Дослідження ринку за допомогою Python-скриптів: Детальний опис робочого процесу

Сьогодні ми розглянемо, як проводити маркетингові дослідження в конкретних галузях, зосереджуючись на зборі ключових слів, їх фільтруванні за намірами та отриманні даних про обсяги пошуку.
Ви також дізнаєтеся, як оновлювати сторінки з результатами пошуку (SERP) та дані про обсяги пошуку, об’єднувати результати й застосовувати показники клікабельності (CTR), щоб визначити найефективніші вебсайти.
Наступні етапи включатимуть налаштування завдань сканування, вилучення даних і об’єднання результатів для аналізу.
Мета
Наша мета — провести дослідження певної галузі та визначити гравців ринку в будь-якому регіоні, який працює в цій галузі. Першим кроком є збір усіх ключових слів, пов’язаних із нішею, яка нас цікавить. Ми також можемо деталізувати ці ключові слова за типами послуг або класифікувати їх за інтенсивністю, тощо.
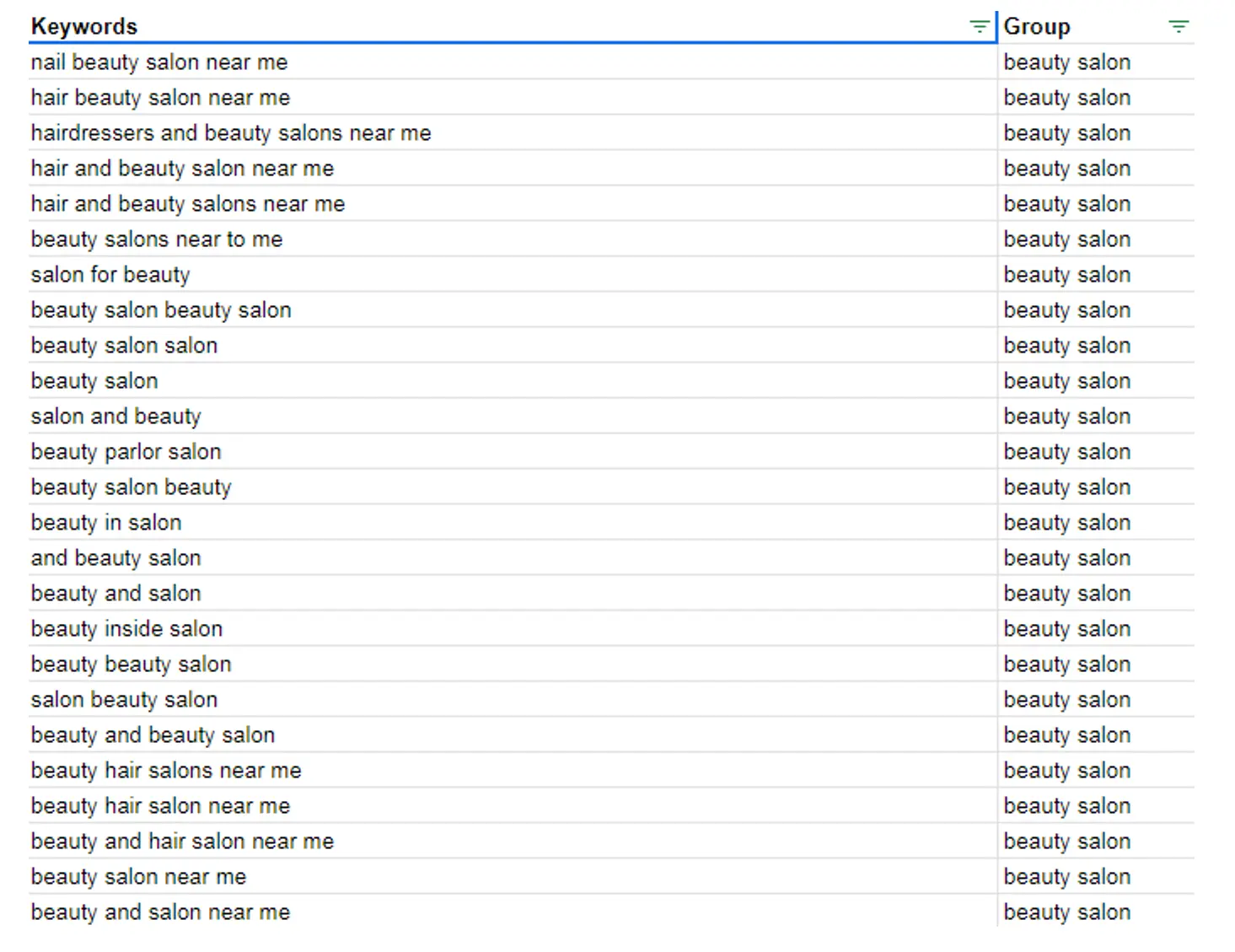
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Keyword data (initial input)”.
Це дозволяє використовувати ці класифікації для подальшого фільтрування ключових слів. У моєму випадку є чотири групи – це ключові слова, пов’язані із:
- б’юті-індустрією (в якості загальної ніші);
- стрижками;
- макіяжем;
- манікюром.
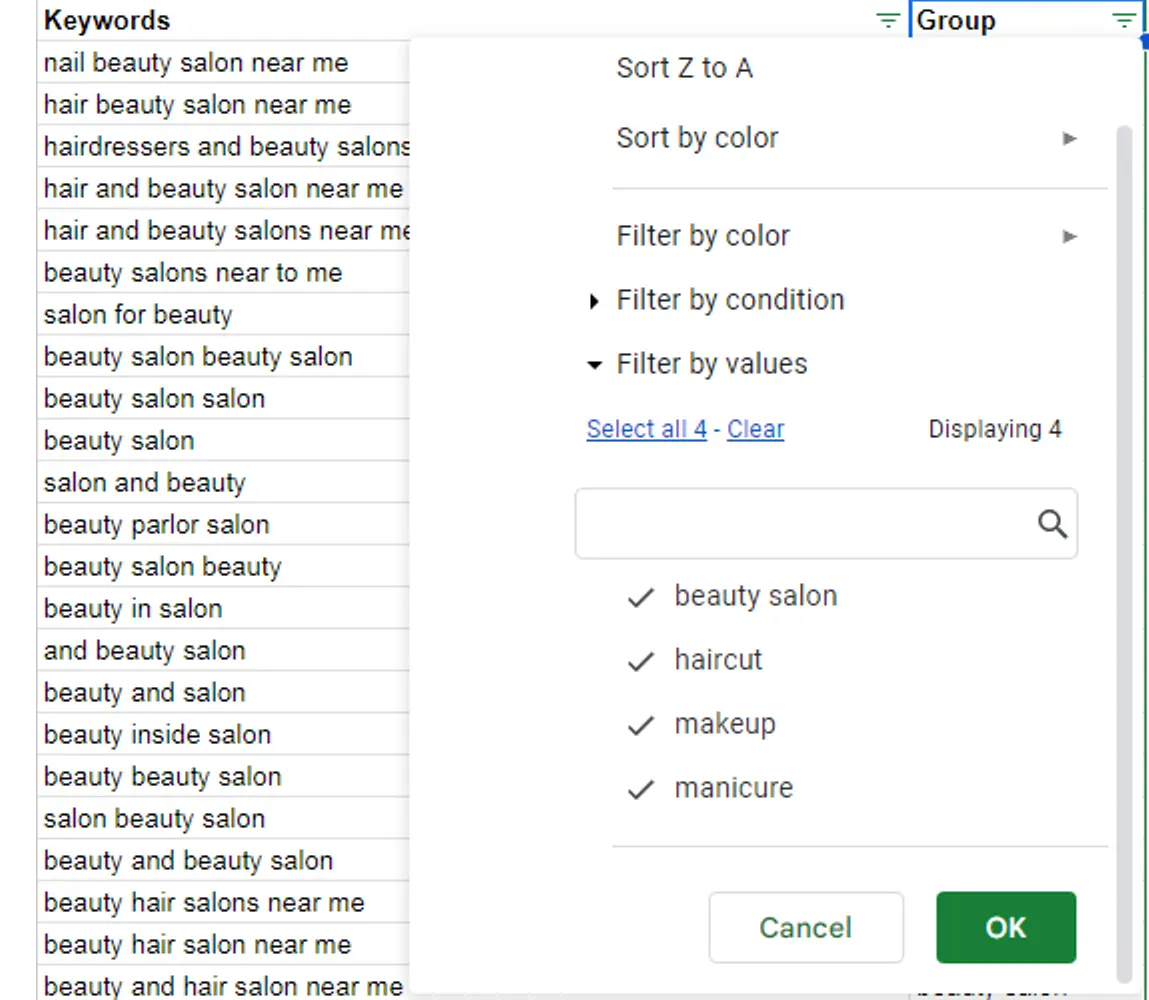
Джерелом ключових слів може бути будь-що. Ви можете виконати класичне дослідження ключових слів або згенерувати їх за допомогою ШІ. Це не має суттєвого значення. У реальному випадку ми починаємо з найзагальнішого набору ключових слів.
Реалізація
Для зручності сприйняття процес розділено на шість ключових кроків. Кожен із них є логічним продовженням попереднього. Давайте розглянемо, як це працює.
Крок 1: Налаштування завдання сканування сторінок пошукової видачі та отримання JSON-файлу з результатами
Першим кроком є оновлення результатів сторінок пошукової видачі у потрібному регіоні. Ми використовуємо простий скрипт, який налаштовує завдання сканування цих сторінок на основі ідентифікатора регіону.
Зразок коду, який використовується в цьому кроці, можна знайти в документі за цим посиланням у розділі під назвою “1. Obtaining JSON File with SERPs”.
Потім результати розбиваються на частини, і всі дані щодо сторінок пошукової видачі експортуються в окремі JSON-файли. Після цього всі ці частини об’єднуються в один JSON-файл із усіма результатами.
Крок 2: Отримання JSON-файлу з даними про обсяги пошуку
Наступним кроком є виконання подібної операції для отримання даних про обсяги пошуку в тій самій області та локації. Ми використовуємо аналогічний ідентифікатор регіону та передаємо той же набір ключових слів для налаштування завдання сканування обсягів пошуку.
Зразок коду, який використовується у цьому кроці, можна знайти в документі за цим посиланням в розділі під назвою “2. Obtaining JSON with the Search Volume data”.
Потім ми отримуємо дані про ключові слова та об'єднуємо їх у єдиний JSON-файл.
Крок 3: Об’єднання результатів сторінок пошукової видачі та обсягів пошуку
Наступним кроком є об’єднання результатів SERP та даних про обсяги пошуку й застосування CTR до найвищих 10 органічних позицій у пошуковій видачі.
Зразок коду, який використовується в цьому кроці, можна знайти в документі за цим посиланням у розділі під назвою “3. Merging the SERP and Search Volume data for traffic estimation through CTR”.
У результаті ми отримуємо вебсайти, які мають найкращі показники та найбільшу частку трафіку в цій галузі, оскільки вони ранжуються за ключовими словами, які ми вибрали. Ми можемо побачити кількість орієнтовного органічного трафіку та частку трафіку тут. Це виглядає так:
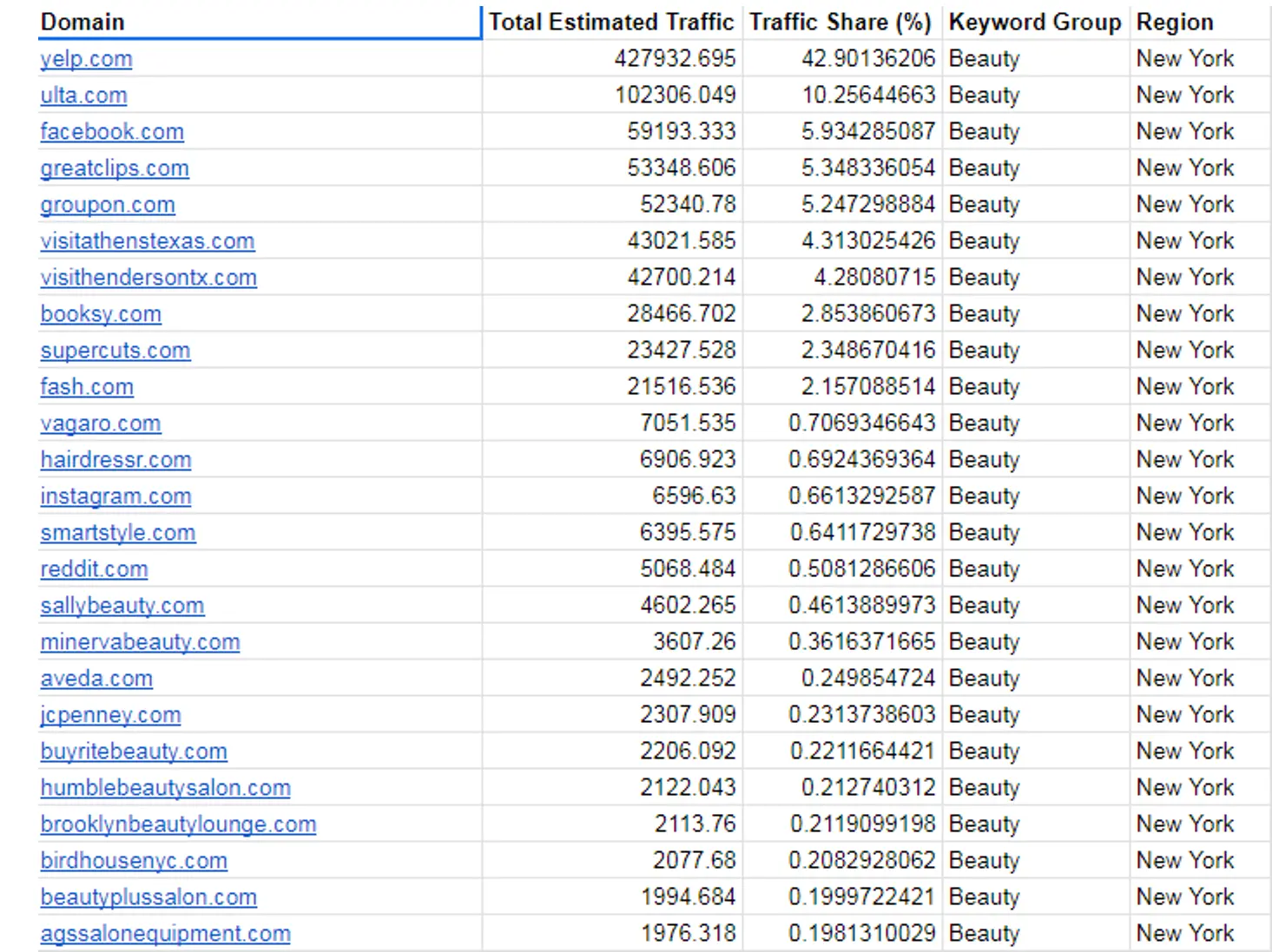
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Market share”.
У нас є багато вебсайтів у цьому списку. Я можу фільтрувати за тегами ключових слів або регіонами, для яких ми налаштували сканування. У моєму випадку я використовую Нью-Йорк і Лос-Анджелес задля наглядності.
Крок 4: Фільтрація та аналіз вебсайтів
Наступним кроком є визначення галузі, до якої належить конкретний вебсайт. Ми налаштовуємо подібне завдання до сканування обсягів пошуку, але передаємо всі отримані домени для їх сканування та визначення галузі.
Зразок коду, який використовується в цьому кроці, можна знайти в документі за цим посиланням у розділі під назвою “4. Classifying obtained websites”.
У результаті ми отримуємо категорії, до яких належать ці вебсайти. Під категорією я маю на увазі їх галузь.
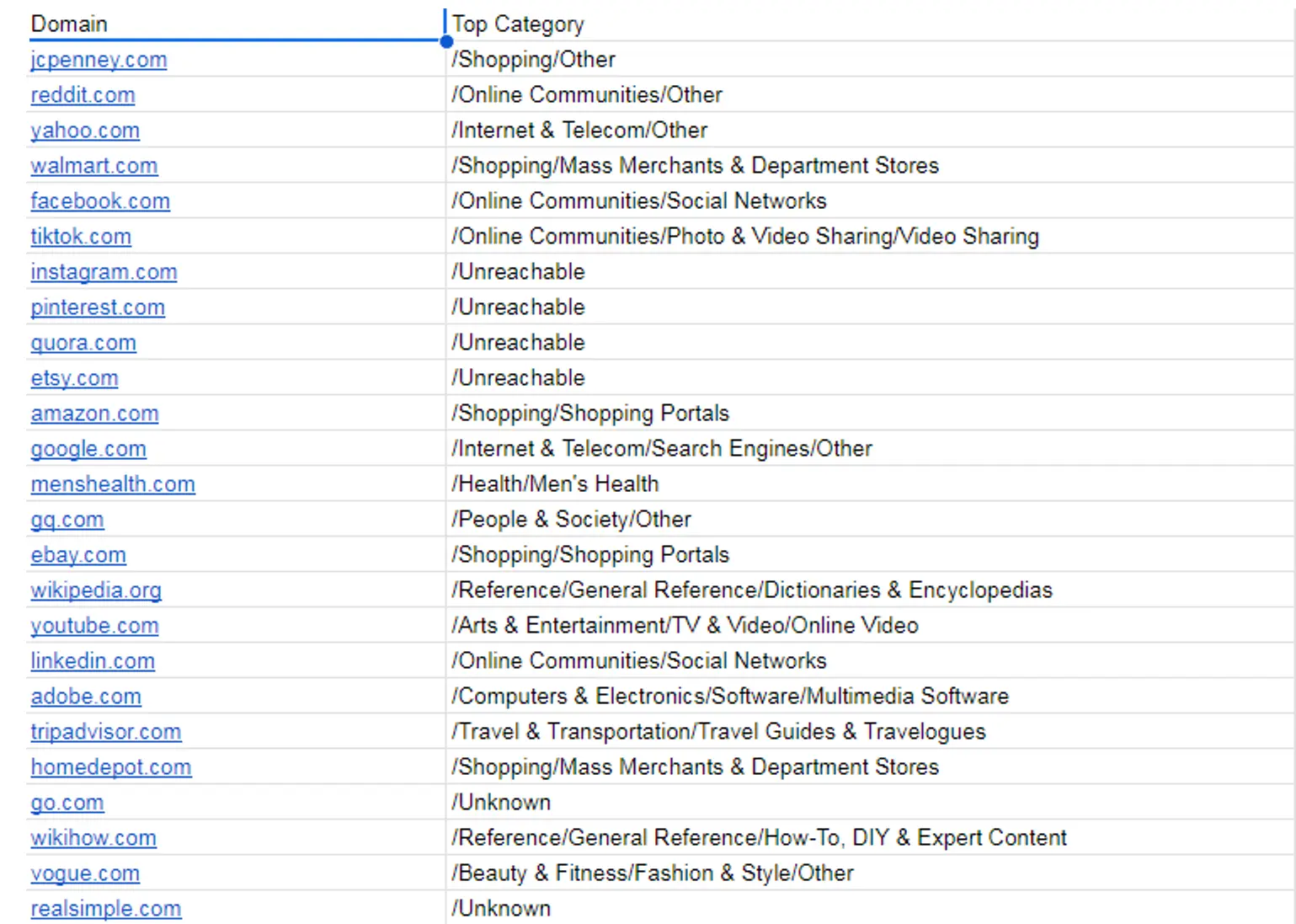
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Domain Category”.
Крок 5: Отримання метрик ранжування
Наступним кроком є отримання базових метрик ключових слів для цих доменів. Ми передаємо всі вебсайти, пов’язані з нішею, щоб отримати метрики ранжування, такі як видимість, оцінка органічного трафіку та кількість ключових слів.
Зразок коду, який використовується в цьому кроці, можна знайти в документі за цим посиланням у розділі під назвою “5. Obtaining Ranking metrics”.
Результати показані нижче:
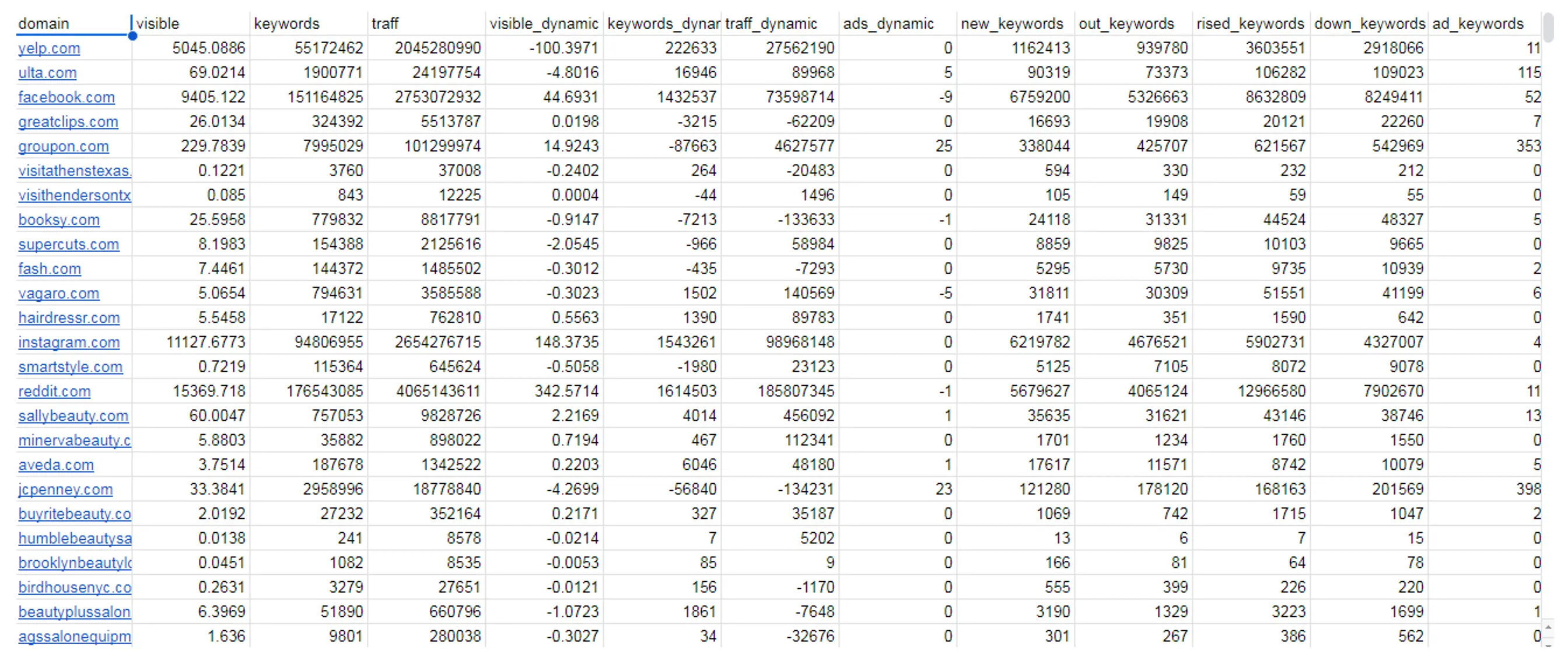
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Domain Keyword Metrics”.
Крок 6: Отримання метрик зворотних посилань
Наостанок, ми виконуємо ту саму операцію, передаючи той самий набір доменів для отримання матриці зворотних посилань, яка включає рейтинг сайту та кількість доменів і сторінок, що посилаються.
Зразок коду, який використовується в цьому кроці, можна знайти в документі за цим посиланням у розділі під назвою “6. Obtaining Backlinks metrics”.
Результати показані нижче:
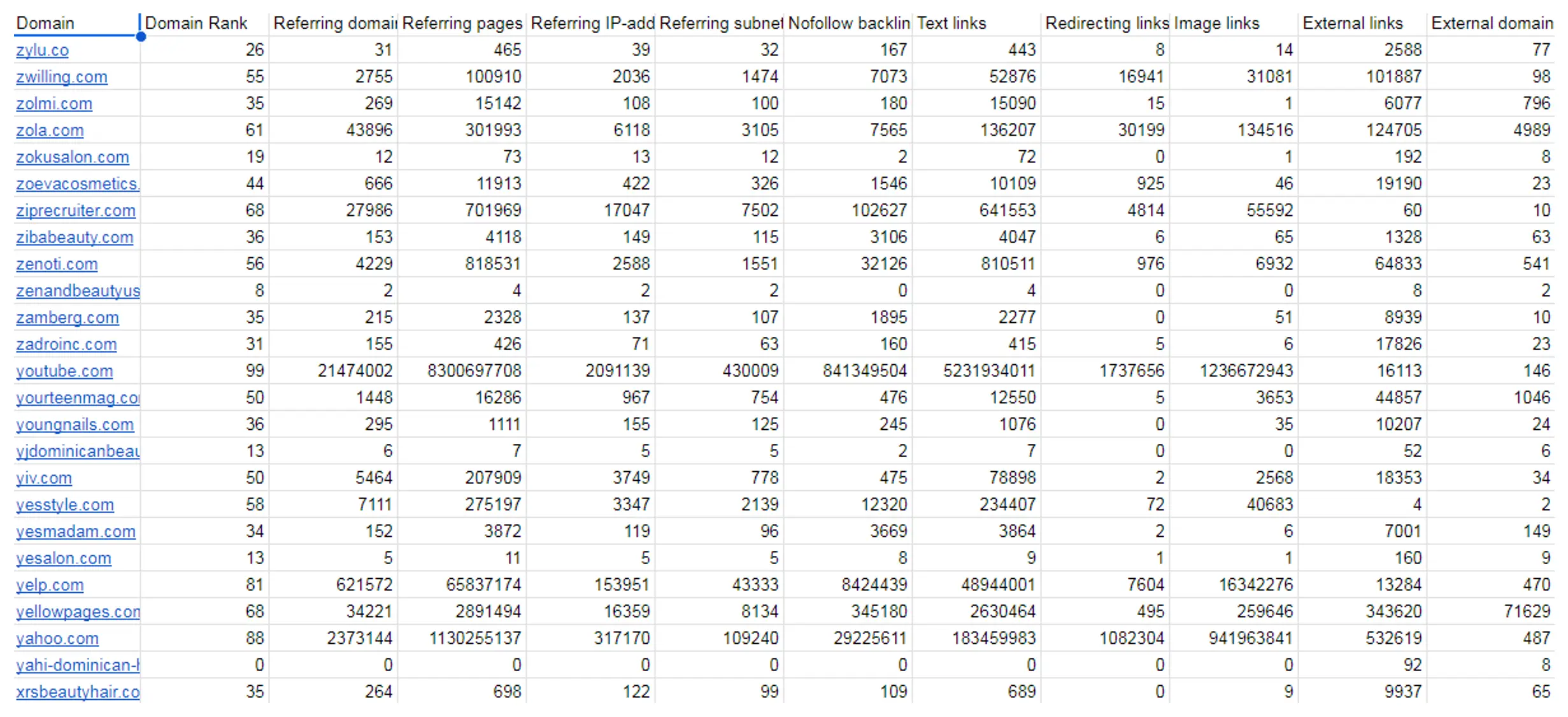
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Domain Backlinks Metrics”.
Результати
Після об’єднання цих результатів ми можемо побачити всі вебсайти в певній області, пов’язані з конкретним типом послуги, та галузь, до якої належить вебсайт.
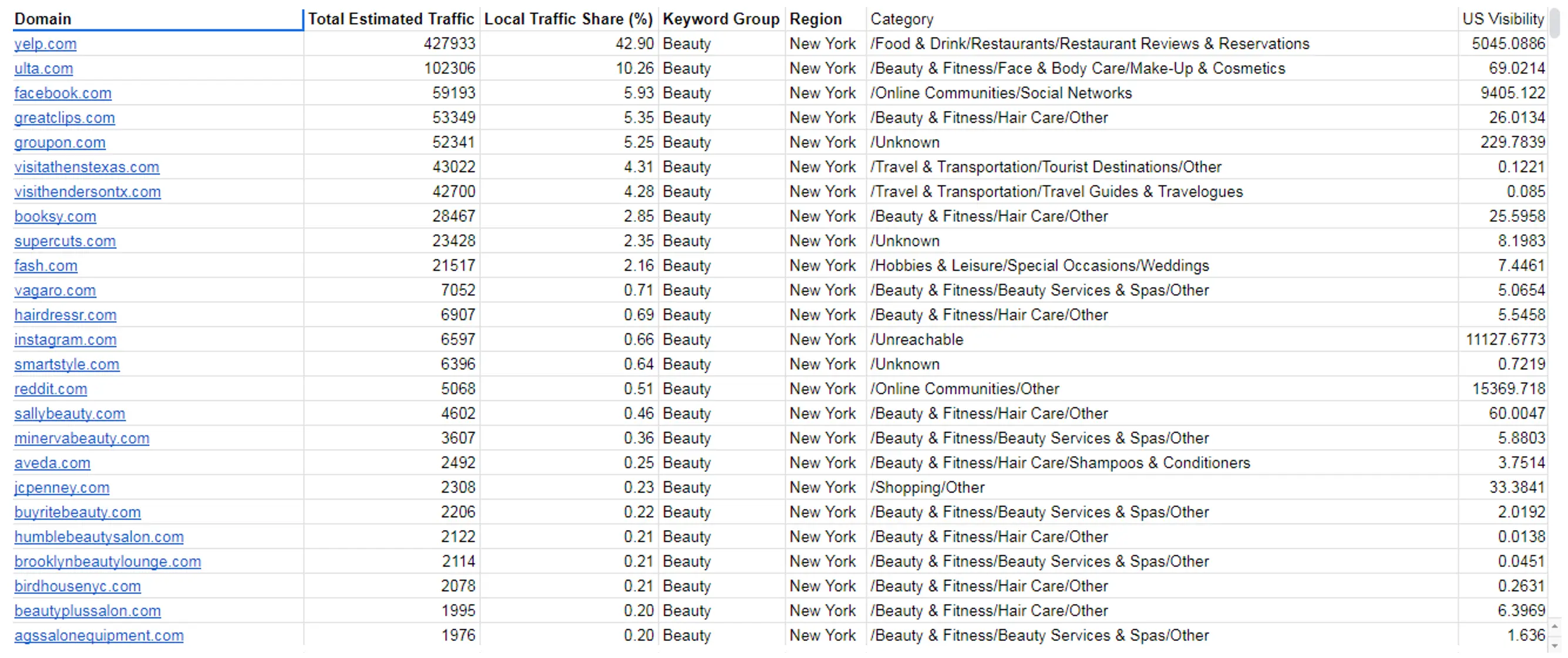
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Final”.
Ми відфільтровуємо всі нерелевантні категорії, залишаючи тільки б’юті та фітнес індустрії. Також можна фільтрувати за типом послуги й місцем розташування. Плюс ми маємо всі метрики щодо продуктивності ключових слів і зворотних посилань.
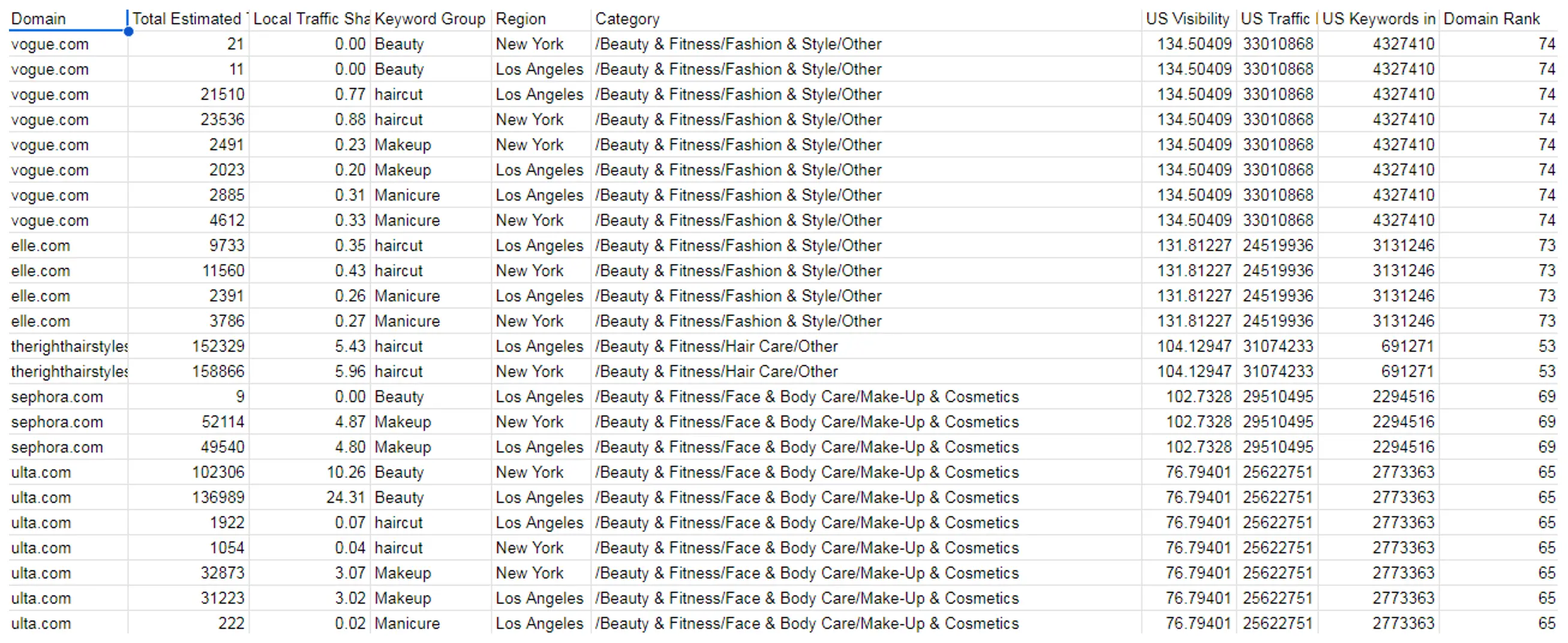
Ви можете переглянути весь лист таблиці за наступним посиланням у розділі під назвою “Final with Categories filtered”.
Висновок
Цей матеріал демонструє комплексний підхід до маркетингових досліджень у конкретних галузях, слідуючи вказаним крокам.
Ми створюємо детальне розуміння гравців ринку та їхньої ефективності, використовуючи:
- збір та фільтрацію ключових слів;
- аналіз сторінок пошукової видачі та обсягів пошуку;
- класифікацію доменів, ранжування і метрики зворотних посилань.
Кінцевий результат дозволяє точно фільтрувати за індустрією, типом послуги й місцем розташування, надаючи корисну інформацію для прийняття зважених рішень і стратегічного планування.
FAQ
Ця методологія є гнучкою, і її можна адаптувати до будь-якої галузі, змінюючи початковий набір ключових слів і налаштовуючи процеси сканування та фільтрації під конкретні потреби.
Процес підтримує регіональну адаптацію шляхом налаштування сканування сторінок пошукової видачі та аналізу ключових слів для конкретних регіонів.
Оцінка трафіку здійснюється шляхом застосування показників CTR до топ-10 органічних позицій у об’єднаних даних сторінок пошукової видачі і обсягів пошуку, що дозволяє визначити вебсайти з найбільшою часткою трафіку.
Використайте Serpstat для маркетингових досліджень
Використовуйте кращі SEO інструменти
SЕО аудит сайту
Використовуючи SEO аудит сайта, ви дізнаєтесь і зможете виправити усі помилки що заважають просуванню
Пакетний аналіз доменів
Отримайте всю інформацію про конкурентів за допомогою пакетного аналізу доменів
Інструменти ШІ для контенту
Інструменти ШІ для контенту – покращуйте якість та швидкість роботи з текстом
Локальне SEO
Отримайте нових клієнтів за допомогою потужного автоматизованого інструменту локальне SЕО
Рекомендовані статті
Кейси, лайфхаки, дослідження та корисні статті
У вас немає часу стежити за новинами? Не турбуйтеся! Наш редактор підбере статті, які неодмінно допоможуть вам у роботі. Приєднуйтесь до нашої затишної спільноти :)
Натискаючи кнопку, ви погоджуєтеся з нашою Політикою конфіденційності