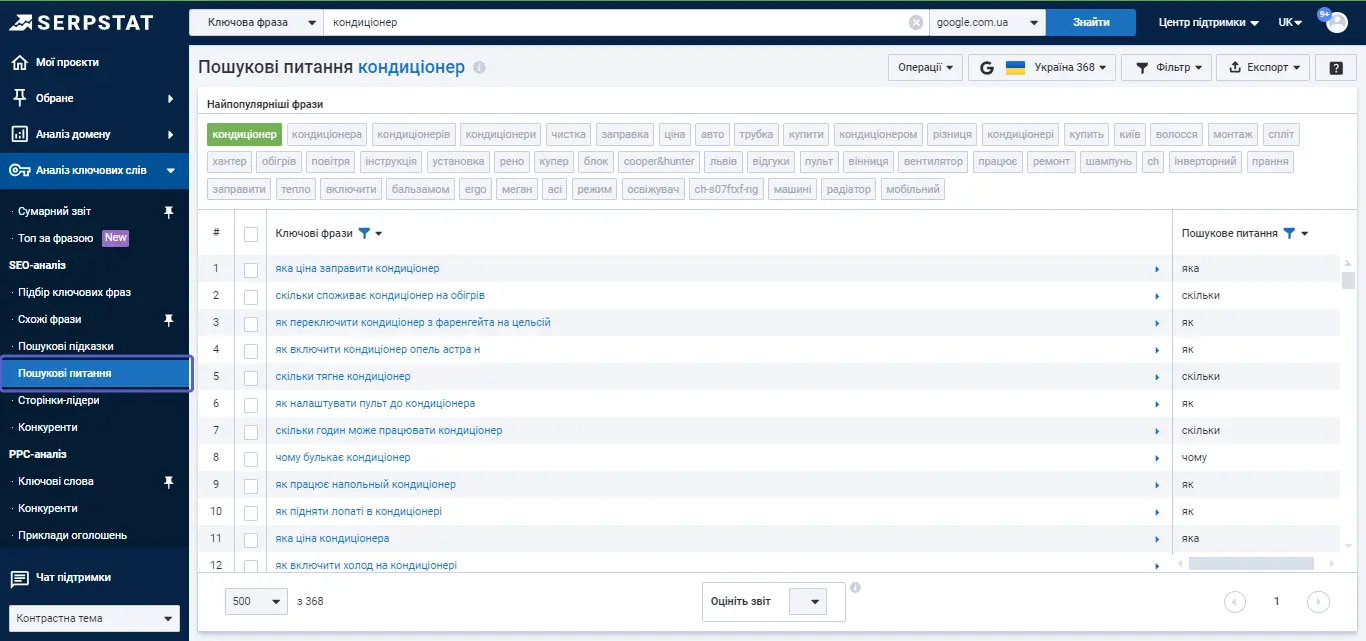
На основі цих запитів можна сформувати питання, якими задаються читачі. Наприклад, якщо ви займаєтеся інсталяцією кондиціонерів, ви можете використати «встановлення кондиціонерів» і подивитися питання, які ставлять користувачі онлайн з використанням цього ключа. Serpstat збирає такі запити просто з пошукової системи.
Отже, якщо існує загальний цільовий тематичний запит, далеко не завжди потрібно намагатися просунутись саме за ним. Швидше за все, вам потрібно просуватися просто шляхом охоплення тематики.
Тобто використовувати якнайбільше варіацій того чи іншого ключа, синонімічних і схожих за значенням фраз, а також, намагатися сформувати контент, який закриває якусь цільову тематику, а не орієнтований конкретно на одне слово. Інакше у вас є великі ризики потрапити під спам-фільтр, і тоді можуть виникнути проблеми при ранжуванні.
Збір семантики за допомогою API
В Inweb для роботи з семантичним ядром розробили розділ «Інструменти».
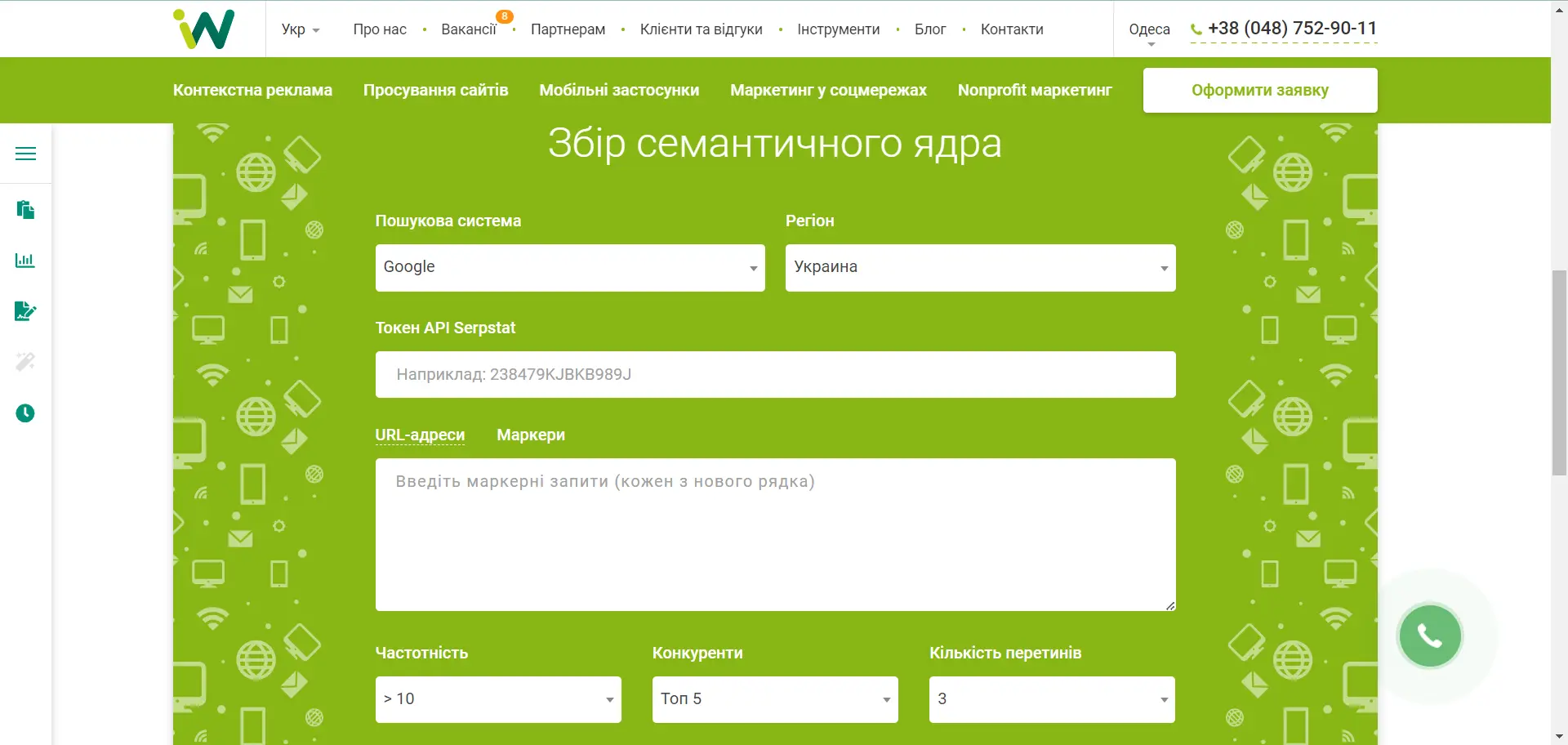
Агентство давно використовує API Serpstat для збору семантики за допомогою свого унікального алгоритму. Цей інструмент може використовувати будь-хто. Єдине, що потрібно — API-ключ. Також потрібно вказати пошукову систему, регіон та токен. Далі є два варіанти: URL-адреси чи маркерні запити.
Також можна додати стоп-слова, відфільтрувати інформаційні запити, додавши «як», «що» та ін.
Збір семантики з маркерами
Розглянемо роботу із маркерами. До прикладу, нам треба зібрати семантичне ядро на сторінку ремонту iphone. Найголовнішим запитом буде «ремонт iPhone», його ми і пишемо, можна вказати кілька маркерів, це будуть різні кластери. Після цього натискаємо «Ок», у нас з'являються релевантні запити за двома кластерами.
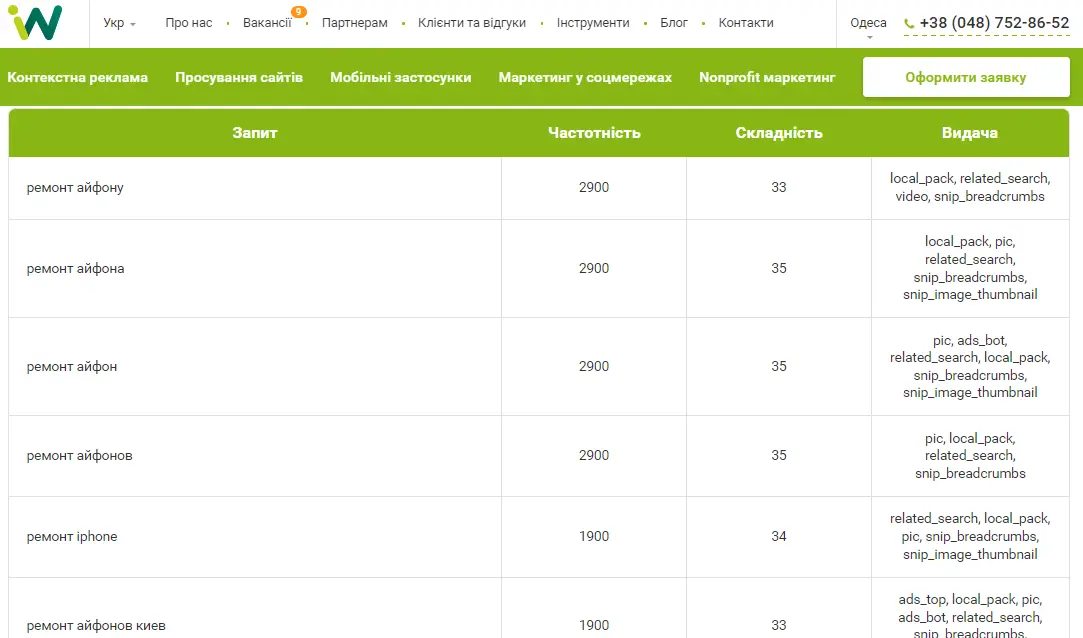
Як це працює: за ключем «ремонт iphone», ми звертаємося по API до Serpstat, щоб отримати топ-100. З одержаного списку, беремо топ-10, по кожному домену із цих 10 запитуємо список ключових слів. Ми отримуємо 10 великих списків ключових слів. У підсумковий список ми додаємо лише ключі, які використовуються на п'яти сайтах з топ-10, це пошукові запити, які є у більшості з топу.
На збирання максимально релевантної семантики піде менше, ніж хвилина, проте тут є і сміттєві запити, їх потрібно відсортувати.
Збір семантики за URL-адресами
За URL-адресами — набагато простіше. Наприклад, потрібно зібрати семантику з ремонту iPhone. Ми заходимо у видачу, пишемо «ремонт iPhone», беремо кілька конкурентів і кидаємо сюди їхні URL-адреси. Далі вказуємо кількість перетинів. Наприклад, додали 5 конкурентів та вказали перетин 3.
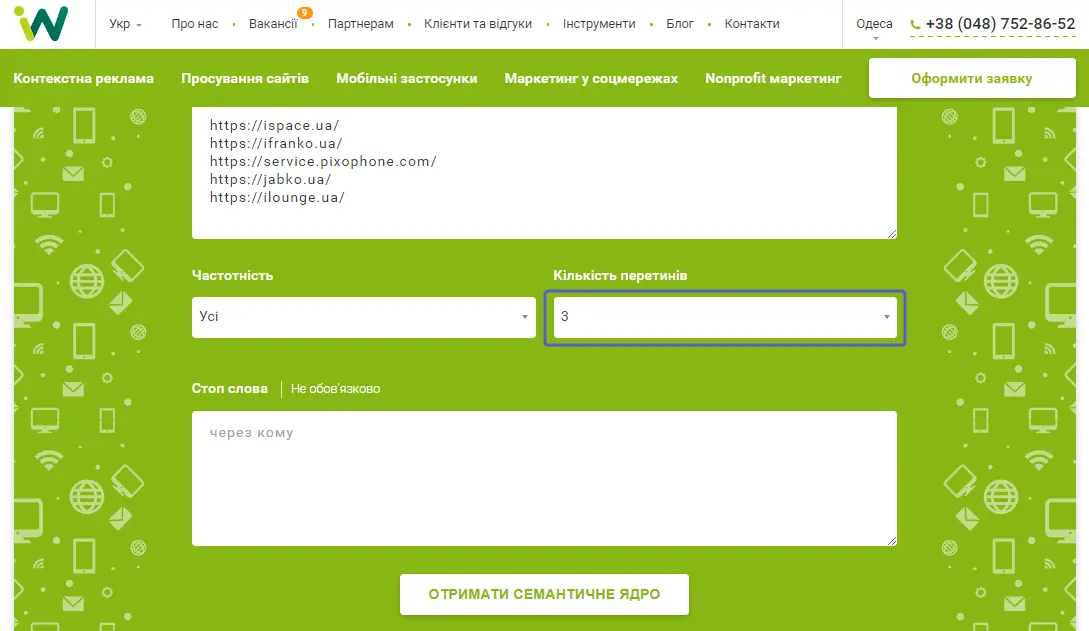
Чим менше перетинів буде, тим більшою буде семантика, але вона може бути менш релевантною. Можна вивантажити зібрану семантику у файл CSV.
Ще для роботи із семантичним ядром є «Перевірка частотності». Наприклад, можна вивантажувати ключові слова з різних джерел: взяти запити із Serpstat, додати ключові слова із Search Console та перевірити їхню частотність.
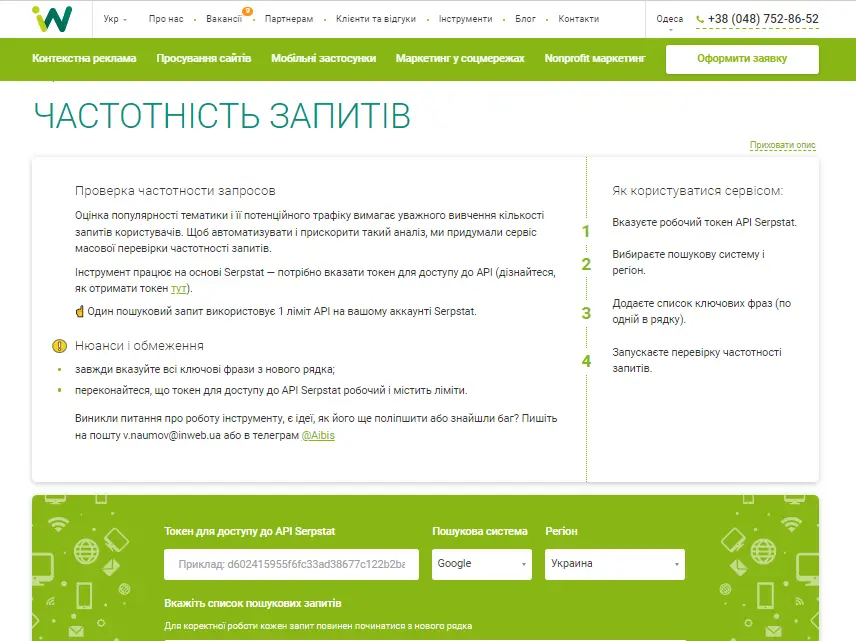
У Serpstat теж є пробивка частотності запитів за API, навіть у розрізі динаміки за рік — Парсинг частотності. Є конкретні кейси, коли це дуже важливо (для стартапів, для E-commerce). Один з найчастіших прикладів того, як працюють з даними з Search Console — пошук ключів для моніторингу в Serpstat. Це найпростіший кейс зі збору семантики для відстеження.
Використання «Дерева сайту» з семантикою свого та конкурентних сайтів
Serpstat має ще один інструмент, який чомусь часто є недооціненим — «Дерево сайту». Чомусь він досі програє за популярністю «Сторінкам-лідерам» (для пошуку найтрафіковіших сторінок):
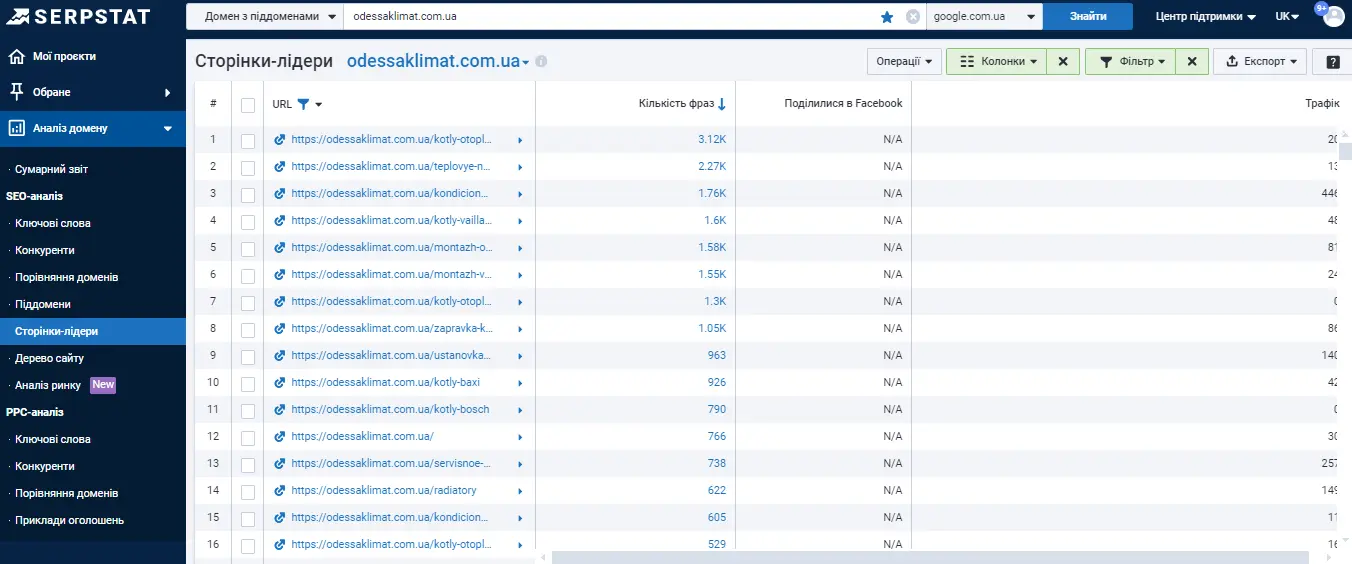
Алгоритм визначає сторінки, які виходять у топ за максимальною кількістю ключів. Проблема в тому, що при цьому враховуються й ключі, за якими сторінка знаходиться в топ-100, а до нього увійти не так вже й складно. Якщо за сторінкою маленький трафік, — з усіх ключів до топ-10 увійдуть одиниці.
Порівняємо те саме з використанням «Дерева сайту».
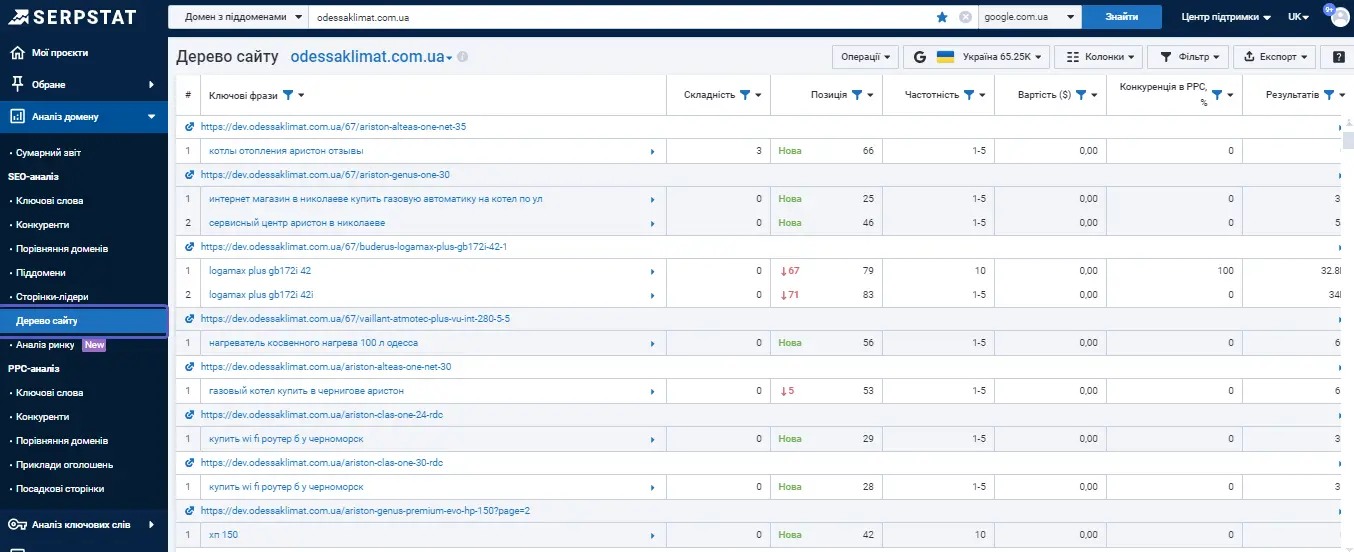
Наприклад, при аналізі сайтів-конкурентів вибираємо фільтр за позиціями з 1 до 10.
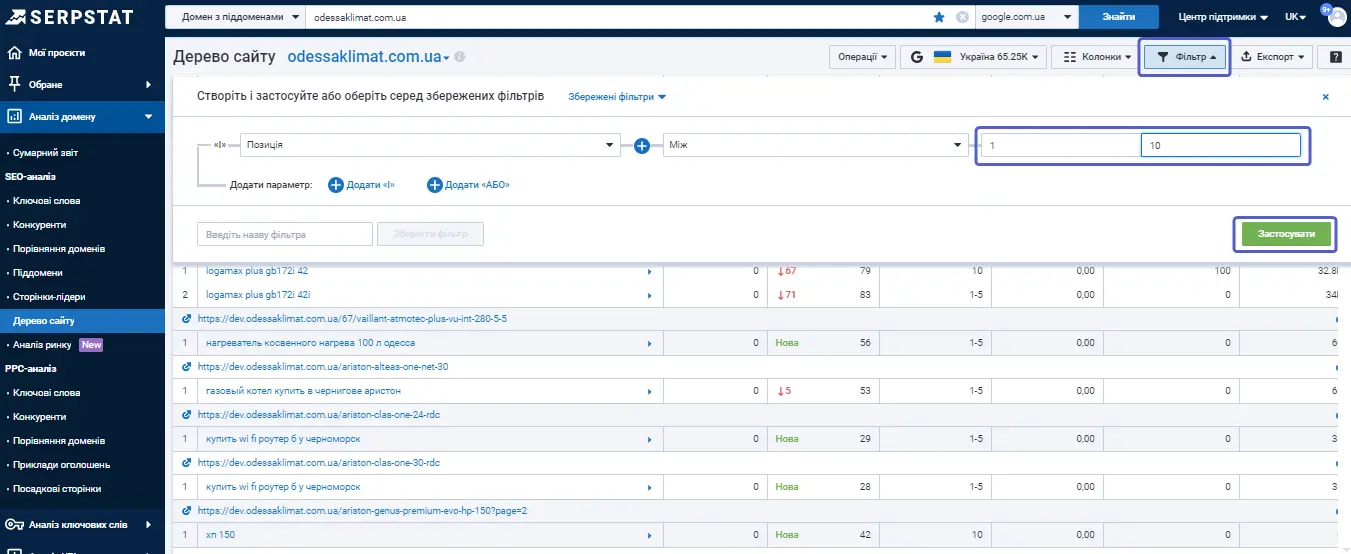
У підсумку отримуємо список сторінок та ключів, за якими конкурент є реально успішним.
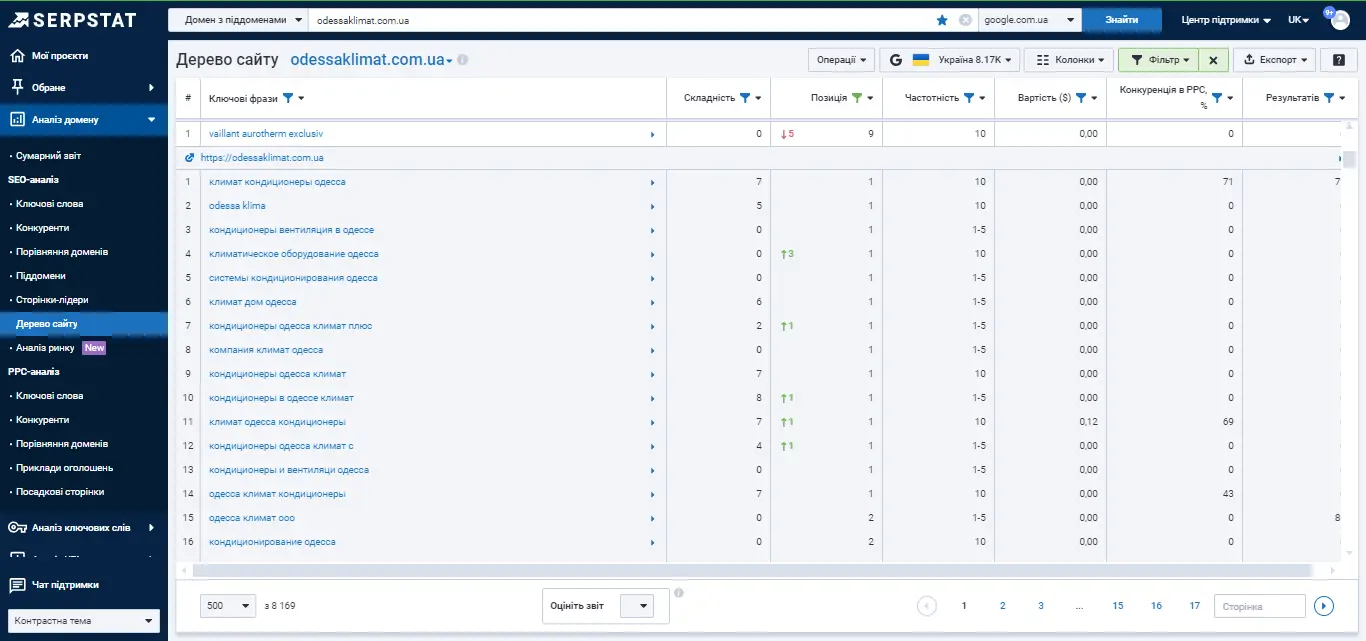
Тут багато низькочастотних ключів, які можна додатково відфільтрувати, наприклад, вказати частотність від 50. Тоді відобразяться дійсно круті сторінки з топ-10:
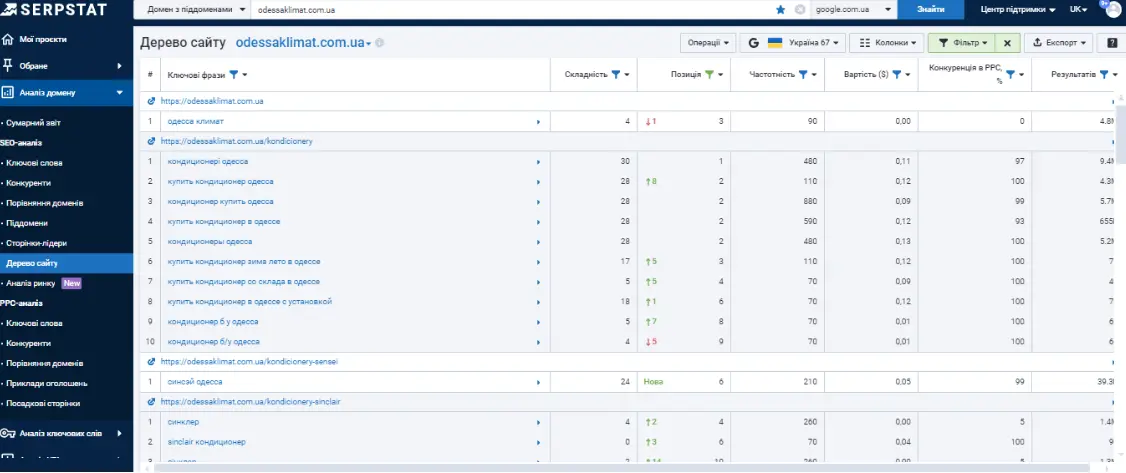
Потім можна здійснити базовий аналіз отриманих сторінок.
Потрібно розуміти, що «Сторінки-лідери» можуть заплутати вас, а «Дерево сайту» може допомогти навіть простіше. Також «Дерево сайту» рекомендується використовувати, коли ви шукаєте нереалізовані можливості. При аналізі будь-якого сайту слід розуміти, що все не буде ідеально. Скрізь можна знайти точки росту.
Наприклад, при аналізі цього сайту видно, що він має велику кількість ключів у топ-10, але зверніть увагу, яка кількість ключових фраз знаходяться у топ-20.
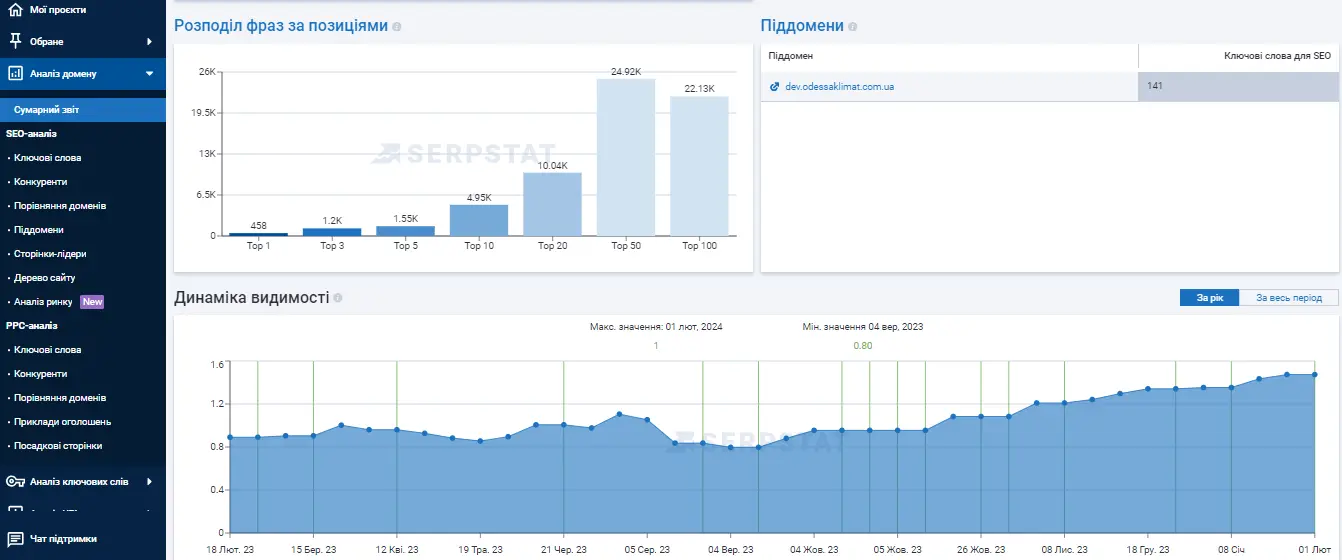
Щоб витягнути їх у топ-10, потрібно щось доопрацювати на деяких сторінках — переписати, додати контент.
Можна використовувати Дерево сайту інакше, зробити вибірку по-іншому. До прикладу, вказати позиції з 11 по 30 і додати фільтр частотності. Так ми отримуємо перспективні ключі, які можуть дати нам трафік, якщо вийти з них у топ-10.
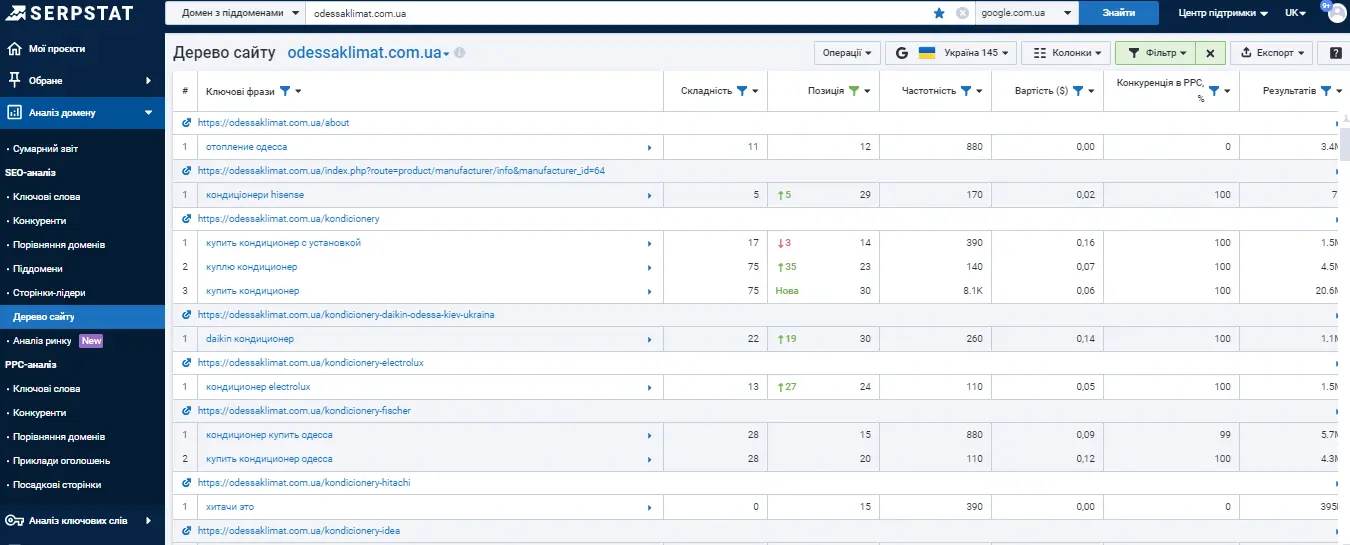
Так стає зрозумілим, де є нереалізована можливість, над якою можна попрацювати. Таким чином можна опрацьовувати ключі, за якими ви знаходитесь в топ-100.
У підсумку весь цей збір семантики робиться, щоб сформувати контент. Прикладом формування контенту може бути і сайт вашого конкурента. Так ви можете формувати всі свої посадкові сторінки: задати топ-20, відкрити основні URL, а фільтрація за частотністю заощадить вам трохи часу і дозволить обрати основні цільові ключі.
Кластеризація
Якщо ви бажаєте розробити нові типи посадкових сторінок або доопрацювати старі, то рано чи пізно ви прийдете до того, що вам потрібно користуватися більш серйозними інструментами, як «Кластеризація» Serpstat.
Це інструмент для групування ключів та формування ТЗ копірайтеру. Загалом, це глобальний крок, до якого так чи інакше приходять усі сеошники та контент-маркетологи. Навіть якщо щось спрацювало без коректно розробленого семантичного ядра, — кластеризація потрібна. Потім, на основі сформованих кластерів, можна робити посадкові сторінки та опрацьовувати контент.
Інструмент Serpstat робить кластеризацію ключів не відштовхуючись від самих ключів, а базуючись на URL-адресах. Умовно є 1000 ключів, за ними проглядається видача, і зі збігів URL-адрес у видачі формуються групи запитів.
Працюючи з «Кластеризацією»потрібно:
- створити проєкт;
- обрати пошукову систему;
- налаштувати параметри групування;
- додати ключі для аналізу.
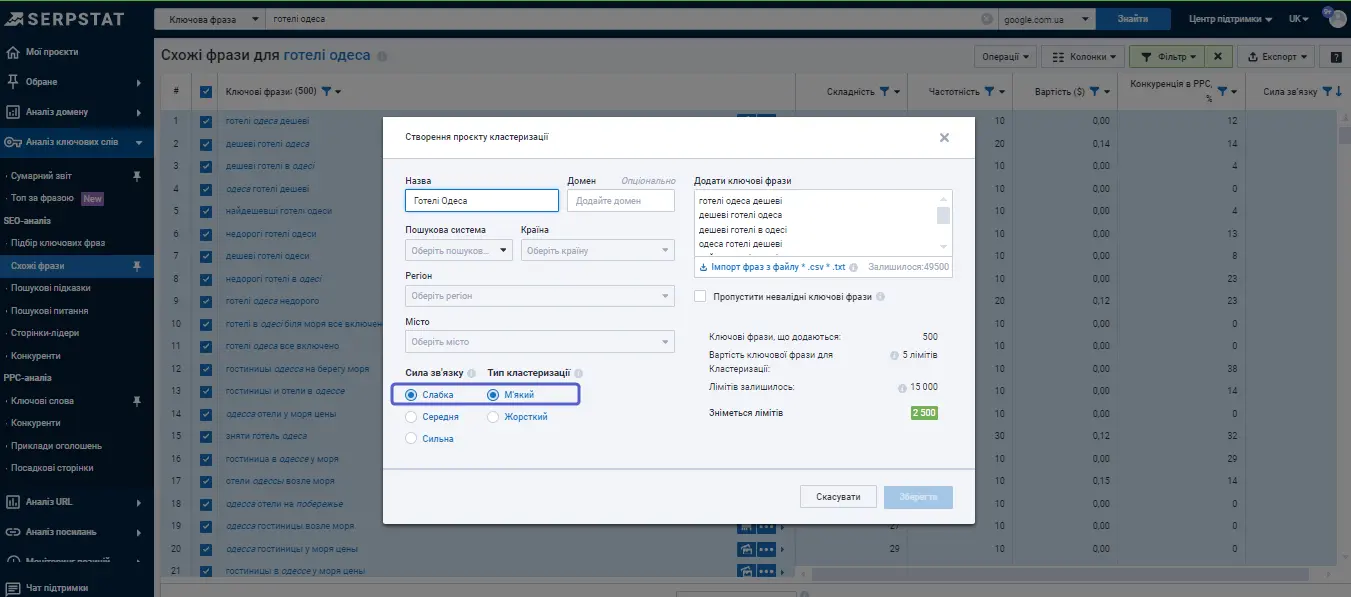
Є кілька параметрів, різні варіації яких будуть впливати на результати. Наприклад, якщо вибрати слабку силу зв'язку, це більше підійде інформаційним сайтам з невеликою кількістю сторінок. Якщо ж працювати з маркетплейсом (де багато товарних позицій), краще зробити сильну кластеризацію, щоб створити більшу кількість кластерів. При цьому один кластер може відповідати безпосередньо за конкретні товари та конкретну сторінку.
Тут ми якраз орієнтуватимемося на URL'и. У результаті — отримаємо групи, з різною кількістю ключів (це абсолютно нормально).
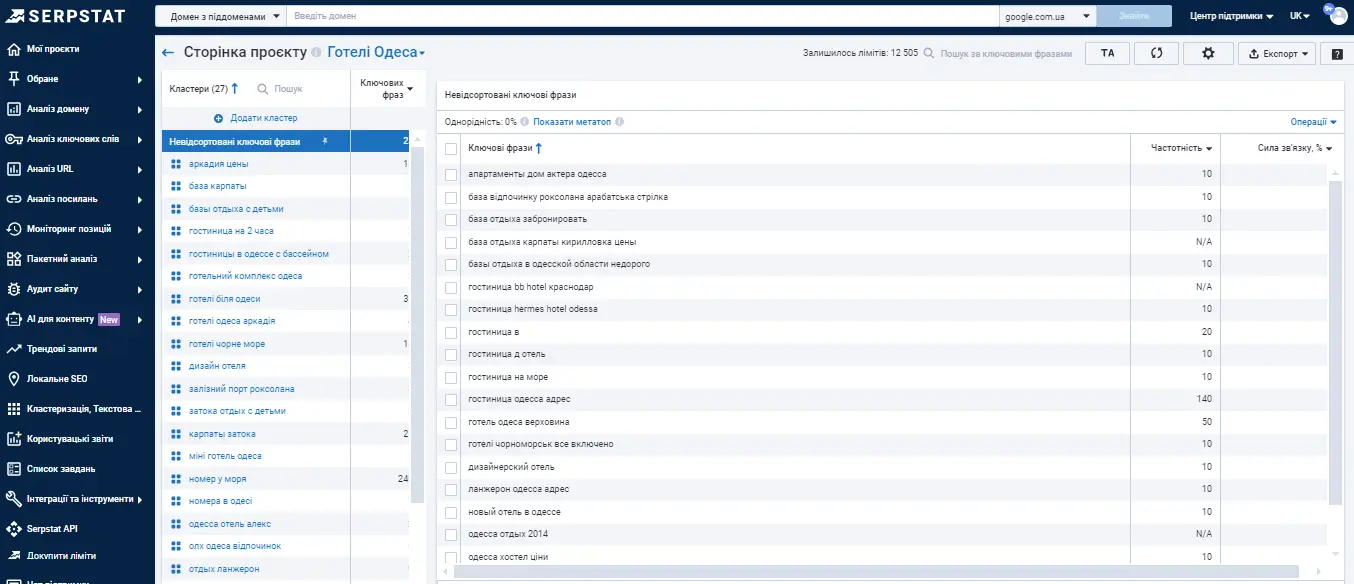
Найголовніше, щоб у вас були сформовані такі основні групи для посадкових сторінок. Вони представляють або те, як доопрацьовувати існуючий контент або як сформувати новий, в залежності від того, які у вас першочергові цілі.
Нічого не заважає об'єднувати кластери, якщо ми розуміємо, що їхні параметри збігаються.
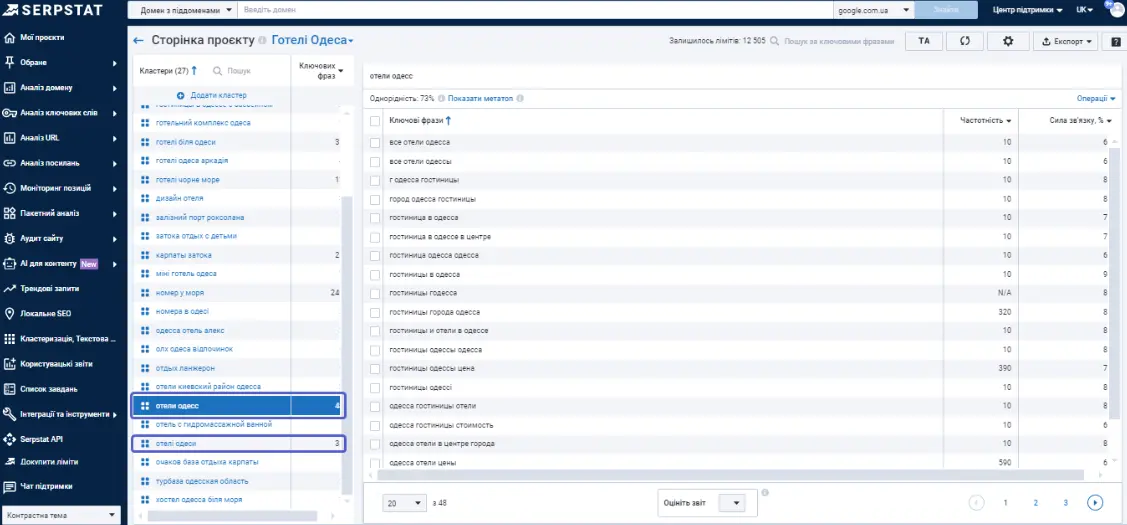
У сервісі є можливість відредагувати ключі, або окремі кластери через опцію «операції». Для цього використовується «Перемістити фрази в ...».
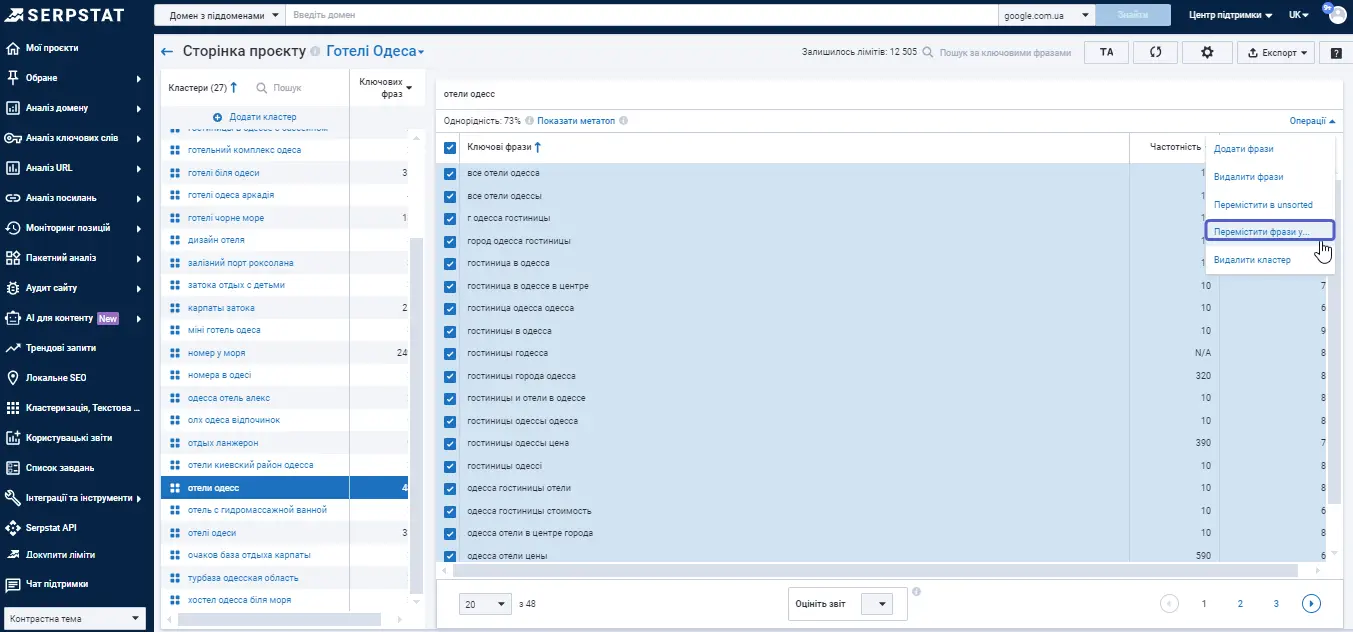
Збільшення кластеру потрібно, коли ми на одній сторінці збираємось розмістити якнайбільше різноманітного контенту, закрити велику тему. Іноді це помилкова дія, тому не завжди можна так робити. Іноді набагато ефективнішим є виділення основної теми та підтем.
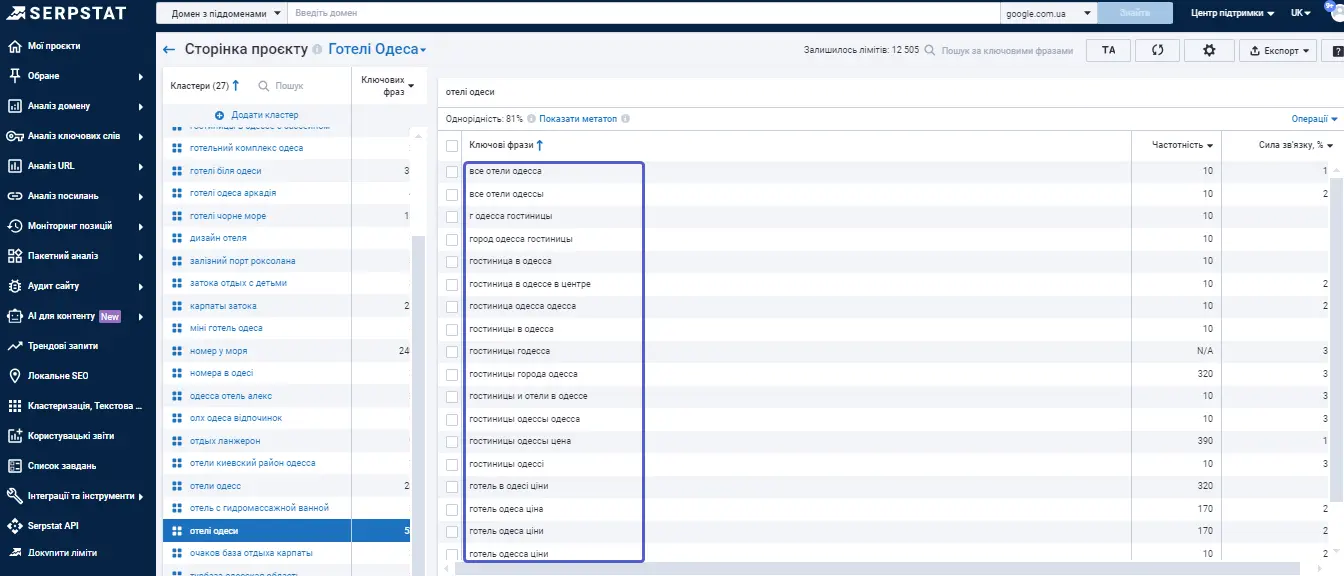
Окрему групу ключів, наприклад, «найближчі готелі», можна використовувати як підкластер і тоді — зробити підкатегорію на основі цього підкластеру для даної тематики. Щоб було зрозуміліше, розберемо один кластер. Алгоритм визначає ці ключі виходячи з тематичної відповідності.
Деякі алгоритми кластеризації чимось схожі на LSI — латентно-семантичне індексування. Але важливо не просто об'єднати ключі в одну групу, а й мати підгрунтя до того групування у видачі пошукової системи і реальний інтент. Serpstat відображає «Метатоп» — топ-30 сторінок, які вивчає краулер у певному регіоні, щоб співставити спільні ключі і додати в окрему групу. Часто сторінки із метатопу на високих позиціях не за одним ключем, а за всім кластером одночасно.
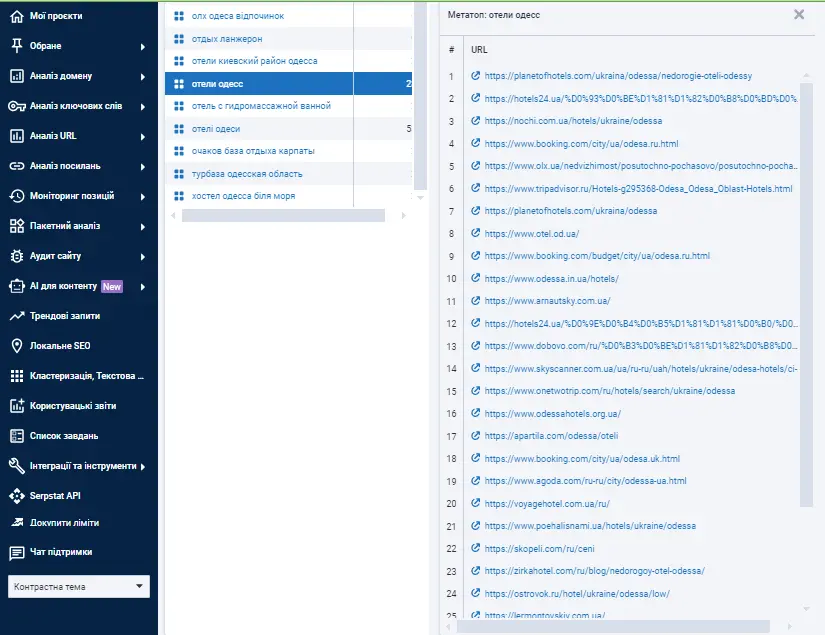
Це дозволяє нам зрозуміти, які сторінки в топі за цими ключами, допомагає при формуванні ТЗ копірайтеру.
Так ми отримуємо основний пул конкурентів. Його, безумовно, потрібно буде проаналізувати, це перший крок. Інколи, наше завдання — сформувати кілька нових посадкових сторінок, тоді ви обмежитеся буквально двома кластерами. А інколи — повністю переробити контент, тоді доведеться опрацьовувати всі сторінки.
Навіть у базовому тарифі Individual у вас є 5 000 лімітів, яких буде достатньо для кластеризації семантичного ядра для невеликого сайту.
Кейси
Розглянемо докладніше особливості використання API в Inweb. Агентство також має сервіс по роботі з текстами. Його логіка схожа на інструмент збору семантики: задається пошуковий запит, пошукова система, регіон. Наприклад, вводимо пошуковий запит «Буріння свердловин на воду», вказуємо семантику, якщо вона є, та натискаємо «Отримати завдання».
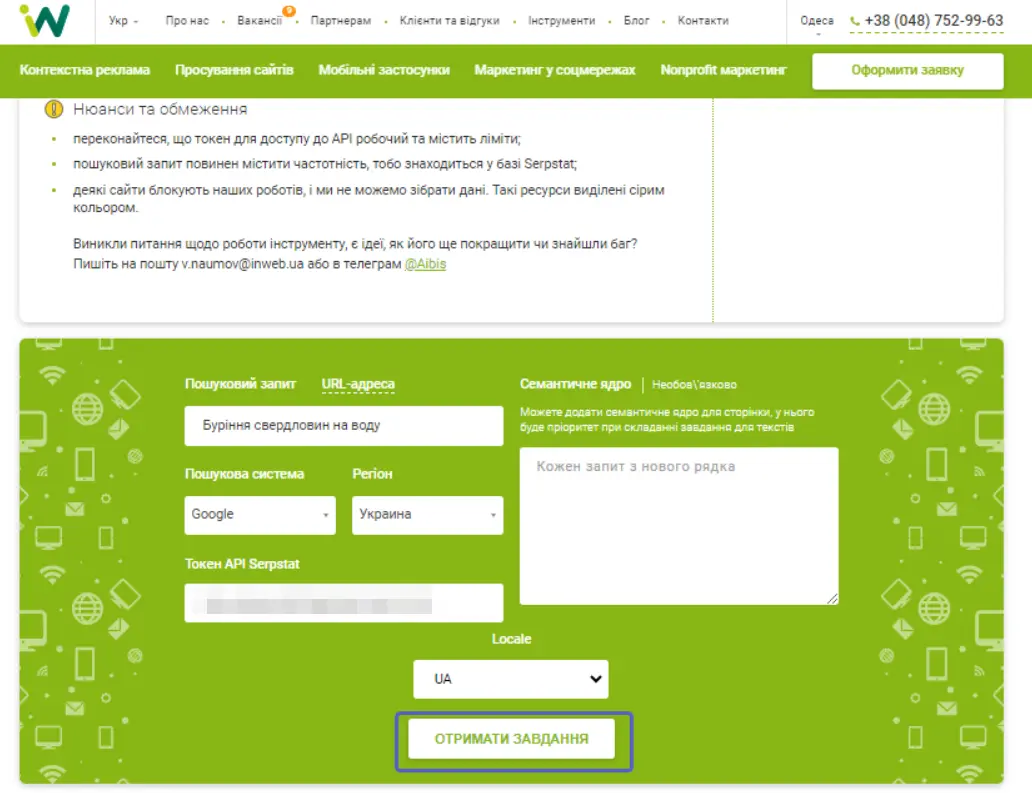
Система звертається до Serpstat, запитує топ-100 за введеним запитом та зберігає топ-10. Далі бот Inweb заходить на сторінки, парсить весь текст і приводить ключі до стандартного вигляду, паралельно фільтруються мінус-слова, наприклад, прийменники або частки.
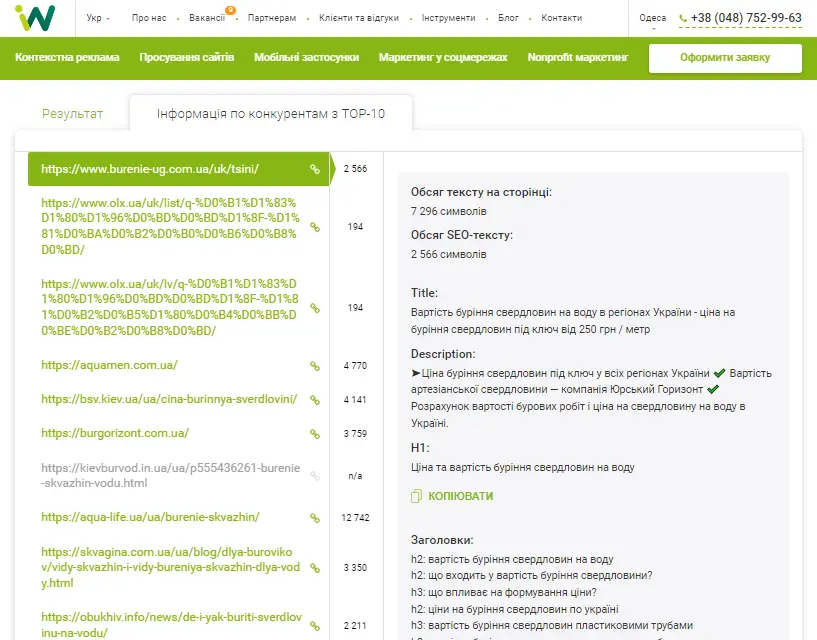
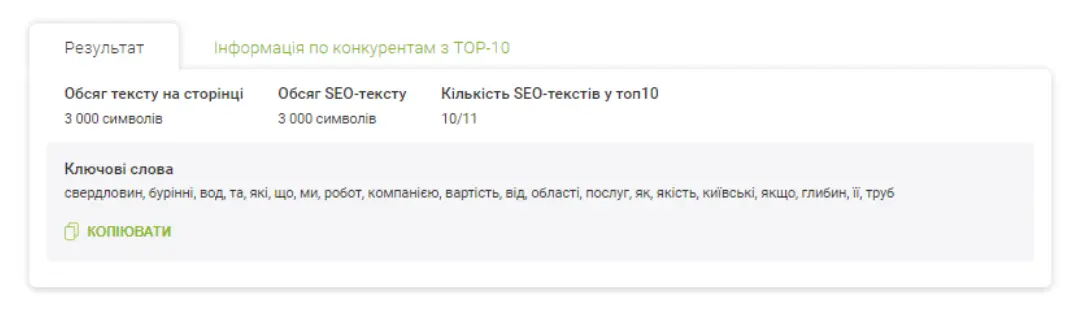
Рахується медіана за кількістю символів, а також відбираються найуживаніші фрази, у тому числі LSI-слова, що формують тематику.
За інформацією із топ-10 є заголовки H, які використовуються на цій сторінці.
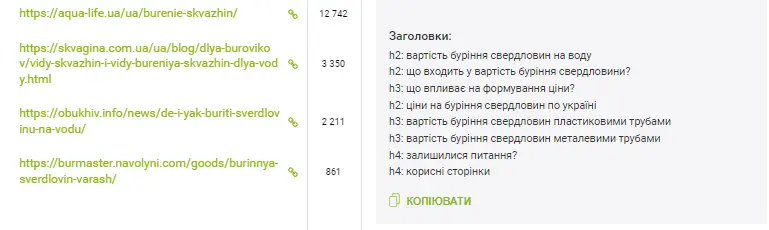
За заголовками можна зрозуміти, про що писати статтю та як сформувати структуру тексту для копірайтера. Також відображаються обсяг тексту та його метатеги.
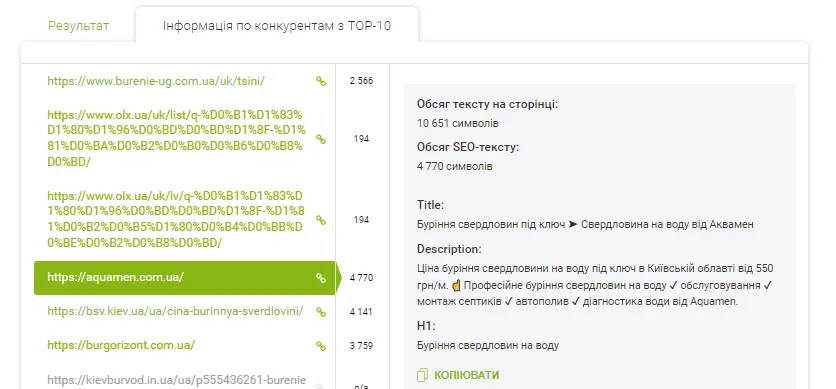
Якщо вказано семантику, то запити розбиваються за словами, зводяться до стандартної форми і лише потім додаються.
Завдяки API Serpstat можна не парсити Google, що тягло б за собою багато витрат.
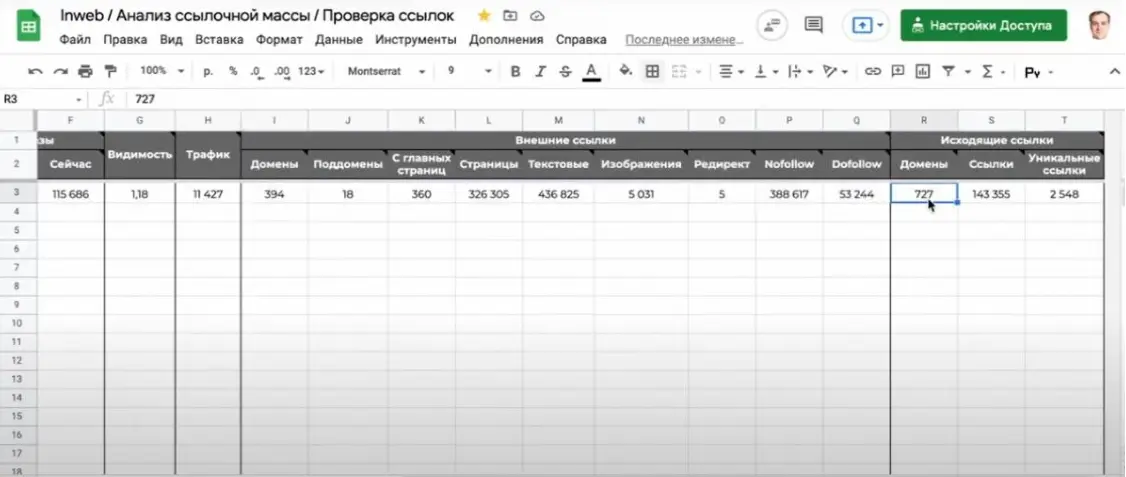
Окремий інструмент існує для аналізу посилань. Inweb аналізує Domain rank від Serpstat та докладні дані за посиланнями: кількість текстових лінків, зображень, редиректів, посилань з головної сторінки. Швидкість збору інформації залежить від того, скільки доменів посилається на сайт.
Таким чином, можна оцінювати домени потенційних донорів.
Для успішного просування важливо враховувати власний регіон сайту та регіон домену-донора. Якщо домен не має хоча б 5 000 ключових слів за даними Serpstat, краще на ньому не розміщувати посилання.
Також потрібно дивитися на співвідношення вихідних та вхідних посилань. Наприклад, якщо на сайт посилається 394 домени, але при цьому він має 25 млн вихідних посилань, — там теж не варто купувати розміщення. Однак потрібно звертати увагу на кількість унікальних посилань. Для розуміння: у футері сайт може розмістити посилання на 5 соціальних мереж. Якщо сайт містить 100 тисяч сторінок, то це буде 500 тисяч вихідних посилань, але за фактом — це ок.
Якщо сайт займається продажем посилань, це видно одразу, — в його «Зовнішніх посиланнях» буде аномальна кількість доменів – десятки тисяч.
Інструмент Serpstat — «Пакетний аналіз» надасть всі ці дані в іншому форматі, але дуже схожим чином. Додатково тут будуть органічні показники доменів,, що посилаються, — видимість, трафік і т.д.
FAQ
Слід так обговорити роботу з підрядником, щоб він надавав вам достатньо даних для аналізу. Потрібно заздалегідь визначитися з ключовими метриками, на які ви звертатимете увагу. У Serpstat на безплатному доступі «Сумарний звіт» покаже загальну динаміку видимості, проте вона може різнитися з вашими цільовими ключами. Загалом, ви можете зрозуміти як йдуть ваші плани.
З платною версією ви зможете використовувати Моніторинг позицій, поставити список цільових ключів і стежити за їх ранжуванням в режимі реального часу. Тобто «Моніторинг позицій» – це інструмент номер один для контролю.
Варто звернути увагу також на «Аудит сайту» для контролю команди, яка працює з технічною стороною вашого сайту. Ви можете вивантажувати дані про помилки, які потрібно виправити. Якщо при цьому оцінка SDO (рівень оптимізації сайту) не змінюється, швидше за все, над головними технічними помилками працювали недостатньо. Бувають і винятки, коли певні помилки виправили, але водночас додали багато нових сторінок, з новими помилками.
Тому що якщо у вас, величезна кількість сторінок з 404 помилкою, всі title однакові, H1 занадто короткі, або для картинок не прописані атрибути ALT – це серйозні проблеми. Все це платформа покаже серед помилок з середнім чи високим пріоритетом.
Це може відбуватися з низки причин. Іноді в тих випадках, коли H1 або не прописаний, або він прописаний з дуже грубими помилками. Саме тому Google замінює власні Title та H1.
Аудит в SEO-сервісах вкаже на такі проблеми: наприклад, надто довгі H1 або title. Якщо це не виправити, — висока ймовірність того, що Google зробить заміну — візьме найбільш релевантний текст із цієї сторінки та розмістить його як Title або Description.
Загалом, логіка формування сніпету змінилась досить давно. Раніше title у сніпеті формувався виходячи із запиту користувача, на основі тексту та заголовку сторінки (щоб він був релевантний цьому запиту). Зараз сніпет формується не виходячи із запитів користувачів, а виходячи з того, який фрагмент тексту найкраще ілюструватиме вміст сторінки, на думку Google. Тобто замість вмісту title, який прописав SEO-фахівець часто показується щось інше або навіть вміст тегу H1. Однак не варто ігнорувати заповнення метатегів, тому що вміст title все одно враховується під час ранжування.Переписати title, щоб він був більш релевантним — завжди гарна ідея.
Висновок
Ми з Serpstat та Inweb розглянули інструменти та інтеграції, які будуть корисними власникам будь-якого бізнесу. Функціональність цих звітів дозволяє провести аналіз конкурентів, підбір ключових слів, кластеризацію, а також — перевірку сторінок з використанням інструменту «Дерево сайту». Сподіваємось що описані кейси та поради експертів агенції будуть для вас корисними!
Проаналізуйте своїх конкурентів
Зареєструйтесь і користуйтесь Serpstat безкоштовно 7 днів
Використовуйте кращі SEO інструменти
Перевірка зворотніх посилань
Швидка перевірка зворотніх посилань вашого сайту та конкурентів
API для SEO
Отримайте швидко великі обсяги даних за допомогою функціонального SЕО API
Аналіз конкурентів
Зробіть повний аналіз сайтів конкурентів для SEO та PPC
Моніторинг позицій
Відстежуйте зміну ранжування цільових запитів використовуючи моніторинг позицій ключів
Рекомендовані статті
Кейси, лайфхаки, дослідження та корисні статті
У вас немає часу стежити за новинами? Не турбуйтеся! Наш редактор підбере статті, які неодмінно допоможуть вам у роботі. Приєднуйтесь до нашої затишної спільноти :)
Натискаючи кнопку, ви погоджуєтеся з нашою Політикою конфіденційності