Начните искать ключевые слова
Используйте Serpstat, чтобы находить лучшие ключи
Как Google ранжирует сайты в тематике
«Финансы» — исследование
«Финансы» — исследование


Я решил провести собственное исследование на примере финансово-кредитной тематики, чтобы понять, как Google классифицирует YMYL-сайты и какие показатели влияют на распределение страниц в топ-30.
Напоминаю, что YMYL — это страницы общественно значимых тематик, таких как новости, финансы, медицина, покупки и так далее.
Что касается E-A-T — это набор критериев для оценки качества страницы и расшифровывается эта аббревиатура как Экспертиза, Авторитет, Доверие (Надежность).
Меня эта тема очень интересует и недавно я опубликовал исследование «Как Google классифицирует YMYL сайты». Исследование было проведено на выборке интернет-страниц сайтов медицинской тематики.
Результаты оказались настолько интересными, что в комментариях и в социальных сетях меня начали просить провести такое же исследование для других тематик. Один из веб-мастеров даже список сайтов финансово-кредитной тематики прислал, за что ему огромное спасибо.
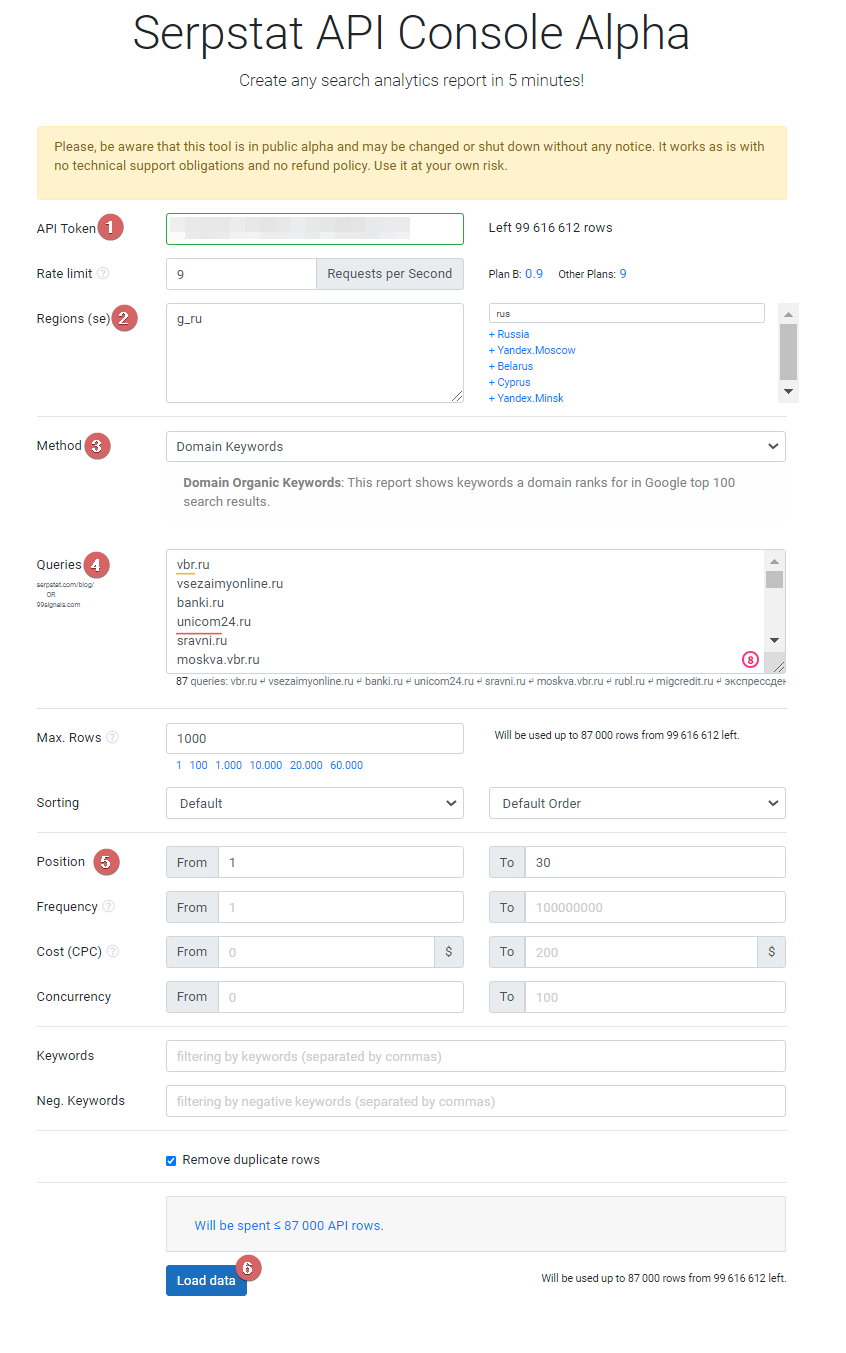
В этой статье я расскажу, как при помощи Serpstat и других SEO-инструментов я провел исследование YMYL-страниц финансово-кредитной тематики, чтобы определить, какие факторы влияют на их ранжирование.
рутинных задач?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! ;)

Используя интеграцию API Majestic и Netpeak Checker получены показатели метрик Majestic для домена и страницы.
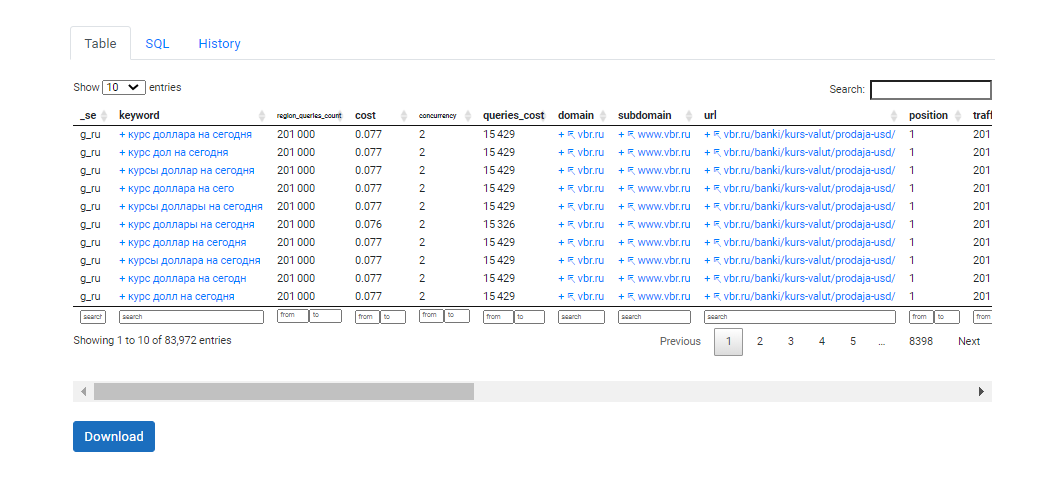
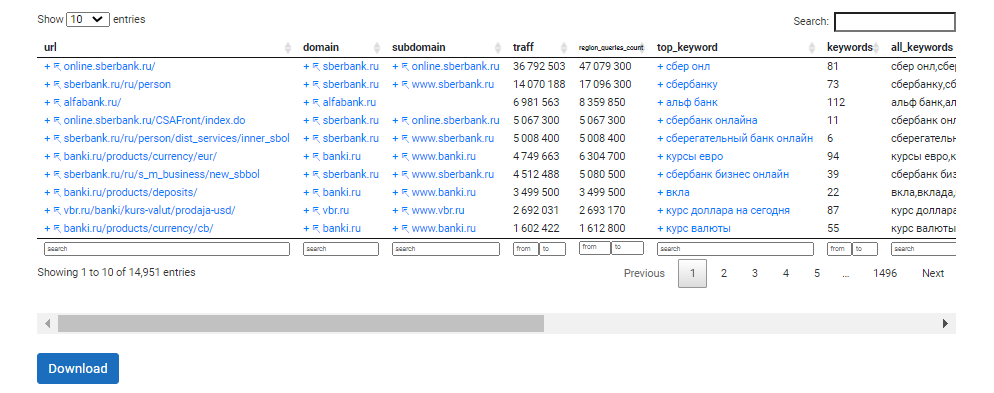
Всего в наборе данных мы получили 41 параметр для анализа факторов ранжирования YMYL-страниц. Естественно, что такой объем данных невозможно проанализировать вручную. Поэтому без автоматизации процессов анализа тут не обойтись.
Вот несколько инструментов, которые будут полезны для таких задач:
Учитывая это, я использовал другой подход. Классифицировал страницы в наборе данных, разделив их на три группы: топ-10, топ-20, топ-30.
Загрузив набор данных в Answerminer, я хотел выяснить, какой из показателей имеет самую высокую корреляцию с показателем «Позиция».
Оказалось, что показатель «Позиция» имеет сильную отрицательную корреляцию по Спирмену с показателем «Citation Flow — Majestic : Host».
При отрицательной корреляции низкие значения показателя «Позиция» соответствуют высоким значениям показателя «Citation Flow — Majestic: Host», что весьма логично.
Тут я сделаю две ремарки:
- Во-первых, корреляция — это лишь сигнал о том, что между двумя признаками возможно существует причинно-следственная связь, но этой связи может и не быть.
- Во-вторых, «Citation Flow — Majestic : Host» — одна из метрик потока Majestic, которая рассчитывается в соответствии с количеством веб-сайтов, ссылающихся на целевой URL (режим: Host).
Разница в средних значениях показателя «Citation Flow — Majestic: Host» между группами топ-10,топ-20, топ-30 статистически значима, т.е. не случайна. Среднее значение CF Majestic: Host для доменов финансово-кредитной тематики в топ-10 составляет 35, для топ-20 — 22, соответственно, а для топ-30 — всего 18.
Затем я загрузил мой набор данных в BigML, создал модель, обучил, оценил ее и выявил, что основным предиктором дерева решений (точка от которой начинают расходиться «ветки») также является показатель CF Majestic: Host.
В общем, для доменов финансово-кредитной тематики ссылки являются одним из определяющих факторов ранжирования.
Третьим по релевантности в наборе данных оказался показатель «Trust Flow — Majestic: Host».
Кстати, в модуле «Анализ ссылок» Serpstat есть схожая метрика — SDR (Serpstat Domain Rank). Принцип расчета показателя похож на Google Page Rank: числовой показатель зависит от того, сколько сайтов ссылаются на анализируемый домен + сколько сайтов ссылаются на сайты, ссылающиеся на анализируемый домен + сколько сайтов ссылаются на сайты, ссылающиеся на сайты, ссылающиеся на анализируемый домен — и так учитываются все сайты в индексе. Эту метрику можно получить и через API обратных ссылок.
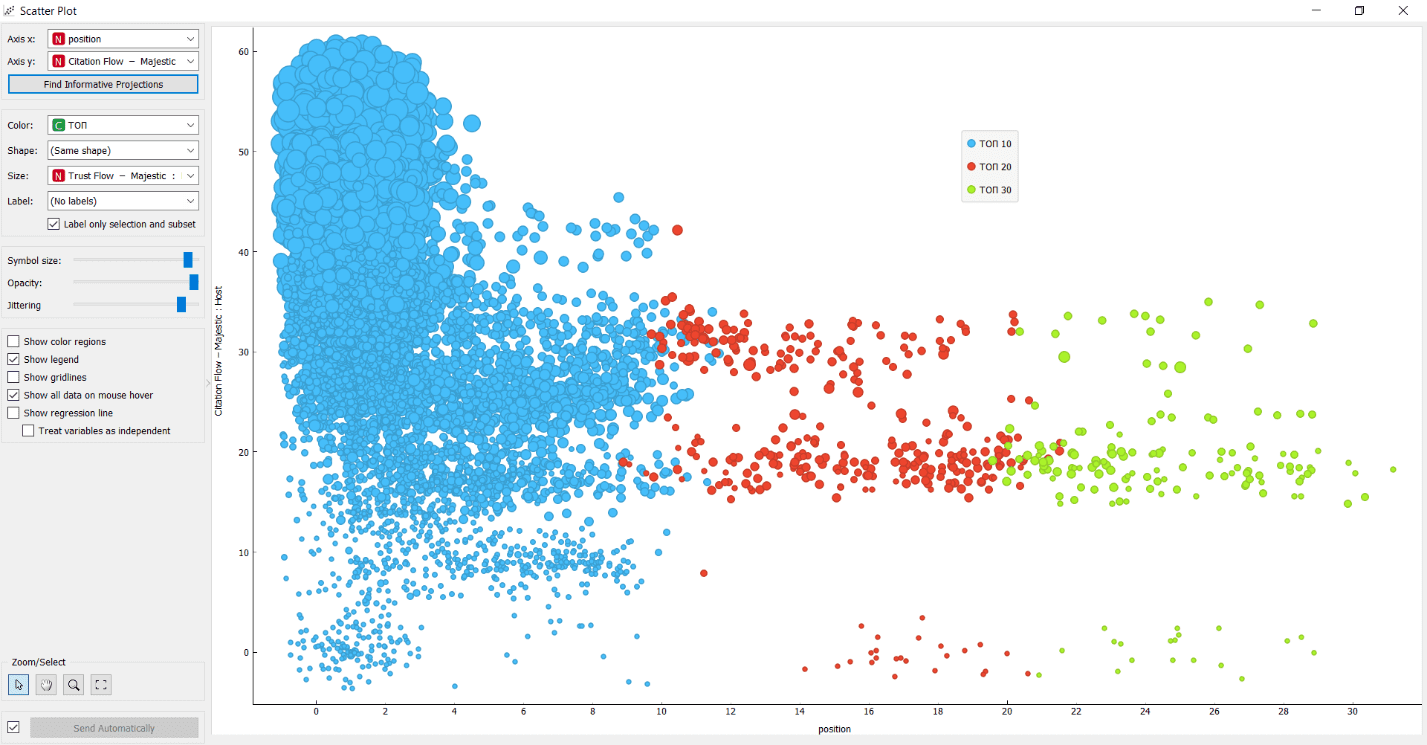
- по горизонтали — значение позиции;
- по вертикали — показатель метрики CF Majestic: Host;
- размер элементов — показатель метрики TF — Majestic: Host.
Так что, не только количество ссылающихся доменов имеет значение, но и их качество. Что интересно, средний показатель TF — Majestic: Host для топ-10 составляет 27, что почти в два раза больше, чем у подгруппы топ-20 и топ-30.
Очень интересным мне показалось отличие между этими группами по показателю «Размер HTML» (количество символов в блоке <html>, включая HTML-теги). Сразу скажу, в моем наборе данных эти различия не статистически значимы (вероятно случайны).
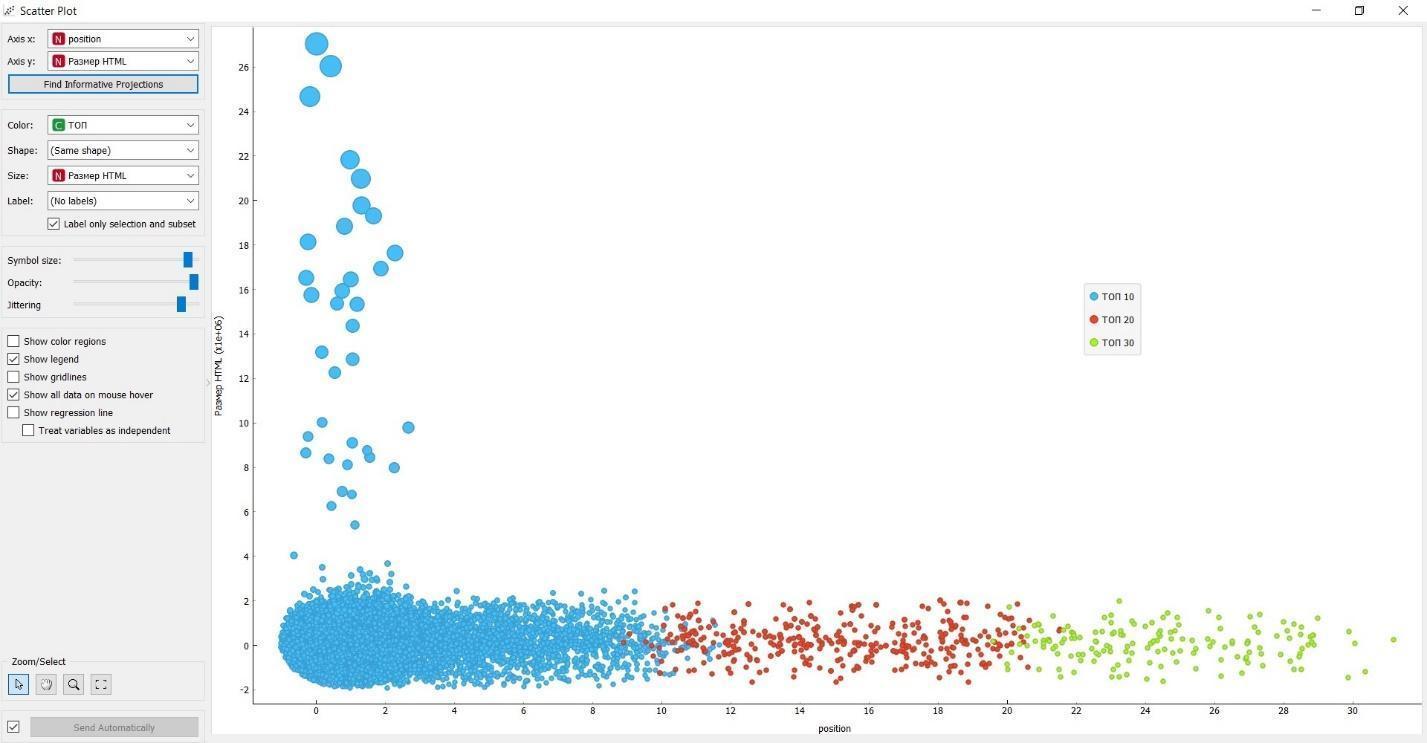
- по горизонтали — показатели позиции;
- по вертикали и в размере элементов — значение показателя «Размер HTML».
Вернемся к нашему показателю CF Majestic: Host.
Обученная в BigML модель говорит о том, что если значение CF Majestic: Host больше 32, и ключевое слово не содержит слово «паспорту», ваш URL с 99,9% уровнем уверенности попадет в топ-10.
Чем хорошо машинное обучение, так это тем, что с его помощью можно рассмотреть несколько сценариев.
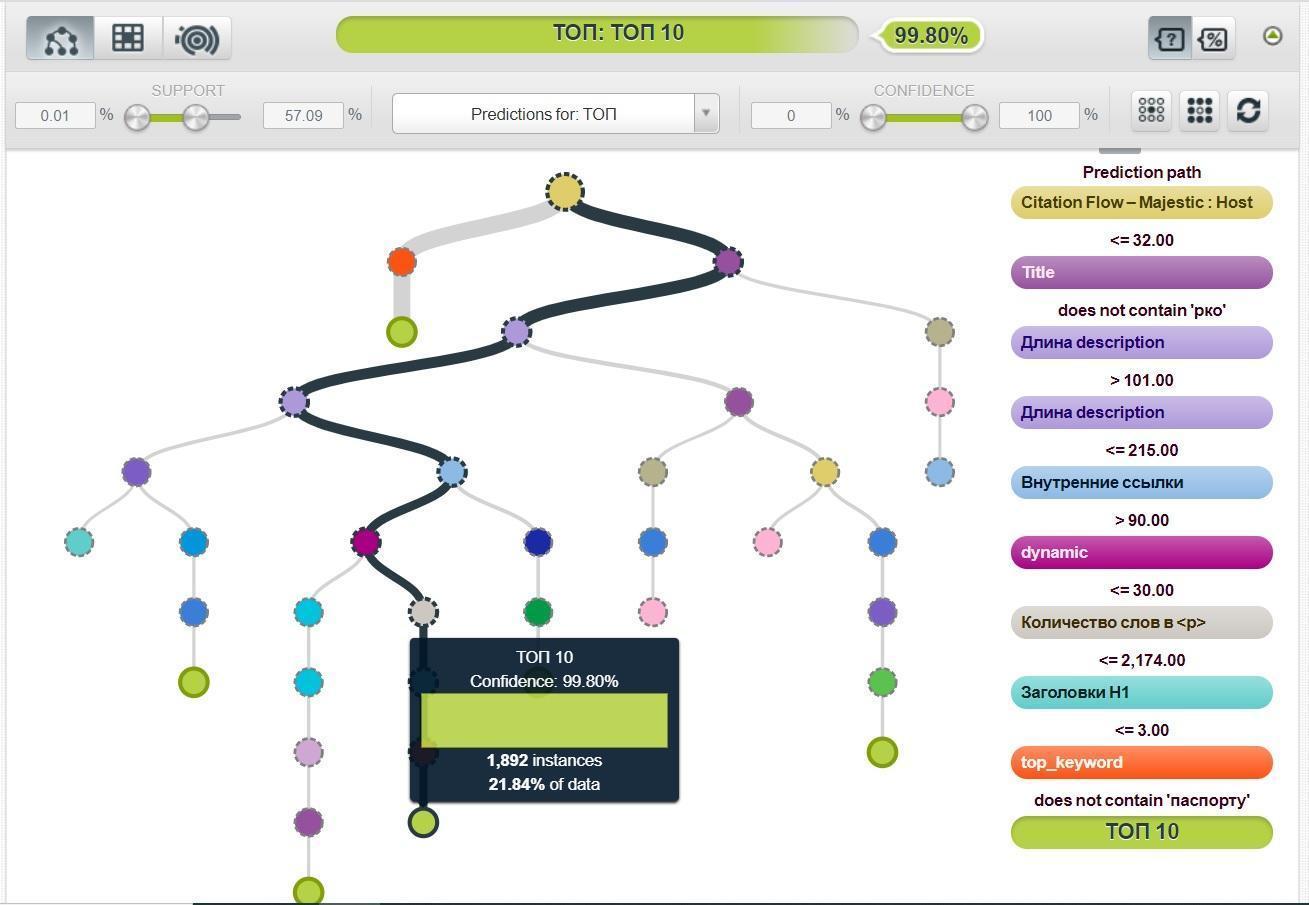
- CF Majestic: Host будет меньше 32, но…
- Title не будет содержать слово «РКО» (расчетно-кассовое обслуживание).
- Длина Description от 101 до 205 символов.
- Внутренних ссылок больше 90.
- Количество слов в <p> меньше 2174.
- Запрос не должен содержать слово «Паспорту».
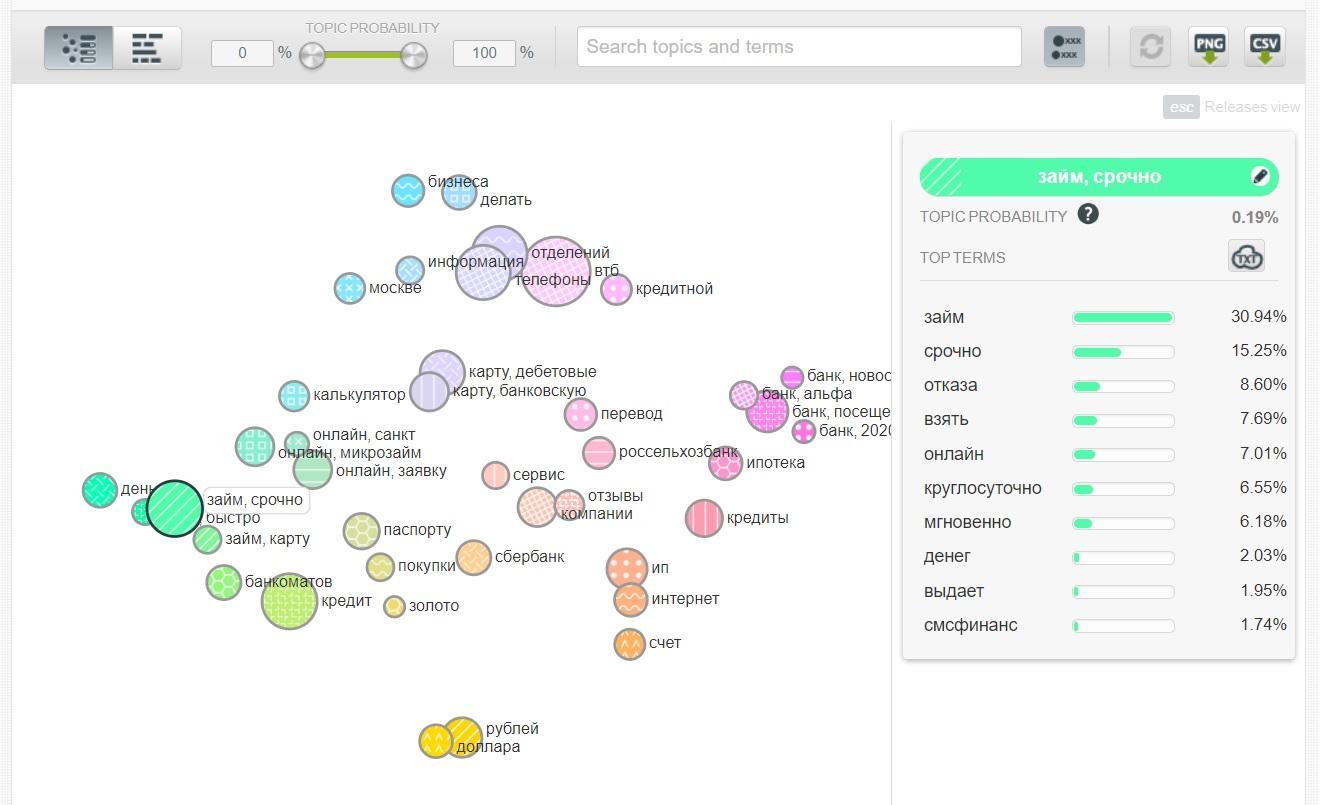
На графике видно, что одной из самых востребованных тематик также является «Займ, срочно».
Если кто-то забыл, напоминаю, что Google использует специальный алгоритм для тестирования подобных запросов на спам. Страницы с контекстом содержимого «Займ, срочно» изначально рассматриваются, как подозрительные.
Давайте сравним облако слов из Title, Description, H1 страниц из топ-10 и страниц из топ-30.

Не знаю, как вам, но мне тематика страниц из топ-10 кажется более сбалансированной и менее спамной.
Также обратите внимание на то, что на страницах из топ-30, ключевые слова в Title, Description и H1 упоминаются чаще (их размер на Рис.4 больше), чем на страницах из топ-10.
В связи с этим, меня заинтересовал показатель «Конкуренция», который используется в Serpstat для целей PPC. Он показывается по шкале от 0 до 100%. Чем больше доменов использую данную фразу в объявлениях, тем выше конкуренция.
Давайте посмотрим на уровень конкуренции между нашими группами интернет-страниц.
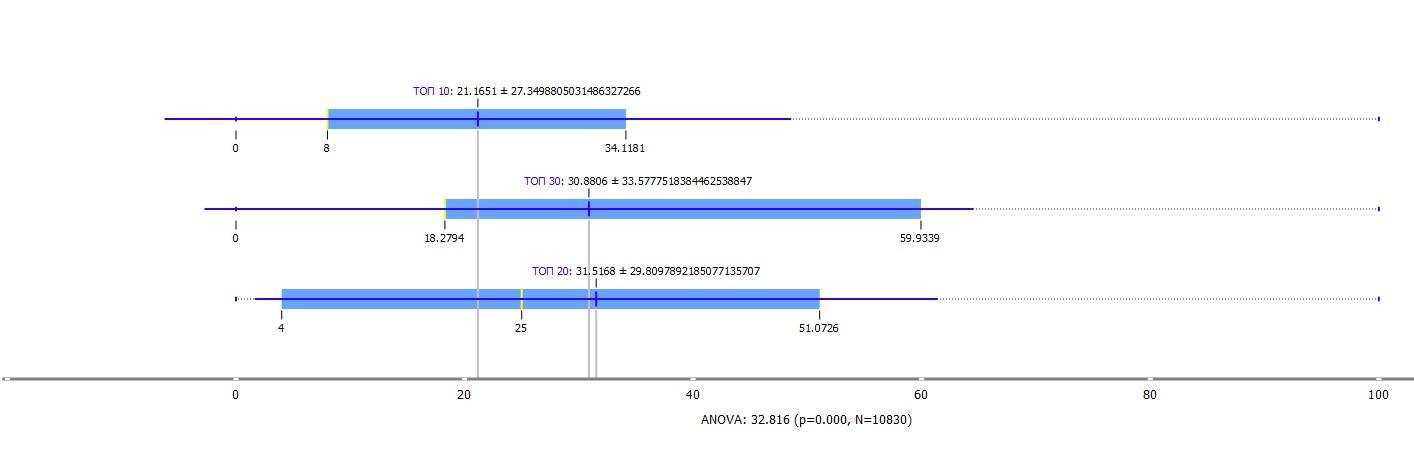
Причем разница в уровне конкуренции между страницами из топ-10 и страницами из топ-20/30 статистически значима (неслучайна).
Экстраполируя определение показателя «Конкуренция» для страницы, можно предположить, что на страницах из топ-20/30 в моем наборе данных может быть «переспам» ключевыми словами в Title, Description и H1.
Обратите внимание, что мое допущение о показателе «Конкуренция» и «переспаме» — это предположение и вы просто примите это к сведению.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Используйте лучшие SEO инструменты
Проверка обратных ссылок
Быстрая проверка обратных ссылок вашего сайта и конкурентов
API для SEO
Получите быстро большие объемы данных используя SЕО API
Анализ конкурентов
Сделайте полный анализ сайтов конкурентов для SEO и PPC
Мониторинг позиций
Отслеживайте изменение ранжирования запросов используя мониторинг позиций ключей
Рекомендуемые статьи
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити :)
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.